ドメイン駆動設計(DDD)についてとビジネスロジックの別け方
ドメイン駆動設計(DDD)とは
顧客と開発者が業務を戦略的に理解し、共通の言葉を使いながらシステムを発展させる手法のこと。
つまりは、業務担当者であるドメインエキスパートと開発者が、チームの共通言語である「ユビキタス言語」を用いて「ドメインモデル」を構築し、それをコードとして実装する。
また大規模で密結合なシステムにならないようにドメイン(問題領域)と境界づけられたコンテキストにてシステムを分割し、コアドメインという最重要領域、つまりは最も大事な業務領域に集中して開発を行う。
アーキテクチャ
ドメイン駆動設計の戦術的設計には、主に以下の4種類のアーキテクチャがあります。
- レイヤーアーキテクチャ
- ヘキサゴナルアーキテクチャ
- クリーンアーキテクチャ
- イベント駆動アーキテクチャ
今回はレイヤーアーキテクチャを用いて実装方法を説明していきます。
プレゼンテーション層
リクエストを受け付けたり、レスポンスを返したりと外部をやりとりする層
アプリケーション層
プレゼンテーション層とドメイン層の仲介役
ドメイン層
ビジネス上の解決すべき問題(コアドメイン)を表現し、オブジェクトやビジネスロジックを主に含みます。
この層は他の層に依存しない。
インフラ層
データベースとの接続や外部システムとの連携を行う層。
パッケージ構成
$ tree
.
├── application # アプリケーション層
│ ├── command
│ ├── dto
│ └── service
│
├── domain
│ └── model # ドメイン層
│
├── infrastructure # インフラ層
│ ├── repository
│ └── service
│
└── presentation # プレゼンテーション層
├── controller
├── request
└── response
エンティティ (Entity)
一意な識別を持つオブジェクト。
利用場面としては、そのシステムでオブジェクトの変更を管理する必要があるときなど。
エンティティの例
Entitiyの例として表せそうなものとしては以下のものがある。
- 社員(マイナンバーや社員番号で識別) : 氏名、住所、所属、給与といった属性を適切に変更する必要がある
- 記事(記事のIDで識別) : タイトルや本文を変更して管理する必要がある
- 商品(JANコードで識別) : 価格、在庫数などを変更したり、商品を削除したりする必要がある
値オブジェクト (Value Object)
ただの値を表現するオブジェクト。
使用場面としては、そのシステムでオブジェクトの変更を管理する必要がないときなど。
値オブジェクトの例
値オブジェクトの例として表せそうなもの。
- 名前 : 姓名 + 氏名で構成される
- 住所 : 郵便番号 + 都道府県 + 市町村 + 町 + 番地 + 号 (+ 建物名 + 部屋番号)で構成される
- 価格 : 数値 + 通貨(円/ドル/...)で構成される
-
実装する時は、できるだけ「値オブジェクト」を使ってプログラムすることが推奨されている。エンティティはなくとも大丈夫で、どうしても必要なときに実装するくらいで構わない。
-
あるシステムではエンティティとして設計されても、別のシステムでは値オブジェクトで設計した利する場合もある。
あるECサイトで、商品を管理する「商品管理システム」と商品を検索する「商品検索システム」があったとします
- 「商品管理システム」 => 商品を価格や商品名を変更したりする必要があるのでエンティティとして設計
- 「商品検索システム」 => クエリに応じて商品を検索するだけなので、商品を変更したりすることがないので値オブジェクトとして設計
Entity (Python)
エンティティを実装する時は、以下の項目を満たさなければいけない。
- 同一性
- 不変性
- 自己カプセル化
同一性
一意な識別子でエンティティが同一かどうか判定できるようにする
不変性
一意な識別子を変更できないようにする
自己カプセル化
値を一意な識別子やプロパティにセットする前に、セッターでバリデーションを行う
class エンティティ:
def __init__(self, id, a):
assert id is not None, "idにNoneが指定されています"
# 2. 不変性: 一意な識別子を変更できないようにする
self.__一意な識別子 = id # ※pythonではプライベートなプロパティを持てないので"__"で隠蔽しています
self.プロパティ = a
def __eq__(self, other):
if not isinstance(other, エンティティ):
return False
# 1. 同一性: 一意な識別子でエンティティが同一かどうか判定できるようにする
return other.一意な識別子 == self.一意な識別子
@property
def 一意な識別子(self):
return self.__一意な識別子
@property
def プロパティ(self):
return self.__プロパティ
@プロパティ.setter
def プロパティ(self, a):
# 3. 自己カプセル化: 値を一意な識別子やプロパティにセットする前に、セッターでバリデーションを行う
assert a is not None, "引数aにNoneが指定されました。〇〇を指定してください。"
self.__プロパティ = a
Python 3.7から導入されたdataclassとの相性が良い。
下記はid,name,ageというフィールドを持つEntityの例。
@dataclass
class User(frozen=True, eq=True):
id: str
name: str
age: int
user_1: User = User(id="1", name="test_1", age=20)
user_2: User = User(id="1", name="test_1", age=20)
# 値による同一性検証でTrueになる(デフォルトでeq=Trueが設定済み)
user_1 == user_2
# frozenで不変オブジェクトになっているのでエラーになる
user_1.id = "2"
dataclass自身が持つ機能はそれだけで便利ですが、とりわけ不変条件を持たせるためのfrozen、値による同一性検証としてのeqといったプロパティは、Entity層に期待される動作。(もちろん不変性や値比較可能であることが必ず求められているわけではない)
またEntity層に限らずとも、単体テストでオブジェクトの同一性検証をする際、__eq__メソッドを逐次定義するのは手間ですし、dataclassを利用するメリットは大きい。
ValueObject (Python)
値オブジェクトを実装する時は、以下の項目を満たさなければいけない。
- 不変性
- 等価性
不変性
値オブジェクトの生成後、インスタンス変数などの値を変更できないようにする
等価性
各プロパティの値で値オブジェクトが同じかどうか判定できるようにする
class 値オブジェクト:
def __init__(self, a: str, b: int):
assert a is not None, "引数aにNoneが指定されています。"
assert b is not None, "引数bにNoneが指定されています。"
self.__プロパティA = a
self.__プロパティB = b
def __eq__(self, other):
if not isinstance(other, 値オブジェクト):
return False
return (other.プロパティA == self.プロパティA) and (other.プロパティB == self.プロパティB)
def __hash__(self):
return hash(self.プロパティA + self.プロパティB)
@property
def プロパティA(self):
return self.__プロパティA
@property
def プロパティB(self):
return self.__プロパティB
集約 / コンポジション
実際の業務では、単体のエンティティや値オブジェクトで設計・開発することはほとんどない。
集約/コンポジションで設計・開発を行う
集約
エンティティと値オブジェクトの塊
コンポジション
値オブジェクトの塊
-
集約は、それを構成する一部に変更を加えることができる。
-
コンポジションは、塊として生まれ、消される。コンポジションを構成する一部に変更を加えることができない。
集約とコンポジションは、ドメイン層に集約名 / コンポジション名でパッケージを作成する
└── domain
├── __init__.py
└── model
├── __init__.py
├── コンポジション名 # パッケージ
├── 集約名 # パッケージ
└── ...
