Open-book な 日本語質問応答システム構築してみた with Haystack and Elasticsearch
本記事は 情報検索・検索技術 Advent Calendar 2022 18日目の記事になります。
※タイトルにつけた Open-book は、本来は Open-domain の方が違和感のない表現かもしれません。しかし、後述する様な理由から、あえて今回の記事では Open-book と題しています。また、タイトルには文字数の関係で(日本語訳の)質問応答と表記しましたが、本文中では Question Answering の用語を用いています。
概要
- Question Answering の概略について簡単にまとめた
-
Haystack(ヘイスタック)1.10 と Elastcsearch 7.9.2 を用いて、日本語の Question Answering システムを作成して動かしてしてみた
- 検証のために書いたコード: https://github.com/Shingo-Kamata/japanese_qa_demo_with_haystack_and_es
- Retriever は通常の Elasticsearch の検索を行った
- Reader のモデルは https://huggingface.co/ybelkada/japanese-roberta-question-answering を利用
- 実用性を考えると、もう少し利用方法(前処理等)やモデルを工夫しなければならなさそうだけど、遊ぶ分にはそれなりのものはできたかも(以下はいい感じの結果が得られた実行例)
質問を入力してください(exit で終了)>>忠臣蔵の主人公は? Inferencing Samples: 100%|█| 1/1 [00:00<00:00, 4.41 Batches/s Query: 忠臣蔵の主人公は? Answers: [ <Answer {'answer': '大石内蔵助', 'type': 'extractive', 'score': 0.8082048296928406, 'context': 'ビ時代劇ご存知旗本退屈男子連れ狼名奉行大岡越前隠密奉行朝比奈剣客商売主演代表作多いテレビ東京新春ワイド時代劇正月時代劇主演俳優定番1人忠臣蔵主人公大石内蔵助忠臣蔵最後忠臣蔵忠臣蔵瑤泉院陰謀3回演じる他勝海舟2回徳川家康4回同じ人物複数回演じる多い近年時代劇専門チャンネル放映三屋清左衛門残日録主演幼い', 'offsets_in_document': [{'start': 437, 'end': 442}], 'offsets_in_context': [{'start': 73, 'end': 78}], 'document_id': 'vfpOJYUBLyfAJxXYLLe9', 'meta': {'article_id': '172458', 'revid': '92630170', 'url': 'https://ja.wikipedia.org/wiki?curid=172458', 'title': '北大路欣也'}}>, <Answer {'answer': '須賀 貴匡', 'type': 'extractive', 'score': 0.8008686304092407, 'context': '須賀 貴匡(すが たかまさ、1977年10月19日 - )は、日本の俳優。東京都江戸川区出身。ラ・セッテを経て、2019年12月からフリーで活動している。\n来歴.