今週の生成AI情報まとめ(9/23~9/29)

こんにちは、ナウキャストでLLMエンジニアをしているRyotaroです。
9/23~9/29で収集した生成AIに関連する情報をまとめています。
※注意事項
内容としては自分が前の週に収集した生成AIの記事やXでの投稿・論文が中心になるのと、自分のアンテナに引っかかった順なので、多少古い日付のものを紹介する場合があります
それでは行きましょう
ひとこと
最近も忙しくて、公開がなんと2週間後になってしまいました泣。。。。なんとか巻き返すので多めに見てください!笑
v0 でプレゼン資料作成
v0 はサイトの UI/UX の作成で使われることが多いが、チラシやプレゼン資料を作ることにも使える。
実際にやってみる
https://v0.dev/ にアクセスし、「ChatGPTの企業導入をテーマにスライドを15枚程度作成してください。テーブルや図解・グラフなどを用いてリッチに作成すること。作成できたらUIを作成すること」と入力。
すると、speakerdeck みたいなプレゼン資料を投影する画面が再現される。

やった見た感想としては、遊びとして、また他に転用することを考慮しなければこれでもいい気がする。実際にビジネスではプレゼン資料を .pptx とか、 google slide とかで他の人に共有・編集できるようにしたいので、ちゃんとやるなら「Gamma」などのプレゼン作成AIツールを使った方がいいかも
これなら、PDFやPowerPiint、PNGでエクスポートできる
一方チラシやポスター、X投稿用の画像などを作るにはめっちゃいい気がする
試しに「v0」の紹介画像を作ってみる
v0に「v0のメリットデメリットを整理して、Xの投稿用にチラシ画像のデザインを作成して」と入力すると、、、

悪くない
参考資料
Anthropic 公式の RAG 精度向上施策
Anthropic 社が 9/20 に「Introducing Contextual Retrieval」というタイトルで記事を出した。その内容が面白かったので共有。
まず、RAGを実装する前に入力トークン制限に収まるくらいの量(20万トークン以下)であればそのままプロンプトに入れてするのが最もシンプル。2024/08/15にリリースされたプロンプトキャッシュにより、コスト面で最大90%節約できるため、大量のプロンプトを投げることに対するハードルも下がった。