「集約 」の実装例
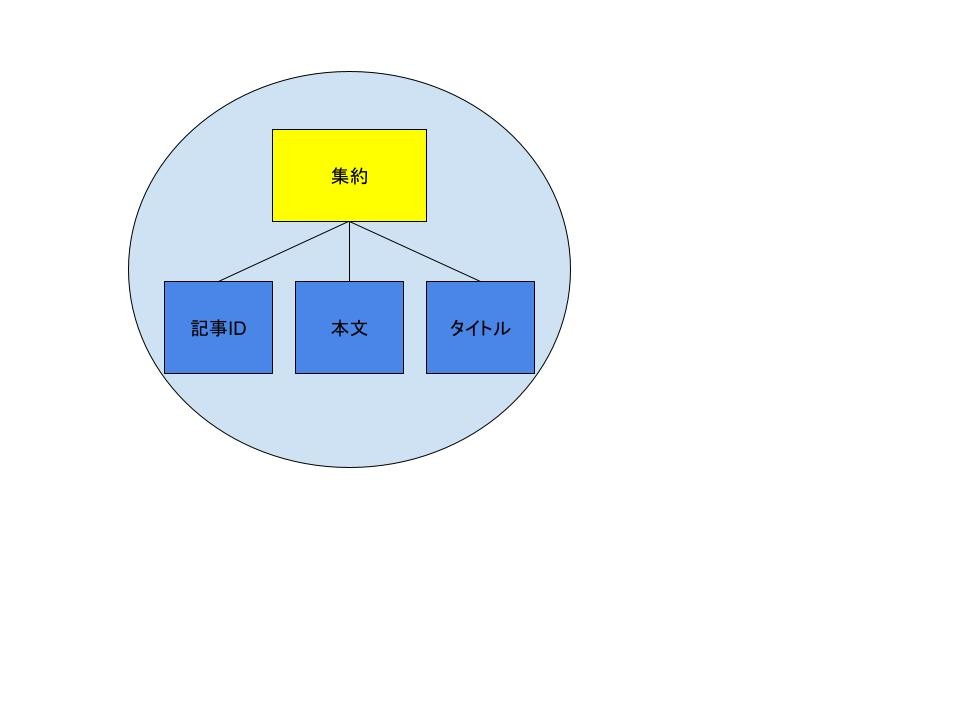
└── domain
├── __init__.py
└── model
├── __init__.py
└── article # 記事集約
├── __init__.py
├── article.py # 記事
├── article_id.py # 記事ID
├── content.py # 本文
└── title.py # タイトル
class 記事ID:
def __init__(self, value: str):
assert isinstance(value, str), "引数valueには、文字列を指定してくだい。"
assert value is not None and value != "", "引数valueは必須です。文字列を指定してください。"
self.__value = value
@property
def value(self) -> str:
return self.__value
class タイトル:
def __init__(self, text: str):
assert isinstance(text, str), "引数textには、文字列を指定してください。"
assert text is not None, "引数textは必須です。文字列を指定してください。"
assert len(text) <= 20, "引数textには20文字以内の文字列を指定してください。"
self.__text = text
@property
def text(self) -> str:
return self.__text
class 本文:
def __init__(self, text: str):
assert isinstance(text, str), "引数textには、文字列を指定してください。"
assert text is not None, "引数textは必須です。文字列を指定してください。"
self.__text = text
@property
def text(self) -> str:
return self.__text
class 記事:
def __init__(self,
id: 記事ID,
title: タイトル,
content: 本文):
assert isinstance(id, 記事ID) and id is not None, "引数idには、記事ID型を指定してください。"
self.__id = id
self.title = title
self.content = content
def __eq__(self, other):
if not isinstance(other, 記事):
return False
return other.id == self.id
@property
def id(self):
return self.__id
@property
def title(self):
return self.__title
@title.setter
def title(self, new_title: タイトル):
assert new_title is not None, "引数new_titleにNoneが指定されました。タイトル型を指定してください。"
self.__title = new_title
@property
def content(self):
return self.__content
@content.setter
def content(self, new_content: 本文):
assert new_content is not None, "引数new_contentにNoneが指定されました。本文型を指定してください。"
self.__content = new_content
「コンポジション」の実装例
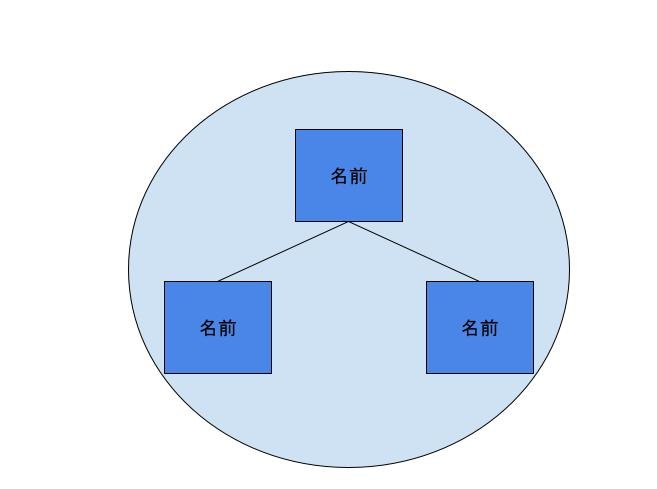
└── domain
├── __init__.py
└── model
├── __init__.py
└── name # 名前コンポジション
├── __init__.py
├── first_name.py # 氏名
└── last_name.py # 姓名
pythonコード
class 姓名:
def __init__(self, name: str):
assert isinstance(name, str), "引数nameには、文字列を指定してください。"
assert name is not None and name != "", "引数nameは必須です。文字列を指定してください。"
self.__name = name
@property
def name(self) -> str:
return self.__name
class 氏名:
def __init__(self, name: str):
assert isinstance(name, str), "引数nameには、文字列を指定してください。"
assert name is not None and name != "", "引数nameは必須です。文字列を指定してください。"
self.__name = name
@property
def name(self) -> str:
return self.__name
class 名前:
def __init__(self, first_name: 氏名, last_name: 姓名):
assert isinstance(first_name, 氏名), "first_nameには氏名型を指定してください。"
assert isinstance(last_name, 姓名), "last_nameには姓名型を指定してください。"
assert first_name is not None, "first_nameは必須です。"
assert last_name is not None, "last_nameは必須です。"
self.__first_name = first_name
self.__last_name = last_name
@property
def first_name(self):
return self.__first_name
@property
def last_name(self):
return self.__last_name
ドメインサービスとは
あるロジックを実現したいがエンティティ/値オブジェクト/集約/コンポジションに実装するのが不適切である場合に用いる。
大抵のロジックは、エンティティ/値オブジェクト/集約/コンポジションのプロパティやメソッドとして実装できるので、ドメインサービスはなくても問題ない。
ドメインサービスを多用すると、次のような問題が発生する。
-
プロパティだけのエンティティ/値オブジェクトが発生(ドメイン貧血症) - ドメインサービスに
ロジックが集中し、バグの温床になる/テストコードが肥大化する
例えば、「複数のエンティティ/値オブジェクト/集約/コンポジションをもとに計算するロジック」など、どうしてもエンティティや値オブジェクトなどで実装できない時や不適切である時にだけドメインサービスを使うべきです。
ドメインサービスは、次のようにドメイン層に実装する。
関連する集約パッケージ、コンポジションのパッケージ以下に実装
$ tree
└── domain
├── __init__.py
└── model
├── __init__.py
├── パッケージ名
│ └── ドメインサービス名.py
├── 集約名
│ └── ドメインサービス名.py
└── コンポジション名
└── ドメインサービス名.py
ドメインサービスの実装例
class ItemRecommender:
"""ユーザーに対して商品をレコメンドするドメインサービス"""
def recommend(self, user: User, items: Items) -> RankedItems:
# ユーザー×商品のマッチスコアと商品IDを格納する変数
scores = {}
# ユーザー×商品のマッチスコアを計算します
for item in items:
# 売れ切れている商品は除外
if item.is_sold_out():
continue
# マッチスコアを計算
match_score = user.calculate_match_score(item)
# 計算結果を格納
scores[item.id] = match_score
# RankedItemsクラスのsort_byメソッド(staticメソッド)を使って、インスタンス化
return RankedItems.sort_by(scores)
セパレートインターフェースで実装
セパレートインターフェースとは、インターフェースとそれを継承した実装クラスの2つに分けて管理する設計パターンのこと。
Pythonではインターフェースがないため、代わりに抽象クラスを使用します。
そして、その抽象クラスを継承した実装クラスの2つを定義することで実現させます。
- 抽象クラス
- 抽象クラスを継承した実装クラス
セパレートインターフェースを利用した方が良い場合の例
- 将来、実装クラスを差し替える可能性がある
- 複数のロジックがある
セパレートインターフェースの方法でドメインサービスを実装することで、実装が抽象に依存する(依存性逆転の原則)プログラムになるので、途中でロジックを切り替えても依存元に影響がないため、改修の必要が無い。
抽象クラスを定義
import abc
class ItemRecommender(abc.ABC):
"""ユーザーに対して商品をレコメンドするドメインサービスを抽象クラスで定義"""
@abc.abstractmethod
def recommend(self, user: User, items: Items) -> RankedItems:
pass
抽象クラスを継承した実装クラスを定義
from ..item_recommender import ItemRecommender
class CalculateMatchPointRecommender(ItemRecommender):
"""
ユーザーに対してマッチスコアが高い順に商品をレコメンドするドメインサービス
"""
def recommend(self, user: User, items: Items) -> RankedItems:
# ユーザー×商品のマッチスコアと商品IDを格納する変数
scores = {}
# ユーザー×商品のマッチスコアを計算します
for item in items:
# 売れ切れている商品は除外
if item.is_sold_out():
continue
# マッチスコアを計算
match_score = user.calculate_match_score(item)
# 計算結果を格納
scores[item.id] = match_score
# RankedItemsクラスのsort_byメソッド(staticメソッド)を使って、インスタンス化
return RankedItems.sort_by(scores)
class EstimatePurchaseProbabilityRecommender(ItemRecommender):
"""
ユーザーに対して購入確率が高い順に商品をレコメンドするドメインサービス
"""
def __init__(self, estimator: Estimator):
