TiKVのMVCCによるバージョン蓄積をトラブルシュートする
この記事について
この記事では、TiKVでは更新を重ねたデータがどのようにバージョン情報を保持しているのか、蓄積されたバージョンを減らすためにいつGCすべきかを知る方法を提示しています。
参考資料
この記事は主に以下の2つの記事を参考にしており、これらに追加的な検証や解説を加えています。
TiDBにおけるMVCCモデル
最初にTiDBにおけるMVCCについておさらいしておきましょう。
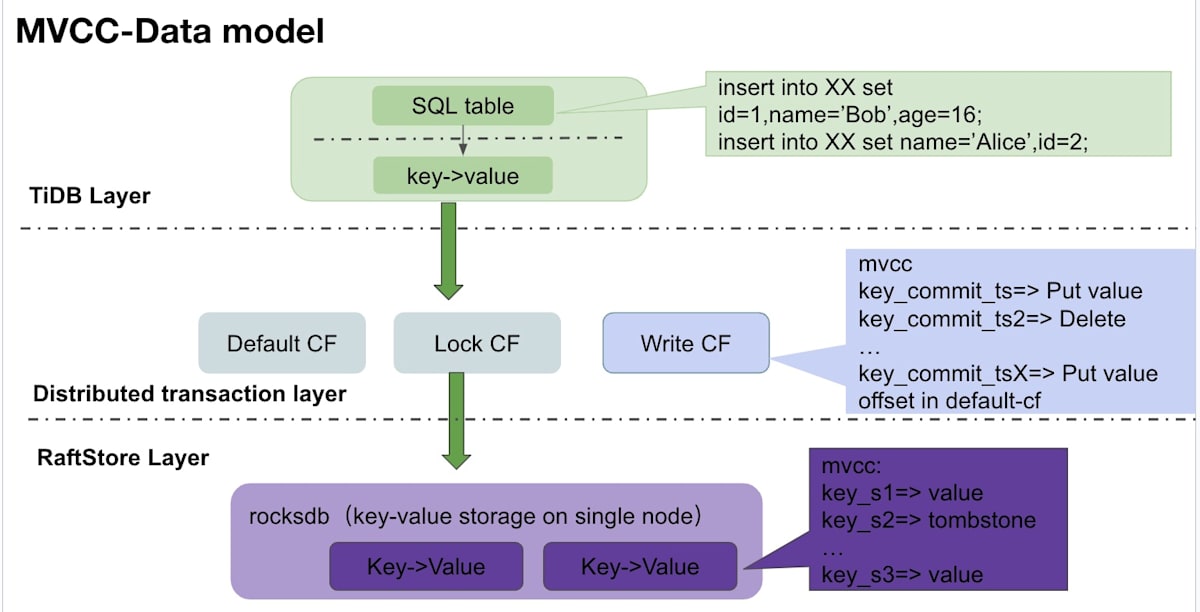
(画像はTiDB MVCC 版本堆积相关原理及排查手段から)
3つのレイヤーで考えます。
- TiDB: ユーザーから見えているレイヤー。このレイヤーではレコードにバージョンという概念はありません。
- TiKV: 分散トランザクションを提供するレイヤー。TiDBから送られてきたデータをMVCCに対応したKV(Key-Value)に変換します。キーには送信順序を示すバージョン情報が付与されています。
- Raftstore: TiKVがデータを保存する場所です。
上記の3つのレイヤーのうち、MVCCの概念はTiKVとRaftstoreの2つに適用されます。
MVCCによるレコードのバージョニング
MVCCによって、どのようにレコードがバージョン管理されているかを実際の動作を見ながら理解しましょう。ここではTiDBとTiKVの2つのレイヤーで考えます。
TiDB
以下のテーブルを作成し、レコードを追加したとします。
CREATE TABLE IF NOT EXISTS student (id BIGINT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(16) UNIQUE KEY, age INT, score INT, INDEX idx_age (age));
INSERT INTO student SET name='bob', age=12, score=99;
TiDBで追加されたレコードは以下のようにKVに変換されます[1]。
# Primary Key/Unique Index
Key: t{tableID}_i{indexID}_indexedColumnsValue
Value: RowID
# Non-Unique Index
Key: t{TableID}_i{IndexID}_indexedColumnsValue_{RowID}
Value: null
今回の場合だと、テーブルIDは以下となります。
> SELECT TIDB_TABLE_ID FROM information_schema.tables WHERE TABLE_NAME = 'student';
+---------------+
| TIDB_TABLE_ID |
+---------------+
| 104 |
+---------------+
1 row in set (0.01 sec)
インデックスIDは以下となります。
> SELECT INDEX_ID, COLUMN_NAME FROM information_schema.TIDB_INDEXES WHERE TABLE_NAME = 'student';
+----------+-------------+
| INDEX_ID | COLUMN_NAME |
+----------+-------------+
| 0 | id |
| 1 | age |
| 2 | name |
+----------+-------------+
3 rows in set (0.01 sec)
テーブルにINTのPKがある場合、Non-Unique IndexのKeyに付与されるRowIDはPKの値となります。
以上のことから、上記の変換後KVは具体的には以下のようになります。
- primary_index:
{t104_i0_1: 1}- レコード:
{t104_r1: (bob, 12, 99)}
- レコード:
- name(unique):
{t104_i1_bob: 1} - age(non-unique):
{t104_i2_12_1}
このように変換されたKVがTiKVへgRPCコールにより送られます。
TiKV
TiKVはTiDBから送られてきたKVをraftstoreに書き込みます。この動作を理解するために、最初にTiKVの基本的な読み書きの動作を簡単に説明します。
基本動作
TiKVの書き込みはGoogle Percolatorの2 Phase Commit (2PC)に基づいて実装されています。説明を簡単にするために、例に用いるKVは簡略化していますが、2PCは概ねこのように動作します。
