Claude Sonnet 4に産業レベルのコードを書かせるプロンプトのハック
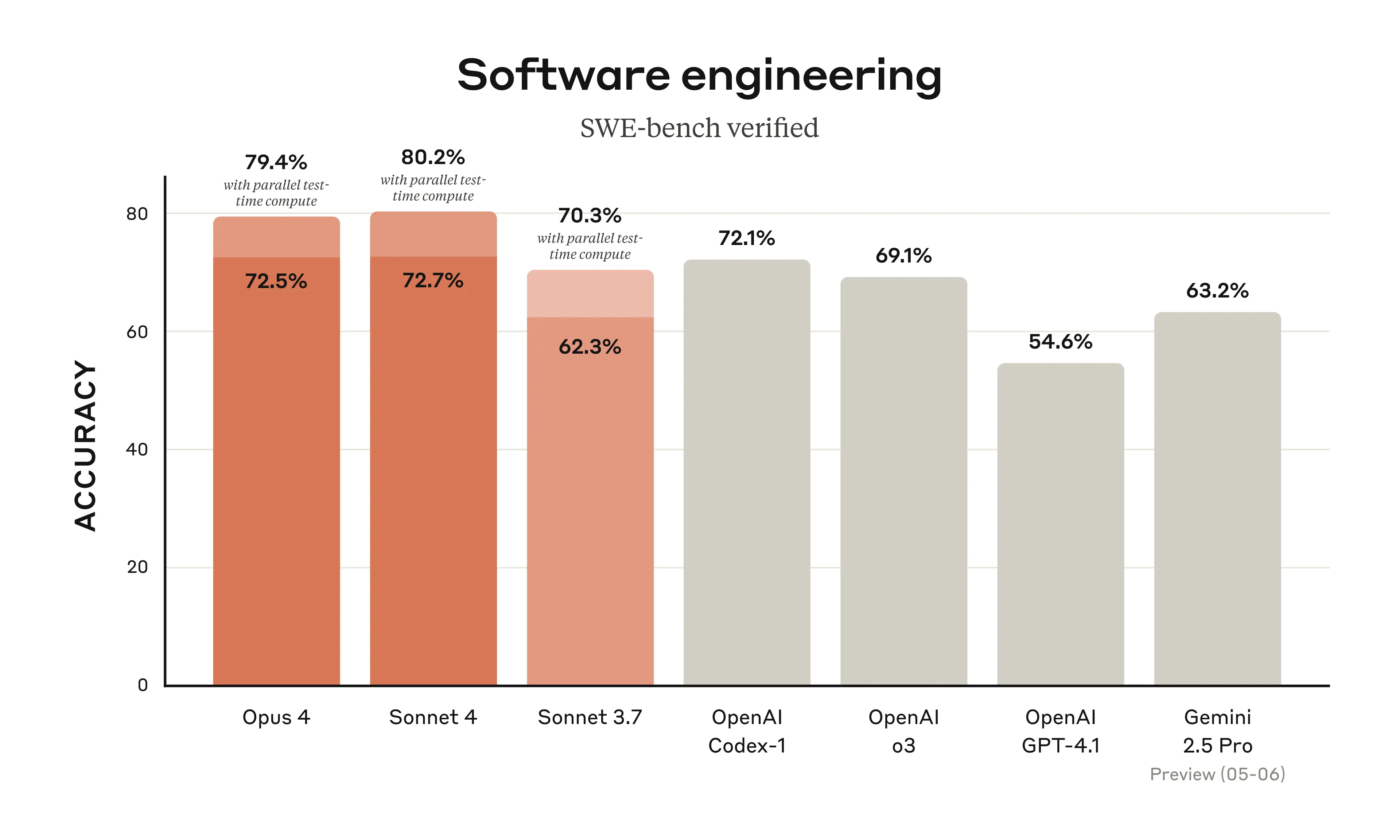
Claude Sonnet 4 は、前のモデルSonnet 3.7を大幅に向上させ、SWE-benchで最先端の72.7%というコーディング精度を実現しています。
このモデルは、実装をより細かく制御するための強化されたステアビリティを備えています。
Opus 4ほどではありませんが、機能と実用性では最適な性能を提供します。

システムプロンプト
システムプロンプトは、AIモデルの振る舞いを制御する基本的な指示のことです。
定義の応答方針や制約が定義されているので、タスクにあったプロンプト設計を行いましょう。
Claude Sonnet 4ではシステムプロンプトに魔法の言葉があります。
目的のタスクによってプロンプトに埋め込みましょう。
「deep dive」(深掘り)
「comprehensive」(包括的な)
「analyze」(分析する)
「evaluate」(評価する)
「research」(調査する)
産業レベルの出力されたコード
# RAG System Package Structure
## rag_system/__init__.py
"""
High-Performance RAG (Retrieval-Augmented Generation) System
A production-ready implementation with FAISS and multilingual support.
"""
__version__ = "1.0.0"
__author__ = "RAG System Team"
from .retriever import RAGRetriever
from .document_loader import DocumentLoader
from .embedding import EmbeddingModel
from .faiss_index import FAISSIndex
__all__ = [
"RAGRetriever",
"DocumentLoader",
"EmbeddingModel",
"FAISSIndex"
]
## rag_system/config.py
"""
Configuration management for RAG system.
Handles all configurable parameters and settings.
"""
import os
import json
import logging
from dataclasses import dataclass
from typing import Dict, Any, Optional
from pathlib import Path
@dataclass
class EmbeddingConfig:
"""Configuration for embedding model."""
model_name: str = "intfloat/multilingual-e5-base"
device: str = "auto" # auto, cpu, cuda
max_length: int = 512
batch_size: int = 32
normalize_embeddings: bool = True
@dataclass
class ChunkingConfig:
"""Configuration for document chunking."""
chunk_size: int = 512
chunk_overlap: int = 50
min_chunk_size: int = 50
preserve_sentences: bool = True
language: str = "multilingual"
@dataclass
class FAISSConfig:
"""Configuration for FAISS index."""
index_type: str = "IndexFlatIP" # Inner Product for cosine similarity
nlist: int = 100 # For IVF indices
nprobe: int = 10 # For IVF indices
use_gpu: bool = False
gpu_id: int = 0
@dataclass
class SearchConfig:
"""Configuration for search operations."""
top_k: int = 10
score_threshold: float = 0.3
max_concurrent_queries: int = 4
timeout_seconds: float = 30.0
@dataclass
class SystemConfig:
"""Main system configuration."""
embedding: EmbeddingConfig
chunking: ChunkingConfig
faiss: FAISSConfig
search: SearchConfig
# File paths
data_dir: str = "./data"
index_dir: str = "./indices"
log_dir: str = "./logs"
# Logging
log_level: str = "INFO"
log_to_file: bool = True
# Performance
num_workers: int = 4
memory_limit_gb: float = 8.0
class ConfigManager:
"""Manages system configuration with file persistence."""
def __init__(self, config_path: Optional[str] = None):
"""
Initialize configuration manager.
Args:
config_path: Path to configuration file. If None, uses default.
"""
self.config_path = config_path or "config.json"
self.config = self._load_config()
self._setup_logging()
def _load_config(self) -> SystemConfig:
"""Load configuration from file or create default."""
try:
if os.path.exists(self.config_path):
with open(self.config_path, 'r', encoding='utf-8') as f:
config_dict = json.load(f)
return self._dict_to_config(config_dict)
else:
# Create default config
config = SystemConfig(
embedding=EmbeddingConfig(),
chunking=ChunkingConfig(),
faiss=FAISSConfig(),
search=SearchConfig()
)
self.save_config(config)
return config
except Exception as e:
logging.error(f"Failed to load config: {e}")
return SystemConfig(
embedding=EmbeddingConfig(),
chunking=ChunkingConfig(),
faiss=FAISSConfig(),
search=SearchConfig()
)
def _dict_to_config(self, config_dict: Dict[str, Any]) -> SystemConfig:
"""Convert dictionary to SystemConfig object."""
try:
return SystemConfig(
embedding=EmbeddingConfig(**config_dict.get("embedding", {})),
chunking=ChunkingConfig(**config_dict.get("chunking", {})),
faiss=FAISSConfig(**config_dict.get("faiss", {})),
search=SearchConfig(**config_dict.get("search", {})),
**{k: v for k, v in config_dict.items()
if k not in ["embedding", "chunking", "faiss", "search"]}
)
except Exception as e:
logging.error(f"Failed to parse config dict: {e}")
raise ValueError(f"Invalid configuration format: {e}")
def save_config(self, config: SystemConfig) -> None:
"""Save configuration to file."""
