画像生成したらコラージュだった件
本記事は、画像生成AI Advent Calendar 2022 15日目を埋める記事です。
はじめに
画像生成AIは、学習した画像をコラージュした画像を出力しているのではないか、という議論があります。多くのモデルは勝手に収集した画像で学習(訓練)されているため、そのようなコラ画像が生成されていたら大問題です。

上の図を見てください。この図は、今月投稿された論文 [1] Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models [Gowthami Somepalli+, arXiv 2022] の図です。上段がStable Diffusionの生成画像、下段が訓練データのサブセット(LAION Aesthetics v2 6+)中で一番似た画像です。生成画像の一部またはほぼ全部が訓練画像にそっくりですよね。画像生成AIに関して危惧されているコラージュは、まさにこのような画像なのではないでしょうか。元画像が1枚のこともあるため、より根本的には「複製」が問題となります。
本記事では、画像生成においてどのような条件で複製が起こるか、どのような複製が起こるかを中心に紹介します。「GANによる画像生成での複製」・「拡散モデルによる画像生成での複製」の関連研究について簡単に説明した後、上記論文を紹介します。なお、機械学習モデル全般の訓練データの記憶・複製問題については割愛しますので、「過適合」や「overfitting」でググってください。
関連研究:GANによる画像生成での複製
訓練画像を記憶して複製してしまう現象は、拡散モデル以外での画像生成でも起こります。特に拡散モデル流行前に一世を風靡したGANについては、複製に関連する論文が多数あります。
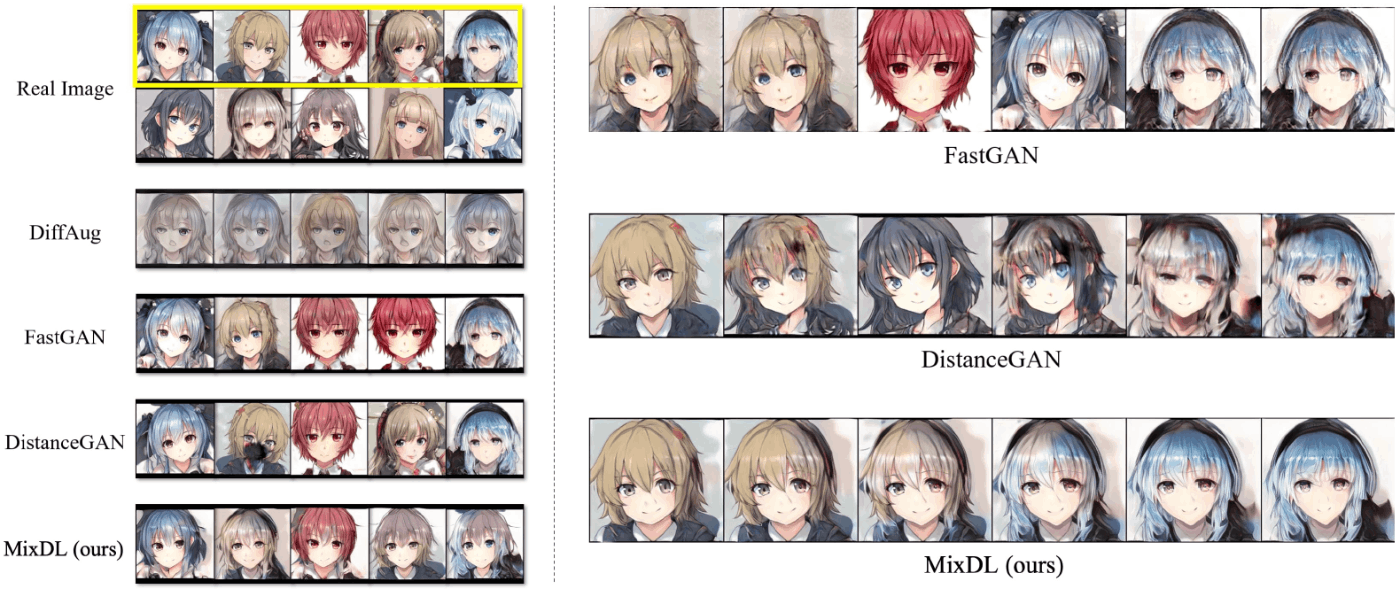
複製は、訓練画像枚数が少ない場合に顕著に発生します。複製発生時の例として、MixDLの論文 [2] の図を示します。図中の"Real Image"が訓練画像(Anime Faceデータセットの画像10枚)です。FastGANの結果で顕著ですが、訓練画像が複製され(図中左)、また、生成画像間の補間が階段状になっています(図中右)。本来であれば、この論文の提案手法MixDLの結果のように滑らかに少しずつ変化してほしいのですが、近くの訓練画像に吸い寄せられるような生成結果になります。この論文を含め、過適合しないようにどう訓練すべきかは、機械学習の重要な課題ですが、本記事では対象外とします。
画像複製問題に焦点を当てた代表的な論文である、[3] の概要を紹介します。
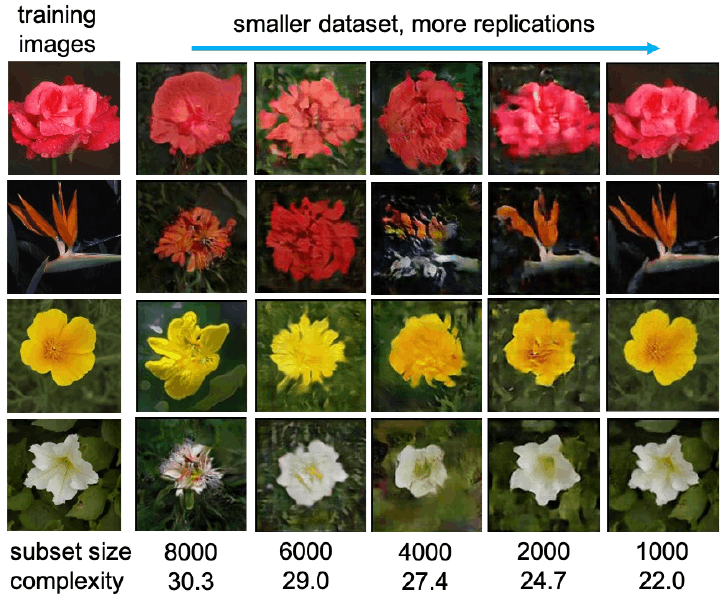
- データセットのサイズと複雑さがGANの複製と生成画像の知覚的品質に重要な役割を果たす