- Prewrite
- Lock CF(CFとはColumn Familiesのこと)に書き込んで、ロックを取る
- Default CFに実データを書き込む
- KeyにはPDから発行される
startTSが含まれる
- KeyにはPDから発行される
- Commit
- Prewriteが成功したらCommitへ進む
- Write CFに
commitTSをKeyに、startTSをValueにして書き込む - Lock CFに書き込んだロックを削除する
上記の動作より、各CFは以下の役割を持つことがわかります。
- Lock CF: データの一貫性(Consistency)を保証するためのロック
- Default CF: 実データを保持する
- Write CF:
commitTSをKey、startTSをValueに持つ。- Default CFは
startTSをKeyに持つので、最新のWrite CFを見れば最新のDefault CFを見つけることができる。
- Default CFは
各CFの役割を踏まえて、次に読み込みの動作を簡単に説明します。
- 読み込み開始時に
startTSと検索対象のリージョン情報ををPDから取得する- TiDBはリージョン情報を元にTiKVへデータの問い合わせを行う。
- Lock CFを見てロックがあれば読み取りを中止する。
- Lock CFにロックがなければ、PDから取得した
startTSを基準にスナップショットを取得して、スナップショットから最新のバージョンを持つKeyをWrite CFから探す- TiDBのデフォルトのtransaction isolationはrepeatable readであり、TiDBはそれをsnapshot isolationとして実装している
- 最新バージョンのKeyを持つWrite CFを見つけたら、Valueを見て
startTSを取得する。 - 取得した
startTSと同じTSOを持つDefault CFを見つける。
以下に具体例を示します。
- Keyが"A"のエントリーを検索する。PDからは
startTSとして100を得る(リージョン情報については割愛) - Lock CFにロックが無いことを確認してWrite CFを検索する。以下のWrite CFが見つかったとする。
- Write CF:
{A_90: 80} - 対応するValueが
80なので、最新のDefault CFが持つTSOは80ということになる。
- Write CF:
- Keyに
A_80を持つDefault CFを探す。- Default CF:
{A_80: 'itemABC'}
- Default CF:
以上がTiKVの基本的な読み書きの動作です。実際にはもっと複雑に動作していますが、大まかな理解としては上記で十分でしょう。
MVCCでの書き込み
ここまでに説明した動作を踏まえて、上から順にクエリが実行されたとします。
-- txn1
INSERT INTO student SET name='bob', age=12, score=99;
-- txn2
UPDATE student SET name='alice' WHERE id = 1;
-- txn3
DELETE student WHERE id = 1;
3つのCF(Lock, Default)はそれぞれ以下のように変遷します。KVのKeyはkとします。
| Txn | 2PC | TSO (from PD) |
Lock CF (delete when committed) |
Default CF | Write CF |
|---|---|---|---|---|---|
| 1 | prewrite | tso1 | {k:(tso1, PUT, ...)} | {k_tso1: ('bob',...)} | |
| commit | tso2 | {k_tso2: tso1, PUT} | |||
| 2 | prewrite | tso3 | {k:(tso3, PUT, ...)} | {k_tso3: ('alice',...)} | |
| commit | tso4 | {k_tso4: tso3, PUT} | |||
| 3 | prewrite | tso5 | {k:(tso5, DEL, ...)} | ||
| commit | tso6 | {k_tso6: tso5, DEL} |