\n高校卒業後は様々なアルバイトをしながら俳優養成所に通っていた。当時は父親から「実家の寿司屋を継がないなら出て行け」と言われ、家を追い出さ', 'offsets_in_document': [{'start': 0, 'end': 5}], 'offsets_in_context': [{'start': 0, 'end': 5}], 'document_id': 'rvlNJYUBLyfAJxXYyd4l', 'meta': {'article_id': '302410', 'revid': '1713277', 'url': 'https://ja.wikipedia.org/wiki?curid=302410', 'title': '須賀貴匡'}}>, ...- 上の結果では、知識ソースに Wikipedia を利用しているが、ソースをニュース記事にしてみてもそれなりの結果は確認できた(著作権的なあれがありそうで今回掲載していないが)
- そもそも、Question Answering システムを独自に作成する価値て何かあるの? について考察(妄想)もしてみた
注意: Haystack 使うと、(Elasticsearch には少なくとも)Index に意図しない Mapping 追加等不明な挙動があるので、試す際の環境には十分注意してください
今回の記事を書いた経緯
-
Vector 型の検索エンジンを色々紹介している記事にて、(今回は取り上げないが)Weaviate という検索エンジンが Question Answering モジュールがデフォで備わっていると紹介されていたので、サンプルデモ(英語)を試したら、確かにいい感じだったので記事を書こうと思った
"question": "What is AI?", 'result': 'inspired by neuroscience', 'result': 'intelligent technologies', 'result': 'artificial intelligence',- Weaviate のデモでは、CNN 等のニュース記事を知識ソースに用いてる感じ
- GPU がないとこのデモ動かすの厳しいかも(Dense(密) Vector を構築しているので)
- Waviate は SeMI Technologies というオランダのスタートアップが中心に開発を行っている
- せっかくまとめるなら、日本語の Question Answering システムを構築したほうが記事として良いと思ったが、Weaviate を日本語で動かすのは少し大変そうであった
- Weaviate を調べる中で Haystack という OSS を知った
-
Weaviate + Haystack の Question Answering が紹介されていた
- Waviate にも Question Answering モジュールが前述のようにあるが、この記事では、Weavitate は Dense Vector の格納先としてのみに利用されてそう
- Haystack は deepset というドイツのタートアップが中心に開発を行っている
-
Weaviate + Haystack の Question Answering が紹介されていた
- Haystack 自体はただのフレームワークであるため柔軟性があり、Elasticsearch を利用できる&日本語設定が楽だったので、今回こっちをまとめることにした