- 複製率は、データセットのサイズと複雑さに関して指数関数的に減衰する
- 2種のGAN(BigGAN, StyleGAN2)と3データセットの組み合わせで、複製率減衰を似た式で表せる
- 知覚的な画像品質は、データセットサイズに対してU字型の傾向を示す

複製率減衰
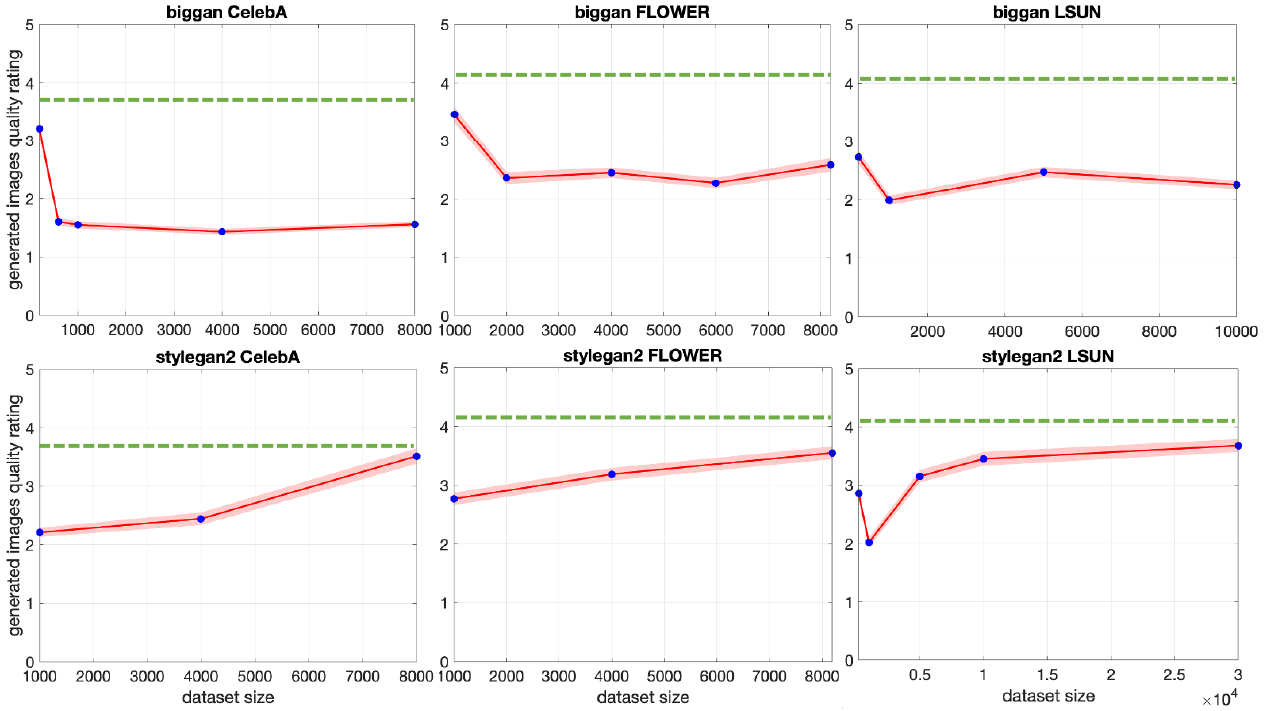
知覚的な画像品質。U字型の右側、データセットが大きくなるほど品質が上がるのは望ましい状態です。逆に、U字型の左側が問題であり、データセットが小さいと、複製が起き、人間が見た時に高品質に見えてしまう、という現象が起きています。
これらのGANに関する研究結果が、どこまで拡散モデルにも通用するかは分かりませんが、「似た見た目の物体がよく出てくると思ったら、実は訓練画像中の物体を複製していた」、「たまに出てくる綺麗な生成画像をチェリーピッキングしていたら、実は複製が原因で綺麗に見える画像だった」ということがないよう、注意が必要かと思います。
関連研究:拡散モデルによる画像生成での複製
拡散モデルでもGAN同様、訓練画像枚数が少ない場合に複製が顕著に発生します。[4] の実験では、以下が定性的・定量的に示されています。
- DDPM、スクラッチ学習、訓練画像10枚:複製が起こる
- DDPM、スクラッチ学習、訓練画像100枚:複製が起こる
- DDPM、スクラッチ学習、訓練画像1000枚:多様な画像を生成できる
- DDPM、大きなデータセットで事前学習、訓練画像10枚で短いfine-tuning:多様な画像を生成できる

拡散モデルが訓練画像を複製する現象は、OpenAIのブログ [5] でも報告されています。意訳されている方がいるので詳細はこちらをご覧ください。OpenAIは、訓練データセット中の重複画像を除去することで、DALL·E 2の訓練画像複製リスクを低減しています。彼らは画像複製の問題を "Image Regurgitation" と呼んでいます。ここでの "Regurgitation" は、「暗記したものを理解せずにそのまま返すこと」の意味であり、短く訳せば「画像受け売り」問題だと思います(実際に生成画像を売っている人がいるわけですし)。
また、こちらは拡散モデルかは分かりませんが、Midjourney v4が"Afghan Girl"と呼ばれる有名な写真を複製することが指摘されており、物議を醸しています。(あくまで参考情報です。信頼性の比較的高い媒体で、詳細な分析結果が報告されることを期待します。)
Diffusion Art or Digital Forgery?
それでは本記事のメインとなる論文を紹介していきます。
「拡散アートかデジタル偽造か? 拡散モデルにおけるデータ複製の調査」。拡散モデルによる画像生成で起こる、replication/reproduction(複製、再現)、forgery(偽造、模造、模倣、贋造、違法コピー)、stealing(窃盗、盗用、盗作、パクリ)を問題視し、検証した論文です。