見ての通り、MVCCでは削除されたレコードもバージョン管理されており、TiDBのレイヤーでは削除されたレコードは見えませんが、ストレージのレイヤー、つまりraftstoreのレイヤーではデータは残っています。レコードは追加や変更を重ねるごとにバージョンも増えていくため、物理的にデータ容量を圧迫していきます。古いバージョンを残したままでは読み書きに影響が出るため、GCによって古いバージョンを回収してデータ領域を解放していく必要があります。
次のセクションでは、バージョンが増えることで起きる問題のトラブルシュートについて解説します。
蓄積されたバージョンのトラブルシュート
ここではMVCCによって蓄積されたバージョンが引き起こす問題をどのように対処すれば良いかを記載します。
どのように解消するか
最初に、蓄積されたバージョンを減らす方法を提示します。2つの方法があります。この記事ではそれぞれの解説を割愛しますので、詳細はリンク先を参照してください。
- tikv-ctlを利用して、手動でcompactionを実行する。
- GCのcompaction filterを無効化する
- GC in Compaction Filter
- compaction filterを有効にしていてもGCは当然に機能しますが、無効化することで、よりアグレッシブに古いバージョンを削除するようになります。
どちらを選んでも、GCによって最終的には古いバージョンが削除されてデータ領域が解放されるという点は変わりません。
どのように分析し、判断するか
compactionを実行すべきか、あるいはcompaction filterを無効化すべきかを判断するには、実際のワークロードやインスタンススペック、そしてメトリクスなど様々な要素を分析して判断する必要があります。ここでは、トラブルシュートのためにどのメトリクスを見るべきか、そしてそれらのメトリクスをどこで見ることができるのかを以下の3つの方法で解説します。
- スロークエリから見つける
- Grafanaから見つける
- Region単位で見つける
スロークエリから見つける
スロークエリのログないしはEXPLAIN ANALYZEの実行結果から、以下のログを見つけることができます。
scan_detail: {total_process_keys: 38458, total_process_keys_size: 10136914, total_keys: 191568, get_snapshot_time...,rocksdb: {delete_skipped_count: 4633036, key_skipped_count: 1823929, block:...
上記のログに含まれる情報のうち、total_process_keysとtotal_keysに注目しましょう。
- total_keys: TiKVによってスキャンされたKeyの数の合計
- total_process_keys: 実際に処理されたKeyの数の合計。
total_keysは古いバージョンを含むが、total_process_keysは古いバージョンを含まない。
total_keysとtotal_process_keysの割合(total_keys/total_process_keys)を計算することで、おおよその平均バージョン数を類推することができます。今回の場合だと、191568/38458≒4.98となるため、各Keyはおおよそ5バージョン保持していることになります。バージョン数だけを見て、蓄積が多すぎるかどうかは判断できませんが、処理が遅く、平均バージョン数が多い場合は対処したほうが良いでしょう。
関連して、以下のメトリクスにも注目します。これらはRocksDBに関連するメトリクスです。
- delete_skipped_count: RocksDBが読み込んだKeyのうち、削除マーカーが付いたKeyの数の合計。
-
key_skipped_count: RocksDBが
Next()などのイテレーションの中で様々な理由によりスキップしたKeyの数。イテレーションの中で、ほしいKeyが見つかるまでスキップを繰り返すので、概ね読み取り量とみなすことができる。
delete_skipped_countが大きい場合、RocksDBをcompactionしたほうが良いでしょう。key_skipped_countが増えると、読み取りのコストも高くなることを示します。
これらのメトリクスがレコードの追加、更新、削除によってどのように変わるかを見ていきます。
UPDATE student SET name = 'alice' WHERE id = 1;
DELETE student FROM WHERE id = 1;
INSERT INTO student SET name = 'chris', age = 15, score = 100;
まず、テーブルを作成します。
