今週の生成AI情報まとめ(9/2~9/8)



こんにちは、ナウキャストでLLMエンジニアをしているRyotaroです。
9/2~9/8で収集した生成AIに関連する情報をまとめています。
※注意事項
内容としては自分が前の週に収集した生成AIの記事やXでの投稿・論文が中心になるのと、自分のアンテナに引っかかった順なので、多少古い日付のものを紹介する場合があります
それでは行きましょう
ひとこと
今週は情報をたくさん仕入れたので、ちょっと多めです…気長にみてください!笑 論文系や検証が必要な新しいサービスが多いと記事を書くのは大変ですねー本当は各ベンダーのプレスとかをまとめるセクションとか作ってみたいですが、んーキャパが足りなそう……
Githubレポジトリのソースコードごと LLM に取り込みたい
LLM に Github のソースコードを読んでもらいたいときに、ファイルをいちいちコピペするのは面倒。そんなときにつかえるソフト。注意するのはソースコードを LLM に読み込ませるところまではやらず、読み込ませる直前のテキストファイルを生成するという点。中の処理はおそらく全部のファイルをファイル構造含めて一つのテキストファイルに表現することで、そこまで難しいことはやっていない。
ただ、 LLM に読み込ませてなにかしたいひとは多分 Cursor の @Codebase 機能を使えばこんな作業はしなくて済むのではと思う……まあ手作業で README.md を作りたいとか、テキスト化して NotebookLM で RAG ができるようにしたいみなたいなモチベがあるなら有用かも。裏のブラックボックスになっている部分を知るのにも使えそう。
実際に使ってみる
実際に使うには、github repository を clone して実行する必要がある。
git clone https://github.com/mpoon/gpt-repository-loader
cd gpt-repository-loader
python3 gpt_repository_loader.py test_data/example_repo -o example.txt
ただ実はこれを fork して package にしている人がいた笑
これを使えばより簡単に実行できる
pip install gptrepo
gptrepo # now output.txt should appear in the current directory
- 出力例:
The following text is a Git repository with code. The structure of the text are sections that begin with ----, followed by a single line containing the file path and file name, followed by a variable amount of lines containing the file contents. The text representing the Git repository ends when the symbols --END-- are encounted. Any further text beyond --END-- are meant to be interpreted as instructions using the aforementioned Git repository as context.