本論文はCC BY 4.0ですので、気になった部分の訳(ほぼ直訳だが意訳・省略を含む)をガンガン載せていきます。なお、コンテンツ複製の検出方法の検討(4章)は、本論文の重要な貢献の一つですが、本記事では割愛します。また、初見では理解に時間を要すであろう定量評価結果も割愛しますので、詳細は論文をご確認ください。
概要
最先端の拡散モデルは、高品質でカスタマイズ可能な画像を生成するため、商業美術やグラフィックデザインに使用できます。しかし、拡散モデルは独自の作品を創造しているのでしょうか? それとも、訓練セットから直接コンテンツを複製しているのでしょうか? 本論文では、生成画像と訓練サンプルを比較してコンテンツ複製を検出できる、画像検索フレームワークについて検討します。Oxford flowers, Celeb-A, ImageNet, LAIONなどのデータセットで訓練された拡散モデルに、提案フレームワークを適用し、訓練セットサイズなどの要因がコンテンツ複製率にどのような影響を与えるかを考察します。また、人気の高いStable Diffusionを含む拡散モデルが、訓練データから露骨にコピーしている事例を確認します。
図1
Stable Diffusionは、訓練データを複製し、記憶した前景と背景の物体をつなぎ合わせて画像を作成できます。また、画素単位で同一ではないが意味的には元の物体と同等の物体を想起する、再構成記憶(reconstructive memory)を示すことがあります。この図では、そのような挙動が起こることを、LAIONから抽出した様々なプロンプトと、手作りのプロンプト(一番右のペア)を使って示しています。このような画像の存在は、データ記憶の性質と拡散画像の所有権について疑問を投げかけるものです。
1. 序論
(拡散モデルの訓練に使用される)巨大データセットは、多くの法的・倫理的リスクを抱えています。これらのデータセットは大きすぎて人間が慎重にキュレーションできず、データソースの出所や知的財産権はほとんど不明です。大規模モデルが訓練データを記憶する能力も考えると、拡散モデルの出力の独創性には疑念が生じます。拡散モデルは、警告無しに、訓練セットのデータを直接複製したり、複数の訓練画像のコラージュを提示したりする危険性があります。
部分的または全体的な訓練画像の複製を、非公式にコンテンツ複製(content replication)と呼ぶことにします。訓練データから部分的または完全な情報を複製することは、原則として、アーティストや写真家への帰属の観点で、拡散モデルの倫理的で合法な使用に影響を与えます。複製物は有益なことも有害なこともあります(※訳注1)。コンテンツ複製が許容される場合、望ましい場合、フェアユースである場合もあれば、「盗用」である場合もあります。これらの倫理的境界は現時点では不明ですが、本論文では、「現代の最先端の拡散モデルで、複製が実際に起こるかどうか、どの程度起こるか」という科学的問題に焦点を当てています。