try:
config_dict = {
"embedding": config.embedding.__dict__,
"chunking": config.chunking.__dict__,
"faiss": config.faiss.__dict__,
"search": config.search.__dict__,
"data_dir": config.data_dir,
"index_dir": config.index_dir,
"log_dir": config.log_dir,
"log_level": config.log_level,
"log_to_file": config.log_to_file,
"num_workers": config.num_workers,
"memory_limit_gb": config.memory_limit_gb
}
os.makedirs(os.path.dirname(self.config_path), exist_ok=True)
with open(self.config_path, 'w', encoding='utf-8') as f:
json.dump(config_dict, f, indent=2, ensure_ascii=False)
except Exception as e:
logging.error(f"Failed to save config: {e}")
raise
def _setup_logging(self) -> None:
"""Setup logging configuration."""
try:
# Create log directory
if self.config.log_to_file:
os.makedirs(self.config.log_dir, exist_ok=True)
# Configure logging
log_level = getattr(logging, self.config.log_level.upper())
handlers = []
# Console handler
console_handler = logging.StreamHandler()
console_handler.setLevel(log_level)
console_formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
console_handler.setFormatter(console_formatter)
handlers.append(console_handler)
# File handler
if self.config.log_to_file:
file_handler = logging.FileHandler(
os.path.join(self.config.log_dir, 'rag_system.log'),
encoding='utf-8'
)
file_handler.setLevel(logging.DEBUG)
file_formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(funcName)s:%(lineno)d - %(message)s'
)
file_handler.setFormatter(file_formatter)
handlers.append(file_handler)
# Configure root logger
logging.basicConfig(
level=log_level,
handlers=handlers,
force=True
)
except Exception as e:
print(f"Failed to setup logging: {e}")
# Fallback to basic config
logging.basicConfig(level=logging.INFO)
## rag_system/document_loader.py
"""
Document loading and preprocessing pipeline.
Handles PDF/TXT files with context-aware chunking.
"""
import os
import re
import logging
from typing import List, Dict, Any, Optional, Iterator
from pathlib import Path
import PyPDF2
import nltk
from nltk.tokenize import sent_tokenize
from dataclasses import dataclass
# Download required NLTK data
try:
nltk.data.find('tokenizers/punkt')
except LookupError:
nltk.download('punkt')
@dataclass
class Document:
"""Represents a processed document."""
content: str
metadata: Dict[str, Any]
source: str
chunk_id: Optional[str] = None
@dataclass
class Chunk:
"""Represents a text chunk."""
text: str
metadata: Dict[str, Any]
source: str
chunk_id: str
start_idx: int
end_idx: int
class DocumentLoader:
"""
High-performance document loader with smart chunking.
Supports PDF and TXT files with context-preserving chunking strategy.
"""
def __init__(self, chunking_config, logger: Optional[logging.Logger] = None):
"""
Initialize document loader.
Args:
chunking_config: Configuration for chunking parameters
logger: Optional logger instance
"""
self.config = chunking_config
self.logger = logger or logging.getLogger(__name__)
def load_documents(self, file_paths: List[str]) -> List[Document]:
"""
Load multiple documents from file paths.
Args:
file_paths: List of file paths to load
Returns:
List of Document objects
Raises:
ValueError: If no valid files found
IOError: If file reading fails
"""
documents = []
if not file_paths:
raise ValueError("No file paths provided")
for file_path in file_paths:
try:
self.logger.info(f"Loading document: {file_path}")
doc = self._load_single_document(file_path)
if doc:
documents.append(doc)
else:
self.logger.warning(f"Failed to load document: {file_path}")
except Exception as e:
self.logger.error(f"Error loading {file_path}: {e}")
continue
if not documents:
raise ValueError("No documents could be loaded successfully")
self.logger.info(f"Successfully loaded {len(documents)} documents")
return documents
def _load_single_document(self, file_path: str) -> Optional[Document]:
"""Load a single document from file path."""
try:
file_path = Path(file_path)
if not file_path.exists():
self.logger.error(f"File not found: {file_path}")
return None
# Determine file type and load accordingly
if file_path.suffix.lower() == '.pdf':
content = self._load_pdf(file_path)
elif file_path.suffix.lower() in ['.txt', '.md']:
content = self._load_text(file_path)
else:
self.logger.warning(f"Unsupported file type: {file_path.suffix}")
return None
if not content or not content.strip():
self.logger.warning(f"Empty content in file: {file_path}")
return None
# Create document with metadata
metadata = {
"filename": file_path.name,
"file_size": file_path.stat().st_size,
"file_type": file_path.suffix.lower(),
"modified_time": file_path.stat().st_mtime
}
return Document(
content=content,
metadata=metadata,
source=str(file_path)
)
except Exception as e:
self.logger.error(f"Failed to load document {file_path}: {e}")
return None
def _load_pdf(self, file_path: Path) -> str:
"""Load content from PDF file."""
try:
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
content = []
for page_num, page in enumerate(pdf_reader.pages):
try:
text = page.extract_text()
if text:
content.append(text)
except Exception as e:
self.logger.warning(f"Failed to extract text from page {page_num} in {file_path}: {e}")
continue
return "\n\n".join(content)
except Exception as e:
self.logger.error(f"Failed to read PDF {file_path}: {e}")
raise IOError(f"Cannot read PDF file: {e}")
def _load_text(self, file_path: Path) -> str:
"""Load content from text file."""
try:
# Try different encodings
encodings = ['utf-8', 'utf-8-sig', 'cp1252', 'iso-8859-1']
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as file:
return file.read()
except UnicodeDecodeError:
continue
raise ValueError("Could not decode file with any supported encoding")
except Exception as e:
self.logger.error(f"Failed to read text file {file_path}: {e}")
raise IOError(f"Cannot read text file: {e}")
def chunk_documents(self, documents: List[Document]) -> List[Chunk]:
"""
Split documents into chunks with context preservation.
Args:
documents: List of Document objects
Returns:
List of Chunk objects
"""
all_chunks = []
for doc in documents:
try:
self.logger.debug(f"Chunking document: {doc.source}")
chunks = self._chunk_document(doc)
all_chunks.extend(chunks)
except Exception as e:
self.logger.error(f"Failed to chunk document {doc.source}: {e}")
continue
self.logger.info(f"Created {len(all_chunks)} chunks from {len(documents)} documents")
return all_chunks
def _chunk_document(self, document: Document) -> List[Chunk]:
"""Chunk a single document with smart splitting."""
text = self._normalize_text(document.content)
if len(text) <= self.config.chunk_size:
# Document is small enough to be a single chunk
return [Chunk(
text=text,
metadata=document.metadata.copy(),
source=document.source,
chunk_id=f"{document.source}_0",
start_idx=0,
end_idx=len(text)
)]
# Use sentence-aware chunking if enabled
if self.config.preserve_sentences:
return self._sentence_aware_chunking(document, text)
else:
return self._simple_chunking(document, text)
def _sentence_aware_chunking(self, document: Document, text: str) -> List[Chunk]:
"""Create chunks while preserving sentence boundaries."""
try:
# Tokenize into sentences
sentences = sent_tokenize(text)
chunks = []
current_chunk = []
current_length = 0
chunk_idx = 0
for sentence in sentences:
sentence_length = len(sentence)
# Check if adding this sentence would exceed chunk size
if (current_length + sentence_length > self.config.chunk_size and
current_chunk and
current_length >= self.config.min_chunk_size):
# Create chunk from current sentences
chunk_text = " ".join(current_chunk)
start_idx = text.find(current_chunk[0])
end_idx = start_idx + len(chunk_text)
chunk = Chunk(
text=chunk_text,
metadata=document.metadata.copy(),
source=document.source,
chunk_id=f"{document.source}_{chunk_idx}",
start_idx=start_idx,
end_idx=end_idx
)
chunks.append(chunk)
# Handle overlap
if self.config.chunk_overlap > 0:
overlap_text = chunk_text[-self.config.chunk_overlap:]
overlap_sentences = [s for s in current_chunk
if any(word in s for word in overlap_text.split())]
current_chunk = overlap_sentences[-2:] if len(overlap_sentences) > 1 else []
current_length = sum(len(s) for s in current_chunk)
else:
current_chunk = []
current_length = 0
chunk_idx += 1
# Add sentence to current chunk
current_chunk.append(sentence)
current_length += sentence_length
# Handle remaining sentences
if current_chunk and current_length >= self.config.min_chunk_size:
chunk_text = " ".join(current_chunk)
start_idx = text.find(current_chunk[0])
end_idx = start_idx + len(chunk_text)
chunk = Chunk(
text=chunk_text,
metadata=document.metadata.copy(),
source=document.source,
chunk_id=f"{document.source}_{chunk_idx}",
start_idx=start_idx,
end_idx=end_idx
)
chunks.append(chunk)
return chunks
except Exception as e:
self.logger.warning(f"Sentence-aware chunking failed: {e}, falling back to simple chunking")
return self._simple_chunking(document, text)
def _simple_chunking(self, document: Document, text: str) -> List[Chunk]:
"""Create chunks with simple character-based splitting."""
