自社ECモールの商品検索エンジンをElasticsearchに置き換えた話
Elasticsearch導入の背景
私はECモールを運営する自社開発サービスのエンジニアとして働いており、WEBサイトのメイン部分はPHP(EC-CUBE)で稼働しております。
従来、モール内の商品検索を担う検索エンジン部分は、PHPから直接DBへSQLクエリを発行する仕組みとしており、メディアへの露出時など多数の流入があった際に、ボトルネックとなっていました。
SQLクエリの見直しを重ねてもなかなか改善にも限界があることから、検索エンジン部分を外出しするため、Elasticsearch(Elastic 社が開発しているオープンソースの全文検索エンジン)の導入をしました。
AWSもOpenSerchという同様のサービスを提供していますが、これはオープンソースであったElasticsearchをフォークして独自に提供しているサービスのためベースは同じものらしいです。ただし、Elastic社の担当者の方曰く、Elastic社のサービスの方が改善や機能追加の頻度が多く、優位であるとのことでしたので、そちらを採用することにしました。
elastic社のElasticsearchの中にもEC2等などサーバーを自社で用意しその上に立てるタイプと、クラウドでフルマネージドで提供してくれるタイプがありますが、運用の負担が少なそうな後者を選択しました。
Elasticsearch導入構成と作業一覧
- 全体構成
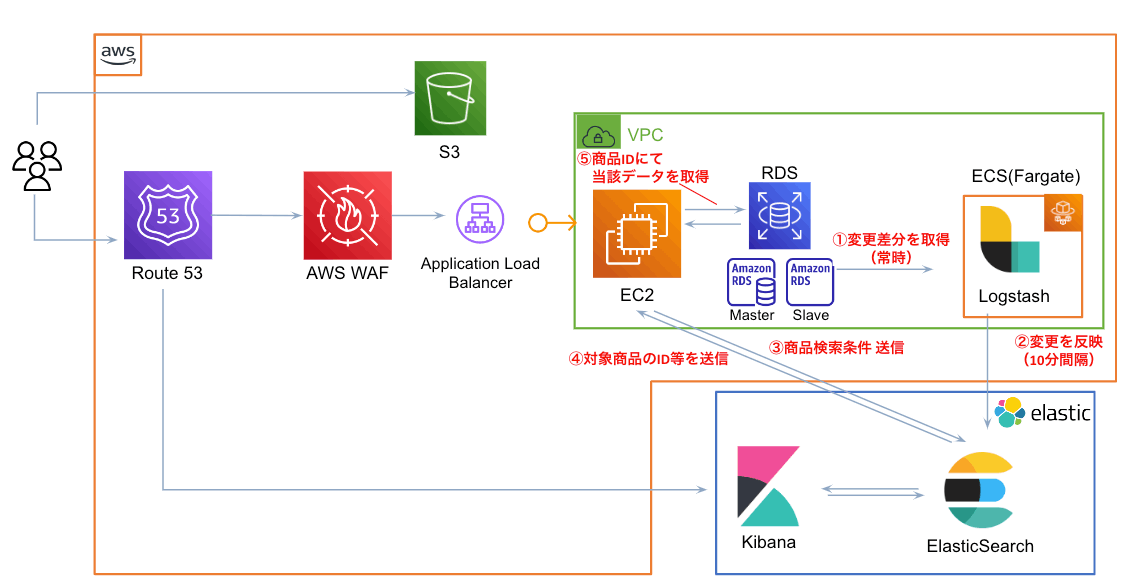
- 作業一覧
- elastic cloud環境の作成
- インデックスデータ作成用のパイプライン作成
- 検索クエリ発行用のプログラムを作成
作業手順
1. elastic cloud環境の作成
-
サインアップページから新規登録を行い、トップページの「Create deployment」を押下

-
Elasticsearchクラウドの環境を選択し、「Create Deployment」を押下
Name : 任意のデプロイメント名
Cloud provider : GCP, AWS, Azureから任意に選択可能ですが、自社でAWSがメインのためそちらを選択しました。
Region : 各クラウドサービスが提供しているリージョンから選択可能。今回はTokyo(ap-northeast-1) を選択。
Hardware profile : Storage Optimized, General Purpose, CPU Optimizedから選択可能で、検索エンジンでの利用はCPU Optimizedが一番パフォーマンスが良いようですが、一番安いStorage Optimizedの2倍の料金であることかつ、検索時の体感に差を感じられなかったことからStorage Optimizedを選択しました。
Version : Elasticsearchのバージョンですが、新規作成時は最新(latest)で問題ないと思います。ただし、リリース後の運用フェーズにおいてElasticsearchの環境を更新した際に、バージョンも一緒に新しくしたところ、仕様の差異により不具合が発生したことがあったため、当たり前ですがバージョンを変える際はしっかりテストを行うようにした方が良いです。
[重要] :デプロイメントの作成が完了するまで5分弱を要します。完了すると画面にelasticsearch接続用のユーザー名とパスワードが取得できるため控えておきます。パスワードについては、後で確認できないため、忘れずに保存しておきます。

2. インデックスデータ作成用のパイプライン作成
既存のデータベースから商品情報を取得および加工し、Elasticserchへインデックスデータを同期するためのパイプラインを作成していきます。
インフラ部分はEC2等でも問題ないかと思いますが、今回はインフラ面の設計フェーズに時間をかけたくなかった事や運用保守の手軽さから、AWS ECSのFargateでコンテナ上に構築することにしました。
ローカルではDockerコンテナ上で開発を進めるため、公式ドキュメントをベースに進めていきます。
- logstashプロジェクト構成
.
├── logstash
│ ├── config
│ │ ├── jvm.options
│ │ ├── logstash.yml
│ │ └── pipelines.yml
│ └── pipeline
│ ├── mysql-connector-java-8.0.28.jar
│ └── product.conf
├── Dockerfile
└── docker-compose.yml
- logstash/config/jvm.options
logstashはJAVAで実装されているようで、先程のイメージでJava仮想マシン(JVM)をインストールするようになっているようです。
下記の公式ドキュメントに、elasticsearch利用の際の推奨設定項目等が記載されているため、用途に合わせてチューニングします。
https://www.elastic.co/guide/en/logstash/8.6/jvm-settings.html
## JVM configuration
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms6g
-Xmx6g
################################################################
## Expert settings
################################################################