※訳注1:原文は "Replicants are either a benefit or a hazard"。本論文の内容と共通点を持つ映画「ブレードランナー」のセリフ "Replicants are like any other machine. They're either a benefit or a hazard." のパロディとなっており、この文章自体が、複製が許容される例と言えるでしょう。
新規または既存のツールを使用して、データセット特性が異なる様々な拡散モデルにおけるデータ複製の挙動を検索します。以下を示します。
- 小規模・中規模のデータセットサイズでは複製が頻繁に発生する
- 一方、大規模で多様なImageNetデータセットで訓練されたモデルの場合、複製は検出できないように見える
後者の発見により、大規模モデルでは複製は問題にならない、と思われるかもしれません。しかし、さらに大きなStable Diffusionモデルでは、さまざまな形式の明白な複製が見られます(図1)。
3. 何を複製と見なすか
創作物からの「複製」については、様々な見解がありますが、複製コンテンツの検出システムを設計する目的で範囲を狭めます。次の(informal、非公式な)定義を考えます。
(前景または背景に)訓練画像と同じように見える物体が含まれている場合に、その生成画像は複製コンテンツを持つと言う。ただし、データ増幅によって生じうる外観の些細な違いは無視する。
("We say that a generated image has replicated content if it contains an object (either in the foreground or background) that appears identically in a training image, neglecting minor variations in appearance that could result from data augmentation.")
知的財産権紛争の対象となる可能性が高い、物体レベルの類似性に焦点を当てています。また、データ増幅によって説明できる外観の些細な違いは、通常は著作権の主張に関連しないため、無視します(※訳注:日本では同一性保持権の侵害が問題になるかもしれません)。(物体レベルの類似性の)代わりとして、スタイルまたは意味上の類似性が考えられますが、ここではそのような定義に焦点を当てません。それらは、非常に主観的であり、通常は知的財産権の侵害とは見なされず、また、多くの画像には明確に定義されたスタイルが無い(例:標準的なカメラで撮影したフィルター処理されていない自然な画像)ためです。
5. 拡散モデルはコピーするか?