----
file2.py
def hello():
print("Hello, World!")
----
folder1/file3.py
def add(x, y):
return x + y
--END--
参考資料
Bland.ai: コールセンターAI
コールセンターの代わりをしてくれるAIで、デモ動画を見ると流暢に答えてくれるのがわかる。特にすごいのが、グラフ形式に会話の変遷が見れることで、顧客の質問が何で、どう答えたかが可視化されている。
try it みたいなページがあるので多分もう開発されて使えるのでは?と思う。(試してはないので詳細は不明です。)

参考資料
Cursor Composer
Cursor に Composer という機能がある。
参考資料
MenubarX
1X 社が家庭用人型ロボット「NEO Beta」を公開(8/30)
ロボットスタートアップであるアメリカの企業 1X が家庭用人型ロボット「NEO Beta」を8/30に公開。1X 社は OpenAI から出資を受けている会社で、ターミネーターの到来も近いと噂されている。
未来がすぐそこまで来ているということか………
参考資料

Anthropic Claude が新しい機能 Harmony を開発
Harmony と呼んでいるこの機能は、ローカルファイルとの同期をするもので、ファイル参照、操作、統合ができる様になり、ローカル上でプロジェクトファイル組み立てたり、複数ファイルを分析とか出来るようになる。日付は公開していないが、近々利用可能になるとのこと。
完全にV0に対抗している感じがする。
参考資料
Physics of Language Models: Part 2.2 How to Learn From Mistakes on Grade-School Math Problems
論文の概略
LM(言語モデル)は、簡単な算数の推論タスクで間違えることがあり、**特に間違いを修正する能力が不足している。**現状、学習時に正しい推論ステップのみを見ているため、推論中に間違いが発生した場合、その修正方法を学習していない。つまり正しいものしか学習せず、間違いとそれを考え直す学習がされていないということ。

そこで、間違いに気づいた時点で生成をやり直す方法が試されたが、最終結果を改善するには多くの再生成が必要だった。
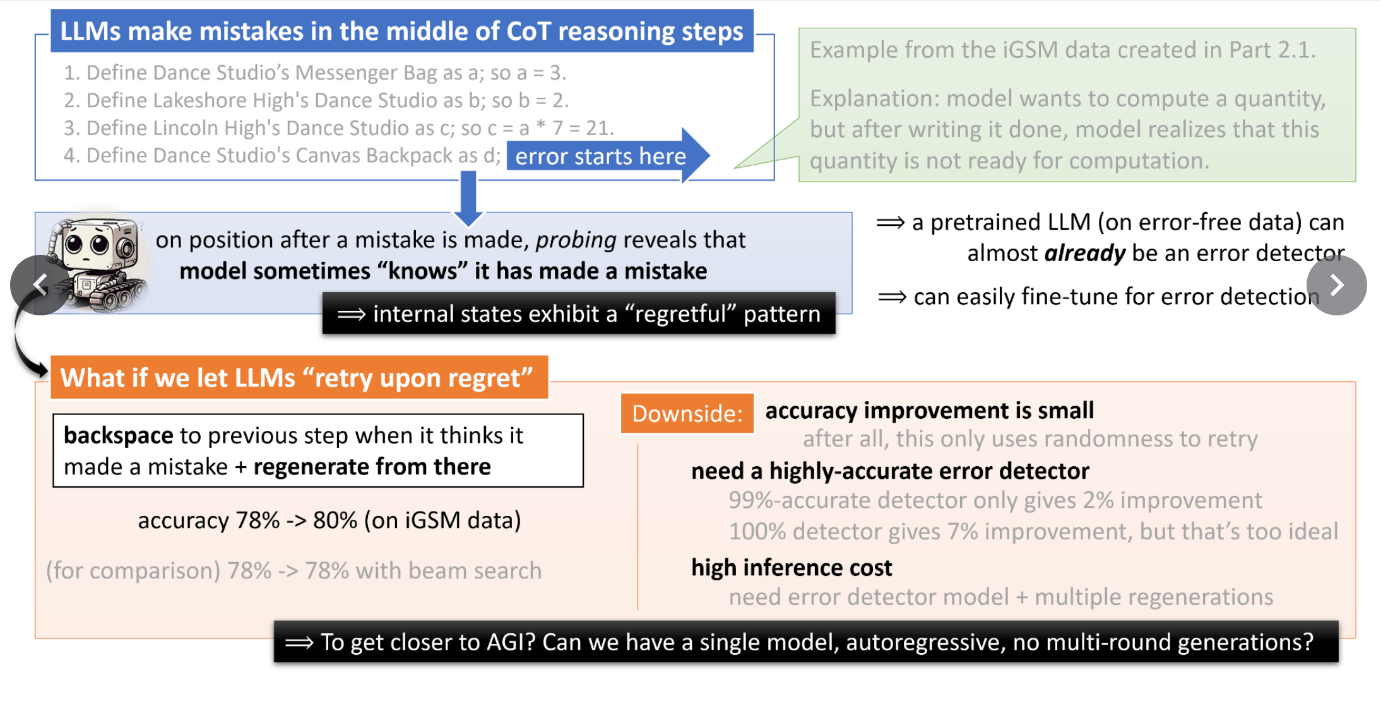
次のアプローチとして、推論の過程に間違いを含み、それを修正するようなデータを学習させた。特に、途中で変数を誤って導出する際に[RETRY]トークンを導入する方法が有効で、中難易度から難易度の高い問題で精度が大幅に改善された。

