🌭
『JavaScript関数型プログラミング 複雑性を抑える発想と実践法を学ぶ』を読んだ 02
01からのつづき
Part 2: 関数型デザインとコーディング
- Part 1では、「なぜ関数型なのか」「なぜJavaScriptなのか」に回答した
- Part 2では、実世界の問題を解決することを目的とする
- 「関数型を理解する」ことがどういうことなのかを学ぶ
- 第3章では、容易に把握できるコードを作成することを目標とする
-
map, reduce, filterなどの宣言的で抽象化された関数を利用する - 関数型のスタイルで再帰を利用する方法も紹介する
-
- 第4章では、第3章で学んだ概念を関数のパイプライン化に適用して、開発を合理化したり、ポイントフリースタイルでプログラムを記述したりする方法を見ていく
- 複雑なタスクを独立した小さいコンポーネントに分割し、合成し、完全な解決策にすることができる
- この結果、モジュール性が高く再利用可能なコードベースが得られる
- 第5章では、アプリケーションで増加する複雑性に対して効果を発揮する、基本的なデザインパターンとエラー処理について学ぶ
- 関数の合成は、ファンクターやモナドなどの抽象データ型によって、より信頼度が高くなり、堅牢となる
- コードは耐故障性(フォールトトレラント性)を備え、例外の状態からの回復力を増すことができる
- Part 2で学ぶテクニックでJavaScriptのコードの記述方法を一致させることができる
- Part 3では、関数型プログラミングのテクニックを適用して、非同期データや非同期イベントなど、さらに複雑なJavaScriptの問題の解決方法を学ぶ
第3章 データ構造の数を減らし、操作の数を増やす
- 本章のテーマ
- プログラムの制御とフローを理解する
- コードやデータについて効率的に把握する
-
map, reduce, filterの威力を解き放つ - Lodashライブラリおよび関数チェーンを理解する
- 再帰的に考える
- Part 1では、2つの目標を達成することができた
- 第1章と第2章を通して、関数型で考える方法を学び、また関数型プログラミングにおいて必要となるツールを理解した
- JavaScriptのコア機能や高階関数について詳細に学んだ
- 純粋な関数の作り方は理解できたはずなので、今度はそれらを接続する方法を学ぶ
-
map, reduce, filterを紹介する- これらを利用すると、逐次的にデータ構造を走査、変換することが可能になる
- ほとんどのループを実現できるため、手動で記述するループをコードから削除することができる
- これらを利用すると、逐次的にデータ構造を走査、変換することが可能になる
- 再帰が関数型プログラミングにおいて果たす重要な役割と、再帰的に考える利点について説明する
- コードの制御フローとメインのロジックを明確に分離できる
- シンプルで拡張可能かつ宣言的なプログラム書き方を身につけることができる
アプリケーションの制御フローを理解する
- アプリケーションの制御フローを理解する
- プログラムが解決に至るまでの実行パスは、制御フローとして知られている
- 命令型プログラム
- 命令型プログラムでは、きわめて詳細に処理のフローやパスを記述する
- タスクの遂行に必要となるステップをすべて明確にする
- ステップにはループや分岐や命令文の実行とともに変化する変数が含まれる
-
命令型プログラムの例
var loop = optC(); while (loop) { var condition = optA(); if (condition) { optB1(); } else { optB2(); } loop = optC(); } optD(); 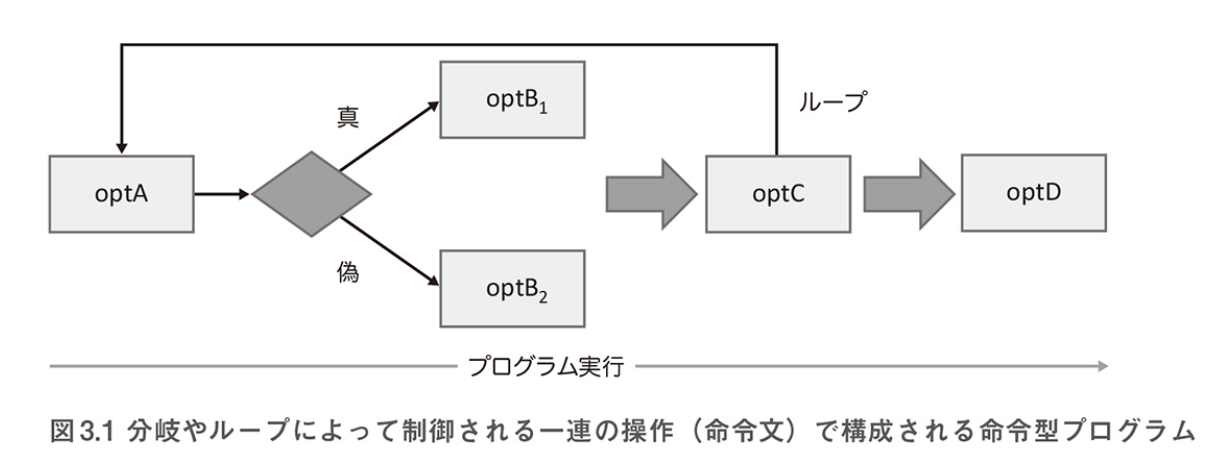
- 命令型プログラムでは、きわめて詳細に処理のフローやパスを記述する
- 関数型プログラム
- 関数型プログラムでは最小限の構造からなるフローを利用することで抽象度を上げる
- 独立したブラックボックス処理が簡単なトポロジーで接続される
- 接続された処理は、状態をある処理から次の処理に移す高階関数にすぎない
- 配列などのデータ構造を関数で処理していく
- データと制御フローは、抽象度の高いコンポーネント間でのシンプルな接続とみなされる
-
関数型プログラムの例
optA().optB().optC().optD(); 
- 命令型プログラム
- プログラムが解決に至るまでの実行パスは、制御フローとして知られている
メソッドチェーン
- メソッドチェーン
- メソッドチェーンとは
- メソッドチェーンは複数のメソッドを1つの命令文内で呼び出すことのできるオブジェクト指向プログラミングのパターンである
- メソッドがすべて同じオブジェクトに属する場合、メソッドカスケードと呼ばれる
- 不変オブジェクトと連携する場合などは、関数型プログラミングにおいても利用することができる
-
文字列処理の例
/* 関数substringとtoLowerCaseは文字列メソッドである 保持する文字列オブジェクトに対して(thisを用いて)処理し、 新しい文字列を返す これらの変換を適用した結果は、元の文字列とは関係のない文字列であり、 元の文字列はそのままの状態となる 関数型プログラミングの観点から見ると、元の文字列が変更されないことで、 文字列処理のためのレンズが必要なくなる */ "Functional Programming".substring(0, 10).toLowerCase() + "is fun"; /* 上記のコードをリファクタリングする 「引数はすべて関数宣言内で明示的に定義しなければならない」という 関数型の原則に従っており、副作用はなく、元のオブジェクトを変異させない ただ、関数を内側から外側に向かって記述することは、JavaScriptのコードとしては メソッドチェーンほど円滑ではない 可読性の面でもメソッドチェーンに劣ってしまう */ concat(toLowerCase(substring("Functional Programming", 1, 10)), "is fun");
- メソッドチェーンは複数のメソッドを1つの命令文内で呼び出すことのできるオブジェクト指向プログラミングのパターンである
- メソッドチェーンとは
関数チェーン
- 関数チェーン
-
コードの再利用メカニズム
- オブジェクト指向プログラムは、コードの再利用メカニズムとして継承を利用する
- StudentはPersonを継承し、状態とメソッドはすべてこのサブタイプに継承される
- 関数型プログラミングは、個別の要求を満足させる新しいデータ構造クラスを作成する代わりに、配列などの一般的なデータ構造を利用する
- 基本となるデータの表現に依存しない、粒度の粗い高階な処理を数多く適用する
- 関数型プログラミングの設計
- 個別の要求を実現するために、関数が別の関数を引数としてとることを許容する
- 手動で記述するループを置き換えることで、保守対象のコード量を削減し、エラーが発生する可能性のある箇所を減らす
- 本章の例題はPersonオブジェクトの集合に基づいて記述している
-
Personオブジェクトの集合
const p1 = new Person("Haskell", "Curry", `111-11-1111`); p1.address = new Address("US"); p1.birthYear = 1900; const p2 = new Person("Barkley", "Rosser", `222-22-2222`); p2.address = new Address("Greese"); p2.birthYear = 1907; const p3 = new Person("John", "von Neumann", `333-33-3333`); p3.address = new Address("Hungary"); p3.birthYear = 1903; const p4 = new Person("Alonzo", "Church", `444-44-4444`); p4.address = new Address("US"); p4.birthYear = 1903;
-
- オブジェクト指向プログラムは、コードの再利用メカニズムとして継承を利用する
-
ラムダ式を理解する
- ラムダ式とは
- 関数型プログラミングから派生したラムダ式は、JavaScriptの世界ではアロー関数と呼ばれる
- ラムダ式は、常に値を返すように求める
-
fullnameを抽出する例
const name = (p) => p.fullname; console.log(name(p1)); //=> 'Haskell Curry' -
nameは具体的な値を指すのではなく、その値を遅延して取得する方法を指す-
nameはこのデータの計算方法を知っているアロー関数を指しているということになる - これが、関数型プログラミングにおいて関数を値として利用することができる理由である
-
- 関数型プログラミングから派生したラムダ式は、JavaScriptの世界ではアロー関数と呼ばれる
- 関数型プログラミングは、ラムダ式と協調して動作する代表的な3つの高階関数、
map, reduce, filterの利用を推奨する- 関数型のJavaScriptのコードの多くは、データのリスト処理が基本となるため
- JavaScriptの派生元であり、その原型でもある言語はLISP(リスト処理: list processing)である
- Lodashのツールキットを使用する
- LodashはUnderscore.jsから派生したもの
- ラムダ式とは
-
_.mapを使ってデータを変換する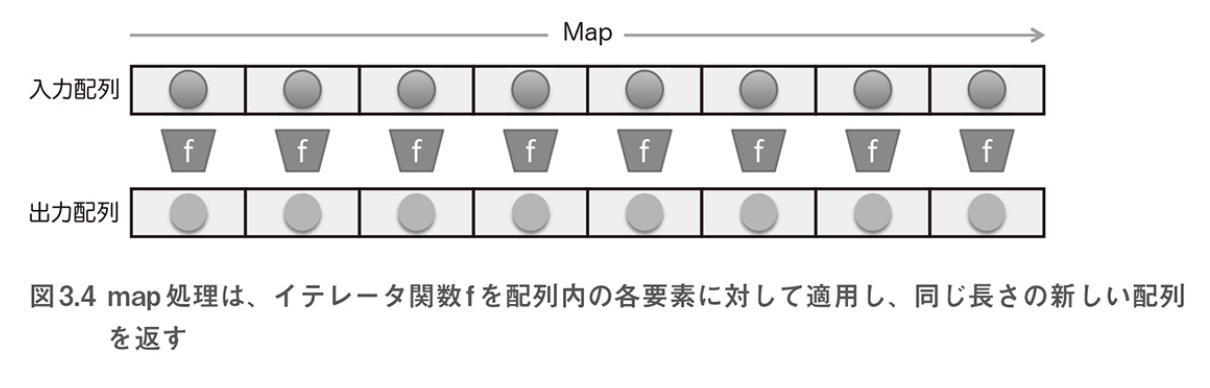
- 学生オブジェクトのリストが与えられ、学生の氏名をすべて抽出したい場合の例
-
命令型アプローチと関数型アプローチ