chunks = []
start_idx = 0
chunk_idx = 0
while start_idx < len(text):
end_idx = min(start_idx + self.config.chunk_size, len(text))
# Adjust end_idx to avoid splitting words
if end_idx < len(text):
while end_idx > start_idx and not text[end_idx].isspace():
end_idx -= 1
if end_idx == start_idx: # Fallback if no space found
end_idx = start_idx + self.config.chunk_size
chunk_text = text[start_idx:end_idx].strip()
if len(chunk_text) >= self.config.min_chunk_size:
chunk = Chunk(
text=chunk_text,
metadata=document.metadata.copy(),
source=document.source,
chunk_id=f"{document.source}_{chunk_idx}",
start_idx=start_idx,
end_idx=end_idx
)
chunks.append(chunk)
chunk_idx += 1
# Move to next chunk with overlap
start_idx = max(end_idx - self.config.chunk_overlap, start_idx + 1)
return chunks
def _normalize_text(self, text: str) -> str:
"""Normalize text for better processing."""
if not text:
return ""
# Remove excessive whitespace
text = re.sub(r'\s+', ' ', text)
# Remove special characters that might interfere with processing
text = re.sub(r'[\x00-\x08\x0b\x0c\x0e-\x1f\x7f-\x9f]', '', text)
# Normalize line breaks
text = re.sub(r'\r\n|\r', '\n', text)
return text.strip()
## rag_system/embedding.py
"""
Embedding model management with multilingual support.
Handles text vectorization using state-of-the-art models.
"""
import os
import logging
import numpy as np
import torch
from typing import List, Dict, Any, Optional, Union
from transformers import AutoTokenizer, AutoModel
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
class EmbeddingModel:
"""
High-performance embedding model with GPU support and batch processing.
Uses multilingual-e5-base for robust multilingual text representation.
"""
def __init__(self, config, logger: Optional[logging.Logger] = None):
"""
Initialize embedding model.
Args:
config: Embedding configuration
logger: Optional logger instance
"""
self.config = config
self.logger = logger or logging.getLogger(__name__)
self.device = self._setup_device()
self.model = None
self.tokenizer = None
self._lock = threading.Lock()
self._load_model()
def _setup_device(self) -> torch.device:
"""Setup computation device (CPU/GPU)."""
try:
if self.config.device == "auto":
if torch.cuda.is_available():
device = torch.device("cuda")
self.logger.info(f"Using GPU: {torch.cuda.get_device_name()}")
else:
device = torch.device("cpu")
self.logger.info("Using CPU for embeddings")
else:
device = torch.device(self.config.device)
self.logger.info(f"Using specified device: {device}")
return device
except Exception as e:
self.logger.warning(f"Failed to setup device: {e}, falling back to CPU")
return torch.device("cpu")
def _load_model(self) -> None:
"""Load the embedding model and tokenizer."""
try:
self.logger.info(f"Loading embedding model: {self.config.model_name}")
# Load tokenizer
self.tokenizer = AutoTokenizer.from_pretrained(
self.config.model_name,
cache_dir="./model_cache"
)
# Load model
self.model = AutoModel.from_pretrained(
self.config.model_name,
cache_dir="./model_cache"
)
# Move to device
self.model.to(self.device)
self.model.eval()
self.logger.info("Embedding model loaded successfully")
except Exception as e:
self.logger.error(f"Failed to load embedding model: {e}")
raise RuntimeError(f"Cannot load embedding model: {e}")
def encode_texts(self, texts: List[str], show_progress: bool = True) -> np.ndarray:
"""
Encode multiple texts into embeddings.
Args:
texts: List of texts to encode
show_progress: Whether to show progress bar
Returns:
numpy array of embeddings with shape (n_texts, embedding_dim)
Raises:
ValueError: If texts list is empty
RuntimeError: If encoding fails
"""
if not texts:
raise ValueError("Empty texts list provided")
try:
self.logger.info(f"Encoding {len(texts)} texts")
all_embeddings = []
# Process in batches
batches = [texts[i:i + self.config.batch_size]
for i in range(0, len(texts), self.config.batch_size)]
if show_progress:
batches = tqdm(batches, desc="Encoding batches")
with torch.no_grad():
for batch in batches:
try:
batch_embeddings = self._encode_batch(batch)
all_embeddings.append(batch_embeddings)
except Exception as e:
self.logger.error(f"Failed to encode batch: {e}")
# Create zero embeddings for failed batch
zero_embeddings = np.zeros((len(batch), 768)) # e5-base dimension
all_embeddings.append(zero_embeddings)
# Concatenate all embeddings
embeddings = np.vstack(all_embeddings)
self.logger.info(f"Successfully encoded {len(texts)} texts to embeddings of shape {embeddings.shape}")
return embeddings
except Exception as e:
self.logger.error(f"Failed to encode texts: {e}")
raise RuntimeError(f"Text encoding failed: {e}")
def _encode_batch(self, texts: List[str]) -> np.ndarray:
"""Encode a batch of texts."""
with self._lock:
try:
# Tokenize
inputs = self.tokenizer(
texts,
padding=True,
truncation=True,
max_length=self.config.max_length,
return_tensors="pt"
)
# Move to device
inputs = {k: v.to(self.device) for k, v in inputs.items()}
# Get embeddings
outputs = self.model(**inputs)
# Use mean pooling over token embeddings
embeddings = self._mean_pooling(outputs, inputs['attention_mask'])
# Normalize if configured
if self.config.normalize_embeddings:
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
return embeddings.cpu().numpy()
except Exception as e:
self.logger.error(f"Batch encoding failed: {e}")
raise
def _mean_pooling(self, model_output, attention_mask):
"""Perform mean pooling on token embeddings."""
token_embeddings = model_output[0] # First element contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
def encode_single(self, text: str) -> np.ndarray:
"""
Encode a single text into embedding.
Args:
text: Text to encode
Returns:
numpy array of embedding with shape (embedding_dim,)
"""
if not text:
raise ValueError("Empty text provided")
embeddings = self.encode_texts([text], show_progress=False)
return embeddings[0]
def get_embedding_dimension(self) -> int:
"""Get the dimension of embeddings produced by this model."""
try:
# For e5-base models, the dimension is typically 768
test_embedding = self.encode_single("test")
return test_embedding.shape[0]
except Exception as e:
self.logger.warning(f"Could not determine embedding dimension: {e}")
return 768 # Default for e5-base
def compute_similarity(self, embedding1: np.ndarray, embedding2: np.ndarray) -> float:
"""
Compute cosine similarity between two embeddings.
Args:
embedding1: First embedding vector
embedding2: Second embedding vector
Returns:
Cosine similarity score
"""
try:
# Ensure embeddings are normalized
norm1 = np.linalg.norm(embedding1)
norm2 = np.linalg.norm(embedding2)
if norm1 == 0 or norm2 == 0:
return 0.0
return np.dot(embedding1, embedding2) / (norm1 * norm2)
except Exception as e:
self.logger.error(f"Failed to compute similarity: {e}")
return 0.0
def get_model_info(self) -> Dict[str, Any]:
"""Get information about the loaded model."""
return {
"model_name": self.config.model_name,
"device": str(self.device),
"max_length": self.config.max_length,
"batch_size": self.config.batch_size,
"normalize_embeddings": self.config.normalize_embeddings,
"embedding_dimension": self.get_embedding_dimension()
}
## rag_system/faiss_index.py
"""
FAISS index management for efficient similarity search.
Handles index creation, persistence, and high-performance retrieval.