self.__estimator = estimator
def recommend(self, user: User, items: Items) -> RankedItems:
# ユーザー×商品の購入確率と商品IDを格納する変数
scores = {}
# ユーザー×商品の購入確率を計算します
for item in items:
# 売れ切れている商品は除外
if item.is_sold_out():
continue
# 購入確率を計算
prob = self.__estimator.predict(user, item)
# 計算結果を格納
scores[item.id] = prob
# RankedItemsクラスのsort_byメソッド(staticメソッド)を使って、インスタンス化
return RankedItems.sort_by(scores)
リポジトリ
リポジトリは、集約のCRUDを担当するオブジェクト。
実際にデータベースとやりとりを行う。
集約とリポジトリは1対1の関係になる: 例えば、「企業」という集約を格納・取得するときは、「企業リポジトリ」を使う。
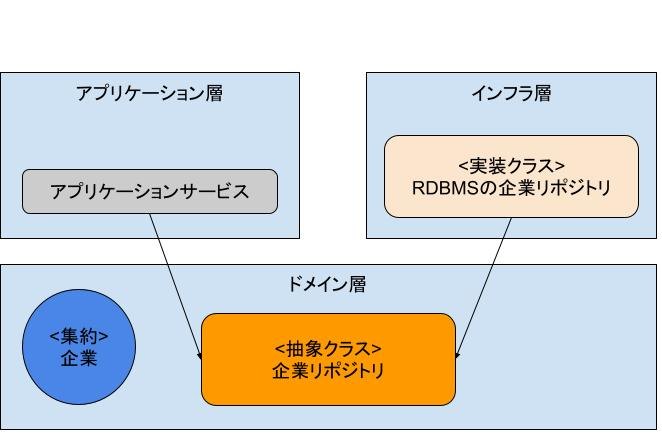
$ tree
├── domain
│ ├── __init__.py
│ └── model
│ ├── __init__.py
│ └── company # 企業集約
│ ├── __init__.py
│ ├── company.py # 企業(エンティティ)
│ ├── company_id.py # 企業ID(値オブジェクト)
│ ├── name.py # 企業名(値オブジェクト)
│ └── company_repository.py # 企業リポジトリ(インターフェース)
├── infrastructure
│ ├── __init__.py
│ └── repository
│ ├── __init__.py
│ └── company
│ ├── __init__.py
│ └── mysql_company_repository.py # 企業リポジトリ(実装クラス)
ドメイン層の実装例
import abc
from typing import NoReturn
class CompanyRepository(abc.ABC):
def company_with(self, company_id: CompanyId) -> Company:
"""企業ID指定で企業(集約)を取得する"""
pass
def save(self, company: Company) -> NoReturn:
"""企業(集約)を保存する"""
pass
def delete(self, company_id: CompanyId) -> NoReturn:
"""企業ID指定で企業(集約)を削除する"""
pass
インフラ層
from domain.model import CompanyRepository
class MySQLCompanyRepository(CompanyRepository):
def __init__(self, driver):
self.__driver = driver
def company_with(self, company_id: CompanyId) -> Company:
"""企業ID指定で企業(集約)を取得する"""
return self.__driver.select_company_by_(company_id)
def save(self, company: Company) -> NoReturn:
"""企業(集約)を保存する"""
if self.__driver.has_record_of(company.id):
self.__driver.update(company)
else:
self.__driver.insert(company)
def delete(self, company_id: CompanyId) -> NoReturn:
"""企業ID指定で企業(集約)を削除する"""
self.__driver.delete(company)
ファクトリ
ファクトリとは、集約やコンポジションをシンプルに生成するオブジェクト。
オブジェクトの生成パターン
集約やコンポジションのコンストラクタで生成する
- 単純な生成を行う場合によい
- しかし、複雑な生成には適さない
- 引数が長くなりがち
class User:
def __init__(self,
user_id: UserId,
first_name: FirstName,
last_name: LastName,
profile_image_path: ProfileImagePath,
age: Age,
gender: Gender):
# バリデーションを行う
# ...
# ...
self.__user_id = user_id
self.first_name = first_name
self.last_name = last_name
self.profile_image_path = profile_image_path
self.age = age
self.gender = gender
# methods
# ...
a_user = User(user_id, FirstName("taiyo"), LastName("tamura"),
ProfileImagePath("https://hogeho.com/path/to/image"),
Age(26), Gender.MEN)
ファクトリメソッドで生成する
- 複雑なロジックで生成できる
- 引数が短くなったりする
class User:
def __init__(self,
user_id: UserId,
first_name: FirstName,
last_name: LastName,
profile_image_path: ProfileImagePath,
age: Age,
gender: Gender):
# バリデーションを行う
# ...
# ...
self.__user_id = user_id
self.first_name = first_name
self.last_name = last_name
self.profile_image_path = profile_image_path
self.age = age
self.gender = gender
# methods
# ...
@staticmethod
def new_men(user_id: UserId, first_name: str, last_name: str, age: int):
return User(
user_id,
FirstName(first_name),
LastName(last_name),
ProfileImagePath("https://hogehoge.com/default/image.jpg"),
Age(age),
Gender.MEN
)
a_user = User.new_men(user_id, "taiyo", "tamura", 26)
「ファクトリとしてのドメインサービス」で生成する
他のシステムにリクエストしてデータを取得する場合、ドメインサービスをファクトリクラスとして利用する。
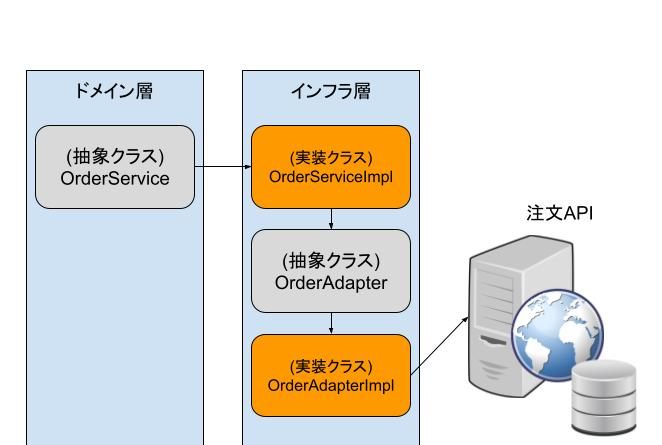
OrderService
# domain.model.order.order_serviceモジュール
import abc
class OrderService(abc.ABC):
"""注文を行うドメインサービス"""
@abc.abstractmethod
def open(self, order: Order) -> OrderStatement:
"""注文オブジェクト指定で注文し、注文明細を返すメソッド"""
pass
OrderServiceImpl
# infrastructure.service.order.order_service_implモジュール
from domain.model.order.order_service import OrderService
from infrastructure.service.order.adaptor import OrderAdaptor
class OrderServiceImpl(OrderService):
def __init__(self, order_adaptor: OrderAdaptor):
self.__order_adaptor = order_adaptor
def open(self, order: Order) -> OrderStatement
"""注文オブジェクト指定で注文し、注文明細を返すメソッド"""
try:
return self.__order_adaptor.open(order)
except Exception as e:
raise Exception("OrderServiceImplクラスのopenメソッドで例外発生しました。{}".format(e))
OrderAdaptor
# infrastructure.service.order.adaptor.order_adaptorモジュール
import abc
class OrderAdaptor(abc.ABC):
@abc.abstractmethod
def open(self, order: Order) -> OrderStatement:
pass
OrderAdaptorImpl
import requests
from domain.model.order.order_id import OrderId
from domain.model.order.order_amount import OrderAmount
from domain.model.order.order_statement import OrderStatement
class OrderAdaptorImpl(OrderAdaptor):
ORDER_API_URL = "https://other.system.api.com/order"
def open(self, order: Order) -> OrderStatement:
response = requests.post(
self.ORDER_API_URL,
data={'user_id': order.user.id, 'item_ids': order.item_ids}
)
order_id = response.content['order_id']
order_amount = response.content['total_amount']
return OrderStatement(
OrderId(order_id),
bool(is_opened),
OrderAmount(order_amount)
)
アプリケーションサービス
アプリケーションサービスとは、プレゼンテーション層とドメイン層の仲介を行うオブジェクト。
- アプリケーションサービスは、ユースケースのイベントフローごとにメソッドを提供する
- アプリケーションサービスはあくまで調整役のため、薄い処理を行うだけのレイヤーとなる
- データベースのトランザクションといったコントロールを行う場合もある
$ tree
.
