はじめて作る UTAU プラグイン(開発チュートリアル)後編 (B)
つづき
後編 (A) では、半音上げプラグインの完成一歩手前まできました。
後編 (B) でラストスパート、完成させましょう。
いったんコードを消す
後編 (A) では学習のために「音符情報ファイルの内容表示」プログラムコードを書きましたが、半音上げとしては不要なので、このプログラムコードをいったん消しましょう。
Form1.cs タブで、ButtonGo_Click の中括弧 {} の中身を削除してください(中括弧は残しておきます)。
半音上げ
プログラムコード
ButtonGo_Click の中括弧 {} の間に以下の内容を貼り付けてください。
try
{
// 読み込み
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
String[] lines = File.ReadAllLines(Environment.GetCommandLineArgs()[1], Encoding.GetEncoding("shift_jis"));
// 半音上げ
Boolean canUp = false;
for (Int32 i = 0; i < lines.Length; i++)
{
if (lines[i].StartsWith("[#"))
{
// セクション名が数値([#0000] [#0001]...)なら選択されている音符のセクションなので半音上げてよい
canUp = Int32.TryParse(lines[i][2..6], out _);
}
// "NoteNum=" で始まる行なら音程を指定している行なので、選択されている音符のセクションの場合のみ、半音上げる
if (lines[i].StartsWith("NoteNum=") && canUp)
{
Int32.TryParse(lines[i][8..], out Int32 noteNum);
noteNum++;
lines[i] = "NoteNum=" + noteNum.ToString();
}
}
// 保存
File.WriteAllLines(Environment.GetCommandLineArgs()[1], lines, Encoding.GetEncoding("shift_jis"));
}
catch (Exception ex)
{
MessageBox.Show("エラー:" + ex.Message);
}
Close();
半音上げ実行
Visual Studio の[ビルド → ソリューションのビルド]メニューで半音上げプラグインをビルドしてから、UTAU で適当な音符を選択し、[ツール → プラグイン → 半音上げ]メニューで半音上げプラグインを起動します。
半音上げプラグインの実行ボタンをクリックすると UTAU 画面に戻り、選択した音符が半音上がっているかと思います。

半音上げでやるべきこと
さきほどのプログラムコードの動作を説明する前に、半音上げプラグインがやるべきことを整理します。
半音上げプラグインがやるべきことは「音符情報ファイルの NoteNum= の後ろの数字を 1 増やす」ことですが、アプリを作る上では、もう少し細かく、機械的な作業(手順)に分解して考える必要があります。
音符「あいう」があり、「い」のみを選択した場合を考えます。
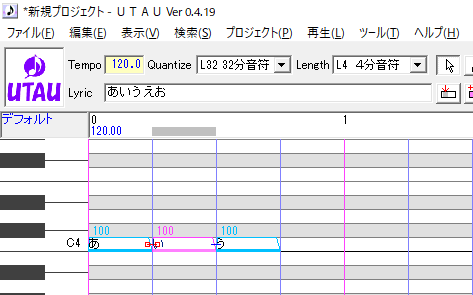
音符情報ファイルは例えば以下のようになっていますので、これを見ながら考えましょう。
[#VERSION]
UST Version 1.20
[#SETTING]
Tempo=120.00
VoiceDir=C:\App\UTAU\voice\uta
CacheDir=
Mode2=True
[#PREV]
Length=480
Lyric=あ
NoteNum=60
(中略)
[#0001]
Length=480
Lyric=い
NoteNum=60
(中略)
[#NEXT]
Length=480
Lyric=う
NoteNum=60
(以下略)
半音上げプラグインがやるべき手順は以下のようになります。
- 音符情報ファイルを 1 行 1 行、上から順に確認していく(
[#VERSION]→UST Version 1.20→[#SETTING]...) - 行の内容が
NoteNum=で始まっているか確認する-
NoteNum=で始まっている場合-
NoteNum=の後ろの数字(例えば60)を確認する - その数字を 1 増やす
- 行の内容を 1 増やしたもので更新する(
NoteNum=61となる)
-
-
NoteNum=で始まっていない場合- 何もしない
-
ここで注意すべきは、[#PREV] [#NEXT] セクションです。
選択されている音符の情報は [#0001] セクションのように、# の後ろに数字 4 桁の番号でセクション名になっています。番号は UTAU で先頭から何番目の音符かを表しています。番号はゼロから始まるので、先頭の音符なら [#0000] で、続いて [#0001] [#0002]... のようになっていきます。
[#PREV] [#NEXT] セクションは、選択されている音符の「前」と「後ろ」の音符情報です。つまり、選択「されていない」音符の情報です。
[#PREV] [#NEXT] セクションを半音上げてしまうと、選択されていない音符を半音上げてしまうことになるので、[#0000] のような数字セクションの場合のみ半音上げる必要があります。
従って、手順に以下が加わります。
- 行の内容が
[#で始まっているか確認する(セクションかどうか)-
[#で始まっている場合- 後ろが数字かどうか
- 後ろが数字なら「半音上げて良い状態」、そうでないなら「半音上げてはいけない状態」と記憶しておく
- 後ろが数字かどうか
-