/* 命令型プログラミングのアプローチ */ var result = []; var persons = [p1, p2, p3, p4]; for (let i = 0; i < persons.length; i++) { let p = persons[i]; if (p !== null && p !== undefined) { result.push(p.fullname); } } /* 関数型プログラミングのアプローチ mapは、単に左から右への処理となる map(f, [e0, e1, e2...]) -> [r0, r1, r2...]; where, f(dn) = rn */ _.map(persons, (s) => (s !== null && s !== undefined ? s.fullname : "")); //=> ['Haskell Curry', 'Barkley Rosser', 'John von Neumann', 'Alonzo Church'] /* mapの内部実装 内部的には、_.map関数は標準的なループが基本となっている この関数は、イテレーションを肩代わりしてくれるので、 ループ変数のインクリメントや、境界条件のチェックに気を使う必要がなくなる */ function map(arr, fn) { const len = arr.length, result = new Array(len); for (let idx = 0; idx < len; ++idx) { result[idx] = fn(arr[idx], idx, arr); } return result; } /* Lodashの_.reverseを使う例 _(...)の表記内にオブジェクトをラッピングしてしまってから、 オブジェクトに対して必要となる変換を適用する */ _(persons) .reverse() .map((p) => (p !== null && p !== undefined ? p.fullname : ""));
-
-
_.reduceを使って結果を集める- データの変換方法は理解できたので、変換したデータから意味のある結果を集める方法を見ていく
-
Personオブジェクトの集合から最も人数の多い国名を知りたいという例など
-
-
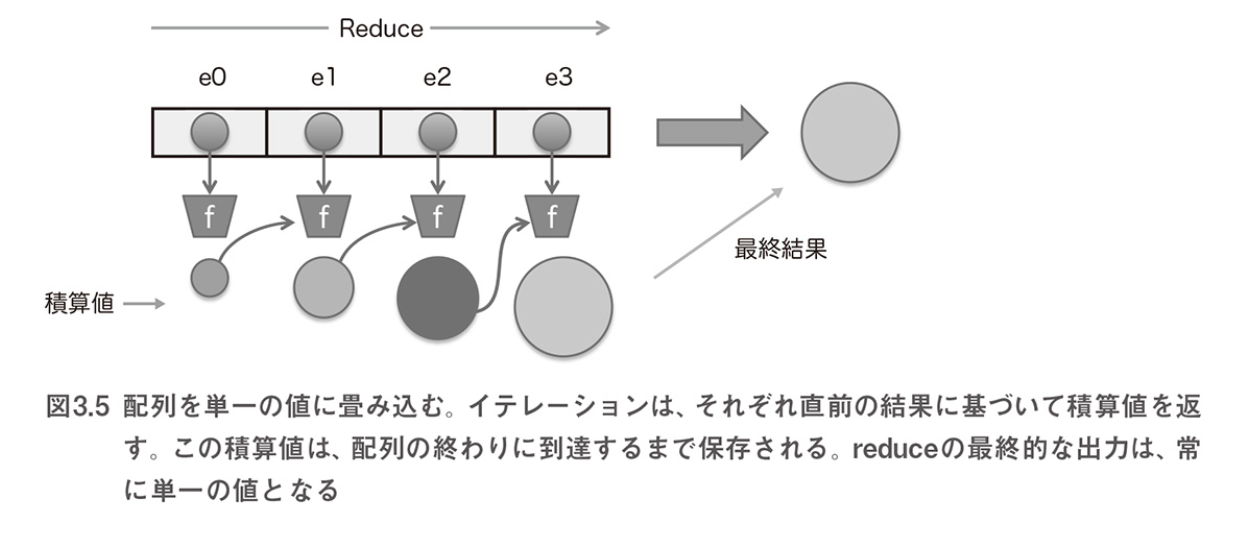
reduce関数を利用する-
reduceは、配列の要素を単一の値に圧縮する高階関数である - 圧縮された値は、各要素に対して関数を適用し、その結果をアキュムレータ(積算器)に加算して計算される
-
reduce関数
reduce(f, [e0, e1, e2, e3], accum) -> f(f(f(f(acc, e0), e1, e2, e3))) -> R /* reduceの内部実装 fn - イテレータ関数は、配列内のすべての値に対して実行される accumulator - アキュムレータの初期値であり、後続の関数呼び出しに 渡される積算結果を保存するのに利用される */ function reduce(arr, fn, accumulator) { let idx = -1, len = arr.length; if (!accumulator && len > 0) { accumulator = arr[++idx]; } while (++idx < len) { accumulator = fn(accumulator, arr[idx], idx, arr); } return accumulator; } /* ある国に在住する人数を知りたい場合 reduceを利用して国別の人数を計算する */ _(persons).reduce((stat, person) => { const country = person.address.country; stat[country] = _.isUndefined(stat[country]) ? 1 : stat[country] + 1; return stat; }); //=> { US: 2, Greece: 1, Hungary: 1 } /* 汎用性のあるmapとreduceを組み合わせて、 このタスクをさらに単純化することができる _(persons).map(func1).reduce(func2); 配列のオブジェクトを前処理した後、すべての国を抽出するのに mapを使用する。 そして、最終結果を集めるのにreduceを使用する */ const getCountry = (person) => person.address.country; const gatherStats = function (stat, criteria) { stat[criteria] = _.isUndefined(stat[criteria]) ? 1 : stat[criteria] + 1; return stat; }; _(persons).map(getCountry).reduce(gatherStats, {}); //=> { US: 2, Greece: 1, Hungary: 1 } /* 直接プロパティにアクセスする代わりに、 personのaddress.cityプロパティに注目して、 レンズ機能を利用する */ const cityPath = ["address", "city"]; const cityLens = R.lens(R.path(cityPath), R.assocPath(cityPath)); _(persons).map(R.view(cityLens)).reduce(gatherStats, {}); //=> { Princeton: 2, Athens: 1, Budapest: 1 } /* 代わりに、_.groupByを使用して さらにシンプルにすることができる */ _.groupBy(persons, R.view(cityLens)); /* reduceは積算結果に依存するので、 可換的演算が提供されなければ、 異なる振る舞いをする可能性がある 加算は可換的演算なのでreduce関数を 逆向きに実行しても同じ結果が得られる reduceRight(f, [e0, e1, e2], accum) -> f(e0, f(e1, f(e2, f(e3, accum)))) -> R */ _([0, 1, 3, 4, 5]).reduce(_.add); //=> 13 /* 割り算のように可換的計算ではない処理の場合は、 結果が異なる */ [1, 3, 4, 5].reduce(_.divide) !== [1, 3, 4, 5].reduceRight(_.divide); //=> true /* さらに、reduceは配列のすべての要素に適用される 配列全体を操作しないように処理を途中で省略することは できない たとえば、不正入力が見つかった時点で検査を続ける必要はないため、 _.some、_.isUndefined、_.isNullなどを利用した効率的な 評価関数を実装することができる */ const isNotValid = (val) => _.isUndefined(val) || _.isNull(val); const notAllValid = (args) => _(args).some(isNotValid); notAllValid(["string", 0, null, undefined]); //=> true notAllValid(["string", 0, []]); //=> false const isValid = (val) => !_.isUndefined(val) && !_.isNull(val); const allValid = (args) => _(args).every(isValid); allValid(["string", 0, null]); //=> false allValid("string", 0, []); //=> true
-
- データの変換方法は理解できたので、変換したデータから意味のある結果を集める方法を見ていく
-
_.filterを使って不要な要素を除去する- 大規模なデータの集合を処理するときは、if-elseなどの条件文の代わりに、
_.filterを利用できる - filterとは
- filter(別名selectとしても知られている)は高階関数であり、返される新しい配列は元の配列のサブセットである
- 述語関数(predicate関数とも呼ばれるbool型の戻り値を持つ関数)pがtrueとなる値を返す
filter(p, [d0, d1, d2, d3...dn]) -> [d0, d1,...dn](元の入力のサブセット)
- 宣言的なスタイルを使用することで、どのような方法で結果を得るのかではなく、実行結果がどうなるのかに集中できるようになる
- これにより、アプリケーションをより深く把握することができる
- filterの実装
- filterは、配列に加えて、各要素の選択基準を満たすかどうかをテストするpredicate関数を引数として受け取る
-
filterの使用例
/* フィルターの内部実装例 */ function filter(arr, predicate) { let idx = -1, len = arr.length, result = []; while (++idx < len) { let value = arr[idx]; if (predicate(value, idx, this)) { result.push(value); } } return result; } /* 配列から無効なデータを除去するのに filter関数が広く利用されている */ _(persons).filter(isValid).map(fullname); /* filterを適用することで、if文などの条件文を 省略することができる */ const bornIn1903 = (person) => person.birthYear === 1903; _(persons).filter(bornIn1903).map(fullname).join(" and "); //=> 'John von Neumann and Alonzo Church'
- 配列内包表記(Array comprehension)
- HaskellやClojureなどの関数型言語に存在する
- JavaScriptではES7で提案されたことがある
- mapとfilterの結合は、配列内包表記やリスト内包表記(list comprehension)という概念を利用することでも可能となる