- https://github.com/deepset-ai/haystack/tree/v1.10.0/haystack/document_stores を見れば分かる通り、Haystack は、Elasticsearch、OpenSearch だけではなく Pinecone 等の連携も対応をしている
- あと忘れてはならないのが、日本語の QA-Reader モデルがありそれなりの結果がでたおかげで、記事にまとめることができた
- モデルを作成していただいた方には本当に感謝しています
Question Answering について
- ここのセクションを書くにあたって以下の記事、論文を参考にした
- https://en.wikipedia.org/wiki/Question_answering
- https://ja.wikipedia.org/wiki/質問応答システム
- https://www.jstage.jst.go.jp/article/jnlp/28/1/28_3/_pdf
- https://aclanthology.org/2020.emnlp-main.550.pdf
- http://ai.stanford.edu/blog/answering-complex-questions/
- https://www.jstage.jst.go.jp/article/tjsai/37/2/37_37-2_A-L64/_article/-char/ja/
Question Answeringとは?
- 自然言語での質問に対して、自動的に答えを返す自然言語処理のタスクである
- 日本語では 質問応答(システム)というみたい(質問回答ではない)
- 以下の感じ(これは Google による Question Answering 機能)
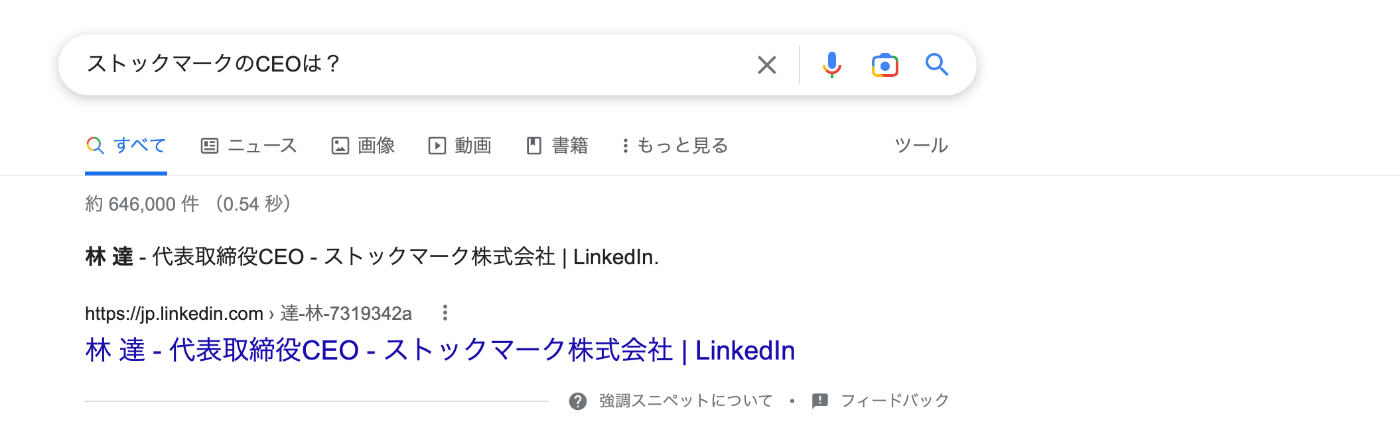
- また、(おそらく)ドキュメント検索を伴わないものだと、いま騒がれている ChatGPT がある
分類
質問できる(あるいは回答できる)領域に関する分類(Open-domain / Closed-domain)
- Open-domain
- 一般的な質問応答
- 一般的の意味は、ちゃんとした質問文であれば、基本任意の質問に対して回答を与えることができるシステム
- Wikipedia 等を用いて構築される
- 個人的には、Closed-domain に対して生まれた用語で、ここまでやれれば Open-domain だという明確なものはあまり無い気がしている
- 一般的な質問応答
- Closed-domain
- 医療製薬等、特定の領域に対してのみの質問応答
- 医療のオントロジー等を用いて構築される
- 最初の質問応答システムは、Closed-domain のものであった
- 野球に関するものだったようである
いろいろな資料を見ると、知識ソースに Wikipedia を使っている場合には間違いなく Open-domain と呼び、オントロジーを用いて高度な自動推論をする場合等は Closed-domain と呼んでいる感じはある。しかし、例えば、社内文章を知識ソースやオントロジーとして利用し、社内の質問、「弊社の冬休みはいつからいつまで?」にのみ回答できるシステムがあった場合に、これがどちらに分類されるかはよくわからない(詳しい方いたらこの2つの違いを明確に区別する方法を教えて下さい)。仮に、もし Closed-domain に分類されたとして、そのシステムが Retriver-Reader モデル(後述)であり、 Reader として Wikipedia で学習された言語モデルを利用していた場合も Closed-domain と果たして呼ばれるのか?等考えてしまう。