├── application
│ ├── __init__.py
│ ├── command # クライアントからの受け取った「エンティティの作成/変更」「値オブジェクトの作成」に必要なデータを詰め込んだクラス
│ │ ├── __init__.py
│ │ └── create_article_command.py
│ ├── dto # プレゼンテーション層がレスポンスを返すのに必要なデータを詰め込んだクラス
│ │ ├── __init__.py
│ │ ├── article_dto.py
│ │ └── articles_dto.py
│ └── service # アプリケーションサービスを定義する
│ ├── __init__.py
│ └── article_application_service.py # 記事のCRUDなどを管理するアプリケーションサービス
...
アプリケーションサービスの実装例
class ArticleApplicationService:
"""記事の操作等を行うアプリケーションサービス"""
def __init__(self, article_repository: ArticleRepository):
self.__article_repository = article_repository
def get_articles(self, page: int, n: int) -> ArticlesDto:
articles = self.__article_repository.articles_with(page, n)
return ArticlesDto([ArticlesDto.Article(an_article.id, an_article.title) for an_article in articles])
def get_article(self, an_article_id: int) -> ArticleDto:
article_id = ArticleId.of(an_article_id)
article = self.__article_repository.article_with(article_id)
return ArticleDto(article.id, article.title, article.content)
@transactional
def create(self, create_article_command: CreateArticleCommand):
article = Article.new(
create_article_command.id,
create_article_command.title,
create_article_command.content
)
self.__article_repository.save(article)
@transactional
def delete(self, an_article_id: int):
article_id = ArticleId.of(an_article_id)
self.__article_repository.delete(article_id)
「境界づけられたコンテキスト」とは
境界づけられたコンテキスト = bounded context
A description of a boundary (typically a subsystem, or the work of a particular team) within which a particular model is defined and applicable.
特定のモデルを定義・適用する境界を明示的に示したもの
代表的な境界の例は、サブシステムやチームなど
ドメインモデルの共有
ドメイン駆動設計ではすべての人(ソフトウェア開発者、ドメインエキスパート)が同じ意味で言葉を使うことを目指す。
コンテキストマッピング
コンテキスト同士の関係性を簡単な図で表すことを、コンテキストマッピングと言う。
「境界づけられたコンテキスト」の具体的な実装方法はこちら
Python でインタフェースを定義するには
PythonでDIを行う
ビジネスロジックとは
- システムのコアの部分
- システムの目的になる処理をするところ
アプリケーションを以下の3つに分けた時、プレゼンテーションでもデータアクセスでもない部分をビジネスロジックとする
- プレゼンテーション
- ビジネスロジック
- データアクセス
データアクセス
この層の役割は、ファイルや DB に対してデータを読み書きすること。
ビジネスロジックをデータアクセスと切り離すのは、保存先が以下のそれぞれであろうとビジネスロジックはそれを気にかけないように記述。
- ファイル
- RDB
- ドキュメント DB
この層は、保存先の媒体によらず同じインタフェースをビジネスロジック層に対して提供。
保存先が変わってもデータアクセス層だけ直せばいいというのが理想的。
プレゼンテーション
この層は、そのアプリケーションとユーザ (or クライアントプログラムなど) とのやりとりを担当する。
具体的には、以下のようなものがプレゼンテーション層に属する。
-
古典的な MVC フレームワークの場合: View や Controller -
APIの場合: API を受け付ける Controller・リクエストやレスポンスの型 -
CLI アプリケーションの場合: コマンドラインオプションの解析・ユーザからの入力受付・処理結果の出力
例えば、古典的なMVC フレームワークによる Web アプリと同様の処理を API や CLI アプリケーションとして提供するとき、プレゼンテーション層以外が使い回せるような構造になっていると理想的。
その使い回すべき部分のうち、データアクセスではない部分がビジネスロジックです。
ビジネスロジック
どこまでがプレゼンテーションで、どこからがビジネスロジックなのか。
例えば、以下のようなアプリケーションを考えてみる。
- コンピュータとじゃんけんをして、その結果をどこかに保存する
「じゃんけんの勝敗判定」は、それが API だろうと CLI アプリケーションだろうと同じ。
そのため、「じゃんけんの勝敗判定」はプレゼンテーションでは無い。
「コンピュータとじゃんけんをして、その結果をどこかに保存するという処理を呼び出すという流れ」も、それが API であろうと CLI アプリケーションであろうと関係無い。
なので、「コンピュータとじゃんけんをして、その結果をどこかに保存する処理を呼び出す、一連の流れ」も、プレゼンテーションでは無い。
「じゃんけんの勝敗判定」と「コンピュータとじゃんけんをして、その結果をどこかに保存する処理を呼び出すという流れ」は、どちらもビジネスロジックに該当します。
ビジネスロジックには2つ種類がある。
- コアなルール系 : じゃんけんの勝敗判定
- 処理の流れ系 : コンピュータとじゃんけんをして、その結果をどこかに保存する処理を呼び出す、一連の流れ
ビジネスロジックでは無いものとビジネスロジックになるもの
日付時刻のフォーマット変換
DB に保存された日付時刻を UI に表示する際があるとして、フォーマットを変換することが多い。
日付時刻の形式変換は、ユーザインタフェースのためだけのロジックであるため、プレゼンテーション層に記述する。
ただし、例外もある。
例えば、日付時刻形式変換アプリを実装する場合、日付時刻形式の変換がシステムのコアとなるロジックであり、変換ロジックが Web アプリだろうと CLI アプリだろうと同じだと考えられるため、変換処理はビジネスロジックに実装する。
このように、同じロジックであっても、アプリケーションによってそれがビジネスロジックか異なる場合もある。
バリデーション
データのバリデーションについては、プレゼンテーションかビジネスロジックか意見が分かれやすい。
- リクエストのフォーマットチェック
- フォーマットより少しだけ複雑な条件チェック
- DB のデータとの整合性チェック
リクエストのフォーマットチェック
リクエスト (CLI であればコマンドライン引数や標準入力) をプレゼンテーション層で受け取った際、最初にバリデーションチェックを行う。
- リクエストの必須パラメータが足りているか
- 文字列のサイズが 1000 以下であるか
リクエストのデータの形式チェックは、プレゼンテーション層で実施する。
理由は以下になる。
- ユーザとのインタフェースでの約束事に対するチェックと考えている
- 不正な形式のデータであることは即座に検知して、以後のプログラムに進ませないようにする
- DB とのやりとりが不要なため、簡単に記述できる
フォーマットより少しだけ複雑な条件チェック
以下のような条件があったとする
- Qiita のようなサイトで、「イイね」は自分にはできないようにする
- TODO 管理アプリで、過去日の TODO は登録できないようにする
フォーマットより少しでも複雑なチェックは基本的にビジネスロジック層で実施する。
- プレゼンテーション層は見た目などの UI に直接関わることだけを知っているべき
- ユーザインタフェースが GUI か API か CLI かなどによらず共通したチェックであると想定される
上記2つの条件はコアなルールに関連することもあり得るため、ビジネスロジックとして考える。
何がビジネスロジックかを突き詰めるよりも、チームとして合意を取ったり、一貫性を取ったりすることの方が大事。