CREATE TABLE IF NOT EXISTS student (id BIGINT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(16) UNIQUE KEY, age INT, score INT, INDEX idx_age (age));
各種メトリクスを見るためにEXPLAIN ANALYZE SELECT * FROM studentを実行します。出力された実行計画を省略していますが、このクエリではテーブルフルスキャンが発生しているため、対象テーブルの全てのレコードにアクセスしています。なお、以降に出てくるメトリクスは全てこのクエリを使って出力されたものです。
| Step | total_keys | total_process_keys | delete_skipped_count | key_skipped_count |
|---|---|---|---|---|
| CREATE TABLE | 1 | 0 | 0 | 0 |
CREATE TABLE直後にSELECTを行った場合、total_process_keysはゼロになる。これは空テーブルであり、処理されたKeyが存在しないため。データが存在しないため、RocksDB関連のメトリクスも当然ゼロになります。total_keysが1になっているのは、条件を満たすバージョンが存在しないことを確かめるために別テーブルのKeyを参照したからです。
次にデータを1行追加します。
BEGIN; INSERT INTO student SET name='bob', age=12, score=99; COMMIT;
各メトリクスは以下の通り。
| Step | total_keys | total_process_keys | delete_skipped_count | key_skipped_count |
|---|---|---|---|---|
| CREATE TABLE | 1 | 0 | 0 | 0 |
| INSERT (id=1) | 2 | 1 | 1 | 1 |
レコードが1行追加されたので、total_process_keysが1になりました。レコード、つまりKeyは1つしかありませんが、それを確認するために2つ目のKeyをみているのでtotal_keysが2になります。トランザクションを利用しているため、RocksDBのレイヤーではLock CFを確認します。トランザクションはcommit済みなのでLock CFはすでに削除されています。この削除されたLock CFをスキップするので、delete_skipped_countが1となります。次にWrite CFを見てから対応するDefault CFを見つけて実データを得ます。レコードが追加された直後なのでLock CF以外はスキップされておらず、key_skipped_countは1となります。
次にレコードを以下のクエリで更新します。
BEGIN; UPDATE student SET name='alice' WHERE id = 1; COMMIT;
各メトリクスは以下の通り。
| Step | total_keys | total_process_keys | delete_skipped_count | key_skipped_count |
|---|---|---|---|---|
| CREATE TABLE | 1 | 0 | 0 | 0 |
| INSERT (id=1) | 2 | 1 | 1 | 1 |
| UPDATE (id=1) | 3 | 1 | 1 | 3 |
レコードが更新されただけなので、total_process_keysは変わらず1のまま。MVCCによって変更前のバージョンが残っているので、変更前のバージョンのKey->変更後のバージョンのKey->別テーブルのKey(これにアクセスしてstudentテーブルを全てスキャンしたことを確認している)の3つのKeyにアクセスしているのでtotal_keysは3となります。
RocksDBのレイヤーでは、削除されたLock CF->変更前のバージョンのKey(Write CF)->変更後のバージョン(Write CF)でスキャンし、最新のcommitTSを見つけます。ここまでの時点でdelete_skipped_countは1となって(削除済みのLock CFをスキップしているので)、key_skipped_countは2(Lock CFのスキップと変更前のバージョンのスキップ)となります。次に、Default CFを見に行きますが、ここでも変更前のバージョンをスキップして変更後のバージョンを見つけるのでkey_skipped_countがさらに1加算されて、合計3となります。