"""
import os
import pickle
import logging
import numpy as np
import faiss
from typing import List, Dict, Any, Optional, Tuple
from pathlib import Path
import threading
class FAISSIndex:
"""
High-performance FAISS index manager with GPU support.
Provides efficient similarity search with various index types and optimization.
"""
def __init__(self, config, logger: Optional[logging.Logger] = None):
"""
Initialize FAISS index manager.
Args:
config: FAISS configuration
logger: Optional logger instance
"""
self.config = config
self.logger = logger or logging.getLogger(__name__)
self.index = None
self.metadata = []
self.dimension = None
self._lock = threading.Lock()
# Setup GPU if available and requested
self.use_gpu = self.config.use_gpu and faiss.get_num_gpus() > 0
if self.use_gpu:
self.logger.info(f"GPU support enabled, using GPU {self.config.gpu_id}")
else:
self.logger.info("Using CPU for FAISS index")
def build_index(self, embeddings: np.ndarray, metadata: List[Dict[str, Any]]) -> None:
"""
Build FAISS index from embeddings.
Args:
embeddings: Array of embeddings with shape (n_items, embedding_dim)
metadata: List of metadata dictionaries for each embedding
Raises:
ValueError: If embeddings and metadata lengths don't match
RuntimeError: If index building fails
"""
if len(embeddings) != len(metadata):
raise ValueError("Embeddings and metadata must have same length")
if len(embeddings) == 0:
raise ValueError("Cannot build index from empty embeddings")
try:
self.logger.info(f"Building FAISS index for {len(embeddings)} embeddings")
with self._lock:
self.dimension = embeddings.shape[1]
self.metadata = metadata.copy()
# Ensure embeddings are float32 and C-contiguous
embeddings = np.ascontiguousarray(embeddings.astype(np.float32))
# Create appropriate index
self.index = self._create_index(embeddings)
# Add embeddings to index
self.index.add(embeddings)
self.logger.info(f"Successfully built FAISS index with {self.index.ntotal} vectors")
except Exception as e:
self.logger.error(f"Failed to build FAISS index: {e}")
raise
プロンプト
## タスクの詳細
Pythonでローカル環境で動作する高性能なRAG(Retrieval-Augmented Generation)システムをゼロから
comprehensiveにdeep diveして実装してください。
実装は産業レベルの完成度を目指し、学術的な深さと実用的な堅牢性を兼ね備えたものにしてください。
## 技術要件
### コアコンポーネント
1. **ベクトルデータベース**: FAISSを活用した効率的な類似度検索
2. **エンベッディングモデル**: `intfloat/multilingual-e5-base`を使用
3. **チャンキング機構**: 文脈を保持したスマートな文章分割
4. **検索インターフェース**: マルチスレッド対応の検索関数
### 品質基準
- エラーハンドリング: 全ての主要操作にtry-catchブロックを実装
- ロギング: 詳細な実行ログをファイル出力 (DEBUG/INFO/ERRORレベル)
- パフォーマンス: 大規模データセットに対応可能な最適化
- 拡張性: モジュール設計による機能追加の容易性
## 実装ガイドライン
### 必須機能
1. ドキュメントの前処理パイプライン
- PDF/TXTファイルの読み込み
- 文脈を考慮したチャンキング (オーバーラップ処理含む)
- テキスト正規化
2. FAISSインデックス構築
- インデックスの作成と保存
- メトリック選択 (コサイン類似度)
- インデックスのロード機構
3. 検索システム
- マルチクエリ検索
- スコア閾値フィルタリング
- 検索結果のランキング
4. ユーティリティ
- プログレスバー表示
- メモリ使用量モニタリング
- 設定ファイル管理
### コード品質
- PEP 8厳格遵守 (型ヒント含む)
- docstringによるAPIドキュメンテーション (Googleスタイル)
- 単体テスト容易な設計
- 設定可能なパラメータ群
## 出力形式
完全なPythonパッケージ構造で出力:
/rag_system
│── init.py
│── config.py # 設定管理
│── document_loader.py # ドキュメント処理
│── embedding.py # エンベッディング処理
│── faiss_index.py # FAISS操作
│── retriever.py # 検索メインロジック
│── utils.py # 補助機能
└── tests/ # 単体テスト
システムプロンプトの特徴に従い、タスクの詳細、技術要件、コアコンポーネント、
品質基準、実装ガイドライン、必須機能、コード品質、出力形式、追加指示のセクションをで
それぞれ期待する設計に落とし込み指示をする。
- 産業レベルの実装を要求し、単なる実験コードではないと指示する。
- 具体的に使用してほしいライブラリの指定やコーディングルールを意識させる
- マルチリンガル対応や、GPU利用など実際に想定される要素を包含
- さらに、テストや設定管理といった観点を意識させる
- 具体的なファイル構造を指定することで、体系的な出力を誘導する
約900行程度のコードをわずか1分程度で出力してくれる
評価
- モジュール化されており、各コンポーネントが明確に分離されている
- 型ヒントを適切に使用し、コードの可読性、メンテナンス性が高い
- エラーハンドリングが徹底されており、堅牢な設計
- 設定管理が系統的に行われており、柔軟性がある
- ドキュメントが詳細で使用法が理解しやすい
- マルチスレッド/GPUサポートがされており、パフォーマンス最適化がされている
改善可能な点
- 必要に応じてテストコードを実装させるようにプロンプトを修正する
- 依存関係の管理を明確にする
以下のRAGシステムに対して、包括的なテストスイートをPythonで作成してください。
テストにはunittestフレームワークを使用し、以下の要件を満たすようにしてください。
### テストの基本要件
1. 単体テストと統合テストの両方を含める
2. テストは`tests`ディレクトリにモジュールごとに整理する
3. テストのセットアップとティアダウンを適切に実装する
4. モックオブジェクトを使用して外部依存関係を隔離する
5. カバレッジ率80%以上を目標とする
### テスト対象モジュールごとの詳細要件
#### 1. config.py のテスト
- 設定のロードと保存が正しく機能するか
- デフォルト値が適切に設定されるか
- 不正な設定値に対して適切に例外が発生するか
- ロギング設定が正しく適用されるか
- 環境変数からの設定読み込み(追加実装が必要な場合)
#### 2. document_loader.py のテスト
- PDFとテキストファイルの読み込み機能
- チャンキングアルゴリズムの正確性(文の境界を保持しているか)
- メタデータが正しく保持されているか
- 不正なファイル形式に対するエラーハンドリング
- 大規模ファイルの処理能力(パフォーマンステスト)
#### 3. embedding.py のテスト
- 埋め込みモデルの正しい初期化
- テキストのバッチエンコードが正しく機能するか
- 類似度計算の正確性(既知の値との比較)
- GPU利用時の挙動(利用可能な場合)
- 空の入力や不正な入力に対する頑健性
#### 4. faiss_index.py のテスト
- インデックスの構築と検索機能
- メタデータの関連付けが正しく行われるか
- 近傍探索の正確性(既知のデータセットで検証)
- GPU使用時の挙動(利用可能な場合)
- インデックスの永続化(保存と読み込み)
### 統合テスト要件
1. 完全なRAGパイプラインのエンドツーエンドテスト
- ドキュメント読み込み → チャンキング → 埋め込み → インデックス作成 → 検索
2. マルチスレッド/マルチプロセス環境での動作
3. 実際のサンプルデータを使用した現実的なシナリオ
### テストデータ戦略
- 小さな制御されたテストデータセット(tests/test_dataに配置)
- 実際のデータを模した合成データ生成
- パフォーマンステスト用の大規模データセット(オプション)
### テスト実行環境のセットアップ
1. pytestを使用してテストを実行できるようにする
2. カバレッジレポートを生成する
3. GitHub ActionsなどCI/CDパイプラインと統合できるようにする
### 期待する出力
1. 各モジュールの完全なテストコード
2. テストデータセット
3. pytestの設定ファイル
4. カバレッジレポート生成の設定
5. CI/CD統合のための基本的なワークフローファイル(オプション)
テストコードは、エッジケースやエラーハンドリングを特に重視し、本番環境での堅牢性を検証できるようにしてください。
追加されたテストコード
# RAG System Comprehensive Test Suite
## tests/__init__.py
"""
RAG System Test Suite
Comprehensive testing for all RAG system components.
"""
import sys
import os
from pathlib import Path
# Add the parent directory to the path to import rag_system
test_dir = Path(__file__).parent
project_root = test_dir.parent
sys.path.insert(0, str(project_root))
## tests/conftest.py
"""
Pytest configuration and fixtures.