DB のデータとの整合性チェック
例えば以下のようなチェックあったとする。
- EC サイトで購入リクエストした商品が購入可能なものである
こういったチェックは必ずビジネスロジック層に記述する。
- UI に起因したチェックではないため、プレゼンテーション層の役割ではないこと
- DB とのやりとりが発生すること
このようなデータの整合性チェックこそがビジネスロジックの代表なので、それはビジネスロジック層に書くべきだと考える。
トランザクションスクリプトとドメインモデル
ビジネスロジックの実装方法には、大きく以下の2つがある。
- トランザクションスクリプト
- ドメインモデル
トランザクションスクリプト
トランザクションスクリプトパターンでは、Serviceクラスに処理を記述し、DTOをデータの入れ物としてやりとりする。
DTOとは以下の3つだけを持ち、処理は Service に記述します。
- データ
- getter
- setter
いわゆる手続き型プログラミングの考え方でビジネスロジックを実装する方式です。
メリット
ドメインモデルパターンよりも学習コストが低いこと
初期実装コストが低い
デメリット
サービスをまたがった処理の共通化がしにくいこと、サービスが Fat になりがち
ドメインモデル
トランザクションスクリプトパターンではただの入れ物だったDTOに処理も持たせ、処理とデータを一緒に配置するオブジェクト指向的な実装をする。
この場合、処理とデータを入れるものを「ドメインモデル」と呼んだりする。
メリット
- ロジックをより共通化しやすいこと
- サービスが Fat になりにくい
デメリット
- 学習コストや初期実装コストが高い
ビジネスロジックは 2 種類ある
クリーンアーキテクチャの図に書かれた言葉を使うと以下の2つになる
- エンタープライズビジネスルール
- アプリケーションビジネスルール
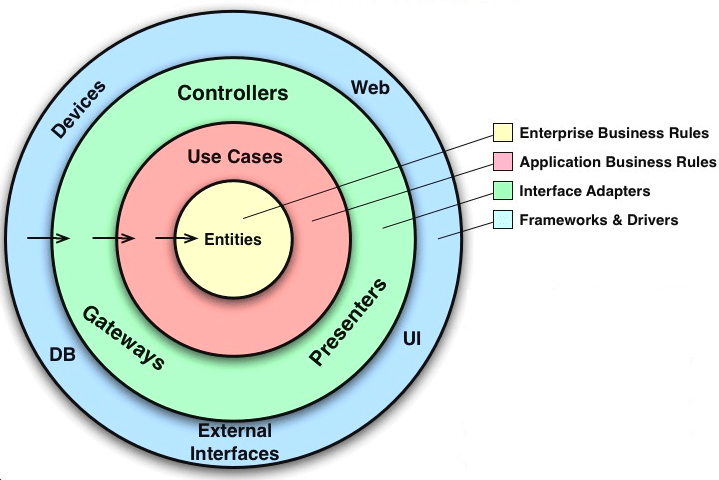
上記でビジネスロジックにはコアなルール系と処理の流れ系の2つがある。
- エンタープライズビジネスルール=コアなルール系
- アプリケーションビジネスルール=処理の流れ系
エンタープライズビジネスルール
システム都合ではない、コアなルールのこと。
例えば、じゃんけんの勝ち負け判定ロジックはシステムであっても現実であっても同じなので、「エンタープライズビジネスルール」に該当する。
業務システムであれば、システムの代わりに帳票などを使って業務を回す際にも登場するルールが「エンタープライズビジネスルール」 です。
アプリケーションビジネスルール
システムを成立させるためのロジックや、システムであることによって発生したロジック。
以下2つが該当。
- ユースケースの処理の流れを実現すること
- トランザクション管理
例えば、「コンピュータとじゃんけんをして、その結果をどこかに保存する処理を呼び出す、一連の流れ」がそれにあたる。
EC サイトで購入リクエストした商品が購入可能なものである
上記を例にする。
- DB などから関係するデータを取り出す処理を呼び出す
-
エンタープライズビジネスルールを呼び出して整合性をチェックする -
整合性チェックに合格した場合、データを保存する処理を呼び出す (商品購入の確定など)
といった流れを実現するのがアプリケーションビジネスルール。
サービスも 2 種類ある
ビジネスロジックが 2 種類あると書いたが、ドメインモデルパターンにおいては、サービスも 2 種類あル。
- アプリケーションサービス
- ドメインサービス
ドメインモデルパターンでは、エンタープライズビジネスルールをドメインモデルに記述して、アプリケーションビジネスルールを 「アプリケーションサービス」クラスや「ユースケース」クラスに記述 する。
「ドメインモデル」には Entity、Value Object など、DDD の戦術的設計で登場する様々な要素が含まれる。
ドメインサービスというのもドメインモデルの要素の 1 つで、Entity や Value Object に記述することがどうしても適切でないエンタープライズビジネスルールを記述するところになる。
ドメインモデルパターンにおいては、ドメインサービスは最後の手段であり、可能な限り使用は控えるべきもの。
一方、「アプリケーションサービス」というのは、処理の流れなど (= アプリケーションビジネスルール) を実現するためのもの。
DDD の戦術的設計では「アプリケーションサービス」と呼ばれ、クリーンアーキテクチャでは「ユースケース」と呼ばれている。
まとめてあってわかりやすい記事
特にビジネスロジックとは何か?という点がわかりやすい。
Entityをdataclassで実現する
冒頭の方のこちらに例を貼った。
こちらの記事も参考になる
CleanArchitecture (クリーンアーキテクチャ)について
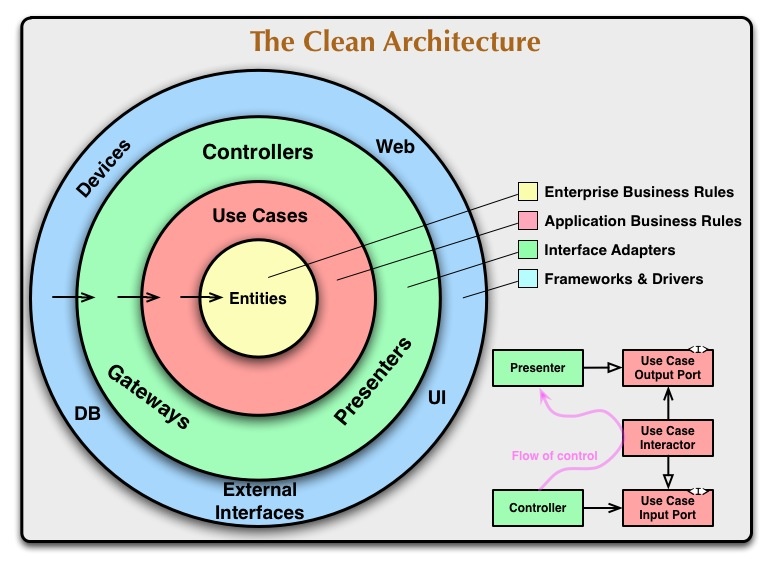
Robert C. Martin(Uncle Bob)が2012年に提唱した、DBやフレークワークからの独立性を確保するためのアーキテクチャであり、DDDを実現する方法のアーキテクチャの一つも言えます。
記事によれば一言で言うと、関心の分離という目的を達成するためのものです。
以下の翻訳記事が元となっています。
クリーンアーキテクチャを実現することで、以下のようなシステムを生み出す。
- フレームワーク独立 : アーキテクチャは、機能満載のソフトウェアのライブラリが手に入ることには依存しない。これは、そういったフレームワークを道具として使うことを可能にし、システムをフレームワークの限定された制約に押し込めなければならないようなことにはさせない。
- テスト可能 : ビジネスルールは、
UI、データベース、ウェブサーバー、その他外部の要素が無しでもテストできる。 - UI独立 : UIは、容易に変更できる。システムの残りの部分を変更する必要はない。たとえば、ウェブUIは、ビジネスルールの変更なしに、コンソールUIと置き換えられる。
- データベース独立 : `OracleあるいはSQL Serverを、Mongo, BigTable, CoucheDBあるいは他のものと交換することができる。ビジネスルールは、データベースに拘束されない。
- 外部機能独立 : 実際のところ、ビジネスルールは、単に外側についてなにも知らない。
SOLID原則
ソフトウェアの拡張性、保守性等を担保し、メンテナンスしにくいプログラムになることを防ぐための原則。
- S:SRP、単一責任の原則
- O:OCP、解放閉鎖の原則
- L:LSP、リスコフの置換原則
- I:ISP、インタフェース分離の原則
- D:DIP、依存性逆転の原則
S (Single Responsibility) 単一責任の原則
クラスは、単一の責任を持つべき
クラスに多くの責任があると、バグが発生する可能性が高くなる。
なぜなら、その責任の1つに変更を加えると、知らないうちに他の責任に影響を与える可能性があるため。
目的
変更の結果としてバグが発生しても、他の無関係な動作に影響を与えないように、動作を分離することを目的としている。
O (Open-Closed) オープン・クローズドの原則
クラスは、拡張にはオープンで、変更にはクローズドであるべき
クラスの現在の動作を変更すると、そのクラスを使用するすべてのシステムに影響を与える。
クラスでより多くの関数を実行したい時、理想的な方法は、既存の関数に追加することであり、変更しないこと。
目的
クラスの既存の動作を変更することなく、クラスの動作を拡張することを目的としている。これは、そのクラスが使用されている場所でバグが発生するのを避けるため。
L (Liskov Substitution) リスコフの置換原則
SがTのサブタイプである場合、プログラム内のT型のオブジェクトをS型のオブジェクトに置き換えても、そのプログラムの特性は何も変わらない
子クラスが親クラスと同じ動作を実行できない場合、バグになる可能性がある。
クラスから別のクラスを作ると、クラスが親になり、新しいクラスが子になる。
子クラスは、親クラスができることをすべてできる必要がある。このプロセスを継承と呼ぶ。
子クラスは、親クラスと同じリクエストを処理し、同じ結果か、同様の結果を提供できなければならない。
このイラストでは、親クラスがコーヒーを提供しています(コーヒーの種類は問わない)。
子クラスがカプチーノを提供することは、カプチーノがコーヒーの一種なので許容されるが、水を提供することは許容されない。
子クラスがこれらの要件を満たさない場合、子クラスが大きく変更され、この原則に違反することになる。
目的
親クラスやその子クラスがエラーなしで同じ方法で使用できるように、一貫性を保つことを目的としている。
I (Interface Segregation) インターフェイス分離の原則
クライアントが使用しないメソッドへの依存を、強制すべきではない
クラスに使用しない動作を実行させようとするのは、無駄が多く、クラスにその動作を実行する機能がない場合、予期しないバグが発生する可能性がある。
クラスは、その役割を果たすために必要な動作のみを実行する必要がある。
それ以外の動作は完全に削除するか、将来的に他のクラスで使用する可能性がある場合は別の場所に移動すべき。
目的
動作のセットをより小さく分割して、クラスが必要なもののみを実行することを目的としています。
D (Dependency Inversion Principle) 依存性逆転の原則