RAG 入門
一般的な RAG ソリューションとして、ドキュメントを 数百トークン以下の chunk に分け、BM25による全文検索と Embedding モデルを利用するベクトル検索を行い、その2つの検索結果をスコアに基づいて融合・重複削除して、プロンプトに上位 k 個の chunk を埋め込む。
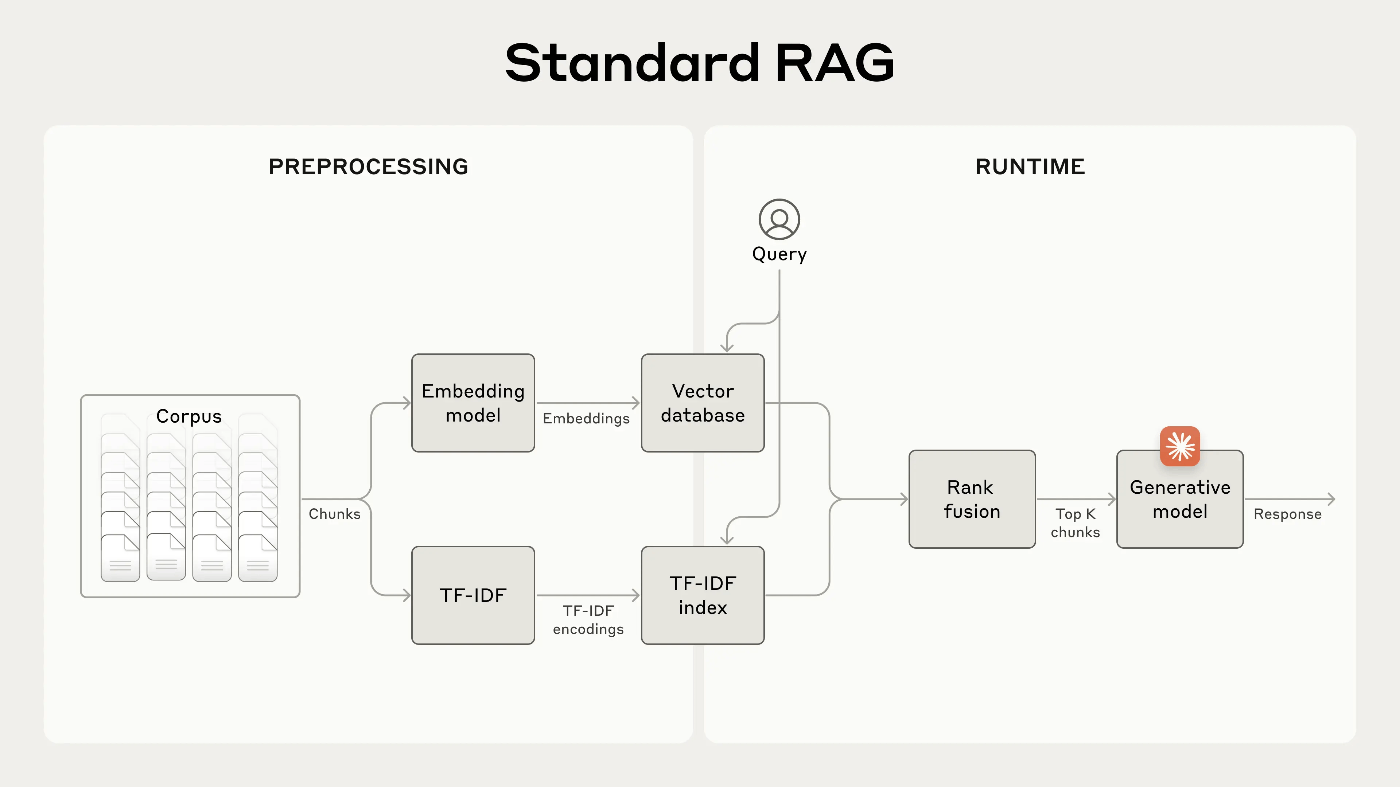
ただしこの方法では、各チャンクにそのチャンクが何を意味するのかタイトルがないので、次のような課題が生まれる。
たとえば、ナレッジベースに財務情報(たとえば、米国 SEC 提出書類)のコレクションが埋め込まれていて、次のような質問を受け取ったとします。「2023 年第 2 四半期の ACME Corp の収益の伸びはどのくらいでしたか?」
関連するチャンクには、「会社の収益は前四半期より 3% 増加しました」というテキストが含まれる場合があります。ただし、このチャンクだけでは、どの会社を指しているか、または関連する期間が特定されないため、正しい情報を取得したり、情報を効果的に使用したりすることが困難になります。