##
## All settings below this section are considered
## expert settings. Don't tamper with them unless
## you understand what you are doing
##
################################################################
## GC configuration
11-13:-XX:+UseConcMarkSweepGC
11-13:-XX:CMSInitiatingOccupancyFraction=75
11-13:-XX:+UseCMSInitiatingOccupancyOnly
## Locale
# Set the locale language
#-Duser.language=en
# Set the locale country
#-Duser.country=US
# Set the locale variant, if any
#-Duser.variant=
## basic
# set the I/O temp directory
#-Djava.io.tmpdir=$HOME
# set to headless, just in case
-Djava.awt.headless=true
# ensure UTF-8 encoding by default (e.g. filenames)
-Dfile.encoding=UTF-8
# use our provided JNA always versus the system one
#-Djna.nosys=true
# Turn on JRuby invokedynamic
-Djruby.compile.invokedynamic=true
# Force Compilation
-Djruby.jit.threshold=0
## heap dumps
# generate a heap dump when an allocation from the Java heap fails
# heap dumps are created in the working directory of the JVM
-XX:+HeapDumpOnOutOfMemoryError
# specify an alternative path for heap dumps
# ensure the directory exists and has sufficient space
#-XX:HeapDumpPath=${LOGSTASH_HOME}/heapdump.hprof
## GC logging
#-Xlog:gc*,gc+age=trace,safepoint:file=@loggc@:utctime,pid,tags:filecount=32,filesize=64m
# log GC status to a file with time stamps
# ensure the directory exists
#-Xloggc:${LS_GC_LOG_FILE}
# Entropy source for randomness
-Djava.security.egd=file:/dev/urandom
# Copy the logging context from parent threads to children
-Dlog4j2.isThreadContextMapInheritable=true
この中で特に、利用するメモリ容量(ヒープサイズ)については4GB~8GBが推奨のようで、少ないと、ガーベージコレクションが頻繁に発生することによりCPU使用率が過度に上がってしまう恐れがあるそう。
また、物理サーバのメモリサイズの75%を超えないように設定することも推奨されております。こちらのチューニングは実際には、logstashを立ち上げ、elastcisearchへの同期の速度を検証しつつちょうど良い具合に設定することにしました。その結果、今回はサーバ(Fargate)を、メモリ8GBで設定し、logstashは6GBにすることにしました。
-Xms6g
-Xmx6g
- logstash/config/logstash.yml
logstashパイプラインでデータを送り込む先である、elasticsearchの接続情報を記載します。
pipeline.ordered: auto
xpack.monitoring.elasticsearch.hosts: ["https://{hoge}.es.ap-northeast-1.aws.found.io:9243"]
xpack.monitoring.elasticsearch.username: "elastic"
xpack.monitoring.elasticsearch.password: {password}
xpack.monitoring.elasticsearch.ssl.verification_mode: none
xpack.monitoring.elasticsearch.hosts : elasticsearchのダッシュボードからホストのURLを取得し、後ろにポート番号(「:9243」の部分)を付記。
xpack.monitoring.elasticsearch.username : デプロイメント作成時に取得した接続情報に記載のユーザー名を記載。デフォルトは「elastic」。
xpack.monitoring.elasticsearch.password : デプロイメント作成時に取得した接続情報に記載のパスワードを記載。
- logstash/config/pipelines.yml
