Revisiting Large Kernel Design in CNNsを読んだ(その2)
はじめに
この記事で使用している画像は参考文献に記載した論文を基に作成しております。その1ではCNNのカーネルサイズを大きくするlarge kernel designのモチベーションとそのガイドラインについて書きました。本記事では具体的なRepLKNetのアーキテクチャについて書きます。
手法
RepLKNet: a Large-Kernel Architecture
Stem
RepLKNetは下流タスクで高いパフォーマンスを発揮できるようによりディテールを捉える構造にした。3×3の畳み込みのあと、low-levelのパターンを捉えられるようにDW 3×3、1×1 Conv、DW 3×3を配置しました。大きいカーネルの畳み込みを除いてモデルの表現力は深さに関係するため1×1畳み込みでモデルを深くし、非線形性の向上とチャネル間での情報の共有を行いました。
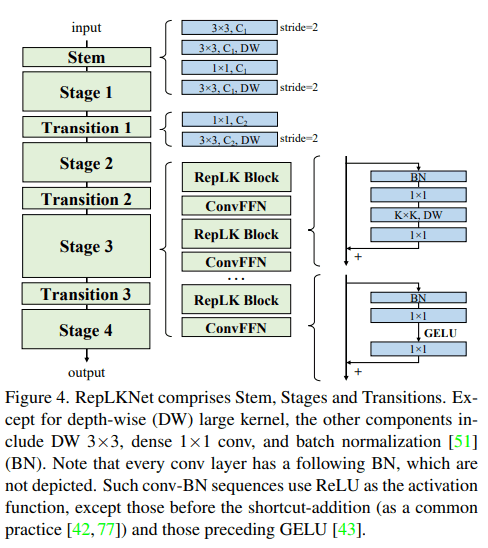
Stage 1-4
short cutとDWを使用したRepLK Blockによって構成されます。DWの前後に1×1 Convを適用、大きいカーネルを使用したDWは5×5畳み込みでre-parameterizationを行います。たぶんコードを見た方が早いと思うので公式実装の該当部分を記載します。
def conv_bn_relu(in_channels, out_channels, kernel_size, stride, padding, groups, dilation=1):
if padding is None:
padding = kernel_size // 2
result = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups, dilation=dilation)
result.add_module('nonlinear', nn.ReLU())
return result
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups, dilation=1):
if padding is None:
padding = kernel_size // 2
result = nn.Sequential()
result.add_module('conv', get_conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups, bias=False))
result.add_module('bn', get_bn(out_channels))
return result
class RepLKBlock(nn.Module):
def __init__(self, in_channels, dw_channels, block_lk_size, small_kernel, drop_path, small_kernel_merged=False):
super().__init__()
self.pw1 = conv_bn_relu(in_channels, dw_channels, 1, 1, 0, groups=1)
self.pw2 = conv_bn(dw_channels, in_channels, 1, 1, 0, groups=1)
self.large_kernel = ReparamLargeKernelConv(in_channels=dw_channels, out_channels=dw_channels, kernel_size=block_lk_size,
stride=1, groups=dw_channels, small_kernel=small_kernel, small_kernel_merged=small_kernel_merged)
self.lk_nonlinear = nn.ReLU()
self.prelkb_bn = get_bn(in_channels)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
print('drop path:', self.drop_path)
def forward(self, x):
out = self.prelkb_bn(x)
out = self.pw1(out)
out = self.large_kernel(out)
out = self.lk_nonlinear(out)
out = self.pw2(out)
return x + self.drop_path(out)
transformerやMLPで広く使われているFeed Forward Network(FFN)から発想を得て、short cut、BN、1×1畳み込み、GELUで構成されたConvFFNを使用しています。ViTやSwinに倣ってシンプルにRepLKBlockの後にConvFFNを配置します。また、全結合層の前にLayer Normalizationを入れる古典的なFFNと比べて、re-parameterizationによってBNは畳み込みに結合できるため効率的な推論を行うことができます。
class ConvFFN(nn.Module):
def __init__(self, in_channels, internal_channels, out_channels, drop_path):