コンテキスト検索の導入
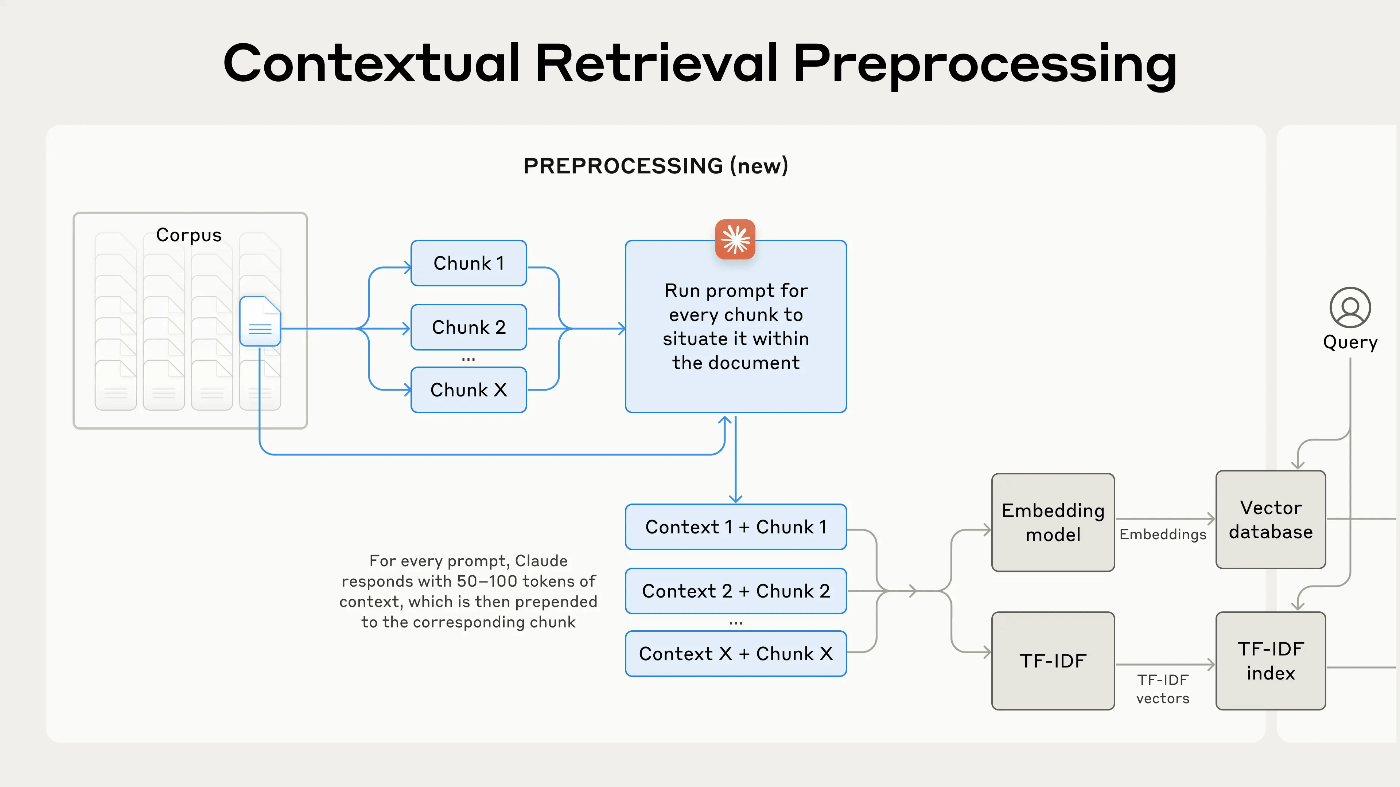
そこで、各 chunk の前に、固有の説明テキスト(タイトル的なもの)を追加することで、改善させることができる。
original_chunk = "The company's revenue grew by 3% over the previous quarter."
contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."
興味深いのは次の説明で、要約追加やHyDEではあまりうまくいかなかったのこと。
他の提案には、チャンクに一般的なドキュメントの要約を追加すること(実験したところ、非常に限られた効果しか得られませんでした)、HyDE(仮想ドキュメント埋め込み)、要約ベースのインデックス作成(評価したところ、パフォーマンスが低いことがわかりました) などがあります。これらの方法は、この投稿で提案されている方法とは異なります。
実際に固有の説明テキストをいれるためには、次のプロンプトを使って作る。