また、正しい推論ステップだけを学習したモデルでは修正能力が不足し、初期段階から間違いを含むデータで学習させる必要があることが分かった。

最終的に、実際の間違えた推論ステップを再現するのは難しいが、仮の間違えた変数を導出する方法でも精度向上が確認された。この手法は、複雑な現実世界のタスクでも応用できる可能性がある。

感想
めちゃくちゃ面白い論文だった。
人間でも正しいことしか教わらなかったら、間違った時にどうすれば正解が導けるかわからないのと同じ。イメージ、名人の将棋対局をみてすごいなって思うだけじゃダメで、実際に自分も打ってみて、この場面でこの手をなぜ打っているのか、別の手を打ったらなぜダメなのか、形勢が悪くなった時にどうカバーするかみたいなところまで考えることをしないと身にならないみたいな(将棋は齧ったことしかないので誰かに怒られそうですが……)。
学習データには正解のみではダメで、間違いを含みかつ、その修正過程を含むデータが重要ということ。
参考資料
v0 でデザイン作成
最近の流行りで X でよく見るのが、Canvas で書いた一枚のチラシみたいなものを v0 で作っちゃうやつ
ということで試しに v0 の料金体系を v0 でチラシっぽく作った結果、めっちゃリッチな感じになった笑これがサクッと作れるのはヤバすぎる
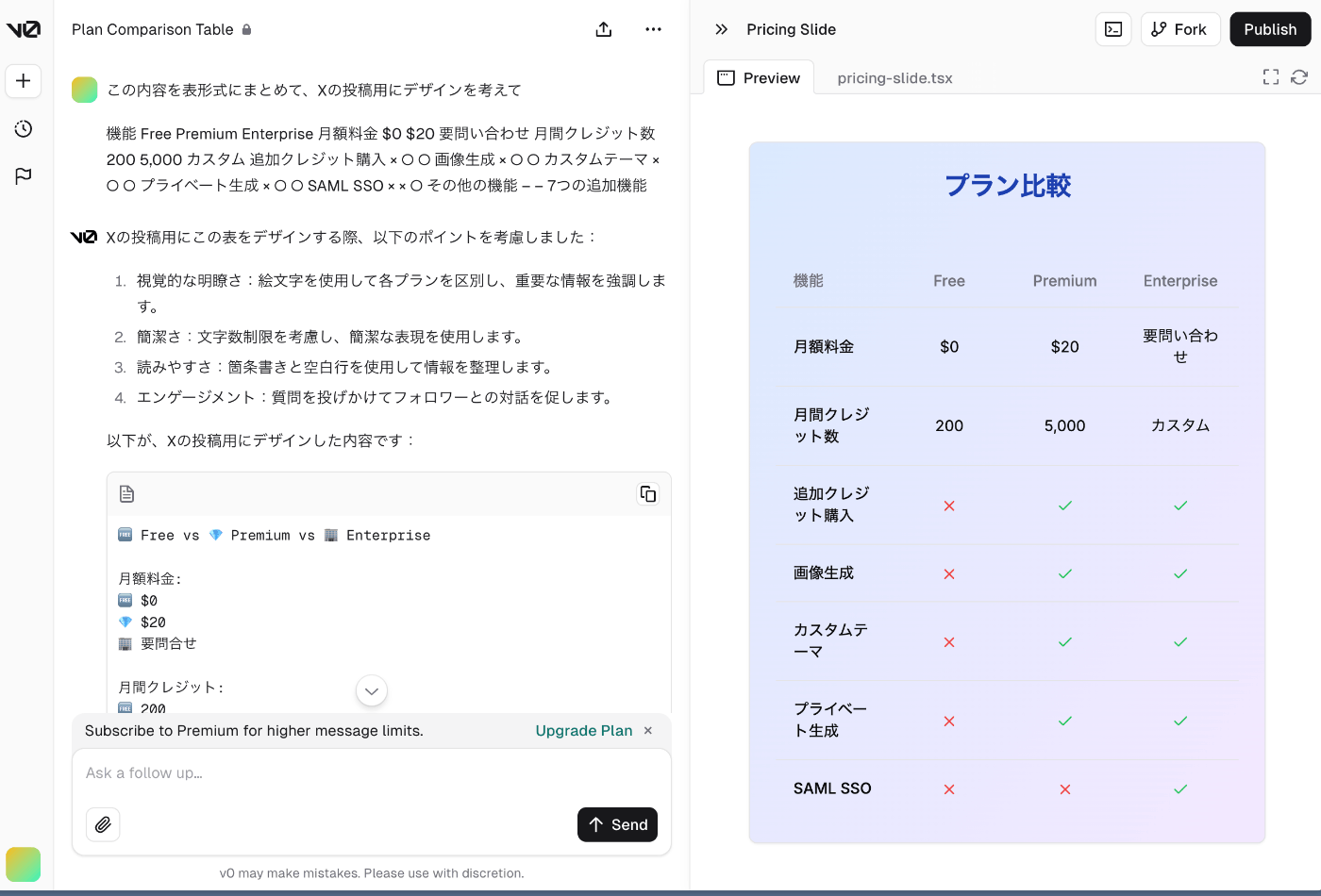
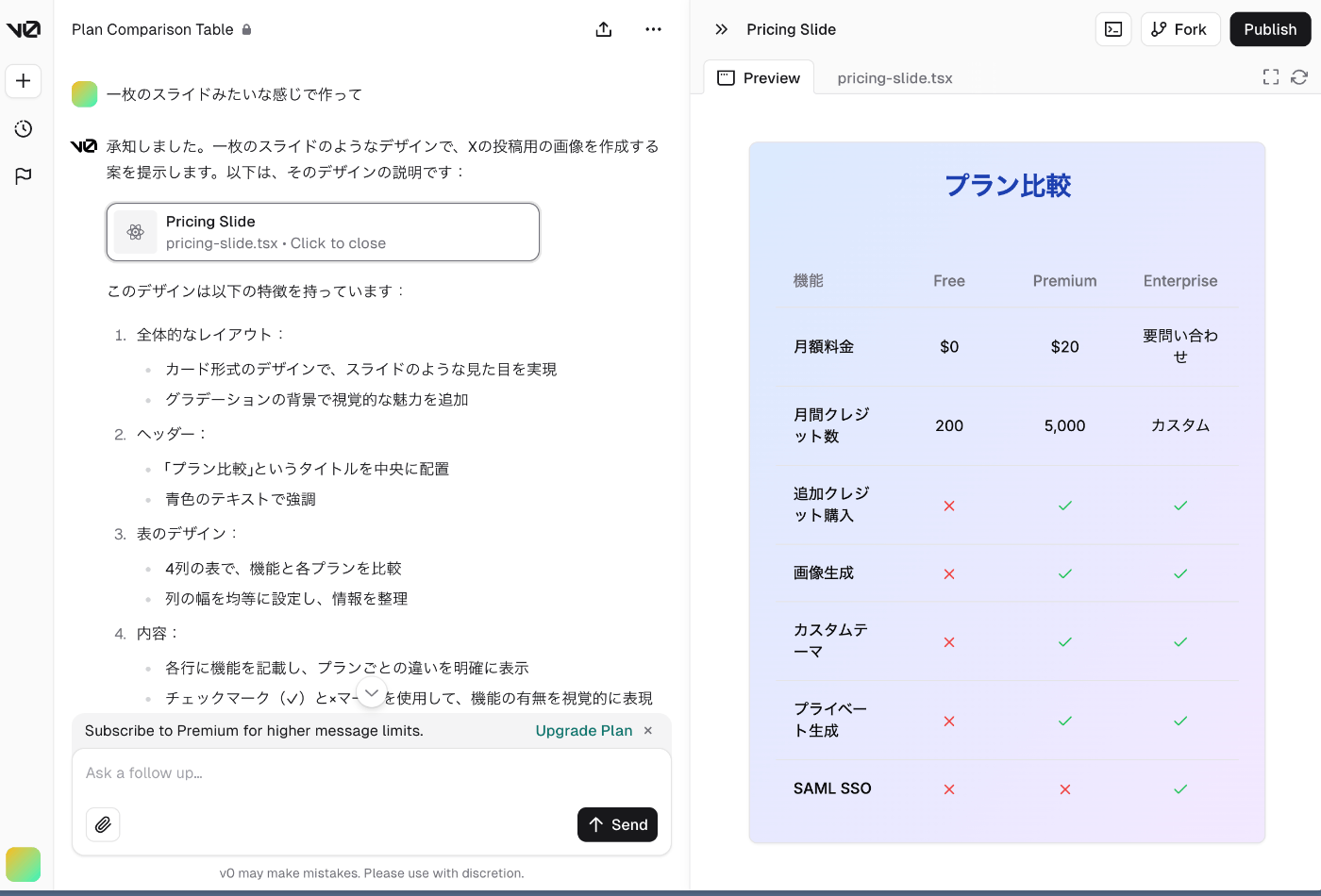
参考資料
v0 で LP(Landing Page)作成
やり方
- スクショして「完全再現したものを出して」と入力
- 上手くいってないところをスクショして修正指示
やってみる
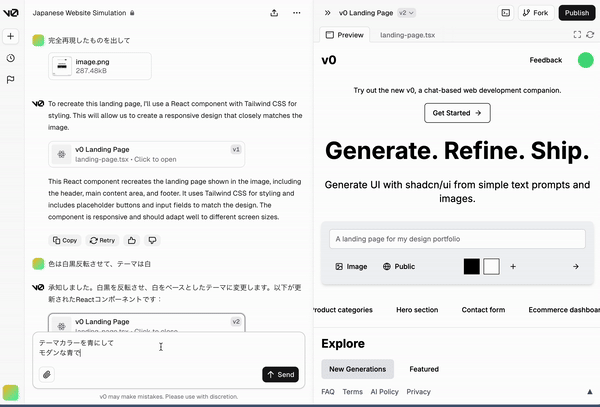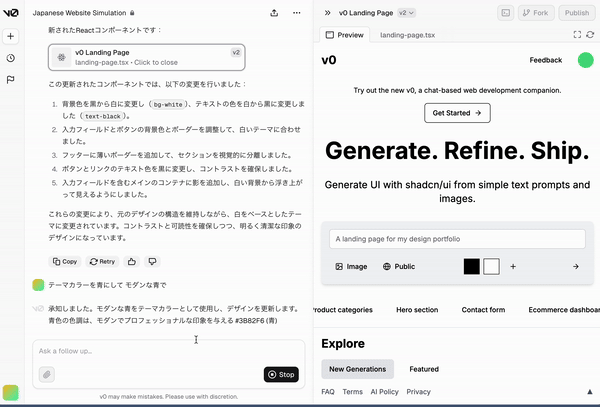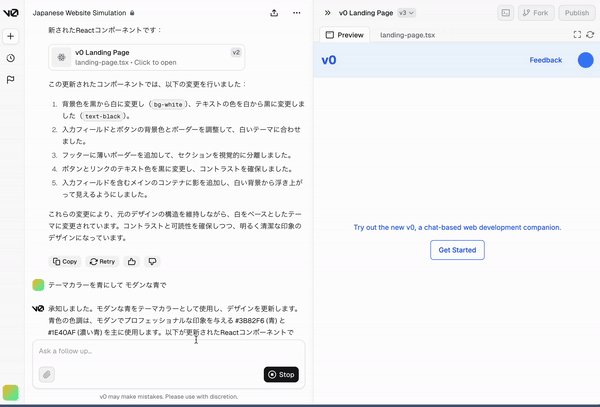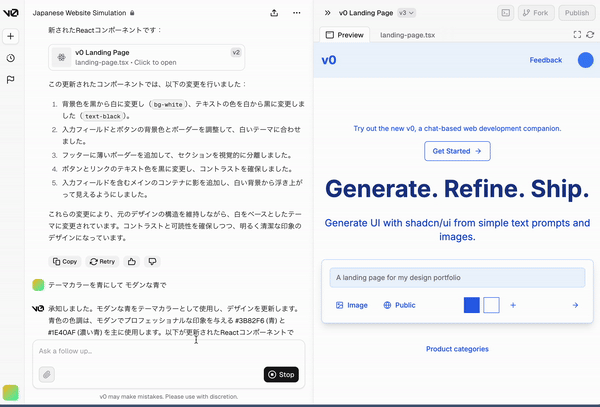
参考資料
ビジネス向けプロンプト集
| No. | プロンプト | 説明 |
|---|---|---|
| 1 | プロンプト作成 | プロンプトクリエイターになっていただき、まずプロンプトのトピックについて尋ね、それを反復的に改善します。a) 修正プロンプト、b) 提案、c) 明確化および強化のための質問を生成します。 |
| 2 | メールマーケティング | [理想の顧客ペルソナ]のニーズに高めのポイントに訴えられますか。[強い行動を取るように誘導する][メールの型] を考案してください。要素ごとに強調しファローを含む内容に改善します。 |
| 3 | ウェブサイトの最適化 | 私のウェブサイトの[トピック]に関するタイトルタグとメタディスクリプションを最適化する方法を提示しています。 |
| 4 | 営業メール | [ブランド/会社の提案]レポートを共有しています。[理想の顧客ペルソナ]向けに私の[製品/サービス]のトラフィックと売上を促す3つのメールのアイデアを提示しています。 |