"""
import pytest
import tempfile
import shutil
import os
import json
import numpy as np
from pathlib import Path
from unittest.mock import Mock, MagicMock
from dataclasses import asdict
# Import configurations
from rag_system.config import (
EmbeddingConfig, ChunkingConfig, FAISSConfig,
SearchConfig, SystemConfig, ConfigManager
)
from rag_system.document_loader import Document, Chunk
from rag_system.embedding import EmbeddingModel
from rag_system.faiss_index import FAISSIndex
@pytest.fixture(scope="session")
def test_data_dir():
"""Create a temporary directory for test data."""
temp_dir = tempfile.mkdtemp(prefix="rag_test_")
yield Path(temp_dir)
shutil.rmtree(temp_dir, ignore_errors=True)
@pytest.fixture
def sample_config():
"""Create a sample configuration for testing."""
return SystemConfig(
embedding=EmbeddingConfig(
model_name="sentence-transformers/all-MiniLM-L6-v2",
device="cpu",
batch_size=4
),
chunking=ChunkingConfig(
chunk_size=100,
chunk_overlap=20,
min_chunk_size=30
),
faiss=FAISSConfig(
index_type="IndexFlatIP",
use_gpu=False
),
search=SearchConfig(
top_k=5,
score_threshold=0.1
)
)
@pytest.fixture
def sample_documents():
"""Create sample documents for testing."""
return [
Document(
content="This is the first test document. It contains some sample text for testing purposes.",
metadata={"filename": "doc1.txt", "file_size": 100},
source="/test/doc1.txt"
),
Document(
content="This is the second test document. It has different content to test chunking and embedding.",
metadata={"filename": "doc2.txt", "file_size": 120},
source="/test/doc2.txt"
)
]
@pytest.fixture
def sample_chunks():
"""Create sample chunks for testing."""
return [
Chunk(
text="This is the first chunk of text.",
metadata={"filename": "doc1.txt"},
source="/test/doc1.txt",
chunk_id="doc1_0",
start_idx=0,
end_idx=33
),
Chunk(
text="This is the second chunk of text.",
metadata={"filename": "doc1.txt"},
source="/test/doc1.txt",
chunk_id="doc1_1",
start_idx=20,
end_idx=54
)
]
@pytest.fixture
def sample_embeddings():
"""Create sample embeddings for testing."""
np.random.seed(42)
return np.random.randn(10, 384).astype(np.float32)
@pytest.fixture
def mock_embedding_model():
"""Create a mock embedding model."""
mock = Mock(spec=EmbeddingModel)
mock.get_embedding_dimension.return_value = 384
mock.encode_texts.return_value = np.random.randn(2, 384).astype(np.float32)
mock.encode_single.return_value = np.random.randn(384).astype(np.float32)
return mock
@pytest.fixture
def create_test_files(test_data_dir):
"""Create test files for document loading tests."""
def _create_files():
# Create text files
text_file = test_data_dir / "sample.txt"
text_file.write_text("This is a sample text file for testing.", encoding='utf-8')
# Create a simple PDF-like file (for testing purposes)
pdf_file = test_data_dir / "sample.pdf"
pdf_file.write_bytes(b"%PDF-1.4\nSample PDF content for testing")
# Create markdown file
md_file = test_data_dir / "sample.md"
md_file.write_text("# Sample Markdown\n\nThis is markdown content.", encoding='utf-8')
return {
'txt': str(text_file),
'pdf': str(pdf_file),
'md': str(md_file)
}
return _create_files
## tests/test_config.py
"""
Tests for configuration management.
"""
import unittest
import tempfile
import json
import logging
from pathlib import Path
from unittest.mock import patch, mock_open
from rag_system.config import (
EmbeddingConfig, ChunkingConfig, FAISSConfig,
SearchConfig, SystemConfig, ConfigManager
)
class TestEmbeddingConfig(unittest.TestCase):
"""Test EmbeddingConfig dataclass."""
def test_default_values(self):
"""Test default configuration values."""
config = EmbeddingConfig()
self.assertEqual(config.model_name, "intfloat/multilingual-e5-base")
self.assertEqual(config.device, "auto")
self.assertEqual(config.max_length, 512)
self.assertEqual(config.batch_size, 32)
self.assertTrue(config.normalize_embeddings)
def test_custom_values(self):
"""Test custom configuration values."""
config = EmbeddingConfig(
model_name="custom-model",
device="cpu",
batch_size=16
)
self.assertEqual(config.model_name, "custom-model")
self.assertEqual(config.device, "cpu")
self.assertEqual(config.batch_size, 16)
class TestChunkingConfig(unittest.TestCase):
"""Test ChunkingConfig dataclass."""
def test_default_values(self):
"""Test default chunking configuration."""
config = ChunkingConfig()
self.assertEqual(config.chunk_size, 512)
self.assertEqual(config.chunk_overlap, 50)
self.assertEqual(config.min_chunk_size, 50)
self.assertTrue(config.preserve_sentences)
self.assertEqual(config.language, "multilingual")
class TestConfigManager(unittest.TestCase):
"""Test ConfigManager class."""
def setUp(self):
"""Set up test environment."""
self.temp_dir = Path(tempfile.mkdtemp())
self.config_path = self.temp_dir / "test_config.json"
def tearDown(self):
"""Clean up test environment."""
import shutil
shutil.rmtree(self.temp_dir, ignore_errors=True)
def test_load_default_config(self):
"""Test loading default configuration when no file exists."""
manager = ConfigManager(str(self.config_path))
self.assertIsInstance(manager.config, SystemConfig)
self.assertIsInstance(manager.config.embedding, EmbeddingConfig)
self.assertTrue(self.config_path.exists())
def test_save_and_load_config(self):
"""Test saving and loading configuration."""
# Create custom config
custom_config = SystemConfig(
embedding=EmbeddingConfig(model_name="test-model"),
chunking=ChunkingConfig(chunk_size=256),
faiss=FAISSConfig(use_gpu=True),
search=SearchConfig(top_k=20)
)
# Save config
manager = ConfigManager(str(self.config_path))
manager.save_config(custom_config)
# Load config
new_manager = ConfigManager(str(self.config_path))
self.assertEqual(new_manager.config.embedding.model_name, "test-model")
self.assertEqual(new_manager.config.chunking.chunk_size, 256)
self.assertTrue(new_manager.config.faiss.use_gpu)
self.assertEqual(new_manager.config.search.top_k, 20)
def test_invalid_config_file(self):
"""Test handling of invalid configuration file."""
# Create invalid JSON file
self.config_path.write_text("invalid json content")
# Should fall back to default config
manager = ConfigManager(str(self.config_path))
self.assertIsInstance(manager.config, SystemConfig)
def test_dict_to_config_conversion(self):
"""Test dictionary to configuration conversion."""
config_dict = {
"embedding": {"model_name": "test-model", "batch_size": 16},
"chunking": {"chunk_size": 256},
"faiss": {"use_gpu": True},
"search": {"top_k": 15},
"data_dir": "./custom_data"
}
manager = ConfigManager(str(self.config_path))
config = manager._dict_to_config(config_dict)
self.assertEqual(config.embedding.model_name, "test-model")
self.assertEqual(config.embedding.batch_size, 16)
self.assertEqual(config.chunking.chunk_size, 256)
self.assertTrue(config.faiss.use_gpu)
self.assertEqual(config.search.top_k, 15)
self.assertEqual(config.data_dir, "./custom_data")
def test_logging_setup(self):
"""Test logging configuration setup."""
with patch('logging.basicConfig') as mock_basic_config:
manager = ConfigManager(str(self.config_path))
mock_basic_config.assert_called()
## tests/test_document_loader.py
"""
Tests for document loading and chunking functionality.