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
すると前処理フローはこうなる
Re-Ranking
最後に Re-Ranking の導入で、これは BM25 やベクトル検索で検索した結果を Re-Ranking モデルに渡し、プロンプトとの関連性・重要性に基づいてスコアをつけて検索結果を再度フィルタリングする方法。有名なのは Cohere が出している Rerankのモデル。この記事でもこのモデルを使って検証を行ったとのこと。
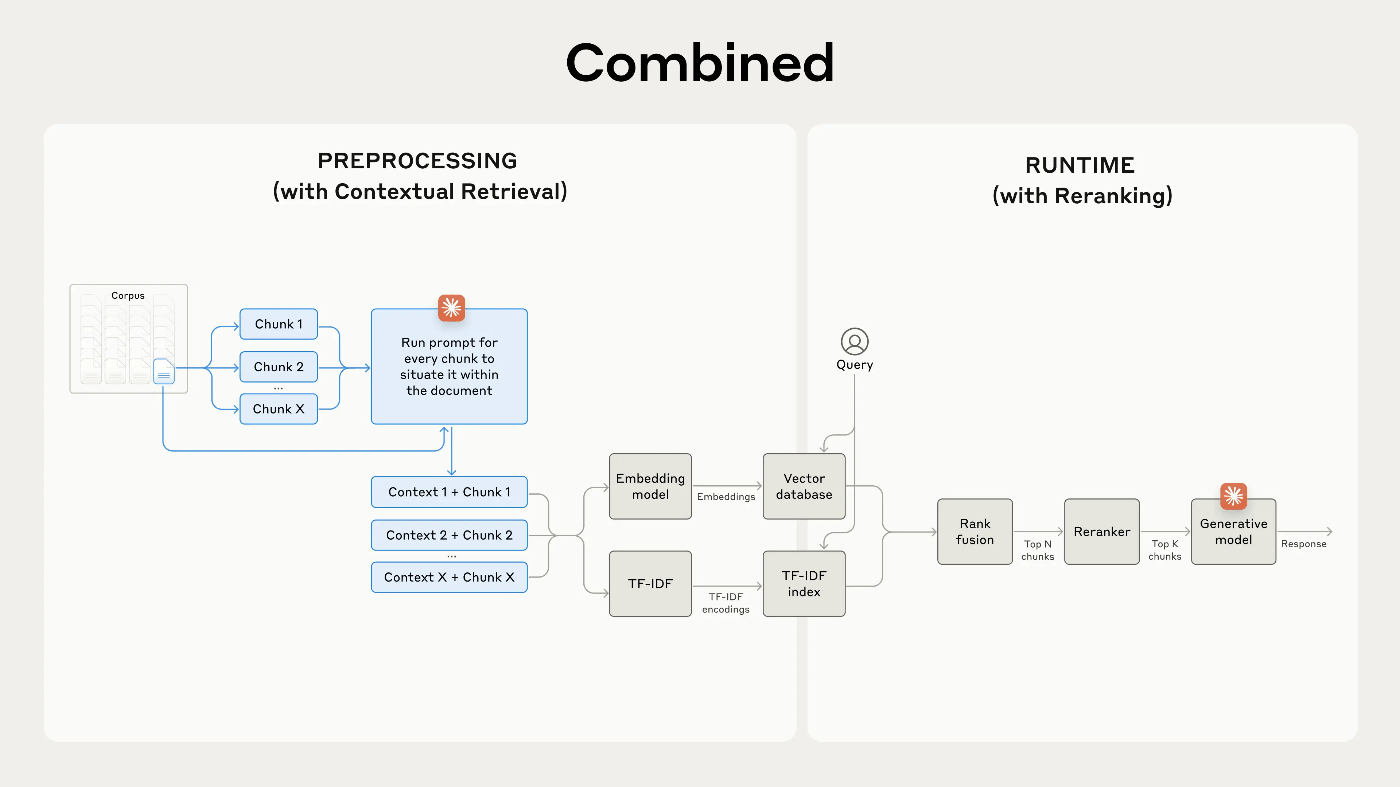
これにより、検索失敗率が67%も減少させることに成功
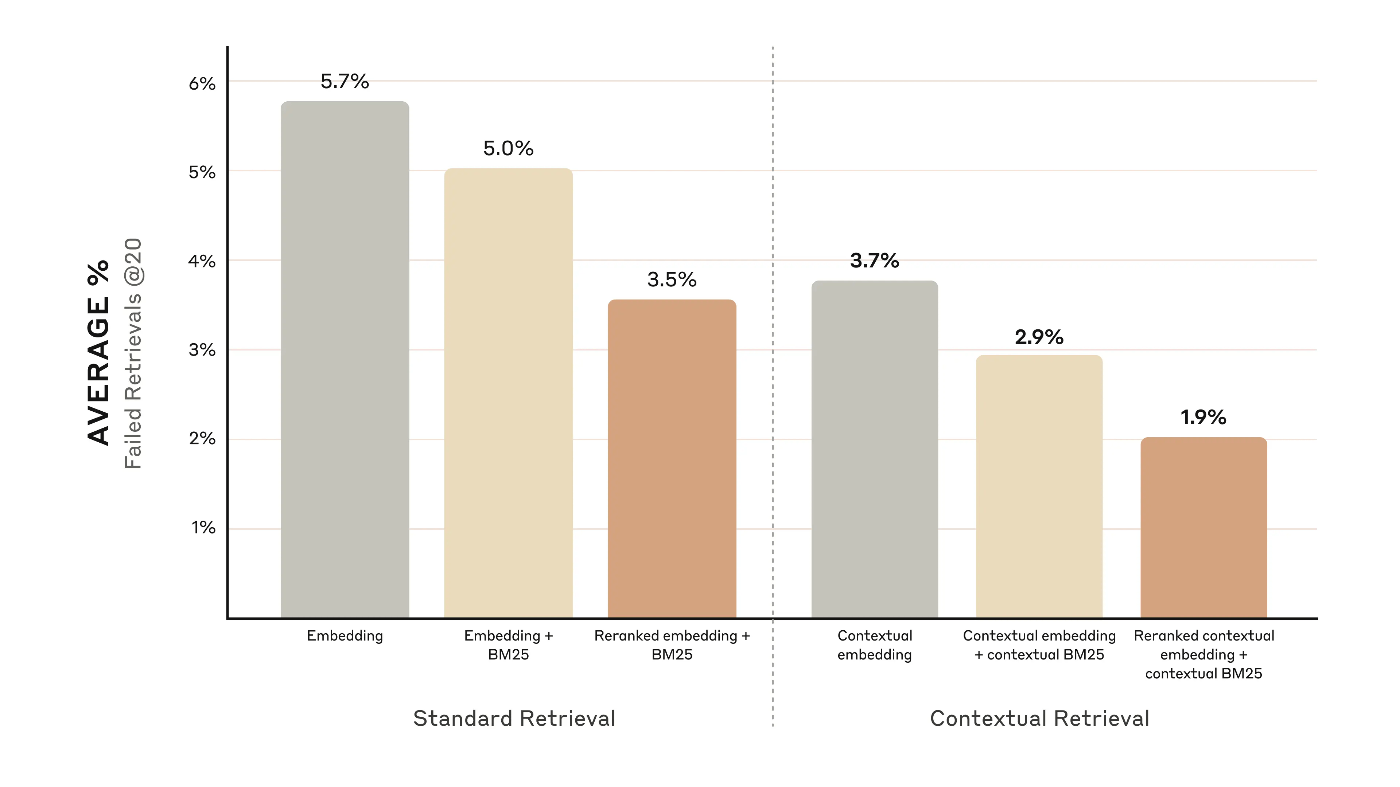
結論
ハイブリッド検索はもちろんのこと、コンテキスト検索の導入という簡単な処理を追加するだけで精度は改善できるし、Re-Ranking モデルも導入自体は簡単なので、非常に実用性の高いアプローチだと思われる。これとは別に最近は GraphRAG というのも流行っているのでそちらを導入するのもありかも?
