Revisiting Large Kernel Design in CNNsを読んだ(その1)
はじめに
この記事で使用している画像は参考文献に記載した論文を基に作成しております。著者の体力が持たなかったため本記事は2本に分けております。この記事では主にRepLNetで紹介されたlarge kernel designのガイドラインについて書いています。
モチベーション
- 近年、Transformerベースの手法が大きな成功を収めており、その理由の一つとしてmulti-head self-attentionが作る大きな受容野があるのではないか?
- 今までのCNNの主流である3×3の小さなカーネルを重ねて受容野を広げる代わりに大きなカーネルを使用すればCNNとViTのパフォーマンスのギャップを埋めることができるのではないか?
貢献
- CNNのカーネルサイズを大きくするデザイン(large kernel design)のための5つのガイドライン
- 31×31の大きなカーネルを持ったRepLKNetの提案
- 下流タスクにおける有用性の実証
Guidelines of Applying Large Convolutions
ガイドライン1:large depth-wise convolutionsは効果的
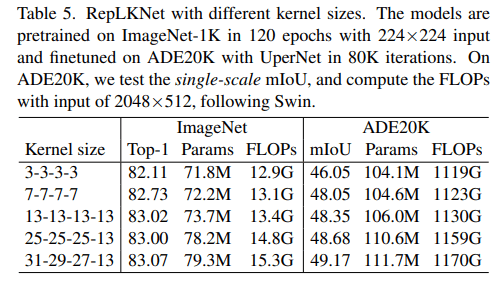
カーネルサイズに応じてパラメータ数とFLOPsが二次関数的に増加します。これに対してdepth-wise convolution(DW)を使用することでパラメータ数、FLOPsの増加を抑えることができます。例えば、カーネルサイズを[3,3,3,3]->[31,29,27,13]に増加してもパラメータ数、FLOPsはそれぞれ18.6%、10.4%しか増加していない(Table5)。
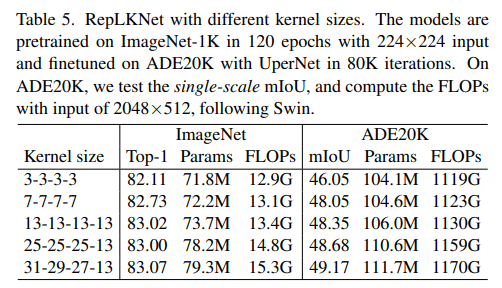
モダンな並列計算機(GPUsなど)でのDWは非効率的(Table1)なのでCUDA kernelsに最適化するいくつかのアプローチに挑戦し、オープンソースフレームワークのMegEngineに統合した。我々の最適化を使用することRepLKNet内のDWに対してレイテンシを49.5%->12.3%に減少させることができる。

ガイドライン2:identity shortcutは大きなカーネルを持つネットワークには必要不可欠
DWを多数使用しておりidentity shortcut(ID)あり/なしがあるためMobilenetV2をベンチマークとして使用し、単純にDWのカーネルサイズを変更しました(Table 2)。Imagenetで100エポック学習させた結果、0.77精度が向上しました。
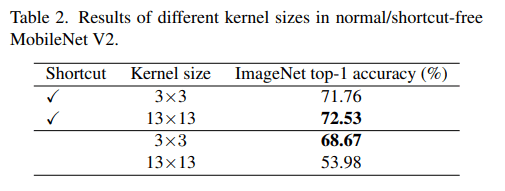
IDによってモデルを異なる受容野のアンサンブルにすることができるため[3]、小さなパターンを捉える能力を失わずに大きな受容野の恩恵を受けることができるのだそうです。
ガイドライン3:小さなカーネルでre-parameterizingする
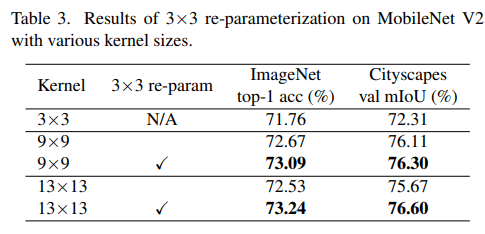
MobilenetV2の3×3畳み込み層を7×7、13×13に置き換えてStructural Reparameterization[4]を行った。(Reparameterizationについては別の記事で詳しく説明されているので本記事での説明は割愛します。こちらの記事はハンズオンの説明も載っていて詳しく解説されているのでおすすめです)

3×3畳み込みと並列により大きいカーネルの畳み込み層、その後BNという構成にし学習後に大きいカーネルにBNごとReparameterizationしたようです。
前述の学習済みモデルをバックボーンとし、DeepLabv3+[5]のCityscapesに対する精度を比較しました。学習時のパラメータはMMSegmentationで与えられるデフォルトのものをそのまま使用したようです。Table3が示すように3×3と比較して大きなカーネルを使用することでmIoUが向上しました。
ガイドライン4:大きな畳み込み層はImageNet分類よりも下流タスクのパフォーマンスを向上する
Table3でも大きな畳み込み層はImageNetとCityscapesの両者において精度を向上させることが確認されているが、ImageNetは1.33%の向上だったのに対しCityscapesでは3.99%の向上であった。同じ傾向はTable5でも確認できる。
多くの研究で、大きなEffective Receptive Fields[6]を意味するコンテキスト情報(文脈情報)が、物体検出やセマンティックセグメンテーションなどの多くの下流タスクで重要であることが実証されています。(つまりERFが大きいと下流タスクに有用なコンテキスト情報を多く抽出できるということなのでしょうか?)
他の理由として、large kernel designはモデルにより多くの形状バイアスをもたらすというものがあります。あくまで私の理解ですが、物体検出やセマンティックセグメンテーションが得意な人間が形状を重視しているので、強い形状バイアスを持ったモデルは下流タスクで有用なのだと思います。勘違いがあればご指摘お願いします。
ガイドライン5:大きいサイズのカーネルは小さいサイズの特徴マップに対しても有用
にわかに信じがたい話ですが、特徴マップ(例えば7×7)よりもカーネルサイズ(例えば13×13)のほうが大きい場合においても有用な情報を抽出できるそうです。Table4はMobilenetV2の最終層のカーネルサイズだけを変化させた場合のパフォーマンスの比較です。最終層なのですでに大きい受容野を持っているはずですが、それでもカーネルサイズの増加は精度の向上に寄与しています。また、下流タスクであるCityscapesのほうが増加率が大きいです。

まとめ
テクスチャ重視のCNNを形状重視にするためにカーネルサイズを拡大して受容野を広げてよう、という論文を読みました。近年のViTの成功に習うだけでなくかなり古くからある論文も引用しており読んでいてためになることばかりでした。私の体力が持たなかったので詳しいことは全然かけてないので興味がある方はぜひ論文を読んでみてください。
参考文献
- Ding, Xiaohan, et al. "Scaling up your kernels to 31x31: Revisiting large kernel design in cnns." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
- Huang, Gao, et al. "Deep networks with stochastic depth." Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14. Springer International Publishing, 2016.
- Veit, Andreas, Michael J. Wilber, and Serge Belongie. "Residual networks behave like ensembles of relatively shallow networks." Advances in neural information processing systems 29 (2016).
- Ding, Xiaohan, et al. "Repmlpnet: Hierarchical vision mlp with re-parameterized locality." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
- Chen, Liang-Chieh, et al. "Encoder-decoder with atrous separable convolution for semantic image segmentation." Proceedings of the European conference on computer vision (ECCV). 2018.
- Luo, Wenjie, et al. "Understanding the effective receptive field in deep convolutional neural networks." Advances in neural information processing systems 29 (2016).
Discussion