小さなデータセットで訓練した拡散モデルは、訓練データからコピーされた画像を生成する傾向があります。訓練セットのサイズを大きくすると、複製の量は減少します。
実験条件
- モデル:DDPM
- データセット:Celeb-A, Oxford Flowers
- 図の生成画像例は、訓練データとの類似度上位20枚の画像から選択
訳注:複製画像を見つけにいっている分、先行研究 [4] より多い画像枚数でも複製が見つかっています。その他の実験条件も異なります。
結果:Celeb-Aデータセット

完全な複製を緑、非常に近いが完全な複製ではないものを青で示します(※訳注:青の基準は謎)。300枚または3000枚の画像で訓練した拡散モデルは、訓練画像から露骨にコピーします。しかし、データセット全体でモデルを訓練した場合、訓練サンプルと似ているが同一ではない生成が現れることがあります。
結果:Oxford Flowersデータセット

不思議なことに、わずか1083枚の画像で訓練したモデルでも、訓練データの(マイナーではあるが)ユニークなバリエーションを創造できます。
6. 事例研究:ImageNet LDM
実験条件
- モデル:クラス条件付きLDM
- データセット:ImageNet
結果
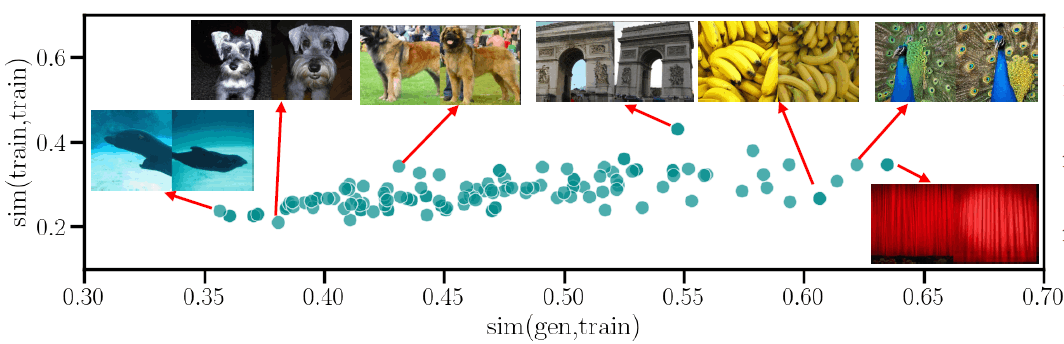
定性的には、このモデルのどの生成にも著しいコピーは観察されません。各クラスの類似度スコアの高い例は、非常に似ているが決して正確なコピーではなく、クラス内の多様性の低さで説明がつくかもしれません(散布図の相関が0.6)。平均類似度スコアは比較的低く、複製の可能性が非常に低いことを示しています。
7. 事例研究:Stable Diffusion
実験条件
- モデル:Stable Diffusion v.1.4
- 訓練データセット:LAION
- 検索対象データセット:LAION Aesthetics v2 6+(1200万枚、訓練最終段階のデータセットのサブセット)
検証方法
- LAION Aesthetics 12M から9000枚の画像(ソース画像と呼ぶ)をランダムにサンプリング
- ソース画像に対応するキャプションを取得
- キャプションをStable Diffusionに入力して画像を生成
- 生成画像ごとに、一致画像(最も似た画像)を調査
結果

図7
Stable Diffusion生成画像に見つかったコピーの事例を示します。SSCDによるtop-1類似度スコアが0.5を超える画像(約170枚、上位1.88パーセンタイル)から選択しています。この0.5の閾値を超えると、かなりの量のコピーが観察されます。
- 上から1行目:壁の絵画以外はそのままコピーされている
- 4行目、6行目:背景がコピー
すべての合成画像はLAIONからのキャプションを使用して生成されましたが、どの生成も(各キャプションに対応する)ソース画像と一致しませんでした。実際、ソース画像のキャプションがソース画像のコンテンツを表していない場合や、生成がソースとはまったく異なる場合があります。この挙動は、図7の1行目で確認できます。5行目の一致画像は、ソース自体よりもソースキャプションをよりよく表しています。

これらの170枚の画像には、複製動作がキャプションのキーフレーズに大きく依存している事例が見つかります。図10に2つの例を示し、キーフレーズを赤で強調表示します。
- 上段:"Canvas Wall Art Print"というテキストが頻繁に(約20%)存在するため、生成にはLAIONの特定のソファが含まれています(図1も参照)。
- 下段:プロンプト"A painting of the Great Wave off Kanagawa by Katsushika Hokusai"(葛飾北斎による神奈川沖浪裏の絵)を少し変えることで、さまざまな生成を示しています。("The Great Wave off Kanagawa by Katsushika Hokusai" → "The Great Wave off Kanagawa" → "A painting of Kanagawa coast" → "A painting of a Wave"の順に)"painting"と"wave"だけが残るよう徐々に単語を除いていますが、どの生成も元の絵に似た波の構造を持っています。

コンテンツよりスタイルがコピーされる生成事例が見受けられます。生成プロンプトにアーティスト名が使用されている場合に明白です。「絵画の名前 by アーティスト名」という形式のプロンプトで多くの絵画を生成したところ、有名な絵画が頻繁に、さまざまな精度で複製されました。図8では、左から右に進むにつれて、コンテンツのコピーは減少していますが、スタイルのコピーは依然一般的です。
キャプションサンプリングの役割