参考資料
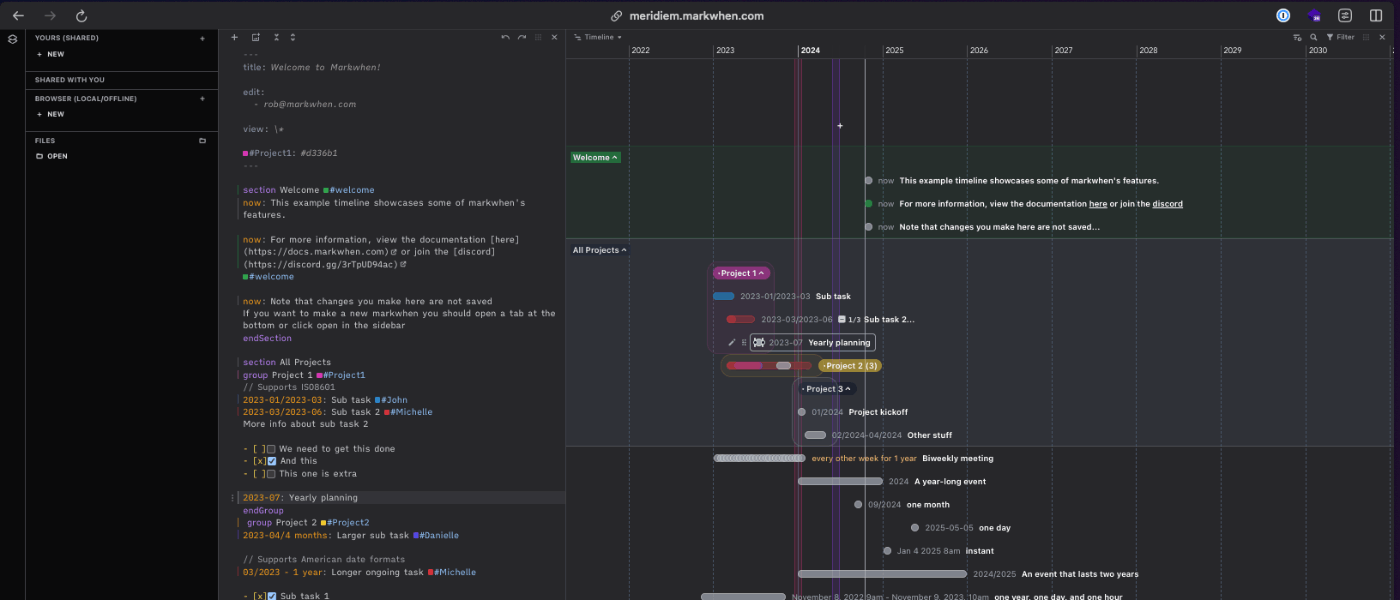
markwhen
自分が知らなかっただけですが、markwhen という markdown テキストをタイムラインに変換するツールがあるそう。マークダウン風のテキストを書くと、見栄えの良いタイムラインやその他のビジュアライズが可能。
markdown 出かけるのでもちろん LLM を噛ませることができ、Cursor などで編集させることもできるので、生成AIと相性いいかも
参考資料
v0 が進化!
また v0 が進化しました!一つは PDF を読み込めるようになったこと。これによりマニュアルや仕様書など大量のテキストデータを一気に送れるようになった。
さらに、web検索機能も追加されており、v0 がデフォルトで知らない情報は自動で web 検索しに行ってくれる。
v0のメリットデメリットを質問したところ、自身のサイトにアクセスして情報を取得してきました!すごい!

v0 は日々進化していて、追いつくのが大変ですね笑
参考資料
OpenAI Advanced Voice をリリース
2024/9/25日に、OpenAIから人間並みの会話ができる「Advanced Voice Mode」を有料会員向けに順次提供を開始すると発表。2024/10/1 時点で、欧州連合、スイス、アイスランド、ノルウェー、リヒテンシュタインを除くすべての Enterprise、Edu、Team ユーザー、およびほとんどの Plus および Free ユーザーが利用できるとのこと。(現時点 10/14 で自分のアカウントで利用できてます!)
Advanced Voice は Plus・Team ユーザー向けに展開されており、無料ユーザーは毎月のプレビューが展開される。
開始するには画面右下の音声アイコンを選択

すると、中央に青い丸が出てきて音声会話ができるようになる

なお標準音声では、黒い丸になってお離、そこで違いを出している模様

いくつかのデモを聞いたが、どれをとっても人間らし差がすごい。間や抑揚、息継ぎなど人間っぽさがすごい出ている。しかも50言語に対応しているので大体の人は使える
これは同時通訳をしている事例。普通にすごすぎる…
参考資料
We are Hiring!
この件についてもっと詳しく知りたい、議論したい、はたまたナウキャストという会社に興味を持ったという方は、カジュアル面談フォームから連絡ください。その際に「今週の生成AI情報まとめ見た!」と書いていただければ幸いです!
Discussion