RDBの仕組み (Postgresqlの内部構造)

MySQLのアーキテクチャ
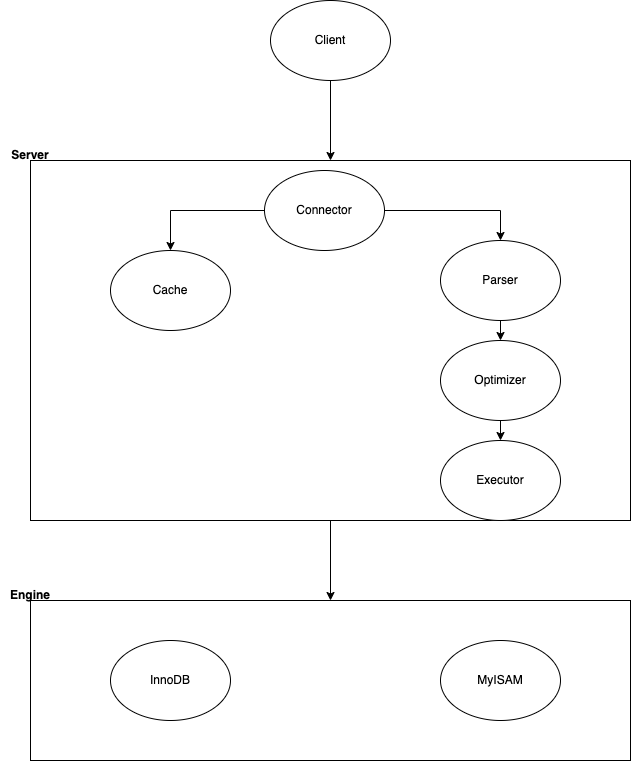
MySQLのアーキテクチャは大きく2つに別れます。
-
接続からSQL実行までの共通部分=> サーバー -
トランザクション管理やデータ永続化、インデックス管理などストレージエンジン固有部分=> ストレージエンジン
ここでは、サーバーとストレージエンジンと呼ぶことにする。
サーバーは接続の受付、ユーザ認証や権限管理、SQL文の構文解析と最適化が含まれている。
- 接続の受付
- ユーザ認証
- 権限管理
- SQL文の構文解析と最適化
ストレージエンジンの役割は大きく分けてトランザクション管理、データフォーマットの定義とデータ永続化、インデックス管理、ロックと排他制御がある。
- トランザクション管理
- データフォーマットの定義
- データ永続化
- インデックス管理
- ロック
- 排他制御
他にもストレージエンジンには固有の機能があり、MySQLなどで使われているInnoDBには全文検索機能や自動クラッシュリカバリ機能などがある。
サーバー部分の詳細
多くのコア機能と組み込み関数がこの層で実装されている。
Connector
クライアントとMySQLの接続コネクションを管理する。
$ mysql> show processlist;
MySQL [production_recustomer_auth_db]> show processlist;
+------+-------+-----------+------+---------+------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+------+-------+-----------+------+---------+------+----------+------------------+
| 3572 | admin | localhost | NULL | Query | 0 | starting | show processlist |
| 3575 | admin | localhost | NULL | Sleep | 121 | NULL | NULL |
+------+-------+-----------+------+---------+------+----------+------------------+
2 rows in set (0.01 sec)
Parser
SQLの字句解析と構文解析を行う。
-
字句解析: 文字の並びを解析し、言語的に意味のある最小の単位(トークン)に分解する処理 -
構文解析: 構文規則に基づいて、字句解析されたトークン同士の関係性を解析する処理
MySQLでは、ここで文法上の問題発見とアクセス先のテーブルの存在確認も行う。
Optimizer
実行に最適なクエリ計画を行う。
アクセス経路、インデックスの有無などのパラメーターから、最もコストの低いクエリを計画する。
実行したいSQLの前にexplainを付けると、クエリ計画を確認できる。
$ mysql>select * from user where id = 1;
$ mysql> explain select * from user where id = 1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | user | NULL | const | PRIMARY,id | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
- partitions :
分割されたテーブルのうち、どれを検索対象にするか。 - possible_keys :
MySQL がこのテーブル内の行の検索に使用するために選択できるインデックス。 - key :
MySQL が実際に使用することを決定したキー (インデックス)。 - rows :
MySQL がクエリーを実行するために調査する必要があると考える行数。
Executor
エンジン(ストレージエンジン)のインタフェースを利用して、コマンドを実行する。
ログシステム
SQL実行時の重要なログとして、以下の2種類が存在します。
- bin log
- redo log
bin logはサーバー、redo logはエンジン(InnoDBエンジン)がデータベース更新時に出力するログです。
binlog
サーバーが出力するログであり、ログ内容としてはデータの変更内容を記録しており、ログは可変的。
レコードの更新内容 or SQL文を保持する。
謝って削除したデータを復元する際に利用する。
バックアップが存在する場合は、バックアップ ~ 指定時点のbinlogを適用することで、指定時点のデータを復元することができる。(DBデータの復元)
マスタスレーブ構成など2つ以上のデータベースが存在する場合は、マスタからスレーブにbinlogを転送することでデータの同期を行う。(レプリケーション)
redo log
エンジンが出力するログ。
ディスクI/Oコストを削減するために設計されたログ。
メモリ上でレコードを更新し、redo log bufferに記録する。
その後、システムが空いている時にディスクに反映させる。
redo logのサイズは固定されており、サイズが足りなくなったらディスクに反映した上でログを上書きする。
DB自体に異常があった場合、メモリ上にあるredo logを使用することでデータの復旧を行うことができる。
MySQLの実行プロセス
- 更新対象レコードを取得
- レコードが
メモリ上に存在しない場合はディスクから取得する - メモリ上でレコードを更新
-
redo logを出力して、ステータスはprepared -
binlogを出力 -
redo logのステータスをcommitに変更する。
クラッシュによってMySQLが再起動した場合は、まずredo logを確認する。
