A Survey on LLM-as-a-JudgeというLLMに評価させる仕組み
LLM-as-a-Judgeの定義
LLM-as-a-Judgeの正式な定義は以下のとおりです。
- LLM-as-a-Judgeプロセス全体から期待される方法で得られた最終評価。スコア、選択、文章など、さまざまな形式をとることができます。
- 対応するLLMによって定義された確率関数。生成は自己回帰プロセスです。
- 評価される任意のタイプの入力データ(テキスト、画像、ビデオなど)。
- 入力のコンテキスト。多くの場合、プロンプトテンプレートであるか、ダイアログの履歴情報と組み合わせたものです。
- 入力とコンテキストCを組み合わせる結合演算子。この演算は、コンテキストに応じて、先頭、中央、末尾などに配置されるなど、さまざまな方法で実行できます。
この公式は、LLM-as-a-Judgeが、コンテキストに基づいて後続のコンテンツを生成し、そこから目標の評価を得る自己回帰生成モデルの一種であることを反映しています。
LLM-as-a-Judgeの形式は、入力設計、モデルの選択とトレーニング、出力の後処理など、評価タスクにLLMを活用する方法を示しています。
LLM-as-a-Judgeの実装におけるさまざまな基本的なアプローチは、この公式に基づいて分類できます。具体的には、In-Context Learning、Model Selection、Post-processing Method、Evaluation Pipelineの4つがあり、図2にまとめられています。

このパイプラインに従うことで、評価のための基本的なLLM-as-a-Judgeを構築することができます。
LLMによる評価における主な課題
- バイアス: LLMは、トレーニングデータに存在するバイアスを反映する可能性があり、これが評価結果に影響を与える可能性があります。例えば、特定の立場にある回答を好んだり、冗長な回答を好んだりする傾向が見られることがあります。 ソースでは、位置バイアス、長さバイアス、自己強化バイアス、多様性バイアス、具体性バイアス、感情バイアスなど、さまざまな種類のバイアスについて詳しく説明しています。 これらのバイアスに対処するため、回答の位置をランダムに入れ替えたり、複数のLLMによる評価結果を統合したりするなどの対策が提案されていますが、まだ完全な解決には至っていません。
- 頑健性: LLMは、入力のわずかな変更に対して評価結果が大きく変化する可能性があり、悪意のある攻撃に対して脆弱である可能性があります。 例えば、評価対象のテキストに意味のない句を挿入することで、評価スコアを操作できることが示されています。 このような攻撃からLLMを守るためには、敵対的トレーニングなどの防御策が必要となりますが、まだ研究段階であり、効果的な対策は確立されていません。
- 強力な基盤モデルの不足: テキストベースの評価では優れた性能を発揮するLLMですが、マルチモーダルコンテンツを効果的に評価できる堅牢なマルチモーダルモデルは不足しています。 現在のマルチモーダルLLMは、異なるモダリティを横断した複雑な推論に苦労しており、マルチモーダル評価タスクにおける信頼性の高い評価を達成する上で課題となっています。また、テキストコンテンツの評価においても、強力な指示追従能力と推論能力を備えたLLMが不足しているため、高品質な評価ができないケースも多々あります。
これらの課題を克服し、LLMをより信頼性の高い、公平で一貫性のある評価ツールとして活用するためには、さらなる研究と開発が必要です。
サマリー

LLM-as-a-Judgeはエージェントの中で2つの一般的な形で現れます。左の図はAgent-as-a-Judgeで、評価者として機能する完全なエージェントを設計しています。上の図は、エージェントのプロセスでLLM-as-a-Judgeを使うことを示しています。
結果