- pipeline.id: product
path.config: "/usr/share/logstash/pipeline/product.conf"
queue.type: persisted
pipeline.workers: 1
- logstash/pipeline/mysql-connector-java-8.0.28.jar
ORACLEの公式サイトよりMySQL用のJDBCドライバ(OSのタイプはPlatform Independent)をインストールして配置します。
※データベースがMySQL以外の場合はそれにあったコネクターを配置してください。
https://dev.mysql.com/downloads/connector/j/ - logstash/pipeline/product.conf
このファイルでパイプラインのインプットとアウトプットを定義していきます。
ざっくりとした流れとしては
- データソース(今回でいえばMySQLのRDS)からSQLでデータを取得
- 取得したデータをインデックスに格納したいフォーマットに加工
- Elasticsearchへアウトプット
下記のイメージで既存のリレーショナルデータベースから取得したデータをElasticsearchでの検索に使用するためのインデックスデータに加工していきます。

input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/pipeline/mysql-connector-java-8.0.28.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://{rds_host}:3306"
jdbc_user => "{db_user}"
jdbc_password => "{db_password}"
jdbc_paging_enabled => false
tracking_column => "unix_ts_in_secs"
tracking_column_type => "timestamp"
last_run_metadata_path => "/usr/share/logstash/.logstash_jdbc_last_run_product"
use_column_value => true
schedule => "* */10 * * * *"
statement => "(select
dp.product_id,
dp.name,
dp.main_comment,
dp.del_flg as dp_del_flg,
dpc.product_class_id,
dpc.product_code,
dpc.stock,
dpc.del_flg as dpc_del_flg,
group_concat(DISTINCT(dpca.category_id)) as category_ids,
UNIX_TIMESTAMP(current_timestamp) as unix_ts_in_secs
from
ssdemodb2.dtb_products dp
left join ssdemodb2.dtb_brands db on db.brand_name = dp.product_brand
left join ssdemodb2.dtb_products_class dpc on dp.product_id = dpc.product_id
left join ssdemodb2.dtb_product_categories dpca on dp.product_id = dpca.product_id
where
UNIX_TIMESTAMP(dp.update_date) >= :sql_last_value
or dp.product_id in (
select
product_id
from
ssdemodb2.dtb_products_class dpc
where
UNIX_TIMESTAMP(dpc.update_date) >= :sql_last_value
)
GROUP by
dpc.product_class_id)
}
}
filter {
ruby {
code => "event.set('category_ids', event.get('category_ids').split(',')) if (!event.get('category_ids').nil?);
}
aggregate {
task_id => "%{product_id}"
code => "
map['product_id'] = event.get('product_id')
map['name'] = event.get('name')
map['main_comment'] = event.get('main_comment')
map['dp_del_flg'] = event.get('dp_del_flg')
map['dtb_products_class'] ||= []
map['dtb_products_class'] << {
'product_class_id' => event.get('product_class_id'),
'product_code' => event.get('product_code'),
'stock' => event.get('stock'),
'dpc_del_flg' => event.get('dpc_del_flg'),
}
map['unix_ts_in_secs'] = event.get('unix_ts_in_secs')
event.cancel()"
push_previous_map_as_event => true