-
配列内包表記
/* 1903年生まれの人を抽出するコードを 配列内包表記でリファクタリングする例 配列内包表記 [for (x of iterable) if (condition) x]; */ [for (p of people) if (p.birthYear === 1903) p.fullname].join(" and ");
- HaskellやClojureなどの関数型言語に存在する
- 大規模なデータの集合を処理するときは、if-elseなどの条件文の代わりに、
-
コードの再利用メカニズム
コードを把握する
- コードを把握する
-
コードを把握することについて
- JavaScriptでは、グローバルに名前空間を共有する数千行のコードを一度に、メモリ空間の単一のページにロードすることが可能である
- コードを把握するとは
- プログラムをすみずみまで見渡して、何が行われているかについて簡単にメンタルモデルを構築する能力を意味する
- このモデルには、すべての変数の状態、関数の結果などの動的な部分と、設計の可読性および表現力のレベルなどの静的な部分が含まれる
- 本書では、不変性と純粋関数によって、このモデルを簡単に構築できることを学ぶ
- 関数型のフローはプログラムの内部的な詳細について明らかにすることなく、その目的を明確にすることができる
- これは命令型プログラムのフローとは根本的に異なる点である
- コードだけではなく、データがステージ間を流れていき、結果が生成される様子を、より解像度高く理解できるようになる
-
宣言型および遅延関数チェーン
- 第1章では、それ自体では単純な関数を組み合わせることで複雑なタスクを行うことができるということを学んだ
- 本節では、一連の関数を接続することで完全なプログラムを構築する方法を学ぶ
- 関数型プログラムの宣言モデルは、独立した純粋関数を評価するのがプログラムであるとみなす
- このモデルは、円滑で表現力豊かなコードを書くことができる抽象を実現できる
- 抽象の実現により、アプリケーションの意図を明示的にする仕様(オントロジー)や用語を確立することができる
-
map, reduce, filterのビルディングブロック上に純粋関数を構築することで、コードを簡単に把握でき、一目で理解できるようなスタイルでプログラムを書くことができる
- 抽象度を上げることによる効果
- 使用する基本データ構造とは無関係に、処理のみを考えることが可能になる
- 関数型プログラミングはデータ構造よりもその処理に重点をおく
- 使用する基本データ構造とは無関係に、処理のみを考えることが可能になる
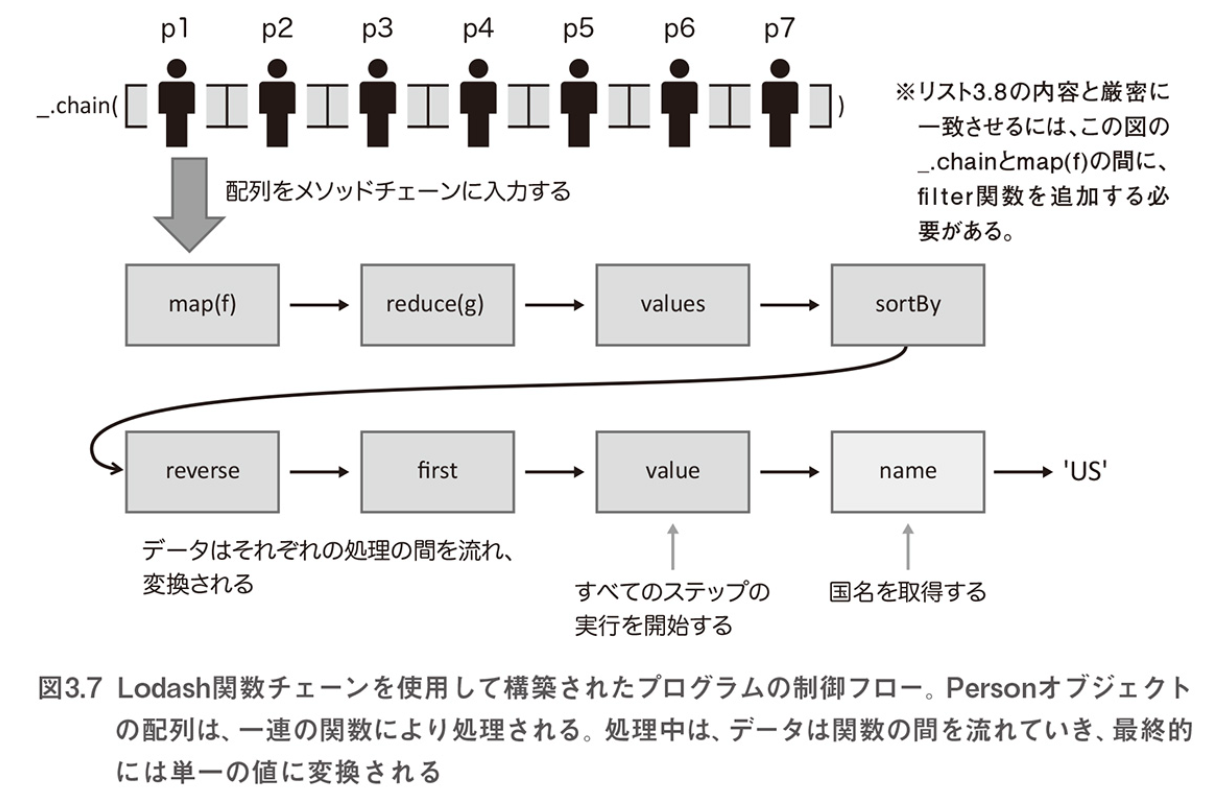
- 名前のリストを読み込んで、正規化し、重複を排除し、得られた結果をソートするというタスクの例
-
命令型と関数型のアプローチの違い
/* 命令型アプローチの例 固有な問題を効率的に解決することを 目的としている よって、関数型コードと比較して、特定のタスクを解決するためだけに 利用できるようなコードとなりやすい(抽象度が低い) 抽象度が低くなるほど再利用の可能性は低下し、 複雑性とエラーの可能性が増すことになる 配列に対して逐次実行するなど */ var result = []; for (let i = 0; i < names.length; i++) { var n = names[i]; if (n !== undefined && n !== null) { var ns = n.replace(/_/, " ").split(" "); for (let j = 0; j < ns.length; j++) { var p = ns[j]; p = p.charAt(0).toUpperCase() + p.slice(1); ns[j] = p; } if (result.indexOf(ns.join(" ")) < 0) { result.push(ns.join(" ")); } } } result.sort(); //=> ['Alonzo Church', 'Haskell Curry', 'John Von Neumann', 'Stephen Keene', 'Stephen Kleene'] /* 関数型アプローチの例 ブラックボックスのコンポーネントを互いに接続しているだけ コンポーネントはテスト済みのAPIを流用する 関数呼び出しをカスケード状に並べることによって、 コードの可読性も増すことができる filter, mapの関数は、names配列内の有効なインデックスによる 最も手間のかかる繰り返しの処理をやってくれる 残されているのは、繰り返し以外のステップについて個別の振る舞いを 記述することのみになる これにより、コード量が削減できるだけではなく、構造が簡潔かつ クリアになる */ _.chain(names) .filter(isValid) .map((s) => s.replace(/_/, " ")) .uniq() .map(_.startCase) .sort() .value(); //=> ['Alonzo Church', 'Haskell Curry', 'John Von Neumann', 'Stephen Keene', 'Stephen Kleene'] /* Lodashを使ったアプローチの例 Personオブジェクトの配列に含まれる国名と その人数を計算する _.chain関数はで接続することで、明示的に配列内の 任意の関数をチェーン化することができる 任意の変数を作成する必要がなく、ループもすべて除去される また、_.chainでは最後のvalue関数が呼び出されるまで 何も実行されないため、、遅延動作するプログラムを作成することが できる これは結果が必要なければ、関数全体の実行を省略できるということを意味する */ const gatherStats = function (stat, country) { if (!isValid(stat[country])) { stat[country] = { name: country, count: 0 }; } stat[country].count++; return stat; }; // この関数は以下の構造を持つオブジェクトを返す // { // US: { name: 'US', count: 2 }, // Greece: { name: 'Greece', count: 1 }, // Hungary: { name: 'Hungary', count: 1 } // } const p5 = new Person("David", "Hilbert", "555-55-5555"); p5.address = new Address("Germany"); p5.birthYear = 1862; const p6 = new Person("Alan", "Turing", "666-66-6666"); p6.address = new Address("England"); p6.birthYear = 1912; const p7 = new Person("Stephen", "Kleene", "777-77-7777"); p7.address = new Address("US"); p7.birthYear = 1909; /* このデータセット内で最大の人数が所属する国名を 返すプログラムを作成する */ _.chain(persons) .filter(isValid) .map(_.property("address.country")) .reduce(gatherStats, {}) .values() .sortBy("count") .reverse() .first() .value().name; //=> 'US'
- Lodashライブラリは、ポイントフリーと呼ばれるプログラミングスタイルへの移行を可能にする
- 次章で詳しく紹介する
- プログラミングパイプラインで遅延して定義できることの利点
- 遅延プログラムは評価される前に定義されるので、データ構造の再利用やmethod fusion(複数のメソッドを1つに融合して、高速化を図る機能)などのテクニックで最適化することができる
- これにより、不要な処理の呼び出しを排除できる
- 高階関数を宣言的に利用することにより、ネットワーク内のあるノードから次のノードへ流れていくデータの経路が明確になり、データ自体の本質を明らかにすることができる
- 第1章では、それ自体では単純な関数を組み合わせることで複雑なタスクを行うことができるということを学んだ
-
SQLライクなデータ: 関数としてのデータ
-
map, reduce, filter, groupBy, sortBy, uniqなどの関数がSQLに似ていることに気が付く- SQLの利用者は、データからその意味を理解することに慣れている
-
Personオブジェクトの集合をテーブル形式で表すことができる
- SQLの用語で考えることは、関数型プログラミングで配列に処理を適用することに似ている
-
/* SQLのクエリを書く場合、 コードの実行結果として、どのようなデータを 期待しているかが明瞭である */ SELECT p.fistname FROM Person p WHERE p.birthYear > 1900 and p.country IS NOT 'US' ORDER BY p.firstname -
SQLライクなJavaScriptを記述する
/* Lodashはミックスイン(mixin)をサポートしている ミックスイン機能を使うと、コアライブラリを拡張する形で 機能を追加することができる */ _.mixin({ select: _.map, from: _.chain, where: _.filter, sortBy: _.sortByOrder, }); /* ミックスインオブジェクトを適用して SQLライクなJavaScriptを記述する */ _.from(persons) .where((p) => p.birthYear > 1900 && p.address.country !== "US") .sortBy(["firstname"]) .select((p) => p.firstname) .value(); //=> ["Alan", "Barkley", "John"]