このように、 Openか? Closedか? はかなり線引きが難しいように思える。
システムの構成に関する分類(Open-book / Closed-book)
- Oopen-book
- book は教科書を意味しており、試験の教科書持ち込みのアナロジーである
- つまり、Open-book は、オンザフライで知識ソースにアクセスしにいくものである
- Google のはこれにあたる
- Clodsed-book
- あらかじめ言語モデルに知識を埋め込んで(学習させて)答える
- 大規模言語モデルがこれにあたる
- おそらく ChatGPT はこれに該当しそう
GPT3等の大規模言語モデルの出現までは、あまり book を気にする必要性はなかったのかもしれないが、現在のように ChatGPT 等が広まって以降は、このアーキテクチャの違いも意味合いがありそう。
Open-book / Closed-book については、 https://www.jstage.jst.go.jp/article/jnlp/28/1/28_3/_pdf のイントロダクションがすごくわかりやすい。
Open-domain な Question Answeing に関して、Open-book なものも Closed-book なものも存在しているので注意(Closed-domain もそうだと思うが)。
その他の分類
- 回答の長さに関して
- Open-book だから切り抜きの回答、Closed-book(ChatGPT) だから文章で回答できる というわけではなさそう
- deepset がだしている https://huggingface.co/spaces/deepset/wikipedia-assistant は、レポートのようなものを生成できる(画像参考)が、Wikipediaを参照しており、Open-book だと思われる
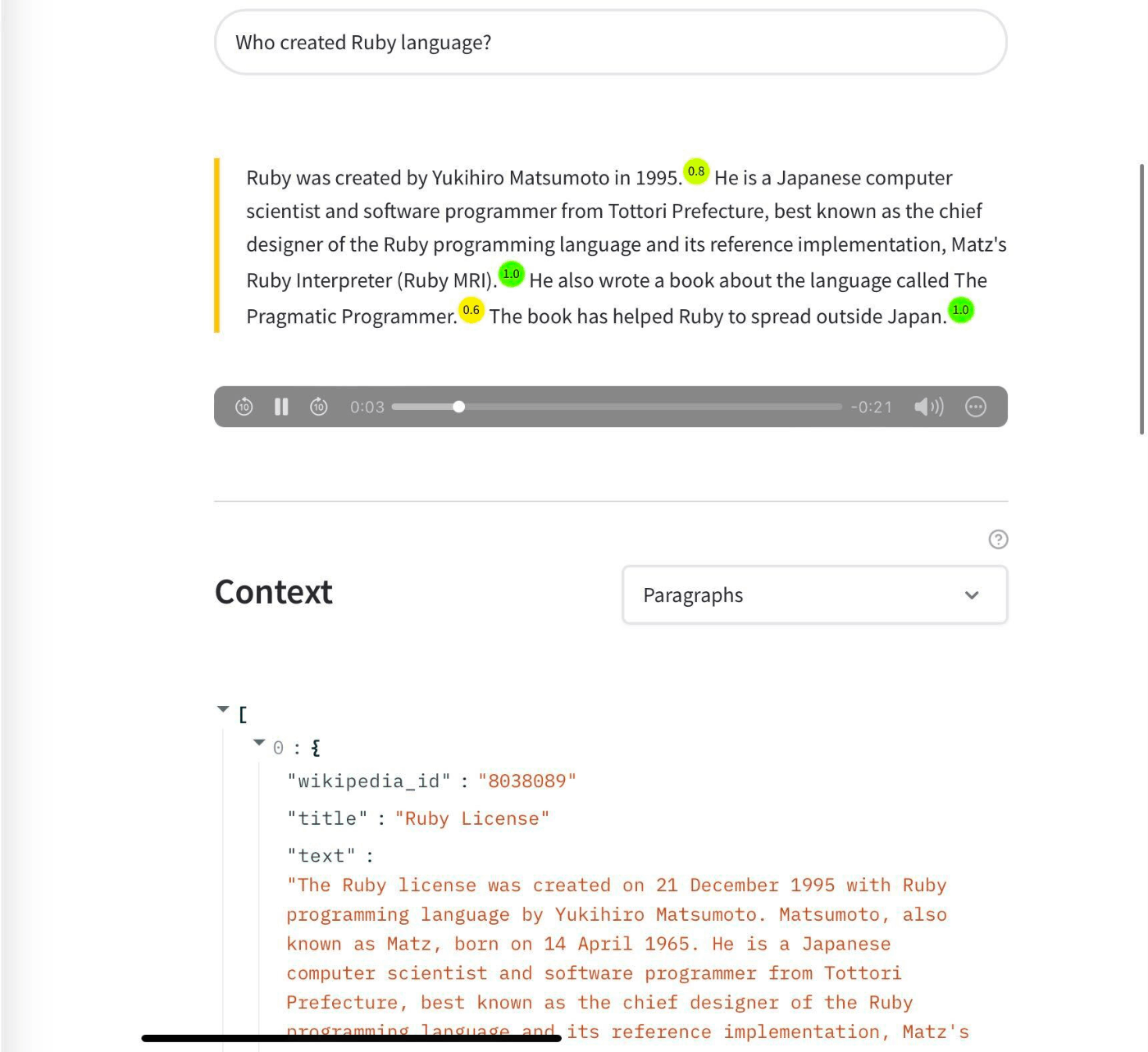
- これは信頼度みたいなものも出ていて面白い
- info を見ると Seq2Seq を用いて文で回答できるようにしていることがわかる
- 今回 Haystack を用いて構成したシステムぽく単語で回答をするのか、ChatGPT のように文章で回答するのかの違いは、factoid、 non-factoid 分類 も関連してきそうではある
- これらは、質問に関する分類であり、factoid 型は固有名詞や数量を問う、つまり回答はそれらの単語があれば十分な質問であり、non-factoid は定義や理由などを問う、単語では答えにくい比較的長文で回答する必要がある質問を指す
- 質問に関する分類ではあるものの、 ChatGPT が non-factoid 型に対応しており、factoid 型の質問をしても比較的長文で回答するところを考察するに、 non-factoid に対応をした Question Answering システムは、factoid 型質問にもより自然なある程度の長文で回答できるものに思われる
- 知識ソースの公開範囲について
- Open-domain Question Answering の文脈でよく Wikipedia の話がでてくるため暗黙のうちにそう考えてしまうが、「Open-domain = Public な情報を知識ソースとする」ではなさそう?