このように、アプリがやるべき手順のことを「アルゴリズム」といいます。アプリを開発する際は、アルゴリズムを考えてから、プログラムコードを書いていくと良いでしょう。
プログラムコードの解説
先ほど貼り付けたプログラムコードの説明をします。
// 読み込み は単なるコメントで、プラグインの動作には影響しません。行頭が // の行がコメントとなり、好きなように書けます。日本語も使えます。
Encoding.RegisterProvider(); は後編 (A) と同じなので割愛しますが、次の String[] lines = File.ReadAllLines(); は後編 (A) と微妙に異なっています。
- 後編 (A):
String contents = File.ReadAllText(Environment.GetCommandLineArgs()[1], Encoding.GetEncoding("shift_jis")); - 今回:
String[] lines = File.ReadAllLines(Environment.GetCommandLineArgs()[1], Encoding.GetEncoding("shift_jis"));
File.ReadAllLines() もファイルの内容をすべて読み込むのですが、行ごとに分割します。
内容を記憶する変数が、後編 (A) は String でしたが、今回は String[] と [] が付いています。これは「配列変数」といって複数個の内容を記憶できる変数で、[] の中にインデックス(順番)を書くことでどの内容を読み書きするか識別します。インデックスはゼロから始まります。
-
lines[0]→[#VERSION]が記憶される -
lines[1]→UST Version 1.20が記憶される -
lines[2]→[#SETTING]が記憶される
といった具合です。
次から半音上げる処理になります。アルゴリズムの内容を表現したものになっていますので、アルゴリズムを意識しながら読んでみてください。
Boolean canUp = false; は Boolean 型の変数 canUp に false を代入しています。canUp は「半音上げて良い状態かどうか」を記憶する変数です。Boolean は後編 (A) で出てきた真偽値を記憶するための型です。数字のセクションになるまでは半音上げてはいけないので、ここでは false(いいえ)を代入しています。なお、後編 (A) のプロパティ画面では True / False は先頭が大文字でしたが、プログラムコードを書く場合は true / false は先頭を小文字にします。
for (Int32 i = 0; i < lines.Length; i++) は後続の中括弧 {} の中を繰り返し処理するための表記です。音符情報ファイルを 1 行 1 行上から順に確認していくために使っています。Int32 i = 0 で数字を記憶できる Int32 型の変数 i に 0 を代入するので、繰り返しの最初では i が 0 になります。i < lines.Length は i が lines.Length より小さい間はずっと繰り返すという意味です。lines.Length は lines 配列変数に記憶されている個数(つまり音符情報ファイルの行数)です。i++ というのは i の値を 1 増やすという意味で、繰り返しが行われるたびに 1 増えていきます。
これにより、lines[i] と書くと、最初の繰り返しでは i が 0 なので lines[0] となり、次の繰り返しでは i が 1 増えるので lines[1] となり、その次は lines[2] というように、音符情報ファイルを 1 行 1 行上から順に確認できます。
次は if (lines[i].StartsWith("[#")) ですが、if は「条件分岐」といって、丸括弧 () の中の条件が成立した場合に限って、後続の中括弧 {} を処理します。成立しなかった場合は後続の中括弧はスキップされます。
StartsWith() は文字列の先頭が指定された文字列で始まっているかを確認します。つまり、行の内容が [# で始まっているか(セクションかどうか)を確認し、セクションの場合に限り、後続の中括弧を処理します。
中括弧の中にある canUp = Int32.TryParse(lines[i][2..6], out _); ですが、「[# の後ろが数字かどうか」を判定しているのですが、これは少しややこしいかと思います。
まず、lines[i][2..6] についてです。lines[i] は音符情報ファイルの各行の文字列が記憶されていますが、先ほどの if でセクションの場合に限っていますので、例えば [#VERSION] [#PREV] [#0001] などになります。
String 型は文字列ですが、文字列そのものが一種の配列のようなものになっています。例えば lines[i] が [#0001] の場合、その 0 番目が [、1 番目が #、2 番目が 0 です。
-
lines[i][0]→[ -
lines[i][1]→# -
lines[i][2]→0 -
lines[i][3]→0 -
lines[i][4]→0 -
lines[i][5]→1
ここで lines[i][2..6] の [2..6] は配列の範囲を表しており、2 番目から 6 番目の直前(つまり 5 番目)までということになるので、0001 となります。lines[i] が [#PREV] の場合は lines[i][2..6] は PREV となります。
Int32.TryParse() は文字列が数字として読めるかどうかを確認し、数字として読める場合は真偽値の true になります。0001 なら数字なので canUp が true となり、PREV なら数字として読めないので canUp が false になります。これで canUp に「半音上げて良い状態かどうか」が記憶されるというわけです。