-
- JavaScriptミックスイン
- ミックスインは、特殊な型(この場合は、SQL命令)に関係する関数の抽象的なサブセットを定義するオブジェクトである
- 他のプログラミング言語のトレイト(trait)に少し似ている
- ターゲットのオブジェクトは、すべての機能をミックスインから借りる
- オブジェクト指向の世界において、ミックスインは継承を使わずにコードを再利用する1つの方法である
- ミックスインは、特殊な型(この場合は、SQL命令)に関係する関数の抽象的なサブセットを定義するオブジェクトである
- 関数型プログラミングは命令型コードよりも強力な抽象化を実現できる
- 上記のJavaScriptのコードは、SQLのようにデータを関数の形にモデル化できる
- これはデータとしての関数としても知られている
- データの出力がどのように得られるかではなく、データの出力が何かを宣言的に説明している
- 高いレベルの抽象化を使用してループ文も置き換えることができる
- 上記のJavaScriptのコードは、SQLのようにデータを関数の形にモデル化できる
- ループを置き換えるための別のテクニックとしては、再帰がある
- 再帰は、本質的に自己相似である問題に取り組むときに、イテレーションを抽象化することができる
- これらの種類の問題に対しては、関数チェーンを使用すると非効率かつ不適切となる
- 再帰は、標準的なループでもっとも手間のかかる箇所を言語ランタイムに委譲することができる
-
-
コードを把握することについて
再帰的に考えることを学ぶ
- 再帰的に考えることを学ぶ
-
再帰について
- 問題に真正面から取り組むことが困難なときは、ただちに問題を分解する方法を探すべき
- 細かい部分に分割できれば、細かい部分を解決していき、それらを組み合わせることで問題全体を解決することができる
- 再帰は、Haskell、Scheme、Erlangなどの純粋関数型言語言語において配列を走査する場合に必要となる
- これらの言語はループ・コンストラクタを持たないから
- 本節では、まず再帰とは何かを説明し、その後再帰的に考えるにはどうしたらよいかを学び、さらに再帰を利用して解析することが可能なデータ構造をいくつか見ていく
- 問題に真正面から取り組むことが困難なときは、ただちに問題を分解する方法を探すべき
-
再帰とは何か
- 再帰とは、ある問題を解決するために、問題をさらに小さな自己相似の問題に分解するように設計するテクニックのことである
- 分解した問題を結合することにより、元の問題を解決することができる
- 再帰関数には2つの主要な部分がある
- 基底部(終了条件としても知られる)
- 再帰部
- 再帰とは、ある問題を解決するために、問題をさらに小さな自己相似の問題に分解するように設計するテクニックのことである
-
再帰的に考えるということ
- 配列内のすべての数字を加算していく問題の例
-
再帰的に考える
/* まずは命令型で考えてみる 配列の要素ごとの繰り返しと、積算値の保持という 解決方法が思いつく */ var acc = 0; for (let i = 0; i < nums.length; i++) { acc += nums[i]; } /* アキュムレータが必要になると考え _.reduceを思いつく */ _(nums).reduce((acc, n) => acc + current, 0); /* 最初の要素を残りの要素に連続的に加算して 結果を計算するという方法で、再帰的に考えることができる これを水平思考と呼ぶ */ sum[1, 2, 3, 4, 5, 6, 7, 8, 9] = 1 + sum[2, 3, 4, 5, 6, 7, 8, 9]; = 1 + 2 + sum[3, 4, 5, 6, 7, 8, 9]; = 1 + 2 + 3 + sum[4, 5, 6, 7, 8, 9]; /* 再帰とループは表裏一体である 変異がなければ、再帰はループに比べて より表現力があり、強力かつ優れた代替手段となる 再帰は入力のサブセットに対して複数回同じ処理を繰り返すことを 前提としているため、コードを簡単に理解できるようにもなる Lodashの_.firstや_.rest関数を使用する例 */ function sum(arr) { if (_.isEmpty(arr)) { return 0; } return _.first(arr) + sum(_.rest(arr)); } sum([]); //=> 0 sum([1, 2, 3, 4, 5, 6, 7, 8, 9]); //=> 45 /* 末尾位置での再起呼び出しを利用した sum関数の少し異なる実装例 */ function sum(arr, acc = 0) { if (_.isEmpty(arr)) { return 0; } return sum(_.rest(arr), acc + _.first(arr)); }
-
- 配列内のすべての数字を加算していく問題の例
-
再帰的に定義されるテータ構造
- 関数型プログラミング(ラムダ計算式、カテゴリー理論など)の生まれた1900年代は、数学コミュニティーが活気に満ちていた時代だった
- 関数型プログラミングは、Alonzo Curchなどの教授の指導のもと、先進的な大学による共同のアイデアと理論に基づいていた
- Barkley Rosser、Alna Turing、Stephen Kleeneなどは、博士課程においてAlonzo Church教授のもとで学ぶ学生だった
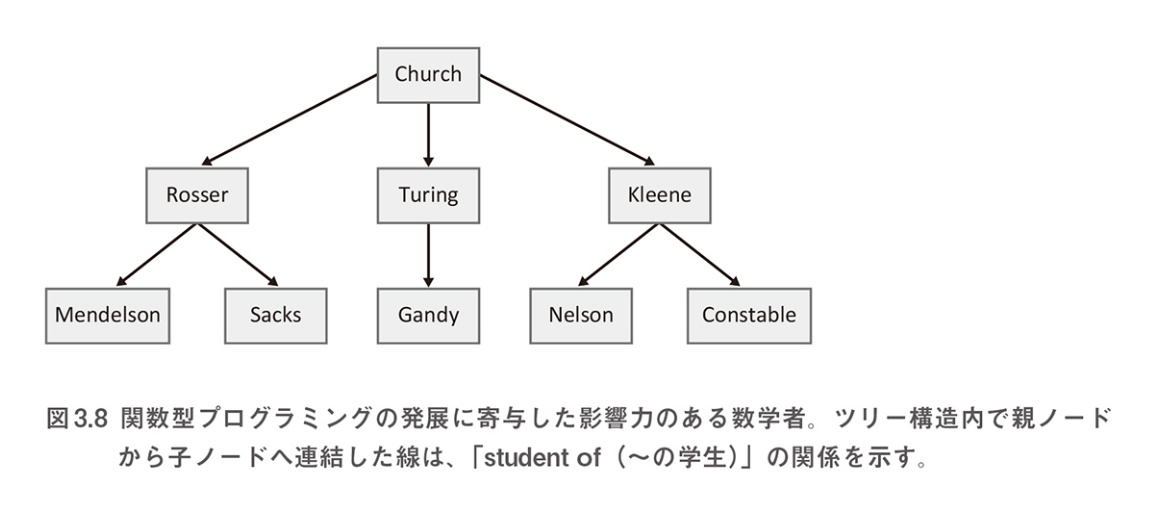
- これまでは配列のようなフラットなデータ構造を解析する関数型テクニックを利用してきた
- これらはツリー状データに対しては使えない
- JavaScriptはもともとツリーオブジェクトを持たないので、ノードに基づいて簡単なデータ構造を作成してみる
-
ノードを使ったデータ構造の例
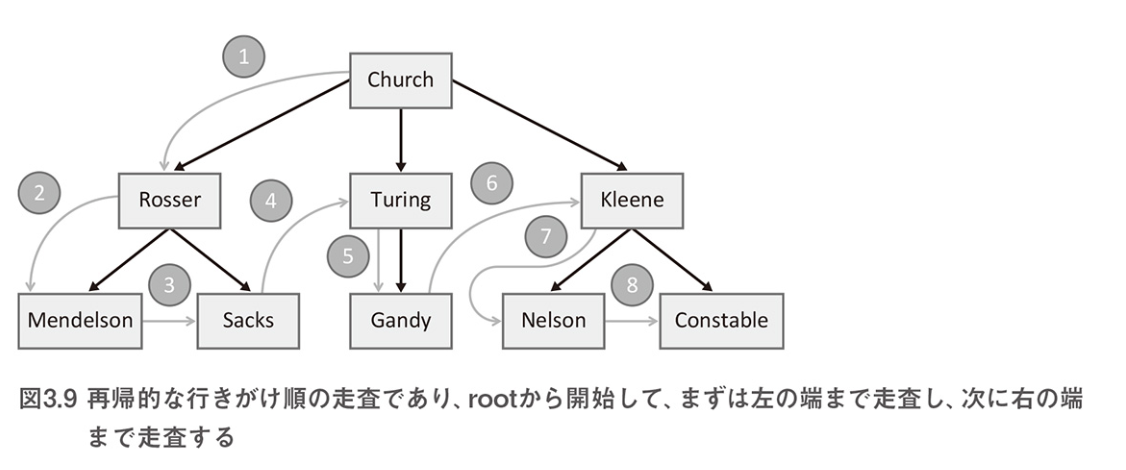
class Node { constructor(val) { this._val = val; this._parent = null; this._children = []; } isRoot() { return isValid(this._parent); } get children() { return this._children; } hasChildren() { return this._children.length > 0; } get value() { return this._val; } set value(val) { this._val = val; } append(child) { child._parent = this; this._children.push(child); return this; } toString() { return `Node (val: ${this._val}, children: ${this._children.length})`; } } /* 新しいノードを作成する */ const church = new Node(new personalbar("Alonzo", "Church", "111-11-1111")); /* ツリーは、ルートノードを含む再帰的に定義された データ構造である */ class Tree { constructor(root) { this._root = root; } static map(node, fn, tree = null) { node.value = fn(node.value); if (tree === null) { tree = new Tree(node); } if (node.hasChildren()) { _.map(node.children, function (child) { Tree.map(child, fn, tree); }); } return tree; } get root() { return this._root; } } /* ノードの主要ロジックはappendメソッドにある */ church.append(rosser).append(turing).append(kleene); kleene.append(nelson).append(constable); rosser.append(mendelson).append(sacks); turing.append(gandy); /* 再起アルゴリズムは、ツリー全体に対して順番に走査していく 走査はルートノードから始まり、すべての子ノードに対して 下向きに行われる 1. ルート要素のデータ部を表示する 2. preorder関数(行きがけ順走査)を再帰的に呼び出して、 左側のサブツリーを走査する 3. 同じ方法で、右側のサブツリーを走査する */ Tree.map(church, (p) => p.fullname);
- データ構造を解析することは、ソフトウェアのもっとも基本的な側面であり、関数型プログラミングの根幹である
- 関数型プログラミング(ラムダ計算式、カテゴリー理論など)の生まれた1900年代は、数学コミュニティーが活気に満ちていた時代だった
-
再帰について
まとめ
- まとめ
- 高階関数map、reduce、filterを利用して拡張可能なコードを記述することができる
- Lodashは、データフローとデータ変換が明確に区別される制御チェーンによってプログラムを作成する
- 関数型プログラミングの宣言的スタイルにより、簡単に把握できるコードを作成できる
- 高いレベルの抽象化をSQLの用語に対応させることにより、データをより深く理解できる
- 再帰は、自己相似的な問題を解決し、再帰的に定義されるデータ構造を解析するために必要となる
第4章 モジュール化によるコードの再利用
-
正常に機能する複雑なシステムは概して、動作する単純なシステムから進化したものである
A complex system that works is invariably found to hava evolved from simple system that worked.