"""
import unittest
import tempfile
import shutil
from pathlib import Path
from unittest.mock import Mock, patch, mock_open
import PyPDF2
from rag_system.document_loader import DocumentLoader, Document, Chunk
from rag_system.config import ChunkingConfig
class TestDocumentLoader(unittest.TestCase):
"""Test DocumentLoader class."""
def setUp(self):
"""Set up test environment."""
self.temp_dir = Path(tempfile.mkdtemp())
self.config = ChunkingConfig(
chunk_size=100,
chunk_overlap=20,
min_chunk_size=30,
preserve_sentences=True
)
self.loader = DocumentLoader(self.config)
# Create test files
self.text_file = self.temp_dir / "test.txt"
self.text_file.write_text("This is a test document. It has multiple sentences. This should be chunked properly.", encoding='utf-8')
self.pdf_file = self.temp_dir / "test.pdf"
# Create a minimal PDF structure for testing
self.pdf_file.write_bytes(b"%PDF-1.4\n")
def tearDown(self):
"""Clean up test environment."""
shutil.rmtree(self.temp_dir, ignore_errors=True)
def test_load_text_file(self):
"""Test loading text file."""
doc = self.loader._load_single_document(str(self.text_file))
self.assertIsNotNone(doc)
self.assertIn("test document", doc.content)
self.assertEqual(doc.metadata["filename"], "test.txt")
self.assertEqual(doc.source, str(self.text_file))
def test_load_nonexistent_file(self):
"""Test loading non-existent file."""
doc = self.loader._load_single_document("nonexistent.txt")
self.assertIsNone(doc)
def test_load_unsupported_file_type(self):
"""Test loading unsupported file type."""
unsupported_file = self.temp_dir / "test.xyz"
unsupported_file.write_text("content")
doc = self.loader._load_single_document(str(unsupported_file))
self.assertIsNone(doc)
@patch('PyPDF2.PdfReader')
def test_load_pdf_file(self, mock_pdf_reader):
"""Test loading PDF file."""
# Mock PDF reader
mock_page = Mock()
mock_page.extract_text.return_value = "Sample PDF content"
mock_reader_instance = Mock()
mock_reader_instance.pages = [mock_page]
mock_pdf_reader.return_value = mock_reader_instance
doc = self.loader._load_single_document(str(self.pdf_file))
self.assertIsNotNone(doc)
self.assertEqual(doc.content, "Sample PDF content")
self.assertEqual(doc.metadata["file_type"], ".pdf")
def test_load_multiple_documents(self):
"""Test loading multiple documents."""
docs = self.loader.load_documents([str(self.text_file)])
self.assertEqual(len(docs), 1)
self.assertIsInstance(docs[0], Document)
def test_load_empty_file_list(self):
"""Test loading empty file list."""
with self.assertRaises(ValueError):
self.loader.load_documents([])
def test_normalize_text(self):
"""Test text normalization."""
messy_text = " This has excessive whitespace \n\n\n "
normalized = self.loader._normalize_text(messy_text)
self.assertEqual(normalized, "This has excessive whitespace")
def test_simple_chunking(self):
"""Test simple character-based chunking."""
doc = Document(
content="A" * 300, # Long content to force chunking
metadata={"test": True},
source="test"
)
chunks = self.loader._simple_chunking(doc, doc.content)
self.assertGreater(len(chunks), 1)
self.assertLessEqual(len(chunks[0].text), self.config.chunk_size)
# Check overlap
if len(chunks) > 1:
# There should be some overlap between consecutive chunks
self.assertTrue(len(chunks[0].text) + len(chunks[1].text) >
chunks[0].end_idx - chunks[0].start_idx +
chunks[1].end_idx - chunks[1].start_idx)
@patch('nltk.tokenize.sent_tokenize')
def test_sentence_aware_chunking(self, mock_sent_tokenize):
"""Test sentence-aware chunking."""
sentences = [
"This is the first sentence.",
"This is the second sentence.",
"This is the third sentence.",
"This is the fourth sentence."
]
mock_sent_tokenize.return_value = sentences
doc = Document(
content=" ".join(sentences),
metadata={"test": True},
source="test"
)
chunks = self.loader._sentence_aware_chunking(doc, doc.content)
self.assertGreater(len(chunks), 0)
# Each chunk should end with a complete sentence
for chunk in chunks:
self.assertTrue(chunk.text.endswith('.'))
def test_chunk_documents(self):
"""Test chunking multiple documents."""
docs = [
Document(
content="Short document.",
metadata={"id": 1},
source="doc1"
),
Document(
content="This is a longer document that should be split into multiple chunks because it exceeds the maximum chunk size that we have configured.",
metadata={"id": 2},
source="doc2"
)
]
chunks = self.loader.chunk_documents(docs)
self.assertGreater(len(chunks), len(docs)) # Should have more chunks than docs
# Check that all chunks have required fields
for chunk in chunks:
self.assertIsInstance(chunk, Chunk)
self.assertIsNotNone(chunk.text)
self.assertIsNotNone(chunk.chunk_id)
self.assertIsNotNone(chunk.metadata)
def test_encoding_error_handling(self):
"""Test handling of encoding errors."""
# Create file with problematic encoding
problematic_file = self.temp_dir / "problematic.txt"
with open(problematic_file, 'wb') as f:
f.write(b'\xff\xfe\x00\x00') # Invalid UTF-8
# Should handle encoding errors gracefully
doc = self.loader._load_single_document(str(problematic_file))
# Depending on implementation, might return None or empty content
class TestDocument(unittest.TestCase):
"""Test Document dataclass."""
def test_document_creation(self):
"""Test document creation."""
doc = Document(
content="test content",
metadata={"key": "value"},
source="test_source"
)
self.assertEqual(doc.content, "test content")
self.assertEqual(doc.metadata["key"], "value")
self.assertEqual(doc.source, "test_source")
self.assertIsNone(doc.chunk_id)
class TestChunk(unittest.TestCase):
"""Test Chunk dataclass."""
def test_chunk_creation(self):
"""Test chunk creation."""
chunk = Chunk(
text="chunk text",
metadata={"key": "value"},
source="test_source",
chunk_id="chunk_1",
start_idx=0,
end_idx=10
)
self.assertEqual(chunk.text, "chunk text")
self.assertEqual(chunk.chunk_id, "chunk_1")
self.assertEqual(chunk.start_idx, 0)
self.assertEqual(chunk.end_idx, 10)
## tests/test_embedding.py
"""
Tests for embedding functionality.
"""
import unittest
import numpy as np
import torch
from unittest.mock import Mock, patch, MagicMock
from rag_system.embedding import EmbeddingModel
from rag_system.config import EmbeddingConfig
class TestEmbeddingModel(unittest.TestCase):
"""Test EmbeddingModel class."""
def setUp(self):
"""Set up test environment."""
self.config = EmbeddingConfig(
model_name="sentence-transformers/all-MiniLM-L6-v2",
device="cpu",
batch_size=2,
max_length=128,
normalize_embeddings=True
)
@patch('rag_system.embedding.AutoTokenizer')
@patch('rag_system.embedding.AutoModel')
def test_model_initialization(self, mock_model, mock_tokenizer):
"""Test model initialization."""
# Setup mocks
mock_tokenizer_instance = Mock()
mock_model_instance = Mock()
mock_tokenizer.from_pretrained.return_value = mock_tokenizer_instance
mock_model.from_pretrained.return_value = mock_model_instance
# Test initialization
embedding_model = EmbeddingModel(self.config)
self.assertIsNotNone(embedding_model.model)
self.assertIsNotNone(embedding_model.tokenizer)
mock_tokenizer.from_pretrained.assert_called_once()
mock_model.from_pretrained.assert_called_once()
@patch('torch.cuda.is_available')
def test_device_setup_gpu_available(self, mock_cuda_available):
"""Test device setup when GPU is available."""
mock_cuda_available.return_value = True
config = EmbeddingConfig(device="auto")
with patch('rag_system.embedding.AutoTokenizer'), \
patch('rag_system.embedding.AutoModel'):
embedding_model = EmbeddingModel(config)
# Device should be set based on availability
self.assertIsNotNone(embedding_model.device)
@patch('torch.cuda.is_available')
def test_device_setup_cpu_only(self, mock_cuda_available):
"""Test device setup for CPU only."""
mock_cuda_available.return_value = False
config = EmbeddingConfig(device="auto")
with patch('rag_system.embedding.AutoTokenizer'), \
patch('rag_system.embedding.AutoModel'):
embedding_model = EmbeddingModel(config)
self.assertEqual(str(embedding_model.device), "cpu")
def test_mean_pooling(self):
"""Test mean pooling function."""
with patch('rag_system.embedding.AutoTokenizer'), \
patch('rag_system.embedding.AutoModel'):
embedding_model = EmbeddingModel(self.config)
# Create mock model output
batch_size, seq_len, hidden_size = 2, 5, 10
token_embeddings = torch.randn(batch_size, seq_len, hidden_size)
attention_mask = torch.ones(batch_size, seq_len)
model_output = [token_embeddings]
result = embedding_model._mean_pooling(model_output, attention_mask)
self.assertEqual(result.shape, (batch_size, hidden_size))
@patch('rag_system.embedding.AutoTokenizer')
@patch('rag_system.embedding.AutoModel')
def test_encode_single_text(self, mock_model, mock_tokenizer):
"""Test encoding single text."""