| 5 | SNS投稿 | 興味のメリットを関わる新しいブログ投稿やソーシャルメディアで宣伝する予定です。キャッチーで簡単なSNS投稿を作成してください。 |
| 6 | 複雑な情報の要約 | SNSが分かりやすく語る表現を考えています。研究論文を要約し、主要なポイントを整理していただけますか? |
| 7 | メールテンプレート | 顧客を行動に促す魅力的なメールテンプレートを設計してください。メールのトーンやフォーマットを適したいと考えています。顧客のニーズに合ったものにするために、[ビジネス/業界]用の提案を交えてメールテンプレートを提供してください。 |
| 8 | ブログ記事執筆 | 2023年の[デザインやSEO]に関するブログ記事に関するSEOの証拠としてブログを執筆したいです。2022年のトレンドを反映し、推奨戦略を盛り込んだコンテンツの作成支援をしていただけますか? |
| 9 | YouTube広告 | 私の[製品/サービス]を[理想の顧客ペルソナ]に紹介し、[強い行動を取るように誘導する]短いカジュアルに関するYouTube広告を宣伝してください。 |
| 10 | X投稿アイデア | [トピック]に関する価値のある関連情報を提供し、[理想の顧客ペルソナ]にアピール、強い行動喚起とともに高品質なリードを引き寄せるX投稿のアイデアを提示しています。 |
| 11 | プレゼンテーションスキルの向上 | 今後の[プレゼンテーション]の期間のために、プレゼンテーションスキルを向上させる必要があります。オーディエンスに強い影響を与えるために効果的なメッセージとビジュアル要素を備えたコンテンツを準備していただけますか? |
| 12 | チームコラボレーションの促進 | リモートワークを続けており、チームのコラボレーションを改善し、チーム全体のやり取りを促進するためのツールや実践方法を提示しています。 |
| 13 | プロジェクト管理の効率化 | チームのプロジェクト管理プロセスを効率化するためのアドバイスが欲しいです。タスク、タイムライン、およびコミュニケーションを効率的に管理して、プロジェクトの成果を出させるにはどうすればよいですか? |
| 14 | 個人の生産性向上のハック | 時間を最適化し、注意を減らし、日々の生産性を高めるための個人の生産性ハックを探しています。効率を改善する3つの戦略を提案してください。 |
| 15 | コンテンツマーケティング戦略 | ブログ投稿、ソーシャルメディア、メールマーケティング、その他の[コンテンツマーケティング戦略]を構築する必要があります。どのように始め、重要な要素を強調すればよいですか? |
| 16 | 顧客サービスの卓越性 | 顧客サービスの体験を改善し、ロイヤリティと満足度を高めています。顧客とのやり取りを強化するための新鮮な戦略やツールを提案してください。 |
| 17 | ネットワーキングと関係構築 | 業界内でプロフェッショナルネットワークを拡大し、顧客の関係を発展させています。今日のデジタル時代に効果的なネットワーキング戦略は何ですか? |
| 18 | 小規模ビジネスの財務管理 | 小規模ビジネスの財務より効果的に管理するためのガイダンスが必要です。予算計画、経費削減、収益性を高めるようにする手順はどうすればよいですか? |