——— John Gall, The Systems Bible (General Systemantics Press, 2012) -
本章のテーマ
- 関数チェーンとパイプラインを比較する
- Ramda関数ライブラリを導入する
- カリー化、部分適用、関数束縛(バインディング)の概念を検証する
- 関数合成を使ってモジュール化されたプログラムを作成する
- 関数コンビネータを使ってプログラムのフローを拡張する
-
モジュール性について
- モジュール性とは、プログラムをより小さく独立したものにどこまで分離可能かを表す
- 大規模なソフトウェアプロジェクトが持つべき、最も重要な品質特性の1つである
- モジュール化されたプログラムとは
- プログラムの構成要素の意味からプログラム全体の意味が導かれるようになっている
- 構成要素(あるいはサブプログラム)は、再利用可能なコンポーネントとなっている
- これらのコンポーネントは、その全体またはその一部をその方のシステムへ組み込むことができる
- 再利用可能なコンポーネントを組み込むことによって、コードの保守性と可読性が高まり、生産性が高まる
- 例としてのUnixのシェルプログラム
-
Unixのシェルプログラム
tr 'A-Z' 'a-z' < words.in | uniq | sort - Unixプログラムの経験がなくても、このコードは単語を大文字から小文字に変換し、重複を排除し、その残りをソードしていることが理解できる
- プログラミングでは、問題を解決するために、問題を小さい部分に分割して、これらの分割した部分を組み立て直して、解決に導く
-
- 第3章では、高レベルの関数を使用して解決した
- 単一のラッパーオブジェクトをカスケード(多段つなぎ)で強く結合したメソッドチェーンで使用した
- 本章では、さらに拡張して、関数合成でゆるく結合したパイプラインを作成する
- 関数フレームワークのRamdaを利用して、部分評価や合成を行う
- コードに適切な抽象度を持たせ、宣言的な関数パイプラインによるポイントフリーなアプローチで解決することが目的である
- モジュール性とは、プログラムをより小さく独立したものにどこまで分離可能かを表す
メソッドチェーンと関数パイプライン
- メソッドチェーンと関数パイプライン
-
パイプラインとは
- 関数をつなげたい場合、メソッドチェーンとは別にパイプラインと呼ばれるアプローチがある
- Haskellで使用される関数の表記
- 関数型プログラミングにおいて関数は、入力型と出力型の間の数学的な写像(マッピング)である

-
isEmptyの例
isEmpty :: String -> Boolean -
JavaScriptでのisEmptyの例
/* この関数は、String型のすべての入力のセットと、 Boolean型の値のセットとの間の参照透過的なマッピングである */ // isEmpty :: String -> Boolean const isEmpty = (s) => !s || !s.trim();
- 関数をチェーンにしたり、パイプライン化したりする方法を理解するには、関数「型の間のマッピング」として見ることが必要となる
-
メソッドをまとめてチェーンにする
-
mapやfilterは、Lodashの暗黙的なラッパーオブジェクトにより、互いに強く結合したチェーンにすることができる
-
メソッドチェーン
/* チェーンは命令型コードに比べて大幅に可読性が向上しているが、 所有するオブジェクトに強く結合してしまっている このオブジェクトは、チェーンに適用できるメソッド数を制限するので、 コードの表現力も制限されることになる チェーンを分割して、自由度を高くできるとよりよい これは関数パイプラインで実現できる */ _.chain(names) .filter(isValid) .map((s) => s.replace(/_/, " ")) .uniq() .map(_.startCase) .sort() .value();
-
-
関数をパイプライン状に配置する
- パイプラインは、処理の流れの向きに関数列を緩く配置したものとなる
- ある関数の出力が次の関数の入力になる

- パイプやフィルターのオブジェクト指向デザインパターンは、関数型プログラミングからアイデアを得たものである
- チェーンとパイプラインの違い
- チェーンはオブジェクトのメソッドにより強い接続を作る
- 一方で、パイプラインは関数の入力と出力をリンクするので、コンポーネントが緩く接続される
- 接続される関数同士において、アリティ(引数の個数)と引数の型の点で互換性がなければならない
- パイプラインは、処理の流れの向きに関数列を緩く配置したものとなる
-
パイプラインとは

互換性のある関数のための要件
- 互換性のある関数のための要件
-
互換性のある関数について
- オブジェクト指向のプログラムは、認証/認可などでときどきパイプラインを使用する
- 関数型プログラミングは、プログラムを構築する唯一の方法としてパイプラインに依存している
- 関数は入力と出力において2つの項目で互換性があるという条件のもと実行される
- 型(type): 1つの関数で返される型は、その型を受け取る関数の引数の型と一致しなければならない
- アリティ(arity: 引数の個数): その型を受け取る関数は、直前の関数呼び出しから返される値を処理するために、少なくとも1個のパラメータを宣言しなければならない
- 関数は入力と出力において2つの項目で互換性があるという条件のもと実行される
-
型互換の関数
- 関数パイプラインを設計する場合、関数の入出力に関して関数間で互換性があることが重要である
- JavaScriptはゆるく型付けされている
- もしあるオブジェクトが実際にある型のように振る舞うなら、そのオブジェクトはその型である
- ダックタイピング(Duck Typing)と呼ばれる
- 「アヒルのように歩き、アヒルのように鳴くものはアヒルである」
- JavaScriptの動的なディスパッチメカニズムは、型情報に関係なくオブジェクトのプロパティとメソッドを探そうとする
- もしあるオブジェクトが実際にある型のように振る舞うなら、そのオブジェクトはその型である
- 2つの関数fとgは、関数fの出力が関数gの入力のセットと同型であるなら型互換である(学生の社会保障番号を処理する例)
-
関数trimとnormalizeを使って手動で関数パイプラインを構築する
// trim :: String -> String const trim = (str) => str.replace(/^\s*|\s*$/g, ""); // normalize :: String -> String const normalize = (str) => str.replace(/\-/g, ""); normalize(trim(' 444-44-4444 ')); //=> '444444444'
-
-
関数とアリティ:タプルの場合
- アリティとは
- アリティとは、関数がとる引数の個数である
- 関数の長さ(length)とも呼ばれる
- 関数型プログラミング以外のプログラミングパラダイムでは、アリティは当然あるものとして考えられている
- 関数型プログラミングでは、引数が多いと参照透過性の観点から複雑性が高まってしまう
-
引数の数による複雑性の対比
// isValid :: String -> Boolean function isValid(str) { ... } // makeAsyncHttp:: String, String, Array -> Boolean function makeAsyncHttp(method, url ,data) { ... }
- アリティとは、関数がとる引数の個数である
- 単一の引数を取る純粋関数は、使い方がとてもシンプルになる
- 純粋関数は、単一の目的、単一の責任に対して動作するから
- よって、できるだけ少ない引数で関数を動作させることが重要となる
- 単項関数として考えることで、複数の引数をとる関数よりも柔軟性があり、多目的に利用できる関数を作成することができる
- タプルについて
- タプルとは
- 関数型言語は、タプル(tuple)と呼ばれる構造に対応している
- タプルは、有限かつ順番に並べられるリストの要素であり、通常は一度に2〜3個の値をまとめたもので、
(a,b,c)などと記述される
-
isValid関数の戻り値を、タプルを活用して抽象化してみる-
JavaScriptでタプルを定義する
// isValid :: String -> (Boolean, String) isValid(" 444-44-4444"); //=> (false, 'Input is too long!) /* Scala言語でのタプル定義 */ // var t = (30, 60, 90); // var sum AngelsTriangle = t._1 + t._2 + t._3 = 180 /* タプルを使わずに、一時的なデータをオブジェクトリテラルや 配列として返す方法もある タプルの方が有利な点 ・不変性: 一度作成されると、タプルの内部のデータを変更することはできない ・一時的な型を作成しなくてもよくなる: データをグループ化するためだけに新しい型を定義しなくてもよい ・異種混合の配列を作成してくてもよくなる: 異種混合の配列は型チェックなどの処理が複雑になるため */ return { status: false, // あるいはreturn [false, 'Input is too long!'] message: "Input is too long!", }; /* isValid関数で考えてみる タプルを使用して、ステータスおよび想定される エラーメッセージをグループ化する タプルは、isValid関数の戻り値として使用できる このタプルは、単一のエンティティとして関数から返され、 その後、必要に応じて別の関数に渡される また、タプルは第2章の値オブジェクトと似た振る舞いをする JavaScriptにはサポートがないので、 独自に実装したTupleデータ型を作成する */ const Tuple = function (/* types */) { const typeInfo = Array.prototype.slice.call(arguments, 0); const _T = function (/* values */) { const values = Array.prototype.slice.call(arguments, 0); if (values.some((val) => val === null || val === undefined)) { throw new ReferenceError("Tuples may not have any null values"); } if (values.length !== typeInfo.length) { throw new TypeError("Tuple arity does not match its prototype"); } values.map((val, index) => { this["_" + (index + 1)] = checkType(typeInfo[index])(val); }, this); Object.freeze(this); }; _T.prototype.values = () => { return Object.keys(this).map((k) => this[k], this); }; return _T; }; /* Tupleオブジェクトは、不変かつ固定長の構造体である n個の型付きの値で構成される異種混合のセットを保持して、 関数間の通信に利用する */ const Status = Tuple(Boolean, String); /* タプルを活用して、学生SSNを検査する例 */ // trim :: String -> String const trim = (str) => str.replace(/^\s*|\s*$/g, ""); // normalize :; String -> String const normalize = (str) => str.replace(/\-/g, ""); // isValid :; String -> Status const isValid = function (str) { if (str.length === 0) { return new Status(false, "Invalid input. Expected non-empty value!"); } else { return new Status(true, "Success!"); } }; isValid(normalize(trim("444-44-4444"))); //=> (true, 'Success!') /* 2要素のタプルはよく使われるので、第一級(ファーストクラス)オブジェクトに しておいてもよい タプルを使用して、StringPairオブジェクトを作成する */ const StringPair = Tuple(String, String); const name = new StringPair("Barkley", "Rosser"); [first, last] = name.values(); first; // => 'Barkley' last; // => 'Rosser' const fullname = new StringPair("J", "Barkley", "Rosser"); //=> アリティが不一致というエラーを投げる
-
- 関数のアリティを減らすには、関数カリー化(function currying)という方法もある
- カリー化は、アリティを抽象化するだけでなく、モジュール性や再利用性を後押しする
- タプルとは
- アリティとは
-
互換性のある関数について
カリー化された関数評価
- カリー化された関数評価
-
カリー化について
- 関数が複数の引数を要求する場合にはどうすればいいか
- まずはカリー化された評価と、通常の評価の違いを理解する
- JavaScriptでは通常の関数呼び出しは引数が不足していても実行することが許されている
- 関数
f(a,b,c)を定義して、引数aのみを与えて呼び出して場合、評価が開始され、JavaScriptランタイムは引数b, cをundefinedに設定する
- 関数