super().__init__()
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.preffn_bn = get_bn(in_channels)
self.pw1 = conv_bn(in_channels=in_channels, out_channels=internal_channels, kernel_size=1, stride=1, padding=0, groups=1)
self.pw2 = conv_bn(in_channels=internal_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0, groups=1)
self.nonlinear = nn.GELU()
def forward(self, x):
out = self.preffn_bn(x)
out = self.pw1(out)
out = self.nonlinear(out)
out = self.pw2(out)
return x + self.drop_path(out)
Transtion Block
このブロックは各ステージの間に配置されており、1×1畳み込みでチャネル数を増加させた後3×3 DW畳み込みで1/2サイズにダウンサンプリングする。
class TransitionBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size) -> None:
super().__init__()
self.layers = nn.ModuleList()
self.layers.add_module('conv1x1', nn.Conv2d(in_channels, out_channels, 1,1,0))
self.layers.add_module('bn1', nn.BatchNorm2d(out_channels))
self.layers.add_module('nonlinear1', nn.ReLU(inplace=True))
self.layers.add_module('conv3x3', nn.Conv2d(out_channels, out_channels, 3, 2, 1, groups=out_channels))
self.layers.add_module('bn2', nn.BatchNorm2d(out_channels))
self.layers.add_module('nonlinear2', nn.ReLU(inplace=True))
def forward(self, x):
return self.layers(x)
Making Large Kernels Even Larger
RepLKNetは各ステージのブロック数
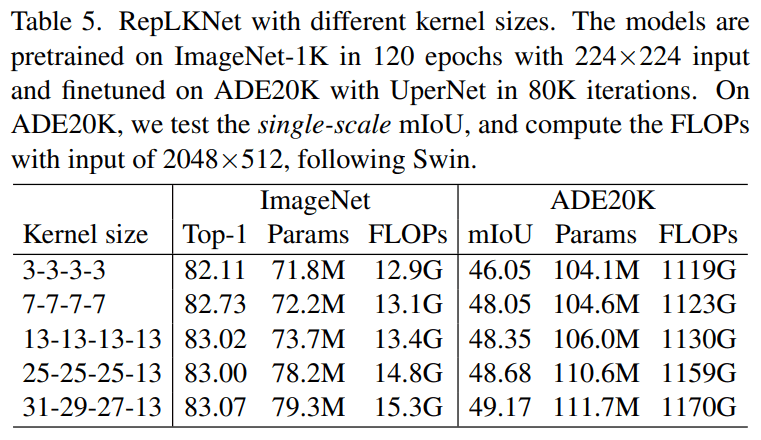
Table5はImageNetとADE20Kに対するパフォーマンスです。ImageNetに対してはカーネルサイズを3→13とすると精度は高くなったものの、それ以上カーネルサイズを増加させてもパフォーマンスは向上しませんでした。一方で、ADE20Kではカーネルサイズを大きくするほどmIoUの向上が見られました。カーネルを[13,13,13,13]→[31,29,27,13]のように変化させるとmIoUは0.82向上する一方で、パラメータ数は5.3%、FLOPsは3.5%しか増加しませんでした。
ImageNet Classification
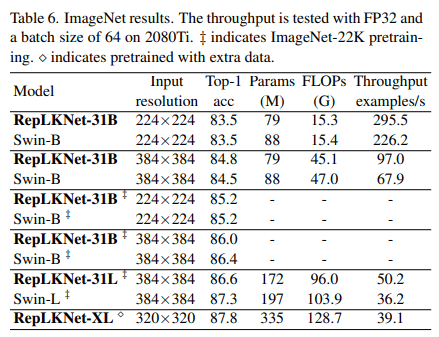
全体的にアーキテクチャが似ているため、まずSwinとの比較を行いました。ImageNet-1Kでの訓練でSwin-Bよりも0.3%精度の高い84.8%の精度を獲得しました。
Semantic Segmentation
学習済みモデルをバックボーンとしてCityscapesとADE20Kでパフォーマンスの比較を行いました。MMsegmentationで実装されたUperNetを使用しました。Swin-Bを凌駕するパフォーマンスでImageNet-22Kで学習済みのSwin-Lよりも高い精度を獲得しました。
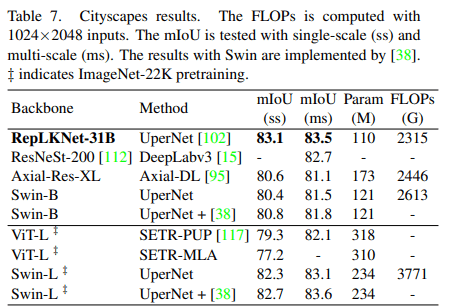
ADE20Kに対して、ImageNet-1K/20Kで学習済みのSwin-Bのどちらよりも高い精度を獲得しました。

Object Detection
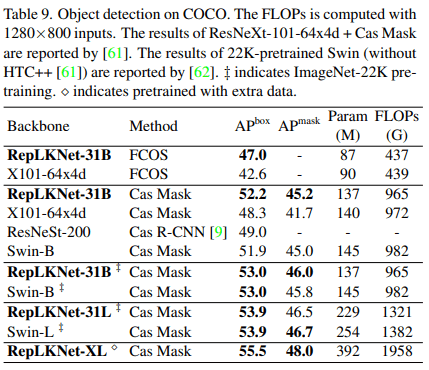
RepLKNetをバックボーンとして物体検出モデルであるFCOSとMask R-CNNを使用しました。ResNeXt-101-64x4dよりも少ないパラメータと低いFLOPsであるにも関わらず4.4高いmAPを獲得しました。
おわりに
ConvNeXtはCNNをTransformerと同じくらい「近代化」してみようという論文だったけど、RepLKnetもTransformerの成功に倣ってCNNの受容野を広げてみた、という内容でした。ただ、本文にもあるようにただカーネルサイズを大きくするだけではパラメータが爆増してしまうので、計算量を低減する工夫がもう少し必要だと感じました。下流タスクのパフォーマンスを向上させるようなのでUperNetと共にセマンティックセグメンテーションや深度推定なんかも試してみたいです。
Discussion