| 19 | 効率的なリモートワーク環境の構築 | リモートワークの効率性を高めるスペースを設営しています。生産性を向上させるためのアドバイスは何ですか? |
| 20 | LinkedInを活用したキャリアアップ | ネットワーキングやキャリアの成長のためにLinkedInを活用したいと考えています。プロフィールやスキルをどのように強化し、機会を引きつけ、スキルをアピールするためにLinkedInの機能をどのように活用すればよいですか? |
| No. | プロンプト | 説明 |
|---|---|---|
| 1 | 製品説明(AIDA) | AIDA(注意、興味、欲望、行動)フレームワークを使用して、「〇〇」の製品説明を書いてください。 |
| 2 | 製品説明(PAS) | PAS(問題解決、解決)フレームワークを使用して、「〇〇」の問題解決方法を強調する製品説明を書いてください。 |
| 3 | 製品説明(FAB) | FAB(特徴、利点、利益)フレームワークを使用して、「〇〇」の価値を示す詳細な説明を作成してください。 |
| 4 | SNS投稿(4Cs) | 4Cs(明確、関連、魅力的、信頼性)フレームワークを使用して、「〇〇」のソーシャルメディア投稿を作成してください。 |
| 5 | Instagram投稿 | ストーリーテリングフレームワークを使用して、「〇〇」のInstagram投稿を作成してください。 |
| 6 | Xスレッド | HERO(物語、感情、反応、発展)フレームワークを使用して、「〇〇」に関してのXのスレッドを書いてください。 |
| 7 | ウェルカムメール | 私の製品「〇〇」を活かすためのウェルカムメールを。 |
| 8 | プロモーションメール | AIDA(注意、興味、欲望、行動)フレームワークを使用して、「〇〇」の割引プロモーションメールを作成してください。 |
| 9 | メールニッケンス | BANT(予算、権限、ニーズ、タイミング)フレームワークを使用して、「〇〇」にメールニッケンスを書いてください。 |
| 10 | メリット紹介 | Listicle/口コミの型フレームワークを使用して、最も重要な製品やブログ投稿を作成してください。 |
| 11 | ケーススタディ記事 | STAR(状況、タスク、行動、結果)を使用して、「〇〇」の顧客体験や事例紹介。 |
| 12 | ハウツー記事 | How-Toフレームワークを使用して、「〇〇」製品に関する方法を説明するブログ記事を書いてください。 |
| 13 | AdWords広告 | PPC(購買、誘導、行動)のフレームワークを使用して、「〇〇」Google AdWords広告を作成してください。 |
| 14 | Facebook広告 | PPC(購買、誘導、行動)のフレームワークを使用して、「〇〇」を含むFacebook広告を作成してください。 |
| 15 | LinkedIn広告コピー | OIC(オファー、情報、行動促進)フレームワークを使用して「〇〇」を宣伝するLinkedInの広告コピーを作成してください。 |