- カリー化された関数は、すべての引数が明示的に定義されている関数である
- 引数の一部だけを渡してこの関数を呼び出した場合、新しい関数を返すようになっている
- この新しい関数は、残りのパラメータが与えられるまで実行を保留する

- JavaScriptでは通常の関数呼び出しは引数が不足していても実行することが許されている
- カリー化は、複数変数の関数を複数の単項関数に変換することで元の関数を段階的に実行するというテクニックである
- 複数変数の関数は、すべての引数が提供されるまで、処理を一時停止あるいは先送りにすることができる
- カリー化された関数の例
-
カリー化された関数
/* curry関数の正式な定義 カリー化は、入力(a, b, c)を個々の単一引数の呼び出しに分解する、 関数間のマッピングである Haskellなどの純粋関数型プログラミング言語では、カリー化は組み込み機能であり、 自動的にすべての関数定義に適用される JavaScriptではカリー化を可能にするコードを追加する必要がある */ // curry(f) :: ((a, b, c) -> d) -> a -> b -> c -> d /* 2個の引数を手動でカリー化する例 カリー化は、レキシカルスコープ(静的スコープ、クロージャはこの仕組みを利用する)の 1つの特性を利用している 返される関数は入れ子になった関数ラッパーであり、引数を補足しておいて 後で利用するようになっている */ function curry2(fn) { return function (firstArg) { return function (secondArg) { return fn(firstArg, secondArg); }; }; } const name = curry2((last, first) => new StringPair(last, first)); [first, last] = name("Curry")("Haskell").values(); first; //=> 'Curry' last; //=> 'Haskell' name("Curry"); //=> [Function] /* Ramdaを使用してTuple型で使用されている checkType関数を実装する */ // checkType :: Type -> Object -> Object const checkType = R.curry((typeDef, obj) => { if (!R.is(typeDef, obj)) { let type = typeof obj; throw new TypeError( `Type mismatch. Expected [${typeDef}] but found [${type}]` ); } return obj; }); checkType(String)("Curry"); //=> 'Curry' checkType(Number)(3); //=> 3 checkType(Number)(3.5); //=> 3.5 let now = new Date(); checkType(Date)(now); //=> now checkType(Object)([]); //=> [] checkType(String)(42); //=> TypeError: Type mismatch. Expected [String] but found [number] /* R.curry関数を使用することで、任意の個数の引数で動作する 純粋な関数型言語のカリー化メカニズムをシミュレートすることができる 自動化されたカリー化とは、宣言された引数の個数に対応するように、 関数スコープを入れ子の形式で作成することと考えることができる */ // fullname :: (String, String) -> String const fullname = function (first, last) { // ... }; // fullname :: String -> String -> String const fullname = function (first) { return function (last) { // ... }; };
-
- カリー化の応用例(デザインパターンの実装)
- 関数インターフェースをエミュレートする
- 再利用可能かつモジュール化された関数テンプレートを実装する
-
関数ファクトリをエミュレートする
- オブジェクト指向の世界では、インターフェースは抽象型であり、クラスが実装すべき規則を定義するのに使用される
-
findStudent(ssn)関数を持ったインターフェースを作成する場合、このインターフェースの具体的な実装先でこの関数を実装する -
Javaでのインターフェースの実装例
public interface StudentStore { Student findStudents(String ssn); } public class DbStudentStore implements StudentStore { public Student findStudent(String ssn) { // ... ResultSet rs = jdbcStmt.executeQuery(sql); while(rs.next()) { String ssn = rs.getString("ssn"); String name = rs.getString("firstname") + rs.getString("lastname"); return new Student(ssn, name) } } } public class CacheStudentStore implements StudentStore { public Student findStudent(String ssn) { // ... return cache.get(ssn); } } - 上記のコードでは、同一インターフェース(
findStudent)の2通りの実装を示している- 一方はデータベースから学生の情報を読み出し、他方はキャッシュから読み出している
- コード呼び出しの観点からは、メソッド呼び出しのみが問題とな理、どこからStudentオブジェクトを読み出すかは問題とはならない
- これは、ファクトリメソッドパターンによるオブジェクト思考デザインの優れた点である
- ファクトリ関数を使用する
-
ファクトリ関数を使用する
StudentStore store = getStudentStore(); store.findStudent("444-44-4444");
-
-
- 関数型プログラミングの世界ではどのように実装すればいいか
- カリー化を活用する
- JavaコードをJavaScriptコードに移植することで、データストアや配列(2つの実装先)内でStudentオブジェクトの検索機能を作成できる
-
findStudent関数
/* 関数をカリー化し、関数定義と評価を分離する 詳細が実装されているfindStudentは、その内部の どちらの実装からも得ることができる */ // fetchStudentFromDb :: DB -> (String -> Student) const fetchStudentFromDb = R.curry(function (db, ssn) { return find(db, ssn); }); // fetchStudentFromArray :: Array -> (String -> Student) const fetchStudentFromArray = R.curry(function (arr, ssn) { return arr[ssn]; }); /* findStudent関数は、その他のモジュールに渡すことも できる しかもこの関数を呼び出すコードは、findStudentの 実際の実装を知らなくても問題ない */ const findStudent = useDb ? fetchStudentFromDb(db) : fetchStudentFromArray(arr); findStudent("444-44-4444"); //=> Student { ssn: '444-44-4444', name: 'Haskell Curry' }
- カリー化を活用する
- オブジェクト指向の世界では、インターフェースは抽象型であり、クラスが実装すべき規則を定義するのに使用される
-
再利用可能な関数テンプレートを実装する
- たとえばエラー、警告、デバッグなどのログ機能を設定したい場合がある
- 関数テンプレートは、カリー化される引数の個数に基づいて関連する関数のファミリーを定義できる
-
Log4jsをカリー化して利用する例 -
Log4jsのカリー化の例
const logger = new Log4js.getLogger("StudentEvents"); logger.info("Student added successfully!"); // データを追加する機能(appender)を利用して、メッセージを表示する logger.addAppender(new Log4js.JSAlertAppender()); // レイアウトプロパイダーを利用して、JSON形式でメッセージを出力する appender.setLayout(new Log4js.JSONLayout()); /* Log4jsは設定可能な項目が多いため、あちこちで コードの重複が起きてしまう可能性がある カリー化を使用して、再利用可能なテンプレートを 定義する */ const logger = function (appender, layout, name, level, message) { const appneders = { alert: new Log4js.JSAlertAppender(), console: new Log4js.BrowserConsoleAppender(), }; const layouts = { basic: new Log4js.BasicLayout(), json: new Log4js.JSONLayout(), xml: new Log4js.XMLLayout(), }; const appender = appenders[appender]; appender.setLayout(layouts[layout]); const logger = new Log4js.getLogger(name); logger.addAppender(appneder); logger.log(level, message, null); }; const log = R.curry(logger)("alert", "json", "FJS"); log("ERROR", "Error condition detected!!"); //=> 要求メッセージとともに警告ウィンドウを表示 /* 単一の関数やファイル内に複数のエラー処理文を実装する場合、 最後のパラメータ(メッセージ)を除くすべてのパラメータを 部分的に設定できるようになる これにより、引数の定義されたタイミングで関数を段階的に構築でき、 柔軟性を高めることができる */ const logError = R.curry(logger)("console", "basic", "FJS", "ERROR"); logError("Error code 404 detected!!"); logError("Error code 402 detected!!");
-
- 多引数関数を単項関数に変換するカリー化に代わるものとして、部分関数適用(partial function application)とパラメータ束縛(parameter bindind)がある
- この2つはJavaScript言語により適度にサポートされている
-
カリー化について
部分適用とパラメータ束縛
- 部分適用とパラメータ束縛
-
部分適用について
- 引数の個数が変更できない関数のパラメータの一部を固定値に初期化して、アリティがより少ない関数を作成する処理のこと
- たとえば、5個のパラメータをとる関数があって、そのうち3個の引数を渡すと、最終的に残り2個の引数を要求する関数が得られる
- 部分適用は、カリー化のように、関数の長さを直接減らすことができる
- カリー化された関数は、本質的には部分適用された関数である
- 部分適用とカリー化の主な違い
- 内部のメカニズムとパラメータ渡しの管理の方法が違う
- カリー化
- 各部分呼び出しにおいて、入れ子になった単項関数を生成する
- 内部的には、これらの単項関数の段階的な合成から生成される
- curry関数を変形すると、引数を部分的に評価することができる
- 評価がいつ、どのように起こるのかを完全に制御できるということ
- 部分適用
- 関数の引数を事前に定義された値にバインド(割り付け)して、引数の個数が少ない新しい関数を生成する
- 生成される関数は、関数のクロージャ内に固定パラメータを含み、関数は以降の呼び出しで完全に評価される
- partial関数の実装例
-
部分適用とカリー化の違い
/* partial関数の内部実装例 */ function partial() { let fn = this; let boundArgs = Array.prototype.slice.call(arguments); // let placeholder = <<partialPlaceholderObj>>; let bound = function () { let position = 0; let length = boundArgs.length; let args = Array(length); for (let i = 0; i < length; i++) { args[i] = boundArgs[i] === placeholder ? arguments[position++] : boundArgs[i]; } while (position < arguments.length) { args.push(arguments[position++]); } return fn.apply(this, args); }; return bound; } /* ロガー関数に、いくつかのパラメータを部分的に適用すると、 さらに具体的な振る舞いを作成することができる */ const consoleLog = _.partial(logger, "console", "json", "FJS Partial"); /* カリー化と部分適用の違い 部分適用の場合、与えられた3個の引数を適用した後に得られるconsoleLog関数では、 呼び出し時に残りの2個の引数が指定されることを期待する カリー化とは違って、consoleLogを1個の引数だけで呼び出すと、新しい関数は返されず、 その代わりに最後の引数がundefinedとして評価されてしまう これを避けるためには、consoleLog関数に再度_.partialを適用する必要がある カリー化は、部分適用の仕様について自動化された方法であり、この自動化が partial関数との大きな違いである */ const consoleInfoLog = _.partial(consoleLog, "INFO"); consoleInfoLog("INFO logger configured with partial"); /* 別のバリエーションとして、Function.prototype.bind()での 関数束縛がある */ const log = _.bind(logger, undefined, "console", "json", "FJS Binding"); log("WARN", "FP is too awesome!");