# Setup mocks
mock_tokenizer_instance = Mock()
mock_model_instance = Mock()
mock_tokenizer.from_pretrained.return_value = mock_tokenizer_instance
mock_model.from_pretrained.return_value = mock_model_instance
# Mock tokenizer output
mock_tokenizer_instance.return_value = {
'input_ids': torch.tensor([[1, 2, 3]]),
'attention_mask': torch.tensor([[1, 1, 1]])
}
# Mock model output
mock_outputs = [torch.randn(1, 3, 384)] # batch_size=1, seq_len=3, hidden_size=384
mock_model_instance.return_value = mock_outputs
embedding_model = EmbeddingModel(self.config)
# Test single text encoding
text = "This is a test sentence."
embedding = embedding_model.encode_single(text)
self.assertEqual(embedding.shape, (384,))
self.assertIsInstance(embedding, np.ndarray)
def test_encode_empty_text(self):
"""Test encoding empty text."""
with patch('rag_system.embedding.AutoTokenizer'), \
patch('rag_system.embedding.AutoModel'):
embedding_model = EmbeddingModel(self.config)
with self.assertRaises(ValueError):
embedding_model.encode_single("")
def test_encode_empty_text_list(self):
"""Test encoding empty text list."""
with patch('rag_system.embedding.AutoTokenizer'), \
patch('rag_system.embedding.AutoModel'):
embedding_model = EmbeddingModel(self.config)
with self.assertRaises(ValueError):
embedding_model.encode_texts([])
def test_compute_similarity(self):
"""Test similarity computation."""
with patch('rag_system.embedding.AutoTokenizer'), \
patch('rag_system.embedding.AutoModel'):
embedding_model = EmbeddingModel(self.config)
# Test with identical vectors
vec1 = np.array([1.0, 0.0, 0.0])
vec2 = np.array([1.0, 0.0, 0.0])
similarity = embedding_model.compute_similarity(vec1, vec2)
self.assertAlmostEqual(similarity, 1.0, places=5)
# Test with orthogonal vectors
vec1 = np.array([1.0, 0.0, 0.0])
vec2 = np.array([0.0, 1.0, 0.0])
similarity = embedding_model.compute_similarity(vec1, vec2)
self.assertAlmostEqual(similarity, 0.0, places=5)
# Test with zero vectors
vec1 = np.array([0.0, 0.0, 0.0])
vec2 = np.array([1.0, 0.0, 0.0])
similarity = embedding_model.compute_similarity(vec1, vec2)
self.assertEqual(similarity, 0.0)
@patch('rag_system.embedding.AutoTokenizer')
@patch('rag_system.embedding.AutoModel')
def test_get_embedding_dimension(self, mock_model, mock_tokenizer):
"""Test getting embedding dimension."""
# Setup mocks to return specific dimension
mock_tokenizer_instance = Mock()
mock_model_instance = Mock()
mock_tokenizer.from_pretrained.return_value = mock_tokenizer_instance
mock_model.from_pretrained.return_value = mock_model_instance
# Mock the encode_single method to return specific dimension
with patch.object(EmbeddingModel, 'encode_single') as mock_encode:
mock_encode.return_value = np.zeros(384)
embedding_model = EmbeddingModel(self.config)
dimension = embedding_model.get_embedding_dimension()
self.assertEqual(dimension, 384)
def test_get_model_info(self):
"""Test getting model information."""
with patch('rag_system.embedding.AutoTokenizer'), \
patch('rag_system.embedding.AutoModel'), \
patch.object(EmbeddingModel, 'get_embedding_dimension') as mock_dim:
mock_dim.return_value = 384
embedding_model = EmbeddingModel(self.config)
info = embedding_model.get_model_info()
self.assertIn("model_name", info)
self.assertIn("device", info)
self.assertIn("embedding_dimension", info)
self.assertEqual(info["embedding_dimension"], 384)
## tests/test_faiss_index.py
"""
Tests for FAISS index functionality.
"""
import unittest
import numpy as np
import tempfile
import shutil
from pathlib import Path
from unittest.mock import Mock, patch, MagicMock
import faiss
from rag_system.faiss_index import FAISSIndex
from rag_system.config import FAISSConfig
class TestFAISSIndex(unittest.TestCase):
"""Test FAISSIndex class."""
def setUp(self):
"""Set up test environment."""
self.temp_dir = Path(tempfile.mkdtemp())
self.config = FAISSConfig(
index_type="IndexFlatIP",
use_gpu=False,
nlist=4,
nprobe=2
)
self.faiss_index = FAISSIndex(self.config)
# Create sample data
np.random.seed(42)
self.sample_embeddings = np.random.randn(10, 64).astype(np.float32)
self.sample_metadata = [
{"id": i, "text": f"sample_text_{i}"}
for i in range(10)
]
def tearDown(self):
"""Clean up test environment."""
shutil.rmtree(self.temp_dir, ignore_errors=True)
def test_build_index_success(self):
"""Test successful index building."""
self.faiss_index.build_index(self.sample_embeddings, self.sample_metadata)
self.assertIsNotNone(self.faiss_index.index)
self.assertEqual(self.faiss_index.index.ntotal, len(self.sample_embeddings))
self.assertEqual(len(self.faiss_index.metadata), len(self.sample_metadata))
self.assertEqual(self.faiss_index.dimension, 64)
def test_build_index_empty_data(self):
"""Test building index with empty data."""
with self.assertRaises(ValueError):
self.faiss_index.build_index(np.array([]), [])
def test_build_index_mismatched_lengths(self):
"""Test building index with mismatched embeddings and metadata."""
embeddings = np.random.randn(5, 64).astype(np.float32)
metadata = [{"id": i} for i in range(3)] # Different length
with self.assertRaises(ValueError):
self.faiss_index.build_index(embeddings, metadata)
@patch('faiss.get_num_gpus')
def test_gpu_detection(self, mock_get_num_gpus):
"""Test GPU detection and setup."""
mock_get_num_gpus.return_value = 1
config = FAISSConfig(use_gpu=True)
faiss_index = FAISSIndex(config)
self.assertTrue(faiss_index.use_gpu)
@patch('faiss.get_num_gpus')
def test_no_gpu_fallback(self, mock_get_num_gpus):
"""Test fallback to CPU when no GPU available."""
mock_get_num_gpus.return_value = 0
config = FAISSConfig(use_gpu=True)
faiss_index = FAISSIndex(config)
self.assertFalse(faiss_index.use_gpu)
def test_create_flat_index(self):
"""Test creating flat index."""
self.faiss_index.build_index(self.sample_embeddings, self.sample_metadata)
# Should create IndexFlatIP for inner product similarity
self.assertIsInstance(self.faiss_index.index, faiss.IndexFlatIP)
def test_search_functionality(self):
"""Test search functionality (if implemented)."""
self.faiss_index.build_index(self.sample_embeddings, self.sample_metadata)
# Test search with one of the original embeddings
query_embedding = self.sample_embeddings[0:1] # First embedding as query
# This would test the search method if implemented
# For now, we test that the index can perform basic operations
distances, indices = self.faiss_index.index.search(query_embedding, k=3)
self.assertEqual(len(
・・・・
ざっくりとした指示の場合
Pythonでローカルで動作するRAGシステムのコードを実装してのように
ざっくりとした指示だと、最低限の要件を満たしたコードが生成される。
※これでもClaude Sonnet 3.5以前よりは良くなっている。
"""
ローカルRAGシステム実装
必要なライブラリ: pip install sentence-transformers chromadb openai langchain langchain-community pypdf
使用方法:
1. documents/フォルダにPDFファイルやテキストファイルを配置
2. python rag_system.py でシステムを起動
3. 質問を入力してRAGによる回答を得る
"""
import os
import logging
from typing import List, Dict, Any
from pathlib import Path
import json
# 必要なライブラリのインポート
try:
import chromadb
from chromadb.config import Settings
from sentence_transformers import SentenceTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader, TextLoader
import numpy as np
except ImportError as e:
print(f"必要なライブラリがインストールされていません: {e}")
print("以下のコマンドでインストールしてください:")
print("pip install sentence-transformers chromadb langchain langchain-community pypdf")
exit(1)
# ログ設定
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class LocalRAGSystem:
def __init__(self,
collection_name: str = "documents",
model_name: str = "intfloat/multilingual-e5-large",
chunk_size: int = 500,
chunk_overlap: int = 50,
persist_directory: str = "./chroma_db"):
"""
ローカルRAGシステムの初期化
Args:
collection_name: ChromaDBのコレクション名
model_name: 埋め込みモデル名(多言語対応)
chunk_size: テキストチャンクのサイズ
chunk_overlap: チャンク間のオーバーラップ
persist_directory: データベースの保存ディレクトリ
"""
self.collection_name = collection_name
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.persist_directory = persist_directory
# 埋め込みモデルの初期化
logger.info(f"埋め込みモデル '{model_name}' を読み込み中...")