・上位モジュールは、下位モジュールに依存してはならない。どちらも抽象化に依存すべき
・抽象化は詳細に依存してはならない。詳細が抽象化に依存すべき
- 上位モジュール(またはクラス): ツールを使って動作を実行するクラス
- 下位モジュール(またはクラス): 動作を実行するために必要なツール
- 抽象化:2つのクラスをつなぐインターフェイス
- 詳細:ツールの動作方法
クラスは動作を実行するために使用するツールと融合すべきではない。
むしろ、ツールがクラスに接続できるようにするインターフェイスと融合すべき。
また、クラスもインターフェイスも、ツールの動作方法を知るべきではない。
ただし、ツールはインターフェイスの仕様を満たす必要があります。
目的
インターフェイスを導入することにより、上位レベルのクラスが下位レベルのクラスに依存するのを減らすことを目的としている。
クリーンアーキテクチャをSOLID原則の観点で見ていく
Frameworks & Drivers(Data Access)
Clean ArchitectureのInterface Adaptersの必要性をレイヤードアーキテクチャの欠点から見ていく。
依存性逆転の原則 (DIP: Dependency Inversion Principle) - (SOLID原則) - 1
上記のようなレイヤードアーキテクチャは処理の流れに沿ってモジュール間が依存している。
直感的に非常に分かりやすいアーキテクチャではあるが、デメリットもある。
それは、Domain層が、Infrastructure層に依存している。
この依存方向により、Infrastructure層を変更すると、Domain層が影響を受ける。
注意点として、依存していることが問題ではなく、依存している方向が問題である。
システムを構築する上でモジュール間の依存は避けては通れないため、依存関係が発生することのそれ自体は何ら悪ではない。
何度も言うように問題になるのは、依存関係の方向ということになる。
レイヤードアーキテクチャに目を向けると、Domain層はビジネス的価値を記述し、Infrastracture層は技術的詳細を記載する。
一般的に詳細を記述しているInfrastracture層の方が変更可能性が高くなる。
安定しているDomain層が、安定していないInfrastracture層に依存するという依存関係の方向が下記の原則に違反している。
安定依存の原則(SDP:The Stable Dependencies Principle)
この原則はモジュール間の依存関係は安定している方向に向いてなければならないという考え方であるSDPと似ています。
この考え方に基けば、レイヤード・アーキテクチャでは、抽象度の高い安定したDomain層が、技術的な詳細である安定していないInfrastructureに依存している状態はこの原則に反している。
この依存関係を解決する考え方として依存性逆転の原則 (DIP) - (SOLID原則)がある。
依存性逆転の原則(DIP)に従うとDomain層とInfrastructure層の関係は下記のようになる。
Domain層は抽象であるInterfaceに依存し、
技術的な詳細であるInfrastructure層もまた抽象であるInterfaceに依存することで依存関係の方向を逆転させる。
こちらが参考になる。
Interfaceの名前は、Domainロジックに必要なデータにアクセスするためのInterfaceであるためData Access Interfaceとする。
Interface Adapters (Repository)
依存性逆転の原則 (DIP: Dependency Inversion Principle) - (SOLID原則) - 2
Interfaceを設けたことで抽象に依存できるようになった。
しかし、一つ問題があり、実装を考えると結局Domain層が、Data Access Interfaceを呼び出すときにInfrastructureをインスタンス化する必要がある。
data_access_interface: Interface = Infrastructure()
data_access_interface.getData()
そこでDomain層からInfrastructureのインスタンスを隠蔽するため、Infrastructureをインスタンス化するData Accessを配置することでこの問題を解決する。
data_access_interface: Interface = DataAccess()
data_access_interface.getData()
Data Accessが Infrastructureを抽象化する。
class DataAccess:
def __init__(self):
pass
def get_data(self):
Infrastructure = Infrastructure()
Infrastructure.getDataFromInfra()
このような構成にすることにより、Domain層に対してデータの実装を抽象化する。
そして、このようなデータアクセス手段、データの永続化を抽象化するオブジェクトをRepositoryと呼ぶ。
デザインパターンとしては、DAOパターンと似ている。
Frameworks & Drivers(Controller)
解放閉鎖の原則 (OCP:Open/Closed Principle) - (SOLID)
次に視点を変えてUI(Presentation)とApplicationの依存関係に目を向けてみる。
一般的に、UIはユーザーの目に最も触れるため比較的変更が多く発生する。
この時UI(Presentation)は、Applicationに依存しているため、UI(Presentation)のソースコードを変更した場合は、静的型付け言語の場合はApplicationのソースコードも含めてコンパイルする必要がある。
UI(Presentation)の修正に伴ってApplicationを含めたテストも必要となるかもしれない。
また、UI(Presentation)が、Applicationの実装を知りすぎてしまうことも問題となる可能性がある。
優先すべきはUI(Presentation)の修正をApplicationに影響させないことだが、Applicationの変更からUI(Presentation)を保護しておきたいのも事実である。
こうした事態を解決する考え方として解放閉鎖の原則 (OCP:Open/Closed Principle) - (SOLID)の考え方がある。
この考え方に基づいて、変更の多いUI(Presentation)からApplicationを閉じるため、Application Interfaceを設ける。
また、依存性逆転の原則 (DIP: Dependency Inversion Principle) - 2におけるData Accessと同じようにUI(Presentation)にインスタンスを隠蔽するためControllerを配置する。
このような構成にすることにより、UI(Presentation)と、Application間の依存関係の方向を制御して、モジュール間の影響を小さくする。
Enterprise Business Rules & Application Business Rules(Usecase & Entity)
単一責任の原則 (SRP:Single Responsibility Principle) - (SOLID原則)
今度は依存関係ではなく、各モジュールの責務に目を向けてみる。
Infrastructureは、最も技術的な詳細を知っており、その詳細な制御によってデータを提供する。
データベースであれば、データベースの制御方法を知っているのがこのモジュールになる。
Data Accessは、Domain層からInfrastructure層を抽象化するため、InfrastructureとDomainを仲介している。
Domain層は、Application層から要求を受けた後、要求に応じてデータを取得してからビジネスロジックを実行する。
この時、Domain層のコードが変更される契機について考える。
主に2つある。
- ビジネスルールに変更があった場合
- 取得するデータに変更があった場合
このようにDomainは、上記のような2つの変更理由によって修正が加えられる。
この問題として、一方の修正によってもう一方のコードに予期せぬ影響を及ぼすかもしれない。
こうした問題への考え方として単一責任の原則 (SRP:Single Responsibility Principle) - (SOLID原則)がある。
この考え方によると一つのモジュールは二つ以上の変更理由で変更されてはいけない。
言い換えれば、二つ以上の変更理由を持つモジュールは一つになるよう分割すべきということになる。
この考えに基づいて、Domainを分割する。
ビジネスルールを提供するモジュールをEntitiesとして、Data Access Interfaceを介してデータを取得するモジュールをUseCase Interactorとする。
そして分割するモジュールの依存関係は、先ほどの安定依存の原則(SDP:The Stable Dependencies Principle)に基づいて、UseCase Interactorを、抽象度が高く安定しているEntitiesに依存する形にします。