-
-
_.partialや_.bindの実際の活用例- コア言語を拡張する
- 遅延関数を束縛する
- 引数の個数が変更できない関数のパラメータの一部を固定値に初期化して、アリティがより少ない関数を作成する処理のこと
-
コア言語を拡張する
- 部分適用は、役に立つユーティリティとともに、String(文字列)やNumber(数値)などのコアなデータ型を拡張するのにも使える
- コア言語の拡張をする場合、コードのポータビリティが犠牲になる可能性があることに注意する
-
コア言語の拡張例
// 最初のN個の文字を取得する String.prototype.first = _.partial(String.prototype.substring, 0, _); "Functional Programming".first(3); //=> 'Fun' // 任意の名前を、名字と名前の形式に変換する String.prototype.asName = _.partial( String.prototype.replace, /(\w+)\s(\w+)/, "$2, $1" ); "Alonzo Church".asName(); //=> 'Church, Alonzo' // 文字列を配列に変換する String.prototype.explode = _.partial(String.prototype.match, /[\w]/gi); "ABC".explode(); //=> ['A', 'B', 'C'] // 簡単なURLを解析する String.prototype.parseUrl = _.partial( String.prototype.match, /(http[s]?| ftp):\/\/([^:\/\s]+)\.([^:\/\s][2,5])/ ); "http://example.com".parseUrl(); // => ['http', 'example', 'com'] /* また、自分自身で関数を実装する前に、まずは新しい言語の 更新状況を確認することをおすすめする */ if (!String.prototype.explode) { String.prototype.explode = _.partial(String.prototype.match, /[\w]/gi); }
- 部分適用は、役に立つユーティリティとともに、String(文字列)やNumber(数値)などのコアなデータ型を拡張するのにも使える
-
遅延関数に束縛する
-
setTimeoutやsetIntervalなどの遅延処理には、部分適用が動作しないケースがある-
this参照がグローバルコンテキスト、つまりwindowオブジェクトに設定されることを期待しているため- そうなっていないと、これらのタイマー関数は動作しない
- 自身のオブジェクトが存在することを期待するメソッドにおいては、関数束縛を使用してコンテキストオブジェクトを設定する必要がある
-
-
_.bindと_.partialの両方を利用した例-
Schedulerの例
/* Schedulerを使用すると、関数本体にラッピングられた任意のコードを 遅延させて起動することができる */ const Scheduler = (function () { const delayedFn = _.bind(setTimeout, undefined, _, _); return { delay5: _.partial(delayedFn, 5000), delay10: _.partial(delayedFn, 10000), delay: _.partial(delayedFn, _, _), }; })(); Scheduler.delay5(function () { consoleLog("Executing After 5 seconds"); });
-
-
- 部分適用もカリー化も、関数がスコープ外のオブジェクトにあからさまにアクセスする必要がないように、正しい引数を与えることができる
- また同時に、引数を減らして単項関数にすることができる
- 必要なデータを取得するためのロジックを分離することは、関数の再利用性を高めることになる
-
部分適用について
関数パイプラインを合成する
- 関数パイプラインを合成する
-
関数型プログラミングと副作用
- 第1章では、問題をより小さくして、単純な下位の問題やタスクに分割することの重要性を見てきた
- パズルのピースのように、分割した問題への解を積み上げることで最終的に問題を解決することを目指した
- 関数型プログラムの目的とは、合成可能となる構造を得ることである
- これが関数型プログラミングの根幹をなすテーマである
- 副作用のない純粋関数の概念が関数型プログラミングを支えている
- 副作用のない関数とは、外部データに一切依存しない関数のこと
- 関数が必要とする情報は、引数として提供されるもののみとなる
- プログラムが純粋関数から構築されている場合、得られるプログラム自体も純粋となる
- 第1章では、問題をより小さくして、単純な下位の問題やタスクに分割することの重要性を見てきた
-
HTMLウィジェットとの合成を理解する
- 合成は関数型プログラミングに特有のアイデアではない
- HTMLウィジェットがページ上にどのように配置されるか考えてみる
- 3個の入力テキストボックスを空のコンテナと組み合わせると、簡単なStudentフォールが生成される
- Studentフォームはコンポーネントであり、他のコンポーネントと組み合わせて、さらに複雑なフォール全体を作成できる
- レゴブロックのように簡単な構造から複雑な構造を構築するのに使用できる
-
Nodeの例
/* Nodeは、オブジェクトを保持しながら別のノード(タプル)への 参照も保持することができる */ const Node = Tuple(Object, Tuple); const element = R.curry((val, tuple) => new Node(val, tuple));
- 3個の入力テキストボックスを空のコンテナと組み合わせると、簡単なStudentフォールが生成される
-
関数合成: 記述を評価から分離する
- 複雑な振る舞いをグループ化するのに関数合成が使用される
-
2個の純粋関数を結合する例
/* 2個の純粋関数を結合する例 関数の構成要素を眺めただけで、簡単に意味を理解できる また、countWords関数が引数とともに実行されるまでは、 評価は行われない 「g :: A -> B」と 「f :: B -> C」の 合成は、「fとgの合成」(f composed of g)と呼ばれ、 「A -> C」の別の関数(アロー)となる これは、下記のように正式に表現することができる f・g = f(g) = compose :: ((B -> C), (A -> B)) => (A -> C) 参照透過性が成り立つ場合、関数はあるグループのオブジェクトを 別のグループのオブジェクトへと接続する矢印にすぎない */ const str = `We can only see a short distance ahead but we can see plenty there that needs to be done `; const explode = (str) => str.split(/\s+/); const count = (arr) => arr.length; const countWords = R.compose(count, explode); console.log(countWords(str)); //=> 19
-
- 参照透過性の原理はモジュール化システムの根幹を成すものである
- 型互換の関数同士をその境界(入出力)でゆるく結合するので、合成はインターフェースに対するプログラミングの原理を満たすことができる
- つまり、各関数は次に呼ばれる関数のインターフェースだけ知っているか、気にかけており、その実装に関しては心配しない
-
compose関数
/* compose関数の内部実装例 */ function compose(/* fns */) { let args = arguments; let start = args.length - 1; return function () { let i = start; let result = args[start].apply(this, arguments); while (i--) { result = args[i].call(this, result); } return result; }; } /* 有効なSSNを検査する評価プログラムの例 */ const trim = (str) => str.replace(/^\s*|\s*$/g, ""); const normalize = (str) => str.replace(/\-/g, ""); const validLength = (param, str) => str.length === param; const checkLengthSsn = _.partial(validLength, 9); const cleanInput = R.compose(normalize, trim); const isValidSsn = R.compose(checkLengthSsn, cleanInput); cleanInput(" 444-44-4444 "); // => '444444444' isValidSsn(" 444-44-4444 "); // => true /* JavaScriptのFunctionプロトタイプを拡張して、 compose関数を追加することもできる */ Function.prototype.compose = R.compose; const cleanInput = checkLengthSsn.compose(normalize).compose(trim); - 合成は結合操作、つまり論理AND操作を使用した要素の連結を意味する
- プログラム全体は部分の総和から導き出すことができる
- 複雑な振る舞いをグループ化するのに関数合成が使用される
-
関数ライブラリによる合成
- Ramdaなどの関数型ライブラリを使う利点は、関数パイプラインを構成しやすい点である
- 学生の名前と教科の得点をリストにする例
-
関数パイプライン
/* 最も優秀な学生を見つけるプログラムの例 */ const smartestStudent = R.compose( R.head, R.pluck(0), R.reverse, R.sortBy(R.prop(1)), R.zip ); /* 記述的な機能エイリアスを使用して、 より明確なコードを作成することができる */ const first = R.head; const getName = R.pluck(0); const reverse = R.reverse; const sortByGrade = R.sortBy(R.prop(1)); const combine = R.zip; R.compose(first, getName, reverse, sortByGrade, combine);
-
- 最も難しいのは合成ではなく、タスクを小さいサブタスクに分割することである
- 一度タスクが分割できれば、あとは合成していくのみ
- しかし、純粋関数をいつも利用できるとは限らない
- アプリケーション開発者として、ローカルストレージから読み込んで、リモートHTTP要求を行うなど、副作用を取り扱うことは避けられない状況に直面する
- このような問題を解決するには、不純なコードを純粋なコードから分離できなければならない
- 分離・独立さえできれば、テストは極めて簡単になる
-
純粋なコードと不純なコードを取り扱う
- 不純なコードとは
- 不純なコードは、実行後に外部に観測可能な副作用を起こす
- 構成する関数のスコープを超えてデータにアクセスする、外部的な依存性を有する
- ただ、関数型プログラミングの利益を得るときに関数を100%純粋にする必要はない
- 不純な振る舞いに対してやるべきこと
- 可能な限り不純な振る舞いを独立させること、理想的には単一の関数内にまとめることで、明確に分離することができる
- さらに、合成を使用して、純粋な部分と不純な部分をつなぎ直すことができる
- 不純なコードをリファクタリングしてみる
-
不純なコードのリファクタリング