| 16 | ホームページコンテンツ | 5-Second Test(見出し、優位性、CTA)フレームワークを使用して、「〇〇」のウェブサイトのホームページコンテンツを最適化してください。 |
| 17 | FAQセクション | SCQA(状況、複雑性、質問、回答)フレームワークを使用して「〇〇」のFAQセクションを作成してください。 |
| 18 | 会社概要 | 5Ws(誰が、何を、いつ、どこで、なぜ)フレームワークを使用して、「〇〇」の会社概要ページを作成してください。 |
| 19 | 特別オファー | AIDA(注意、興味、欲望、行動)フレームワークを使用して、「〇〇」の特別オファーのランディングページを作成してください。 |
| 20 | LP | PPC(購買、誘導、行動)のフレームワークを使用して、「〇〇」を含むランディングページのLPを書いてください。 |
| 21 | ウェビナーLP | Event Promotionフレームワークを使用して、「〇〇」に関するウェビナーのランディングページを作成してください。 |
| 22 | プレスリリース(新製品) | プレスリリースのフレームワークを使用して、「〇〇」の発表を含むプレスリリースを書いてください。 |
| 23 | プレスリリース(受賞) | プレスリリースのフレームワークを使用して、「〇〇」の受賞を含むプレスリリースを書いてください。 |
| 24 | プレスリリース(パートナーシップ) | Joint Ventureフレームワークを使用して、「〇〇」社との新しいパートナーシップに関するプレスリリースを書いてください。 |
| 25 | 製品デモ動画台本 | Explainerビデオフレームワークを使用して、「〇〇」の製品デモビデオのスクリプトを作成してください。 |
| 26 | 顧客レビュー動画台本 | STAR(状況、タスク、行動、結果)フレームワークを使用して、「〇〇」のお客様の声のビデオスクリプトを書いてください。 |
| 27 | お客様の声 | PAS(問題、解決、解決)フレームワークを使用して、「〇〇」に関する説明ビデオのスクリプトを書いてください。 |
| 28 | 成功事例 | STAR(状況、タスク、行動、結果)フレームワークを使用して、ポジティブフィードバックを示す成功事例を書いてください。 |
| 29 | 顧客レビュー | STAR2フレームワークを使用して、「〇〇」のフィードバックフィールドについての成功事例を書いてください。 |
| 30 | 製品レビュー | 5Ws(誰が、何を、いつ、どこで、なぜ)フレームワークを使用して、「〇〇」のレビューを書いてください。 |
参考資料
新しい AI Editor 「Melty」
最近口火を切ったように AI Native なエディターツールが開発されていますね。その一つが「Melty」
Melty は、ターミナルから GitHub までの操作を認識し、ユーザーと協力して本番環境対応のコードを作成する初の AI コード エディター