Interface Adapters(Presenter)
単一責任の原則 (SRP:Single Responsibility Principle) - (SOLID原則)
先ほどからUI(Presentation)と記載しているモジュールがある。
Viewを表示する責務を担うモジュールと、Controllerから受け取ったデータを解釈しViewに引き渡すモジュールが混在しているため括弧書きになっていると言える。
単一責任の原則 (SRP:Single Responsibility Principle) - (SOLID原則)と同じ考え方に基づき分割する。
このPresenterは、Controllerから受け取ったApplicationからのデータを解釈し、Viewに引き渡すことが責務となります。
インターフェース分離の原則(ISP:Interface Segregation Principle) - (SOLID原則)
次にControllerに目を向ける。
Controllerの責務はViewの状態を受け取ってApplication Interfaceを介して、Applicationが要求するデータ形式でデータを引き渡すことです。
しかし、先ほどの変更によってViewにデータを引き渡すPresenterは、Controllerを介してApplicationのデータを受け取る。
この依存関係において一つの問題が生じる。Controllerに本来責務でない実装が入ってしまうことになる。
Application InterfaceのリターンをPresentationに渡す実装が必要となる。
また、View起点でなくInfrastructure起点のデータをViewに表示する場合においては、Controllerは単にPresentationにデータを引き渡すためだけにApplication Interfaceを呼び出さなければならない。
こうした問題を解決する考え方にインターフェース分離の原則(ISP:Interface Segregation Principle) - (SOLID原則)がある。
この考え方に基づき、Controllerが使用しないInterfaceを呼び出す実装が必要ないようにInterfaceを分割する。
Controllerも責務に沿ったInterfaceのみを呼び出せるようにInput Boundaryが配置された。
Presenterも責務に沿ったInterfaceのみを実装できるようにOutput Boundaryが配置された。
ここでOutput Boundaryを実現しているモジュールがPresenterである点に注意が必要となる。
ここでも安定依存の原則(SDP:The Stable Dependencies Principle)が基づいて依存関係が調整される。
上記の図ですが、下記の図にかなり近づいてきていることがわかるはずです。
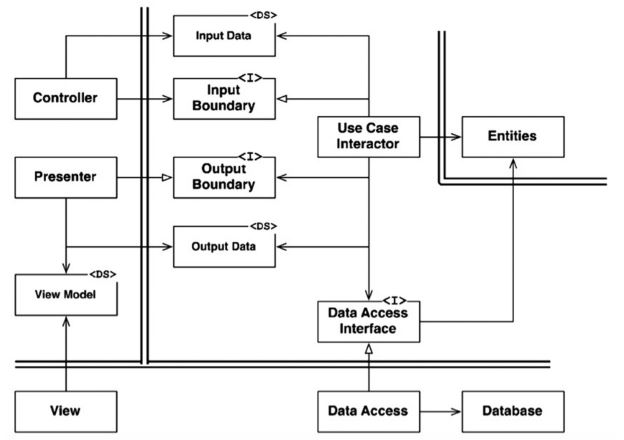
ほとんどの構成が同じです。
クリーンアーキテクチャの図と異なる点は、以下の2つです。
- Applicationモジュールが存在する
- DSと記載されたData Structureが存在しない
Applicationモジュールが存在する事に関しては、UseCase InteractosとApplicationのどちらもアプリケーションルールの記述が責務ですので一つのモジュールにまとめることも可能になる。
次にデータ構造に関しては図が煩雑になるため割愛しているのみで、明示的に書けば同じとなる。
このデータ構造が示す意味は、依存する側は依存されている側が定義しているデータ構造に合わせて Interfaceを呼び出す必要があると強調していると理解できる。
仮、`ControllerがUseCase側のデータ構造でなく、Controller側で定義したデータ構造をUseCase側で解釈しなければならないのであれば、UseCaseは推移的にControllerに依存しているといえる。
以下資料をもとに自分なりに模写のようにまとめましたが、全てを真似る必要はないはずです。
コントローラーからアプリケーションサービスを呼び出す層も、オブジェクトを渡すのではなく、通常の引数で渡すことが可能であれば、依存関係にはならないはずです。
どこまでやるかはチームの規模や状況次第によります。
最低限はアプリケーション層辺りまでは作って、そこにロジックを書いていくことかと思います。
参考資料
人によって微妙に解釈が異なる場合もある
クリーンアーキテクチャはその難しさから人によって微妙に解釈が違います。そんな疑問点を複数の原著などから、共通部分を抜き出してまとめてくれた方がいます。
安定依存の原則(SDP:Stable Dependencies Principle)など他のことについてもこちらに詳しく書いてある
途中からクリーンアーキテクチャを導入する場合
既に負債だらけだったり、MVCで作り込んだアプリケーションを途中からクリーンアーキテクチャにする場合はどうするべきか?
モノタロウさんが良い前例を書いてくれています。
結論を言うと、 「いったんすべての処理をユースケース層に置いてしまうこと」 だそうです。
そこから徐々に、それぞれの処理を適切な層へと移していくとのこと。
──どのような手順で、幹を設計していくのでしょうか?
芝本 設計を始めた段階では、いったんすべての処理をユースケース層に置いてしまいます。
その後、チーム内で議論し合いながら、それぞれの処理を適切な層へと移していくわけです。例えば、APIの呼び出しが発生するのならば、その処理をリポジトリ層に移譲します。
他にも幹と呼ばれる、プロダクトの心臓的な場所から着手するのが良いとのこと。
芝本 機能のなかでも“幹”といえる処理の設計から着手していきました。
──“幹”とはどういうことでしょうか?
芝本 検索ページのなかには、キーワード検索はもちろん、商品カテゴリによる検索など多種多様な検索ページが存在します。そのうち、検索ページの根幹といえるのはキーワード検索です。この機能を“幹”と呼び、他の機能を“枝”と呼んでいました。前者の機能を、まずはクリーンアーキテクチャ化していくと決めました。
以下は、自分が大変同意見だと感じたところです。
最初は「ビジネスロジックを置くところ」ぐらいのノリでユースケース層ぐらいは置いてもよいかもしれませんが、リポジトリ層だのプレゼンテーション層だのDIPなどは考える必要ないかなと思います。
「クリーンアーキテクチャの設計において理想を追い求めすぎると、いくら時間があっても足りなくなってしまいます。」というところも自分も経験しました。「本当はこうなんじゃないか?こっちが正しいんじゃないか?」なんてやるのは、開発作業が本当に進まないですし、スタートアップ的な組織だったら尚更致命的かと思っています。現実の落とし所というのは本当に大事です。
──「クリーンアーキテクチャを導入したい」と考えている読者の方々に、アドバイスはありますか?
芝本 クリーンアーキテクチャは層の種類が多い、いわば“重たい”設計でもあります。そのため、立ち上がったばかりのアプリケーションにクリーンアーキテクチャを用いるのは時期尚早です。ある程度の規模まで成長してから、クリーンアーキテクチャへの移行を検討してほしいです。
それから、アプリケーションの規模が大きいということは、移行プロジェクトも長期にわたるものになります。「クリーンアーキテクチャ化後に、どのようなテストをして品質を保証するか」「リリースをどのような手順で行うか」などの方針を予め決めておく方がいいです。
もうひとつ、クリーンアーキテクチャの設計において理想を追い求めすぎると、いくら時間があっても足りなくなってしまいます。できる限り、現実的な落としどころを模索してください。「直したい」と思う部分は、後でリファクタリングすればいいですから。
Pythonで適してそうなクリーンアーキテクチャの構成図?
$ tree
- src
- domain
- <damain a>
- <damain a>_entity.py
- i_<domain a>_repository.py
- apllication
- <domain a>
- <function a>
- <function a>_<domain a>_inputdata.py
- i_<function a>_<domain a>_usecase.py
- <function a>_<domain a>_interactor.py
- adapter
- <domain a>
- controller
- <domain a>_controller.py
- gateway
- <domain a>_<DB名など>.py
- infrastractor
- <db>
- i_<db>_handler.py
- <postgresなど>
- <postgresなど>_handler.py
ドメイン層
- model : ドメインモデル。ビジネスロジックをここに書く
- repository : ドメインオブジェクトを取得・保存するインタフェース
- service : ドメインオブジェクトに責務を持たせるものではないケース or 複数のドメインモデルを操作する時に使うシナリオ
model - ドメインモデル
エンティティと値オブジェクトを置く場所とも考えられる。
適切な責務であるか、を見分けるには?
これを見分けるテストの1つに
{{ドメインモデル}}さん、xxxしてくれませんか?
