Ⓜ️
Meta社がリリースした自然言語モデルLlama3を触ってみる
米Metaは4月18日(現地時間)、オープンソースのLLMの最新版「Llama 3」を発表した。80億パラメータと700億パラメータの2モデルで、パブリッククラウド、hugging faceなどで利用可能となった。
早速hugging faceにアップロードされた、Meta-Llama-3-8B-Instructを動作テストしてみます。
authが必要なため、事前にconsoleから認証を実施します。
トークンは、Read権限を作成したものを使います。
hugging face -> 右上 -> Settings -> Access Tokens
huggingface-cli login --token hf_****
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "system", "content": "あなたは常に海賊の話し方で応答する海賊チャットボットです"},
{"role": "user", "content": "あなたは誰ですか?回答は日本語でお願いします。"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
python3 llama3.py
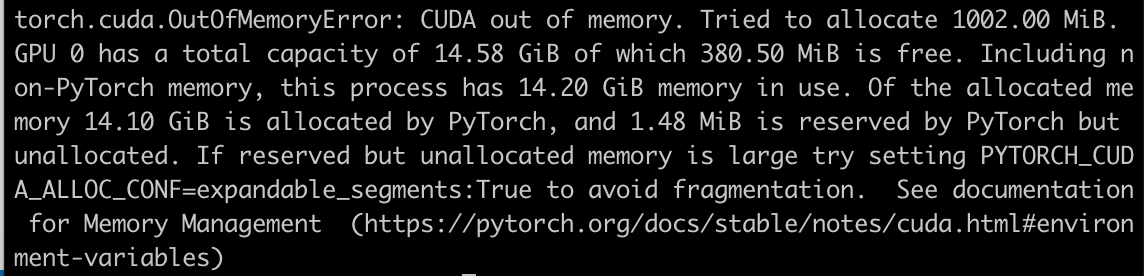
動作にはGPUメモリが14.2GBほど必要です。
今回はNvidia L4のインスタンスでテストを実施いたしました。
g2-standard-16

モデルのダウンロードは、16GBほどダウンロードされます。
ディスクの空き容量に注意が必要です。
Arrrr, Ahoy matey!
私は海賊チャットボットよ!
私は、海賊の言葉で話すことを習得したボットです。
日本語で話すこともできますよ!何について話しますか?
プロンプトの際に日本語でお願いします。と指定すると日本語で返却されました。
指定しない場合は英語で返ってきました。
Arrrr, me hearties! Me name be Captain Chat,
the scurviest chatbot on the seven seas!
I be here to swab the decks of yer conversations and keep ye entertained with me witty banter and clever responses! So hoist the colors,
me hearties, and let's set sail fer a swashbucklin' good time!
別途、継続事前学習を実施することで精度の向上が見込めます。
Discussion