Github には公開されているが、install 方法までは書いておらず、package をダウンロードするには google form に入力するように促されるためまだ実際には使えない。
ぱっとみデモ動画を見る感じでは、ターミナルから Github までに操作を認識している、というメリットをあまり感じないので、正直よくわからないが今後に期待したい。

参考資料
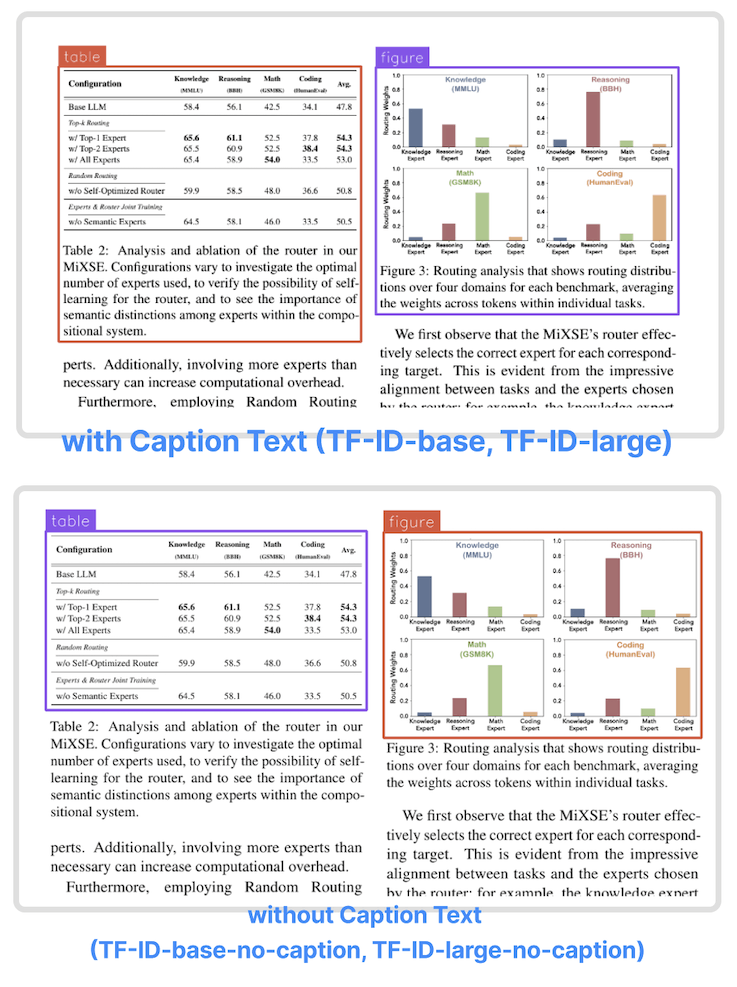
TF-ID-base: 論文内の図表を検出する
hugging face で公開されている画像認識モデル。単一の紙ページの画像を入力として受け取り、指定されたページ内のすべての表と図の境界ボックスを返すとのこと。
オブジェクト検出結果の形式は以下の通り
{
"<OD>": {
"bboxes": [
[x1, y1, x2, y2],
...
],
"labels": [
"label1",
"label2",
...
]
}
}
モデルを使うためのコードもしっかり用意されており、簡単に使えそう。
LLM に論文を理解させる前段としてこの処理を挟んでやったら、理解度上がりそう
モデルの概要
TF-ID (Table/Figure IDentifier) は、 Yifei Huが作成した、学術論文内の表や図を抽出するために微調整されたオブジェクト検出モデルのファミリーです。4 つのバージョンがあります
| モデル | モデルサイズ | モデルの説明 |
|---|---|---|
| TF-IDベース[HF] | 0.23億 | 表/図とそのキャプションテキストを抽出します |
| TF-ID-large [HF] (推奨) | 0.77億 | 表/図とそのキャプションテキストを抽出します |
| TF-ID-ベース-キャプションなし[HF] | 0.23億 | キャプションテキストなしで表/図を抽出する |
| TF-ID-large-no-caption [HF] (推奨) | 0.77億 | キャプションテキストなしで表/図を抽出する |
参考資料
RAG精度向上に関する研究: 要約を活用したクエリ書き換えが検索精度を大幅に向上させる (by AWS)
8/16 に AWS 所属の研究者が発表した論文、Meta Knowledge for Retrieval Augmented Large Language Models で、従来の「検索してから読む」方式を拡張し、「”準備してから書き換えて”検索して読む」枠組みを考案した。

簡単に流れを整理すると
- 元文書からメタデータと質問&回答セットを作って index 化する
文書を事前に決められたカテゴリー(研究分野や応用タイプなど)に分類するメタデータを作成
また教師-生徒型のプロンプティングを用いて、文書の内容に基づく人工的な質問と回答のペアを作る
- メタ知識要約(MK Summary)を生成する
メタ知識要約(MK Summary)は、メタデータを使って、関連する文書の内容を簡潔にまとめたもの。例えば、「機械学習」というメタデータに関連する論文の主要なポイントをまとめた要約など。
- 特定のメタデータ(例:研究分野)に関連する文書の質問を集める