/* 不純なコードとしてのshowStudent関数 ・findStudentは、ローカルオブジェクトや外部の配列への参照を利用する ・appendは、直接HTML要素を記述・修正する */ const showStudent = compose(append, csv, findStudent); /* 不純なコードをcurry関数を使用して リファクタリングする */ // findObject :: DB -> String -> Object const findObject = R.curry((db, id) => { const obj = fund(db, id); if (obj === null) { throw new Error(`Object with ID [${id}] not found`); } return obj; }); // findStudent :: String -> Student const findStudent = findObject(DB("students")); const csv = ([ssn, firstname, lastname]) => { `${ssn}, ${firstname}, ${lastname}`; }; const append = R.curry((elementId, info) => { document.querySelector(elementId).innerHTML = info; return info; }); // showStudent :: String -> Integer const showStudent = R.compose( append("#student-info"), csv, findStudent, normalize, trim ); showStudent("44444-4444"); //=> '44444-4444, Alonzo, Church' /* プログラムを左から右向きに結合して 視覚化したい場合は、Ramdaのcomposeの ミラー関数を使用することもできる これはpipeと呼ばれている F#では`|>`演算子を組み込み機能として 提供している R.pipeとR.composeは、いずれも明示的に引数を宣言しなくても 新しい関数を作成することができる このような記述スタイルをポイントフリーコーディングと呼ぶ */ R.pipe(trim, normalize, findStudent, csv, append("#student-info"));
-
- 不純なコードとは
-
ポイントフリープログラミング
- ポイントフリープログラミングについて
- 関数composeやpipeを使うと、引数(関数のポイント)を宣言する必要がないことを意味する
- コードが宣言型になり、ポイントフリーのスタイルになる
- ポイントフリープログラミングは、関数型JavaScriptのコードをHaskellのコードやUnixの哲学に近づけることができる
- さらに抽象化のレベルを高めることができる
- 関数composeやpipeを使うと、引数(関数のポイント)を宣言する必要がないことを意味する
- ポイントフリースタイルのコーディングは、タシットプログラミング(tacit programming)としても知られている
- Unixプログラムに極めて似ている
-
ポイントフリーな方法で記述する
/* Unixプログラムをポイントフリーな方法で 記述したコードの例 */ const runProgram = R.pipe(R.map(R.toLower), R.uniq, R.sortBy(R.identity)); runProgram([ "Functional", "Programming", "Curry", "Memorization", "Partial", "Curry", "Programming", ]); //=> ['curry', 'functional', 'memorization', 'partial', 'programming']
- 合成は、関数をポイントフリーのコーディング形式に変形する
- どのような引数をとるのか、より大規模な式でどのように接続されるのかなどを一切宣言しないことになる
- やりすぎると、あいまいな、あるいは難読化したプログラムを生成してしまうことになるため注意する必要がある
- すべてがポイントフリーである必要はない
- 一度に2、3個の関数が実行されるように関数合成を分ける方がいい場合もある
- さらに先へ進むためには、エラーハンドリング、条件分岐の取り扱い、複数の関数を逐次に走らせる機能について考える必要がある
- ポイントフリープログラミングについて
-
関数型プログラミングと副作用
関数コンビネータを使ってフロー制御を管理する
- 関数コンビネータを使ってフロー制御を管理する
-
コンビネータについて
- 第3章では、命令型と関数型の各パラダイムのプログラムの制御フローを比較した
- 命令型コードは、
if-elseやforなどの手続型制御メカニズムを使用してプログラムの処理フローを進める - 関数型プログラミングでは、上記の制御メカニズムは使わない
- 制御メカニズムの代わりとして、関数コンビネータを利用する
- 命令型コードは、
- コンビネータとは
- 関数(あるいはコンビネータ)などを組み合わせた高階関数である
- これが制御ロジックとして機能する
- コンビネータでは変数を一切宣言せず、ビジネスロジックを含まない
-
composeやpipeのほかにも多くのコンビネータが存在する
- 関数(あるいはコンビネータ)などを組み合わせた高階関数である
- 本章で紹介する一般的なコンビネータ
identitytapalternationsequencefork(join)
- 第3章では、命令型と関数型の各パラダイムのプログラムの制御フローを比較した
-
identity(Iコンビネータ)
- identityコンビネータは、与えられた引数と同じ値を返す関数である
identity :: (a) -> a
- 関数の数学的な性質を調べるために広く使用される
- 実用的な用途
-
R.sortBy(R.identity)のように使用する - 関数コンビネータのフローに対してユニットテストを行う
- カプセル化した型からデータを関数的に抽出する
-
- identityコンビネータは、与えられた引数と同じ値を返す関数である
-
tap(Kコンビネータ)
- tapコンビネータは、void型関数を合成に橋渡しするために使われる
- tap関数は自らを関数に渡して、自らを返す
tap :: (a -> *) -> a -> a- 値は通し、副作用だけを挟むために使われる
- tap関数がとる引数
- 入力オブジェクト
aと、このaに対して動作を実行する関数 - (パススルー関数のこと)
- 入力オブジェクト
-
tap関数の使用例
const debugLog = _.partial(logger, "console", "basic", "MyLogger", "DEBUG"); /* debugLogをその他の関数の合成に 組み込むこともできる */ const debug = R.tap(debugLog); const cleanInput = R.compose(normalize, debug, trim); const isValidSsn = R.compose(debug, checkLengthSsn, debug, cleanInput); isValidSsn('444-44-4444'); // 出力 // MyLogger [DEBUG] 444-44-4444 // MyLogger [DEBUG] 444444444 // MyLogger [DEBUG] true
- tapコンビネータは、void型関数を合成に橋渡しするために使われる
-
alternation(ORコンビネータ)
- alternationコンビネータは、関数呼び出しに応えて既定の振る舞いを提供する際に、簡単な条件付きロジックを実行する関数のことである
- 2個の関数を引数にとり、値が真(true)と判定される(false、null、undefinedのいずれでもない)場合に、最初の関数の実行結果を返し、値が未定義の場合は2番目の関数の結果を返す
-
alternationコンビネータの使用例
const alt = function (func1, func2) { return function (val) { return func1(val) || func2(val); }; }; /* curry関数やラムダを使用して 簡単に記述することもできる */ const alt = R.curry((func1, func2, val) => func1(val) || func2(val)); /* alternationコンビネータを使って、showStudentプログラムの一部に 使用することで、取得処理が失敗して戻ってきたケースを処理することが できる また、取得処理が失敗したときに、新しいオブジェクトを作成することもできる */ const showStudent = R.compose( append("#student-info"), csv, alt(findStudent, createNewStudent) ); showStudent("444-44-4444"); //=> '444-44-4444, Alonzo, Church' /* 上記のコードは、命令型コードにおける 簡単なif-else文をエミュレートしている */ var student = findStudent("444-44-4444"); if (student !== null) { let info = csv(student); append("#student-info", info); } else { let newStudent = createNewStudent("444-44-4444"); let info = csv(newStudent); append("#student-info", info); }
- alternationコンビネータは、関数呼び出しに応えて既定の振る舞いを提供する際に、簡単な条件付きロジックを実行する関数のことである
-
sequence(Sコンビネータ)
- seqコンビネータは、一連の複数の関数をループさせるために使用される
- 2個以上の関数を引数にとり、新しい関数を返す
- 新しい関数は、引数で与えられたすべての関数を、同じ値に対して順次実行する
-
sequenceコンビネータの使用例
const seq = function (/* funcs */) { const funcs = Array.prototype.slice.call(arguments); return function (val) { funcs.forEach(function (fn) { fn(val); }); }; }; /* seq関数により、互いに関連はあるが、それぞれ独立している 一連の処理を実行することができる Studentオブジェクトを見つけたら、seqを使用してHTMLページを表示し、 同時にコンソールにログを出力することができる すべての関数は、定義された順番に、同じStudentオブジェクトに対して 実行される */ const showStudent = R.compose( seq(append("#student-info"), consoleLog), csv, findStudent ); - seqコンビネータは値を返さない
- 一連の動作を順々に実行するだけ
- seqコンビネータを合成に追加したい場合は、
R.tapを使用して、その関数を他の関数に橋渡しする
- seqコンビネータは、一連の複数の関数をループさせるために使用される
-
fork(join)コンビネータ
- forkコンビネータは、1個のリソースを2通りの異なる方法で処理して、その結果を結合するのに便利な関数である
- 3個の関数を引数にとる
- join関数と、提供された入力を処理する2個のterminal関数
- 分岐(フォーク)したそれぞれの関数の結果は、最終的には2個の引数をとるjoin関数に渡される

- 3個の関数を引数にとる
-
forkコンビネータの使用例
const fork = function (join, func1, func2) { return function (val) { return join(func1(val), func2(val)); }; }; /* 数値の配列からA〜Fの成績の平均を計算する例で forkの動作を見てみる */ const computeAverageGrade = R.compose( getLetterGrade, fork(R.divide, R.sum, R.length) ); computeAverageGrade([99, 80, 89]); //=> 'B' /* 評価(点数)の集合について平均値と中央値(メディアン)が 等しいかどうかを調べる例 */ const eqMedianAverage = fork(R.equals, R.median, R.mean); eqMedianAverage([80, 90, 100]); //=> True eqMedianAverage([81, 90, 100]); //=> False
- forkコンビネータは、1個のリソースを2通りの異なる方法で処理して、その結果を結合するのに便利な関数である
-
コンビネータの利点
- コンビネータは自由を開放し、ポイントフリープログラミングを可能にする
- コンビネータは純粋なので、他のコンビネータに合成することもできる
- アプリケーションの複雑性を減らすことができる無数の選択肢を提供してくれる
- 関数型プログラミングは、不変性と純粋の基本原理を通じて、プログラムを構成する関数の細かいレベルのモジュール化を可能とし、再利用性を高めることができる
- モジュール化された関数型プログラムは、抽象的な関数から構成される
- 抽象的な関数は、個別に理解でき、再利用することができて、関数自体の意味はそれらの合成する規則から導き出される
- 本章では、純粋関数を作成することが関数型プログラミングの根幹であると学んだ
- これらのテクニックは、純粋関数が合成可能となることを目標として、カリー化や部分適用を用いて純粋関数の抽象化を活用する
- エラー処理について次章で見ていく
- コンビネータは自由を開放し、ポイントフリープログラミングを可能にする
-
コンビネータについて
まとめ
- まとめ
- 関数チェーンおよび関数パイプラインは、再利用可能かつモジュール化・コンポーネント化された関数を接続できる
- Ramdaはカリー化と合成に適した関数型ライブラリである
- カリー化と部分適用で、純粋関数のアリティを減らすことができる
- 全体の解決に到達するために、タスクを簡単な関数に分割して、それらの関数を合成することができる
- 関数コンビネータを使用すると、複雑なプログラムフローの調整や、ポイントフリーな方法でプログラムを書くことができるようになる
- 実世界の問題に挑戦しやすくなる
『JavaScript関数型プログラミング 複雑性を抑える発想と実践法を学ぶ』を読んだ 03 へ続く
Discussion