timeout => 300
}
mutate {
copy => { "product_id" => "[@metadata][_id]"}
}
}
output {
elasticsearch {
hosts => ["https://{elasticsearch_host}:9243"]
index => "products"
document_id => "%{[@metadata][_id]}"
user => "elastic"
password => "{elasticsearch_password}"
}
}
主な設定項目に関して、簡単に説明していきます。
こちらの設定は既存のデータソース(MySQLデータベース)および、JDBCドライバの設定値となるため、前述の作業までの情報を元に記載します。
jdbc_driver_library => "/usr/share/logstash/pipeline/mysql-connector-java-8.0.28.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://{rds_host}:3306"
jdbc_user => "{db_user}"
jdbc_password => "{db_password}"
同期の頻度をcron形式で指定します。今回はRDSへの負荷と検索情報の鮮度を天秤にかけて10分に設定しました。
schedule => "* */10 * * * "
ページング処理(Elasticseach側でSQLにOFFSETを追加し、データ取得を分割してくれる)を実施するかの有無。
下記をtrueに設定することで、データ取得時のSQLを分割して実行してくれます。これにより、DBの負荷とネットワークの負荷を分散することが可能です。しかし、公式ドキュメントの記載に「Be aware that ordering is not guaranteed between queries」とあるように、データの取得順番が保証されないため、RDBのデータベース構成およびSQLの書き方によってはデータが重複する事象が発生します。
実際に自分もこの仕様にハマってしまい、インデックスデータの重複が発生するケースがありました。
今回の場合、商品ヘッダに複数の明細データをJOINして取得しているため、OFFSETでデータが取得され、かつSQLの実行順が担保されないため、後述の「2. 取得したデータをインデックスに格納したいフォーマットに加工」の過程において不整合が起きて、インデックスデータの重複が発生してしまいます。この点については後ほど補足します。
jdbc_paging_enabled => false
tracking_columnは同期用のsqlが実行された時間が格納されているカラムを指定する行です。この値が、last_run_metadata_pathで指定したファイルに保存され、
次回、同期用クエリを発行する際に最終同期時間をSQLに埋め込むことにより、前回の同期から更新があったレコードのみを同期対象とすることができます。(SQLの :sql_last_valueの部分で呼び出している)
use_column_valueをfalseにした場合は、tracking_columnに関わらず、最後にSQLを発行した時間を :sql_last_valueで使用できます。
tracking_column => "unix_ts_in_secs"
tracking_column_type => "timestamp"
last_run_metadata_path => "/usr/share/logstash/.logstash_jdbc_last_run_product"
use_column_value => true
下記に、RDBからデータを取得するためのSQLを記載します。
schedule =>"{データ取得用SQL}"
下記の部分が、logstashのruby filterという機能で、SQLで取得したレコードに対して何かしら加工したい場合、Rubyのコードをインラインで記載することができます。
下記の例であれば、「category_ids」がカンマ区切りで取得されたのもを、配列に変換しています。 インデックスにしたときに、同類のデータが複数ある場合(例:商品のカテゴリが複数ある場合)、配列で持っておくことにより、or条件での検索が可能になります。
ruby {
code => "event.set('category_ids', event.get('category_ids').split(',')) if (!event.get('category_ids').nil?);
}
RDBから取得してきたデータ1行がそのまま、Elasticsearchのドキュメント(RDBで言うレコード)1行になれば良いのですが、
本件のように商品ヘッダに商品明細が複数リレーションする場合で、商品ヘッダごとのインデックスを作成したい場合、SQLで取得してきた複数レコードを1ドキュメントにまとめる必要があります。そこで出てくるのが、下記のaggregate filterです。
ここは処理のイメージとしては、RDBから取得してきた商品明細単位のレコードが順番に流れてきて、商品ヘッダIDが変わるまで、商品の明細データをフィールド(RDBで言うところのカラム)ごとに配列にまとめていくような処理となります。
task_idの部分で指定したカラム(商品ヘッダID)が変わるまで、流れてくるレコードを1つのドキュメントにまとめる処理を実行します。実際に配列に入れる処理はcodeの中にRubyで記載しています。
aggregate {
task_id => "%{product_id}"
code => "