- Open-domain、closed-domain のような単語が生まれた当時に、あまりインターネットが普及してなかったみたいなこともあったりするのかも?
- 一方、知識ソースが Public なのか Internal なのか? は現実問題として重要なファクターな気がするので、そのあたりに言及している文献を探しているが、見つからず(どなたかご存知ならば教えて下さい!)
Retriver-Readerモデルについて
- Open-book な Question Answering システムは、 Retriver-Reader モデルがよく採用される[1]
- Retriver-Reader モデルは2つのパートでできている
- Retriver: 知識ソースから回答があるドキュメントを見つける
- Reader: ドキュメントから回答がある箇所を抽出する
- 以下の論文にある図がすごくわかりやすい
https://www.anlp.jp/proceedings/annual_meeting/2021/pdf_dir/P7-15.pdf
図において、「雷門」の記事全体が Passage のように見えるが、実際には記事を分割したものの1つが Passage に該当(分割する理由は後述)すると考えるべき[2]
-
Retriever-Reader モデルのいいところは、回答のエビデンス(根拠)が提示できるところである
- ただし、これは Open-book なシステム全部がそうであるとか、Closed-book なシステムはできないとか、そういことは含意しない
- あくまで、Retriver-Reader モデルだと、結果のエビデンスである Passage や Passage 分割元の記事情報が取得しやすいというだけである
- 一般的に、Retriever は BM25 の Term Vector ベースの Sparse な検索が(少なくとも2020年くらいまでは)このタイプのデファクト...であったが、最近では Dense な Retriver も重要とされている
- Reader は Dense なモデルであり、SQuAD 等で訓練されたモデルを用いる
- Reader による抽出の作業等でコストがかかるため、ドキュメント全部を走査するのではなく、500単語程度の Passage 単位にデータを分割するのがよいとされている
- 参考: https://docs.haystack.deepset.ai/docs/optimization#document-length
- テキストを Passage に分割したところで、メタデータとして記事IDや記事タイトルなを持たせれば、もとのソースを引くことは容易である
- つまり、同じタイトル情報を持つが本文情報は異なるドキュメントが複数あったりする
- また、メタデータも検索対象にしてもよい(というか、したほうがよい)
- Haystack でも、タイトル等はメタ情報に入れている
今回作成した検証用コードについて
https://github.com/Shingo-Kamata/japanese_qa_demo_with_haystack_and_es について
解説
- README に書いているとおりだが、既存の Elasticsearch もしくは sample_es を利用し Open-book な Question Answering を行う
- sample_es には検証用の Elasticsearch を構築するための方法を記載
- Retriver は通常のBM25で行い、Reader は JaQuAD で学習した日本語のモデルを利用
工夫した点、考慮した点、苦労した点
- sample_es に関して
- 日本語使うので、Elasticsearch に日本語プラグイン入れる手順を書いた
- 上で述べたとおり、単語数の上限を考えたほうが良いので、400単語分割するようにした
- ただし、英語と日本語でこのあたり同じなのかは怪しい
- ドキュメントに タイトルや URL のメタ情報を含めた
- タイトルや URL で Aggregation して一覧を見たくなるだろうから、それらの Mapping には Keyword 型も用意した
- haystack_qa.py に関して
- 動作確認して、ElasticsearchDocumentStore の引数の指定を見繕った
- 初回モデル DL したら、それを Local に保存して再利用するようにした
- README にも書いたが、 content_type の問題が結構厳しくて、最終的にある程度 haystack のコードを読んで workaround を記載した
動作テスト
- 今回は sample_es につなげて検証
- Wikipedia の記事も、sample_es の README にある dump を利用
- GPU 使えば瞬時に回答が帰ってくるので、速度は○
- CPU 環境でも試したが、速度は遅いが結果は全く同じであった