LAION自体からキャプションをサンプリングしているため、キャプションソース画像の複製につながる可能性がありますが、通常はキャプションソースを複製しません。LAIONのキャプションは、データセットの画像と密接に関連する「キーフレーズ」を含むことがあるため、記憶された画像を想起させます。そのため、LAIONベースのキャプションサンプリングは、他のサンプリング方法よりもデータ複製率が高くなる可能性があります。「典型的な」キャプションのベースラインサンプラーがないため、科学的な方法でこのバイアスを修正することは困難です。さらに、熟練の拡散モデルユーザーが使用するキャプションは、多くの場合、LAIONによくある強力なキーフレーズ("art station"、"35mm"、アーティスト名など)を利用しています。
重複訓練データの役割
LAIONデータセット中には重複画像があり、重複画像の方が複製される確率が高いと疑われます。複製されたコンテンツは、重複が通常より多い訓練画像から抽出される傾向があるようです。根拠:SSCD 0.95以上を重複と定義すると、訓練データのランダム画像は平均11.6回重複。一方、生成画像に対してSSCDが0.5以上となる一致画像(訳注:図7のTop Matchのような画像)は平均34.1回重複。
8. 考えられる複製原因(Stable Diffusionで何故複製が起こるかの考察)
ImageNet LDMとStable Diffusionで挙動が異なるため、それら2つの共通点(同様の更新ルール、訓練ルーチン、パラメータ数)ではなく、それら2つの相違点が複製挙動の差異を生んでいることになります。Stable Diffusionでの複製動作は、以下の要因の複雑な相互作用から生じると推測されます。
- Stable Diffusionは、(クラスではなく)テキストで条件付けされる
- 訓練セットの画像重複数の分布が大きく歪んでいる(※訳注:画像重複の有無だけでは説明できない根拠は原文参照)
- 訓練時に、データのサブセットに過適合するのに十分な回数、モデルが更新される
9. 制限と結論
拡散モデルは訓練データから忠実性の高いコンテンツを複製できることが判明しました。大規模モデルの典型的な画像には、我々の特徴抽出器で検出できるコピーコンテンツは含まれていないようですが、コピーは安全に無視できないほど頻繁に発生するようです(Stable Diffusionのランダム生成画像の約1.88%が、データセットとの類似性0.5以上)。
この結果では、Stable Diffusion等のモデルにおける複製の量が過小評価されています。
- Stable Diffusionの実験での複製検索対象は、訓練データ全体の0.6%未満にすぎない
- 検索対象データ(LAION Aesthetics v2 6+)以外からコンテンツを複製する例が確かに存在する(図12)
- 我々の検索方法では特定できない複製が存在する可能性が高い

おわりに
本記事では、画像生成AIで起こる画像複製の問題を紹介しました。一部の条件では明白な複製が実証されています。複製が確認されていない条件については、複製が実際に起きていないのか、複製が検出できていないだけなのか、分かりません。複製の挙動・原因のさらなる分析、複製の起こらない画像生成方法、高精度な複製検出方法が求められます。本記事が、画像生成AIの技術・倫理に関する、エビデンスに基づく議論のお役に立てば幸いです。
参考文献
[1] Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, Tom Goldstein, "Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models", arXiv 2022. https://arxiv.org/abs/2212.03860
[2] Chaerin Kong, Jeesoo Kim, Donghoon Han, Nojun Kwak, "Few-Shot Image Generation with Mixup-Based Distance Learning", ECCV 2022. https://arxiv.org/abs/2111.11672
[3] Qianli Feng, Chenqi Guo, Fabian Benitez-Quiroz, Aleix M. Martinez, "When Do GANs Replicate? On the Choice of Dataset Size", ICCV 2021. https://arxiv.org/abs/2202.11765
[4] Jingyuan Zhu, Huimin Ma, Jiansheng Chen, Jian Yuan, "Few-shot Image Generation with Diffusion Models", arXiv 2022. https://arxiv.org/abs/2211.03264
[5] Alex Nichol, "DALL·E 2 Pre-Training Mitigations", OpenAI Blog 2022. https://openai.com/blog/dall-e-2-pre-training-mitigations/
Discussion