self.embedding_model = SentenceTransformer(model_name)
# ChromaDBクライアントの初期化
self.client = chromadb.PersistentClient(
path=persist_directory,
settings=Settings(anonymized_telemetry=False)
)
# コレクションの取得または作成
try:
self.collection = self.client.get_collection(name=collection_name)
logger.info(f"既存のコレクション '{collection_name}' を読み込みました")
except:
self.collection = self.client.create_collection(name=collection_name)
logger.info(f"新しいコレクション '{collection_name}' を作成しました")
# テキストスプリッターの初期化
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
)
def load_documents(self, documents_dir: str = "./documents") -> List[Dict[str, Any]]:
"""
ドキュメントディレクトリからファイルを読み込み
Args:
documents_dir: ドキュメントが格納されているディレクトリ
Returns:
読み込まれたドキュメントのリスト
"""
documents = []
documents_path = Path(documents_dir)
if not documents_path.exists():
documents_path.mkdir(parents=True, exist_ok=True)
logger.warning(f"ドキュメントディレクトリ '{documents_dir}' を作成しました")
return documents
# サポートされているファイル形式
supported_extensions = {'.pdf', '.txt', '.md'}
for file_path in documents_path.iterdir():
if file_path.suffix.lower() in supported_extensions:
try:
if file_path.suffix.lower() == '.pdf':
loader = PyPDFLoader(str(file_path))
else:
loader = TextLoader(str(file_path), encoding='utf-8')
docs = loader.load()
for doc in docs:
doc.metadata['source'] = str(file_path)
documents.append({
'content': doc.page_content,
'metadata': doc.metadata
})
logger.info(f"ファイル '{file_path.name}' を読み込みました")
except Exception as e:
logger.error(f"ファイル '{file_path.name}' の読み込みに失敗: {e}")
logger.info(f"合計 {len(documents)} 個のドキュメントを読み込みました")
return documents
def add_documents(self, documents: List[Dict[str, Any]]):
"""
ドキュメントをベクトルデータベースに追加
Args:
documents: 追加するドキュメントのリスト
"""
if not documents:
logger.warning("追加するドキュメントがありません")
return
all_chunks = []
all_metadatas = []
all_ids = []
for i, doc in enumerate(documents):
# テキストをチャンクに分割
chunks = self.text_splitter.split_text(doc['content'])
for j, chunk in enumerate(chunks):
if chunk.strip(): # 空のチャンクをスキップ
chunk_id = f"doc_{i}_chunk_{j}"
all_chunks.append(chunk)
all_metadatas.append({
**doc['metadata'],
'chunk_id': chunk_id,
'chunk_index': j
})
all_ids.append(chunk_id)
if not all_chunks:
logger.warning("有効なチャンクがありません")
return
# 埋め込みベクトルを生成
logger.info(f"{len(all_chunks)} 個のチャンクの埋め込みベクトルを生成中...")
embeddings = self.embedding_model.encode(all_chunks, show_progress_bar=True)
# ChromaDBに追加
self.collection.add(
documents=all_chunks,
metadatas=all_metadatas,
ids=all_ids,
embeddings=embeddings.tolist()
)
logger.info(f"{len(all_chunks)} 個のチャンクをデータベースに追加しました")
def search(self, query: str, n_results: int = 5) -> List[Dict[str, Any]]:
"""
クエリに基づいて関連ドキュメントを検索
Args:
query: 検索クエリ
n_results: 返す結果の数
Returns:
検索結果のリスト
"""
# クエリの埋め込みベクトルを生成
query_embedding = self.embedding_model.encode([query])
# 類似度検索を実行
results = self.collection.query(
query_embeddings=query_embedding.tolist(),
n_results=n_results
)
# 結果を整形
search_results = []
if results['documents']:
for i in range(len(results['documents'][0])):
search_results.append({
'content': results['documents'][0][i],
'metadata': results['metadatas'][0][i],
'distance': results['distances'][0][i] if results['distances'] else None
})
return search_results
def generate_answer(self, query: str, context_docs: List[Dict[str, Any]]) -> str:
"""
コンテキストに基づいて回答を生成(シンプルな実装)
Args:
query: ユーザーの質問
context_docs: コンテキストとなるドキュメント
Returns:
生成された回答
"""
if not context_docs:
return "関連する情報が見つかりませんでした。"
# コンテキストを結合
context = "\n\n".join([doc['content'] for doc in context_docs])
# シンプルな回答生成(実際のLLMを使用する場合はここを置き換え)
answer = f"""
以下の情報に基づいて回答します:
質問: {query}
関連情報:
{context[:1000]}...
※ この回答は検索されたドキュメントに基づいています。より詳細な回答を得るには、OpenAI APIなどのLLMサービスを統合してください。
"""
return answer
def chat(self, query: str) -> Dict[str, Any]:
"""
チャット形式でクエリに応答
Args:
query: ユーザーの質問
Returns:
回答と関連情報を含む辞書
"""
# 関連ドキュメントを検索
search_results = self.search(query)
# 回答を生成
answer = self.generate_answer(query, search_results)
return {
'query': query,
'answer': answer,
'sources': [
{
'content': doc['content'][:200] + '...',
'source': doc['metadata'].get('source', 'Unknown'),
'distance': doc.get('distance', 0)
}
for doc in search_results
]
}
def get_collection_info(self) -> Dict[str, Any]:
"""
コレクションの情報を取得
Returns:
コレクションの統計情報
"""
count = self.collection.count()
return {
'collection_name': self.collection_name,
'document_count': count,
'persist_directory': self.persist_directory
}
def main():
"""
メイン実行関数
"""
print("=" * 50)
print("🤖 ローカルRAGシステム")
print("=" * 50)
# RAGシステムの初期化
rag_system = LocalRAGSystem()
# コレクション情報を表示
info = rag_system.get_collection_info()
print(f"📊 コレクション情報:")
print(f" - 名前: {info['collection_name']}")
print(f" - ドキュメント数: {info['document_count']}")
print(f" - 保存先: {info['persist_directory']}")
print()
# ドキュメントが少ない場合は読み込みを実行
if info['document_count'] < 10:
print("📚 ドキュメントを読み込み中...")
documents = rag_system.load_documents()
if documents:
rag_system.add_documents(documents)
print("✅ ドキュメントの読み込みが完了しました")
else:
print("⚠️ documentsフォルダにファイルを配置してください")
print()
# インタラクティブチャット
print("💬 質問を入力してください('quit'で終了):")
print("-" * 50)
while True:
try:
query = input("\n🔍 質問: ").strip()
if query.lower() in ['quit', 'exit', '終了']:
print("👋 ありがとうございました!")
break
if not query:
continue
# RAG実行
print("\n🔄 検索中...")
result = rag_system.chat(query)
print(f"\n📝 回答:")
print(result['answer'])
if result['sources']:
print(f"\n📚 参照したソース:")
for i, source in enumerate(result['sources'], 1):
print(f" {i}. {source['source']} (類似度: {1-source['distance']:.3f})")
print(f" {source['content']}")
print()
except KeyboardInterrupt:
print("\n👋 ありがとうございました!")
break
except Exception as e:
print(f"❌ エラーが発生しました: {e}")
if __name__ == "__main__":
main()
- シンプルな単一クラス設計 (LocalRAGSystem)
- ChromaDBをベクトルデータベースとして使用
- 埋め込みモデルはSentenceTransformerのみ
- 回答生成はシンプルな文字列結合(LLM未使用)
ライブラリ等を指定していないので、意図した実装とならない場合がある。
最後に
Claude Sonnet 4のような強力なコーディングAIを活用することで
開発現場に大きく影響を与えるでしょう。
AIの得意なタスクを任せ、自身の時間を有効的に使いましょう。
Discussion