- そもそも、ソースに何があるかを確認(タイトルで集約)した
curl -H "content-type: application/json" -XPOST localhost:9200/ja/_search -d '{ "size": 0, "aggs": { "types": { "terms": { "field": "title.keyword", "size": 1000 } } } }'- この集約結果から、どのような記事があるかを確認した
- いい感じかもの例(関連したタイトルの記事があるのを上の集約結果から確認済み)
Query: 忠臣蔵の主人公は? Answers: [ <Answer {'answer': '大石内蔵助', 'type': 'extractive', 'score': 0.8082048296928406, 'context': 'ビ時代劇ご存知旗本退屈男子連れ狼名奉行大岡越前隠密奉行朝比奈剣客商売主演代表作多いテレビ東京新春ワイド時代劇正月時代劇主演俳優定番1人忠臣蔵主人公大石内蔵助忠臣蔵最後忠臣蔵忠臣蔵瑤泉院陰謀3回演じる他勝海舟2回徳川家康4回同じ人物複数回演じる多い近年時代劇専門チャンネル放映三屋清左衛門残日録主演幼い', 'offsets_in_document': [{'start': 437, 'end': 442}], 'offsets_in_context': [{'start': 73, 'end': 78}], 'document_id': 'vfpOJYUBLyfAJxXYLLe9', 'meta': {'article_id': '172458', 'revid': '92630170', 'url': 'https://ja.wikipedia.org/wiki?curid=172458', 'title': '北大路欣也'}}>, <Answer {'answer': '須賀 貴匡', 'type': 'extractive', 'score': 0.8008686304092407, 'context': '須賀 貴匡(すが たかまさ、1977年10月19日 - )は、日本の俳優。東京都江戸川区出身。ラ・セッテを経て、2019年12月からフリーで活動している。\n来歴.\n高校卒業後は様々なアルバイトをしながら俳優養成所に通っていた。当時は父親から「実家の寿司屋を継がないなら出て行け」と言われ、家を追い出さ', 'offsets_in_document': [{'start': 0, 'end': 5}], 'offsets_in_context': [{'start': 0, 'end': 5}], 'document_id': 'rvlNJYUBLyfAJxXYyd4l', 'meta': {'article_id': '302410', 'revid': '1713277', 'url': 'https://ja.wikipedia.org/wiki?curid=302410', 'title': '須賀貴匡'}}>,Query: 鳥羽・伏見の戦いは何年に起きた? Answers: [ <Answer {'answer': '1868年の', 'type': 'extractive', 'score': 0.9833235740661621, 'context': '.\n以下は歴代の伏見奉行および在任期間の一覧である。\n奉行所.\n1625年にそれまで奉行所が置かれていた清水谷から富田信濃守屋敷跡に移転。以後、1868年の鳥羽・伏見の戦いで焼失するまで、江戸時代を通して奉行所が置かれた。\n跡地は現在は京都市営桃陵団地となっている。現地には碑があるのみとなっている。', 'offsets_in_document': [{'start': 416, 'end': 422}], 'offsets_in_context': [{'start': 72, 'end': 78}], 'document_id': 'tvtOJYUBLyfAJxXYgVa2', 'meta': {'article_id': '346830', 'revid': '244805', 'url': 'https://ja.wikipedia.org/wiki?curid=346830', 'title': '伏見奉行'}}>, <Answer {'answer': '戊辰戦争', 'type': 'extractive', 'score': 0.9626041054725647, 'context': 'え、弘化3年(1846年) - 慶応4年8月21日(1868年10月6日))は、陸奥国弘前藩出身の新選組隊士。歩兵差図役下役。\n慶応3年(1867年)頃、新選組へ入隊。局長近藤勇の側近を務める。\n戊辰戦争が起こると、鳥羽・伏見の戦い、甲州勝沼の戦い、会津戦争に転戦。母成峠の戦いで戦死した。享年23。', 'offsets_in_document': [{'start': 110, 'end': 114}], 'offsets_in_context': [{'start': 98, 'end': 102}], 'document_id': 'IvlNJYUBLyfAJxXYws-3', 'meta': {'article_id': '297094', 'revid': '1736073', 'url': 'https://ja.wikipedia.org/wiki?curid=297094', 'title': '千田兵衛'}}>, - 微妙な例