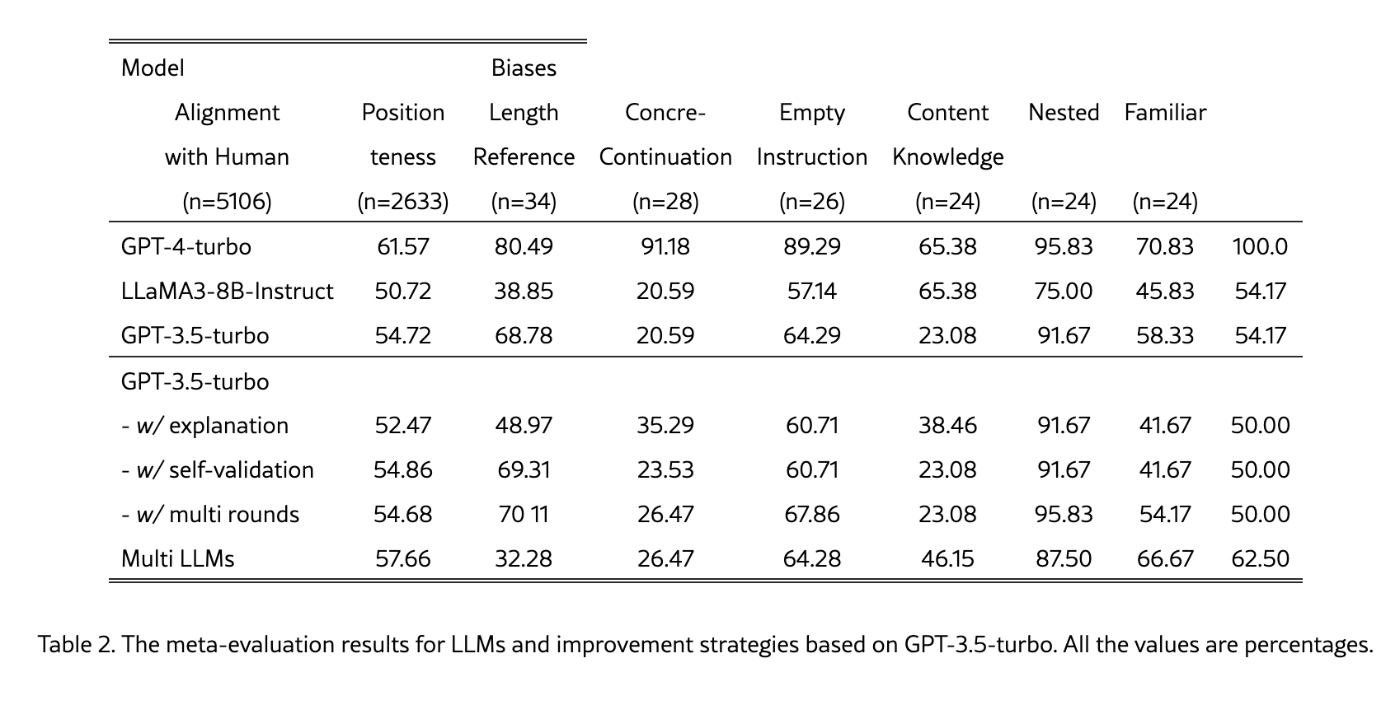
実験結果と分析
ソースによると、LLM-as-a-Judgeの改善戦略に関するメタ評価実験が行われ、その結果が表2に示されています。この実験では、GPT-4、GPT-3.5、LLaMA3-8B-Instructの3つのLLMを評価者として選択し、「説明の提供」、「自己検証」、「複数ラウンドによる要約」、「複数LLMによる投票」という4つの改善戦略についてメタ評価を行いました。評価次元は、人間による評価との整合性、バイアス、位置バイアスの3つです。
異なるLLMの評価性能の比較
実験の結果、異なるLLM間で評価性能に大きな差があることがわかりました。GPT-4は、すべてのメタ評価次元においてGPT-3.5とLLaMA3-8B-Instructを大きく上回り、バイアスも少ないことが示されました。このことから、経済的に可能であれば、GPT-4を自動評価に用いることで、バイアスを最小限に抑えた客観的な結果を得られる可能性が高いと言えます。
一方、LLaMA3-8B-InstructとGPT-3.5は、ほとんどのメタ評価次元で同様の指標を示しました。しかし、LLaMA3-8B-Instructは位置バイアスにおいてパフォーマンスが低く、GPT-3.5は空参照バイアスにおいて課題を抱えていることが明らかになりました。LLaMA3-8B-Instructはオープンソースであるため、特定のデバイアス微調整を行えば、比較的小規模な自動評価器として優れた評価性能を達成できる可能性があります。
異なる改善戦略の性能比較
改善戦略に関しては、すべての修正がLLM-as-a-Judgeの評価結果を効果的に改善するわけではないことが明らかになりました。
-
説明の提供 (- w/ explanation)は、評価スコアや選択とともに理由を提供することで解釈可能性を高め、人間によるレビュー時の論理的なバックトラックを支援します。しかし、評価性能とバイアスの軽減という点では、概して悪影響を及ぼすことがわかりました。この性能低下の原因は、自己説明によってより深いバイアスが導入されたためと考えられています。
-
自己検証 (-w/ self-validation)は、効果がほとんど見られませんでした。これは、LLMの過剰な自信が原因である可能性があり、自己検証中の再評価の取り組みが制限されている可能性があります。この制限については、セクション7.1で詳しく説明します。
-
複数ラウンドによる要約 (- w/ multi rounds)は、明確な利点がある戦略であり、人間による評価との整合性と位置バイアスの両方において改善が見られました。複数回の評価を実行することで、単一ラウンドにおける偶発的な要因によるランダムな影響を軽減できるためと考えられます。
-
複数LLMによる投票 (Multi LLMs)は、整合性の指標が大幅に低下した一方、バイアスの指標がわずかに改善しました。複数のLLM評価器を用いてコンテンツを同時に評価し、その結果を統合することで、単一のLLM評価器によって導入されるバイアスを軽減できる可能性がありますが、整合性の低下は懸念材料です。
結論
要約すると、LLMの固有の能力と潜在的なリスクのために、LLM-as-a-Judgeの一般的な改善戦略は、評価性能の向上やバイアスの軽減において完全には有効ではありません。限界と課題については、セクション7でさらに議論されています。
まとめ
LLM-as-a-Judgeは、まだ初期段階の分野ですが、評価プロセスを自動化し、さまざまな分野における意思決定を改善するための大きな可能性を秘めています。これらの課題に対処し、より信頼性が高く、堅牢で、強力な基盤モデルを開発することで、LLM-as-a-Judgeは、将来、人間と協力してより良い判断を下すための不可欠なツールになる可能性があります。
Discussion