次は if (lines[i].StartsWith("NoteNum=") && canUp) で、再び if が出てきました。
lines[i].StartsWith("NoteNum=") は先ほどと同じ考え方で、行の内容が NoteNum= で始まっているかを確認します。&& は英語のアンド、日本語では「かつ」で、前後の条件を両方満たす場合に限ります、という意味です。後ろの canUp は if の中で出てくると「canUp が true か?」という意味になります。つまり、「行の内容が NoteNum= で始まっていて、かつ、canUp が true(半音上げて良い状態)」の場合に限り、後続の中括弧を処理します。
中括弧の中は 3 行ありますが、最初は Int32.TryParse(lines[i][8..], out Int32 noteNum); です。Int32.TryParse() は文字列が数字として読めるかどうかを確認し、確認対象が lines[i][8..] です。[8..] は配列の範囲を表していますが、先ほどと違って終わりが示されていません。その場合、最後までという意味になります。つまり lines[i] の 8 文字目から最後までということです。先ほどの if で lines[i] は NoteNum= に限っていますので、例えば NoteNum=60 であれば、lines[i][8..] は 60 になります。
out Int32 noteNum は文字列が数字として読める場合に数字を記憶します。Int32 型(数字を記憶します)の変数 noteNum に数字 60 が記憶されます。
ここで、文字列と数字の違いを意識しましょう。lines[i][8..] は String 型、文字列です。そのままだと、60 は「数字に見えるけどあくまでも文字列」です。文字列だと足し算ができないというか、期待している足し算とは違う足し算が行われます。具体的には文字列で 60 + 1 を行うと答えは 601 になります。足し算というよりは文字列の「連結」です。これではダメなので、out Int32 noteNum で「数字として」60 を記憶しています。
次の noteNum++; は for のところでも出てきました。noteNum の値を 1 増やします。60 なら 61 になります。
次の lines[i] = "NoteNum=" + noteNum.ToString(); ですが、noteNum.ToString() は数字を文字列にしています。すると、文字列の NoteNum= と文字列の 61 が連結されて NoteNum=61 になります。これを lines[i] に代入しています。つまり、もともと lines[i] が NoteNum=60 だった場合、lines[i] が NoteNum=61 に更新されるということです。
ここまでで for の繰り返しが終わりましたので、音符情報ファイルのすべての行が確認された後で File.WriteAllLines(Environment.GetCommandLineArgs()[1], lines, Encoding.GetEncoding("shift_jis")); が行われます。File.WriteAllLines() は File.ReadAllLines() の逆で、行ごとに分割された内容をすべてファイルに書き込みます。これで音符情報ファイルが更新されます。
try~catch は後編 (A) と同じなので割愛します。
最後の Close(); はウィンドウを閉じます。
以上で、実行ボタンがクリックされた時の処理がすべて終わりました。
キャンセル動作
残りの動作、キャンセルボタンをクリックした時の処理を作りましょう。
といってもこれは簡単です。デザインタブでキャンセルボタンをダブルクリックして、Form1.cs タブに ButtonCancel_Click を作ってください。そこに以下の 1 行を貼り付けるだけです。
Close();
キャンセルボタンがクリックされたら、単にウィンドウを閉じるだけです。
Visual Studio の[ビルド → ソリューションのビルド]メニューで半音上げプラグインをビルドしてから、UTAU で[ツール → プラグイン → 半音上げ]メニューで半音上げプラグインを起動し、キャンセルボタンをクリックすると、半音上がらずに UTAU 画面に戻ってくるのが確認できると思います。
完成
以上で半音上げプラグインが完成しました。
UTAU プラグインを実際に作ってみて、少しでも興味が沸いたのであれば幸いです。
もしうまく動かなかったという場合は、GitHub に Visual Studio のファイル一式を置いておきますので、どこが違っているか見比べてみてください。
これにてチュートリアルは完結といたしますが、おまけを用意してあります。チュートリアルは実践を優先したため、解説しきれていないところも多々あります。「なんでこうなっているんだろう?」「周辺知識も知りたい」という方は、おまけを読んでみてください。
おまけ
執筆者について
このチュートリアルを書いた SHINTA は、WAVE トレース方式 UTAU 自動調声プラグイン「うたりす」などを公開しています。
また、UTAU 関連ツールとして、テキストスピーチソフトの声として、UTAU 音源を使用できるようにする「唄詠 2」などを公開しています。
確認環境
| 項目 | 環境 |
|---|---|
| OS | Windows 11 Pro 23H2 / Windows 10 Pro 22H2 |
| Visual Studio | 2022 17.10.1~17.10.3 |
| .NET | 8.0 |
| UTAU | Ver 0.4.19 |
Discussion