map['product_id'] = event.get('product_id')
map['name'] = event.get('name')
map['main_comment'] = event.get('main_comment')
map['dp_del_flg'] = event.get('dp_del_flg')
map['dtb_products_class'] ||= []
map['dtb_products_class'] << {
'product_class_id' => event.get('product_class_id'),
'product_code' => event.get('product_code'),
'stock' => event.get('stock'),
'dpc_del_flg' => event.get('dpc_del_flg'),
}
map['unix_ts_in_secs'] = event.get('unix_ts_in_secs')
event.cancel()"
push_previous_map_as_event => true
timeout => 300
特筆すべき内容は記載していないため、説明は割愛しますが、logstashの公式イメージを使用し、前述までで作成した各種設定ファイルをイメージにコピーしています。
- Dockerfile
FROM docker.elastic.co/logstash/logstash:8.1.1
RUN rm -f /usr/share/logstash/pipeline/logstash.conf
ADD logstash/pipeline/ /usr/share/logstash/pipeline/
ADD logstash/config/ /usr/share/logstash/config/
ローカルで検証するためにdocker-compose.ymlで管理していますが、別コンテナと紐付けて使用するなどがなければ作成しなくても良いです。
- docker-compose.yml
version: '3'
services:
logstash:
build: .
ここまでで、logstashの構築が完了したので、実際にコンテナを立ち上げて、elasticsearchにインデックスデータを作成します。
今回、実際の本番環境ではインフラ部分の管理をしたくなかったため、AWS ECSでFargateタイプのコンテナを選択し稼働させています。
3. 検索クエリ発行用のプログラムを作成
前述まででElasticsearchのクラウド上にインデックスデータが作成されている状態のため、実際に検索条件を指定して、対象のデータを取得する機構を実装します。
検索にはElasticsearchのフォーマットに沿って作成した下記のようなjson形式の検索条件を検索APIエンドポイント({elasticsearchのホスト名}/{index}/_search )にGETまたはPOSTすることで取得できます。
{
"query": {
"bool": {
"filter": [
{
"bool": {
"must": [
{
"range": {
"start_date": {
"lte": 1655996400
}
}
},
{
"bool": {
"should": [
{
"range": {
"end_date": {
"gte": 1655996400
}
}
},
{
"term": {
"end_date": "0"
}
}
]
}
},
{
"term": {
"draft_flg": "0"
}
},
{
"term": {
"dp_del_flg": "0"
}
}
]
}
}
]
}
},
"from": 0,
"size": "60",
"_source": [
"product_id"
],
"sort": [
{
"eval_product4": "desc"
},
{
"published_date": "desc"
},
{
"product_id": "asc"
}
]
}
<?php
class SC_Helper_Elasticsearch
{
private $elasticsearch_url = "";
private $elasticsearch_all_count_url = "";
// _search APIで一度に取得可能なデータ上限数
const UPPER_LIMIT_OF_ELASTICSEARCH_RESULT = 10000;
public function __construct($target_index_name)
{
$this->setSearchUrlByTargetIndexName($target_index_name);
}
private function setSearchUrlByTargetIndexName($target_index_name)
{
// 検索用URLをセット
$this->elasticsearch_url = ELASTICSEARCH_URL . $target_index_name . "/_search";
// 全件数取得用URLをセット
$this->elasticsearch_all_count_url = ELASTICSEARCH_URL . $target_index_name . "/_count";
}
private function postJson($url, $data, $timeout_limit_seconds=30)
{
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_HTTPHEADER, array('Content-type: application/json'));