もしredo logのステータスがcommitであれば、redo logに記述された更新内容をコミットする。
もしredo logのステータスがpreparedであれば、binlogの状態を確認する。
該当のbinlogが出力されていない場合は、redo logの更新内容をロールバックする。
binlogが出力されている場合は、redo logの変更内容をコミットする。
トランザクション分離レベルについて
ダーティーリード
あるトランザクションがコミットされていない未確定の変更情報の状態でも、別のトランザクションから変更内容を読み込めてしまう問題が発生する現象のこと。
ノンリピータブルリード - 反復不能読み取り
あるテーブルに対して読み取り(SELECT)をした後に、別の人がそのテーブルに対して更新(UPDATE)によってデータを書き換えてしまうことで、次に読み取りした際に検索結果が異なってしまう問題が発生する現象のこと。
DBは複数の人が利用するので誰かがデータを読んだ後にデータが更新されることは当たり前ではあるものの、それによって不都合が起こる時がある。
ファントムリード
先ほどのノンリピータブルリードに似ている。
最初のテーブル読み取り(SELECT)の後から2回目の読み取り(SELECT)の間に、別の人が行の追加(INSERT)を行うと、2回のSELECTで結果の行数が変わってしまうという問題が発生する現象のことです。
1回目の検索結果の行数を使った処理を行う時に、2回目の検索結果の行数が違うことで問題となってしまうことがある。
トランザクション分離レベル
上記3つの現象のどれが起きるかはトランザクション分離レベルによって決まる。
-
READ UNCOMMITED: コミットされていない変更を他のトランザクションから参照できる設定。 -
READ COMMITED: コミットされた変更を他のトランザクションから参照できる設定。 -
REPEATABLE READ: 同じトランザクション内の一貫性読み取りはすべて、最初の読み取りによって確立されたスナップショットを読み取る。 -
SERIALIZABLE: 一つ一つトランザクションを順番で実行する設定。
| 分離レベル | ダーティリード | ノンリピータブルリード | ファントムリード |
|---|---|---|---|
| READ-UNCOMMITTED | ○ | ○ | ○ |
| READ-COMMITED | - | ○ | ○ |
| REPEATABLE-READ | - | - | ○ |
| SERIALIZABLE | - | - | - |
上記は「ロック」という仕組みを使う。
ロックをかけるとその行は他の人のトランザクションからは読み書きができないようになります。
これによりデータの一貫性が保たれます。
トランザクションの分離によって、データの不整合が発生する問題を解決することができますが、もちろんこれにはデメリットもある。
ロックをかけると、`その間は他のデータ処理が止まる`ので、データベースの動作が全体的に重くなってしまう。
一つ一つのロックは数ミリ秒ではあるものの、これが沢山発生すると大きな動作遅延に繋がってしまう。
MVCC - MultiVersion Concurrency Controll
RDBのisolation level(分離レベル) がREAD COMMITTEDやREPEATBLE READなんかの時のために採用しているシステムのこと。
RDBでは同時に複数トランザクションが一つのテーブルを操作したりする。
例えばあるトランザクションがテーブルAを参照中に、Aの内容を書き換えるような別のトランザクションが存在すると、取ってきたデータに不整合が生じる。
この不整合をどの程度許容するかが分離レベルである。
-
READ UNCOMMITTED: COMMITされていないトランザクションAの変更をトランザクションBが参照できます -
READ COMMITTED: COMMITされたトランザクションAの変更をトランザクションBが参照できます -
REPEATBLE READ: COMMITされたトランザクションAの追加をトランザクションBが参照できます -
SERIALIZE: 同時に最大1つまでのトランザクションしか存在しないのと等価です
READ COMMITTED以降を実現するためにはSELECTで共有ロックを、UPDATEとINSERTで専有ロックを取得すれば良いが、パフォーマンスを考えるとなるべくロックの取得はしたくない。
そこで考え出されたのがMVCCであり、MVCC実装はRDBやストレージエンジンによって違うが、ここではMySQLのinnoDBを考える。
MVCC実装
全てのテーブルの全てのレコードにはMySQLが自動的に以下の3つのカラムを追加する。(ユーザからは見えません)
- DB_ROW_ID : その行のID
- DB_TRX_ID : 最後にそのレコードを追加・更新したトランザクションID
- DB_ROLL_PTR : そのレコードの過去の値を持つundo log recordへのポインタ
トランザクションIDが100のトランザクションが、あるレコードを挿入するとDB_TRX_IDに100が代入され、DB_ROLL_PTRはNULLになる。
トランザクションIDが102のトランザクションでレコードの値を書き換えると,undo log recordに過去の値が保存され,DB_ROLL_PTRにそのrecordへのポインタが代入され,DB_TRX_IDに102が入ります.
もしこれらの変更がCOMMITされたとして、分離レベルがREPEATABLE READの場合、トランザクションIDが99のトランザクションはこのレコードを参照できない。
トランザクションIDが101のトランザクションはこのレコードの変更前の値をundo log recordから探して参照する。
トランザクションIDが103のトランザクションは変更後の値を見ることができる。ざっくり「自分のトランザクションIDより未来の追加と変更は取得されない」と思っておけばそこまで困らない。