と問いかけてみる。
- 文脈がおかしい
- このドメインモデルには適切じゃないため、別のドメインモデルが必要と考える。
- xxxが複数である
- 関数は複数に分ける必要がある
上記当てはまるものをできるだけなくすように直していく。
ただのフィールドか値オブジェクトかエンティティか
モデリングする際に
- ただのフィールドにするか
- 値オブジェクトにするか
- エンティティにするか
これらで悩むことがあります。悩んだら以下のように判断するらしい。
-
ドメインルール、振る舞いを持たない要素であればただのフィールドのままにする -
不変(変更するには交換 = 新しいオブジェクトを生成する)であり、属性が同じであれば同一とみなすのであれば値オブジェクト(ValueObject) -
ライフスパンを持ち、可変であり、属性が同じでも同一とみなさない(=識別子が必要) 場合はエンティティ(Entity)
ドメインモデルは成長し続ける
ドメインモデルの責務であるかの判断は時に難しく、悩むこともある。
その場合は 一旦その時点での判断に任せる。
時間をおいてリファクタしてみたり、新しい仕様によって改善されることは多々あるので、その時に修正すれば良い。
フィールドはできる限りprivateにする
クリーンアーキテクチャはドメイン層のデータの整合性を保つことが重要。
そのため、他の層で意図しないドメインオブジェクトの破壊が起きないように、不用意にアクセス出来ないようにしなければいけない。
ドメインモデルとデータモデルは違う
注意としてドメインモデルとDBのデータモデル(テーブル設計)は一緒になることもあるが、一緒ではないです。
ドメインモデルでは、「年齢」が業務の関心事であれば、年齢クラスを作ります。年齢クラスは内部的に生年月日をインスタンス変数に持ち、そのインスタンス変数を使って年齢を計算するロジックをメソッドとして持ちます。年齢を知りたいという関心事があり、それを計算するロジックの置き場所が必要だから年齢クラスを作る、というアプローチです。
一方、データモデルでは、年齢は記録すべきデータではありません。計算の結果です。テーブルには計算のもとになる生年月日だけを記録します。
ref: 現場で役立つシステム設計の原則 〜変更を楽で安全にするオブジェクト指向の実践技法
このようにドメインモデルは業務ロジックに注目し、それをクラスという単位で設計する。
データの整理を目的とするデータモデルとは本質的に異なる。
またデータモデルはドメインモデルが大きく変更された場合に、同じように変更しようとするとスキーマの変更やらデータ埋めといったマイグレーション作業が大変になる。
なのでドメインモデルとデータモデルは別なものと考え、無理にデータ側をドメインモデルに合わせず後方互換性を保たせるような運用をすると良い。
repository - リポジトリ
ドメイン層にあるリポジトリはドメインモデルを入出力するためのインタフェースです。
なのでロジックは介在せず、インタフェース定義のみ存在する。
例えば以下は課金マイクロサービスで使用しているカード履歴のリポジトリです。
from abc import ABCMeta, abstractmethod
from model import CardHistory
class InterfaceCardHistory(metaclass=ABCMeta):
""" """
@abstractmethod
def find(self, fingerprint: str) -> CardHistory:
raise NotImplementedError
@abstractmethod
def find(self, history: CardHistory) -> None:
raise NotImplementedError
入出力が基本なのでこのように取得と保存・更新処理が大半になる。
依存するもの
repositoryが依存するのはmodelのみです。
それ以外依存するものはありません。
また逆にmodelがrepositoryに依存することはありません。
service - サービス
サービスは以下の用途で利用する。
-
ドメインオブジェクトに 責務を持たせるものではない ケース - データ整合性を保つために
複数のドメインモデルを操作するケース
前提としてサービスはステートレスである必要がある。
ドメインオブジェクトに責務を持たせるものではないケース
例えば永続化処理を行う層にあるデータを利用して判定を入れたいケースがあるとする。
同じEmailアドレスを登録できないようにする処理はよくあるが、これはリポジトリを経由する必要があるのでUser modelにロジックを持たせるのではなくサービスで処理するのが適切になる。
データ整合性を保つために複数のドメインモデルを操作するケース
単一のアトミックな操作で複数のドメインモデルを扱うことは往々にしてある。
先に述べたようにドメイン層ではデータの整合性を保つことが非常に重要であるため、それが崩れない範囲でのトランザクション処理が必要になってくる。
それを担保する粒度としてドメインサービスが使える。
サブスクリプションの購読をする場合のケースを考える。
- レシートの保存
- ユーザの購読ステータスの更新
上記2つはトランザクション処理としてまとまっている必要がある。
しかし、下記2つのモデルは別々です。
- レシート
- 購読ステータス
そういった複数のドメインモデルを扱う時にドメインサービスが適切です。
serviceだらけにしないこと
前述の複数のドメインモデルを扱ったりする際に、データ整合性を気にしなくてもいいケースでもserviceを用意したり、1ドメインオブジェクトを取得するだけでもserviceを挟んだりしがちです。
このようなケースはユースケース層の責務であるので、わざわざserviceを挟む必要はないです。
依存するもの
serviceが依存するのはrepository(Interface)とmodelだけです。
それ以外依存するものはありません。
インタフェースとして定義しておく
上位レイヤが利用する時に依存が疎になるよう、インタフェースとして定義しておく。
もちろん実装したstructも用意します。
from abc import ABCMeta, abstractmethod
class InterfaceCard(metaclass=ABCMeta):
""" """
@abstractmethod
def add(self, user_id: str, token: str) -> None:
raise NotImplementedError
@abstractmethod
def delete(self, user_id: str, card_id: str) -> None:
raise NotImplementedError
class CardService:
"""CardService"""
_repo: CardRepository
def __init__(self, repo: InterfaceCard) -> None:
self._repo = repo
def new_card_service(repo: InterfaceCard) -> CardService:
return CardService(repo=repo)
ドメイン層はドメインロジックを実装したものであり、適切に設計されていればそのコードを読めばおおよその仕様を把握できるとのこと。
そのため、分かりやすくするようにドメイン層ではコメントを厚めにした方が良いとのこと。
ユースケース層
ユースケース層ではユースケースに応じた関数を用意する。
ここでいうユースケースというのは特にアクターが異なるケースを想定している。
- ユーザ
- 管理者
- バッチ処理
これらよってユースケースは大きく異なる。
- ユーザであれば自身の
データを作成・更新したりする事ができる -
管理者であればユーザが取得・更新できないような操作が可能になる - バッチ処理では上記 のアクターが使わないような大量データを操作することを可能にする
それぞれのアクターによってユースケース異なるので、ユースケース層で関数を用意する。
他の具体例としては「データを更新して、更新を反映した上でユーザステータスをレスポンスに返してほしい」というユースケースの時に、ドメイン層で以下のように分かれているのをユースケース層でまとめて1つの関数としたりする。
- データを更新する
- ユーザステータスを取得する
このようにユースケースに沿った関数を用意する。
依存するもの
usecaseが依存するのはservice(InterFace)とrepository(InterFace)とmodelです。
ユースケースを満たすために複数のドメインモデルを扱うこと(serviceと違ってデータ整合性を意識しなくてよいケース)も当然ある。
データ変換はすべきか
開発者によってはmodelはusecaseより上の層(クリーンアーキテクチャの図で言う緑色の部分)に対して隠蔽すべき、としてusecase層で変換することもあるが、IDDD本ではどちらもメリット・デメリットあるので適宜判断してという感じです。
ドメインモデルを公開するメリット
- DTOの詰め替えによるメモリ仕様・GCが起きない
- コード量も増えない
ドメインモデルを公開しないメリット
- 依存が疎になる(ドメインモデルの変更の影響が減る)
インタフェースとして定義しておく
上位レイヤが利用する時に依存が疎になるよう、インタフェースとして定義しておく
インタフェース層
役割
インタフェース層は外部の技術要素をまとめたもの。
ここで言う技術要素というのは以下です。
- DB操作
- 外部APIコール
- APIとしての口
依存するもの
依存するのはusecase(InterFace)、repository(InterFace)、modelあたりです。
DB操作/外部APIコール
repository(InterFace)を実装する形になる。
内部ではドメインモデルをDBのデータモデルに変換して保存している。
逆に取得ではDBのデータモデルをドメインモデルに変換する処理がある。
先に述べたようにドメインモデルとデータモデルは似ているが異なるものなので、正規化などの場合によっては複数のデータモデルに分かれたりすることもあり、逆に複数のドメインモデルを1つのデータモデルとして管理することもある。
APIとしての口
usecaseを使ってhandlerを用意する。
長くなったので以下が続き