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_TIMEOUT, $timeout_limit_seconds);
curl_setopt($curl, CURLOPT_USERNAME, ELASTICSEARCH_ID);
curl_setopt($curl, CURLOPT_PASSWORD, ELASTICSEARCH_PASSWORD);
// 証明書を利用しない
curl_setopt($curl,CURLOPT_SSL_VERIFYPEER, false);
$result = curl_exec($curl);
curl_close($curl);
return $result;
}
// 検索条件に合致する全件数を取得(10,000件を超える検索結果となる場合は_search APIでは取得不可のため_count APIを使用する)
private function getTotalResultNumberOfSearchConditions($search_param_array, $timeout_limit_seconds)
{
// 連想配列からjsonを生成し成形
$_search_json_param = json_encode($search_param_array, JSON_UNESCAPED_UNICODE|JSON_PRETTY_PRINT);
$search_json_param = stripslashes($_search_json_param);
$result_json = $this->postJson($this->elasticsearch_all_count_url, $search_json_param, $timeout_limit_seconds);
$response_array = json_decode($result_json, true);
// elasticsearchからエラーコードが返却された場合
if (array_key_exists("error", $response_array)) throw new Exception("Elasticsearch検索エラー(エラーコード:" . $response_array["status"] . ")");
// elasticsearchからエラーコードが返却されず、nullの場合はタイムアウトによるエラー
if (SC_Utils_Ex::isBlank($response_array)) throw new Exception("Elasticsearch検索エラー(タイムアウト)");
if ( ! SC_Utils_Ex::isBlank($response_array["count"])) {
return $response_array["count"];
}
else {
return 0;
}
}
public function searchByTimeoutLimitSeconds($search_param_array, $timeout_limit_seconds)
{
// 連想配列からjsonを生成し成形
$_search_json_param = json_encode($search_param_array, JSON_UNESCAPED_UNICODE|JSON_PRETTY_PRINT);
$search_json_param = stripslashes($_search_json_param);
$result_json = $this->postJson($this->elasticsearch_url, $search_json_param, $timeout_limit_seconds);
$response_array = json_decode($result_json, true);
// elasticsearchからエラーコードが返却された場合
if (array_key_exists("error", $response_array)) throw new Exception("Elasticsearch検索エラー(エラーコード:" . $response_array["status"] . ")");
// elasticsearchからエラーコードが返却されず、nullの場合はタイムアウトによるエラー
if (SC_Utils_Ex::isBlank($response_array)) throw new Exception("Elasticsearch検索エラー(タイムアウト)");
// 検索条件の対象全件数
$total_count = $response_array["hits"]["total"]["value"];
// 検索結果が10,000件以上となる場合は、_search APIで件数取得ができないため、_count API で取得しなおす
if ($total_count >= self::UPPER_LIMIT_OF_ELASTICSEARCH_RESULT) {
$_count_param_array = $search_param_array["query"];
$count_param_array["query"] = $_count_param_array;
$total_count = $this->getTotalResultNumberOfSearchConditions($count_param_array, $timeout_limit_seconds);
}
// 検索結果を連想配列で返す
return [$total_count, $response_array];
}
}
Discussion