- そもそもまったく関連記事がない質問
Query: モルカーの主人公は? Answers: [ <Answer {'answer': 'g', 'type': 'extractive', 'score': 0.9396477341651917, 'context': 'ち1 molの電子を授受する酸化剤・還元剤のグラム数を1グラム当量とする。\n例えば、2価の酸である硫酸の分子量を98とすると、硫酸の1グラム当量は49 gである。98 gの硫酸は2グラム当量となる。初歩の学習者にはが見受けられるので注意されたい。\nモル当量.\n化学反応において、反応物のあいだの量的関', 'offsets_in_document': [{'start': 704, 'end': 705}], 'offsets_in_context': [{'start': 75, 'end': 76}], 'document_id': 'Q_lNJYUBLyfAJxXYnobj', 'meta': {'article_id': '212231', 'revid': '1866007', 'url': 'https://ja.wikipedia.org/wiki?curid=212231', 'title': '化学当量'}}>, <Answer {'answer': 'イオン強度', 'type': 'extractive', 'score': 0.9150944948196411, 'context': 'イオン強度(いおんきょうど)とは、電解質溶液の活量係数とイオン間の相互作用を関係づけるための概念で、溶液中のすべてのイオン種について、それぞれのイオンのモル濃度formula_1と電荷formula_2の2乗の積を加え合わせ、さらにそれを1/2にしたものである。例えば、2価の陽イオンと2価の陰イオン', 'offsets_in_document': [{'start': 0, 'end': 5}], 'offsets_in_context': [{'start': 0, 'end': 5}], 'document_id': 'avlNJYUBLyfAJxXYei5x', 'meta': {'article_id': '270147', 'revid': '1037035', 'url': 'https://ja.wikipedia.org/wiki?curid=270147', 'title': 'イオン強度'}}>,- 関連記事があるのに回答がよくない
Query: 千葉真一の職業は? Answers: [ <Answer {'answer': '富三郎', 'type': 'extractive', 'score': 0.9076371192932129, 'context': '京都中野区にジャパン・アクション・クラブ ("JAC" ) を創設。1973年11月、東京都港区六本木に資本金150万円で法人化した。結成式には若山富三郎が駆けつけてお祝いをしていた。\n初期は千葉主演の映画・テレビドラマに、大葉健二・金田治・西本良治郎・春田純一・山岡淳二など第一期生らが数人単位で出', 'offsets_in_document': [{'start': 277, 'end': 280}], 'offsets_in_context': [{'start': 74, 'end': 77}], 'document_id': 'dPtOJYUBLyfAJxXYVgRd', 'meta': {'article_id': '132503', 'revid': '92495967', 'url': 'https://ja.wikipedia.org/wiki?curid=132503', 'title': 'ジャパンアクションエンタープライズ'}}>, <Answer {'answer': '『風雲 ストームライダーズ』', 'type': 'extractive', 'score': 0.7904555797576904, 'context': '香港電影金像奨は、香港で毎年春に開催される、中華圏で最も有名な映画賞の授賞式典の一つ。日本では香港アカデミー賞とも称される。1999年に催された第18回では千葉真一が『風雲 ストームライダーズ』で、外国人として初めてにノミネートされた。', 'offsets_in_document': [{'start': 83, 'end': 97}], 'offsets_in_context': ...