- これらの質問をClaude 3 Sonnetに与えて、要約を作成してもらう
これは推察するに、元データは関係なく特定のメタデータに関する知識をより言語化して、メタ的視点を獲得するための知識を作成する過程。例えば「機械学習」というメタデータだったら、「機械学習」というただの分野名というメタデータにとどまらず、現在「機械学習」の分野がどういうことをやっていて、どういう風潮なのかをさまざまな文書から要約するということ。
その分野に関する理解を深めるためのフェーズ、と解釈した。
- クエリの拡張生成と検索
ここでは、あらかじめ生成したメタ知識要約を使って、実際のクエリを拡張して検索する。ヒットした質問と回答のセットを得て、回答する
感想
アイデア自体はシンプルで、アーキテクチャとしても全然ビジネスですぐ実装できそうな印象。あとはこれを実装して、精度を検証するMLOpsを回せれば最高。
参考資料
ターミナルでLLMとペアプロできるツール
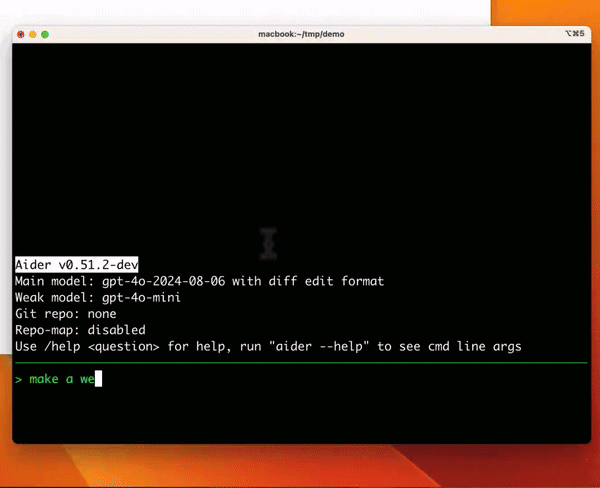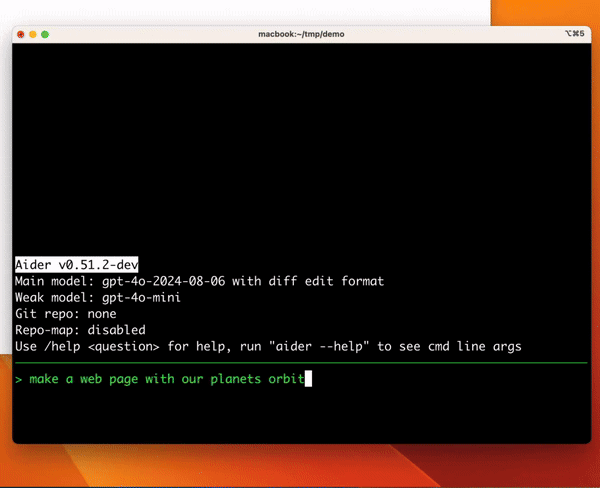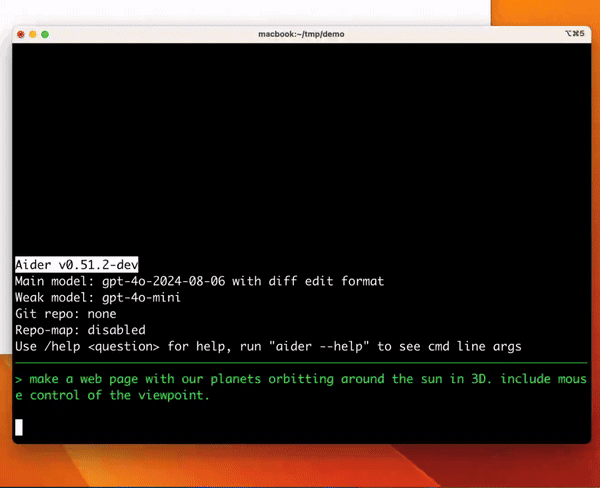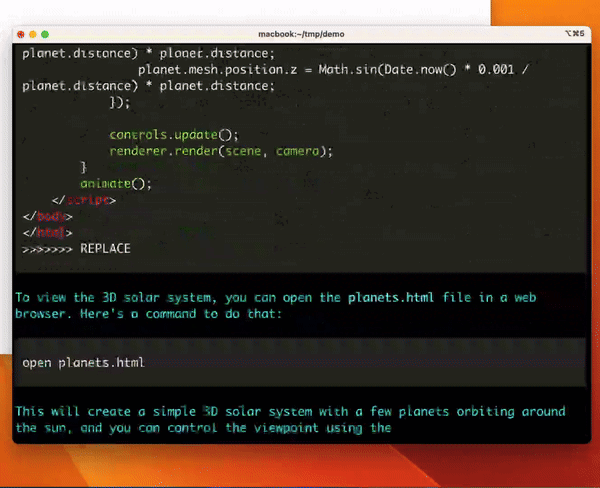
python の pip 経由で install して使えるので結構ハードルは低い。
python -m pip install aider-chat
# Change directory into a git repo
cd /to/your/git/repo
# Work with Claude 3.5 Sonnet on your repo
export ANTHROPIC_API_KEY=your-key-goes-here
aider
# Work with GPT-4o on your repo
export OPENAI_API_KEY=your-key-goes-here
aider
API Key を設定して使うが、ほぼ全ての LLM に対応している。ベストなモデルは GPT-4o か Claude 3.5 Sonnet とのこと。他にも Llama とか Groq とか OSS のモデルも利用できる。
特徴
- 編集したいファイルで aider を実行します。aider <file1> <file2> ...
- 変更を依頼する:
- 新しい機能やテストケースを追加します。
- バグについて説明してください。
- エラー メッセージまたは GitHub の問題の URL を貼り付けます。
- コードをリファクタリングします。
- ドキュメントを更新します。
- Aider はリクエストを完了するためにファイルを編集します。
- Aider は、適切なコミット メッセージを使用して変更を自動的に git コミットします。
普通に使ってみたい
参考資料
ChatGPT の上位互換が登場する?
なんと、ChatGPTの上位互換が月額最大$2,000(約29万円)で登場するかもしれないらしい。
参考資料
Discussion