備考
- Haystack に Chatbot との連携もあるらしい(すげー)
- 同僚が(Haystackとは)別に試した手法として、Elasticsearch で BM25Retriever して、Reader モデルに GPT-3 を使うという方法もいい感じに動いていた
- GPT 汎用すぎてやばい。。。
感想
- 上にも書いたが、サービスを実際に触ると、理論的な勉強にもなる(Elasticsearch 触って、Analyzer の概念や、Synonym の概念等一般的な全文検索の教養が身につくように)ため、それは今回トライしてよかった部分である
- そもそも、自分は Retriever-Reader モデルですら知らなかった
- Retriever 対象フィールドと Reader の対象フィールドが必ずしも一致しない(というか変化しうる可能性があるということ)を知った
- Passage 分割が必要だということを知った
- 結果はあと一歩な感じで、Weavitate で英語のデモを試したときは、 Dense Retriver も使えたこともあってかなかなかの精度だったので、もう少し Haystack の日本語でも精度をあげたい
- だけど、全くだめではなく、年代を聞けば年代を返すし、誰かを尋ねたら人の名前的なものをは返してくれる
- Passage 分割方法(前処理)の修正や、Haystack にも Dense Retriever を利用する方法がある(Retriever モデルがあればだが)のでそれも試してみたい
- 日本語特有の問題もありつつも、基本的には、 Weavitate も Haystack もやったことはすごく似ていたので、今後同じような Question Answering システムを構築する際には、何をすればよいかある程度わかるという自信が持てた
余談: Platformer 以外が Quesiton Answering システムを構築する意義はあるのか? について考察してみた
今回、Haystack を用いて、 Open-book な Question Answering システムを構築したが、そもそもそれが意義があることなのかを考察してみた
- 一般の知識ソースを利用するような Domain については、Platformer(GAFAM、OpenAI 等)に勝てるはずがないし勝つ意義もない
- ChatGPT すごすぎ。。。
- そういえば2月に GPT-4 もでるのか
- ただ、別に ChatGPT 出る前から、一般の知識は Google で検索していた(し、これからも Google も使うのは間違いない)
- ChatGPT すごすぎ。。。
- 一方で、Google があるのに、Elasticsearch や OpenSearch が各所で利用されているように、自前の検索は廃れるどころか、技術書もそれなり出ており、需要は増しているようにすら思える
- 検索システム ― 実務者のための開発改善ガイドブック 買いました、いい本ですよ!
- Elasticsearch 等の需要があるのは、(Question Answering について の章でも書いたように)おそらく一般に公表できない( Google のサーバにクローリングさせられない)情報が各社各サービスごとにあり、それらにの検索は自前で実装する必要があるということ
- 「Shingo Kamata の住所は?」に、GoogleもChatGPTも答えられないし、答えられてはいけない
- あるいは、Google がクローリングできたとしても、データ数が少なく過ぎて適切にランキングできないという場合もあるかもしれない
- 別の言い方をすれば、Google という最強の存在がいるにもかかわらず、自分みたいな検索エンジニアにも一定の需要がある理由とも言えそう
- 同様のアナロジーで、いくら ChatGPT や Google があっても、例えば社内ドキュメントをベースとした Question Answering の需要等は一定あるのではないだろうか?
- 上で述べたように、○○さんの住所は? や、取引先に関する質問等
- あとは、Slack の過去の投稿を知識に Question Answering できても良さげな気がする
- ただ、そのニーズに応えるのは、今回紹介したような Retriver-Reader なスタイルではないかもしれないが、適用しやすさ(コストのやすさ)と、Evidence がとれるということから、直近では今回のものでも役立ちそう
- ただし、ChatGPT でもわかってきたように、そもそも検索というスタイルが UX 的に悪くチャット型がもとめられる可能性はありそう
- タクソノミー型が重要視されてくるかもしれない
- とはいえ、上で述べたように Haystack では Chatbot との連携もあるので、知見を役立てられそうな部分はある
- ただし、ChatGPT でもわかってきたように、そもそも検索というスタイルが UX 的に悪くチャット型がもとめられる可能性はありそう
- むしろ、Question Answering が真に必要かを問われるのは(真の競合は)、ChatGPT みたいなものより、「既存の検索でことたりる」ことではないだろうか?
- 例えば、「Shingo Kamata が物理出社した日はいつ?」という質問は、知識がある人には、Slackで
from: @shingo_kamata in: office_channel 出社しますの検索ができれば必要ない - (Open-book な)Question Answering システムがより価値を出すためには、以下のようなことができると良さそう
- non-factoid 型の質問にも対応できるようにする
- 複数の Passage から自動推論して、単一 Passage だけでは回答ができない質問も回答ができるようにする(例えば、「A社のCEOはBさん」、「AはCに社名変更」 という2つの Passage から、C社のCEOに関してBさんと回答できる 等)
- そもそも仕組み的には Open-book な手法では難しい可能性もありつつ、GPT-3 ではこれらもある程度できているので。。。
- 例えば、「Shingo Kamata が物理出社した日はいつ?」という質問は、知識がある人には、Slackで
なので、ここでの結論としては、「通常の検索の体験を真に上回ることができるのならば、(Platformer 以外でも) Question Answering サービスの構築をすることの価値はある」 とする。
Discussion