次にDELETEを行う。
BEGIN; DELETE FROM student WHERE id = 1; COMMIT;
各メトリクスは以下の通り。
| Step | total_keys | total_process_keys | delete_skipped_count | key_skipped_count |
|---|---|---|---|---|
| CREATE TABLE | 1 | 0 | 0 | 0 |
| INSERT (id=1) | 2 | 1 | 1 | 1 |
| UPDATE (id=1) | 3 | 1 | 1 | 3 |
| DELETE (id=1) | 4 | 0 | 1 | 5 |
DELETEによりテーブルのデータが無くなったのでtotal_process_keysはゼロになります。一方で、MVCCによりid=1のバージョンは1つ増えたのでtotal_keysは4となります。DELETEを実行してもRocksDBのレイヤーでは削除されていないので、deleted_skipped_countは1のままです。MVCCのバージョンが1つ増えると、削除前のバージョンの数(ここでは2つ)だけkey_skipped_countが増えるので、前回から2加算して5となります。
最後に、新規にレコードを追加してみます。
BEGIN; INSERT INTO student SET name = 'chris', age = 15, score = 100; COMMIT;
各メトリクスは以下の通り。改めてEXPLAIN ANALYZE SELECT * FROM studentを実行している、つまりテーブルフルスキャンが行われていることを思い出してください。
| Step | total_keys | total_process_keys | delete_skipped_count | key_skipped_count |
|---|---|---|---|---|
| CREATE TABLE | 1 | 0 | 0 | 0 |
| INSERT (id=1) | 2 | 1 | 1 | 1 |
| UPDATE (id=1) | 3 | 1 | 1 | 3 |
| DELETE (id=1) | 4 | 0 | 1 | 5 |
| INSERT (id=2) | 5 | 1 | 2 | 6 |
新たにレコードを作成したことで、total_process_keysは1となります。同様にid=2のバージョンが追加されたのでtotal_keysに1加算されて5となります。id=1とid=2はそれぞれ異なるロックで管理されている、つまり新たにLock CFが追加されており、その後id=2のINSERT処理のcommitによって、削除されたのでdelete_skipped_countは2となります。新規に追加されたレコードには古いバージョンがありません。よって、新たにスキップされるKeyはid=2のLock CFの1つのみであるため、key_skipped_countは1加算されて6となります。
Grafanaから見つける
スロークエリからMVCCによる影響を調べてわかるのは、当然ながらそのクエリの中で使われているテーブルに限定されます。クラスタ全体のtotal_keysなどのメトリクスは、オンプレミスやPlaygroundのTiDBに付属するGrafanaのダッシュボードから見ることができます。
- TiKV Details > Coprocessor Detail > Total Ops Details (Table Scan) / Total Ops Details (Index Scan)
例えばTotal Ops Details (Table Scan)の場合は以下のようなチャートを見ることができます。
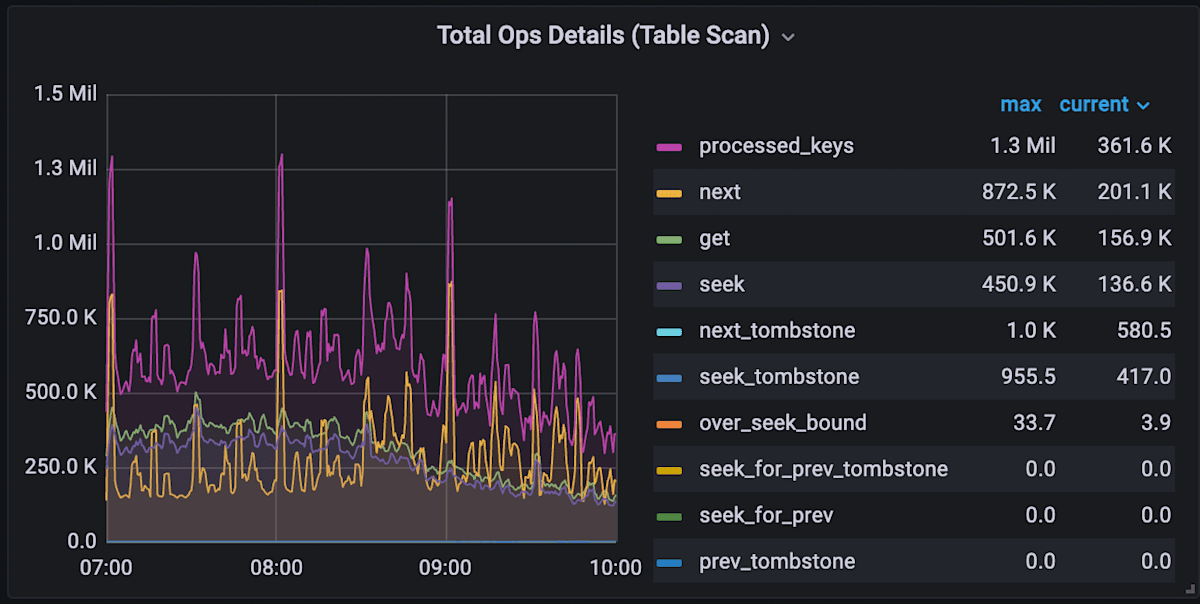
チャートの項目は以下のとおりです。
- processed_keys: スロークエリの中の
total_process_keysと同じ。実際に処理されたKeyの数。 - next/get/seekなど: Keyをスキャンする際にTiKVから呼び出された命令。これらの合計がスロークエリの
total_keysと近似する。
このチャートの場合、processed_keysが1.3Mであるのに対し、nextなどがおおよそ1.82M(≒872.5K+501.6K+450.9K+...)であるため、それほどバージョンが蓄積されていないことになります。もしprocessed_keysの数がnextなどの合計値を大きく下回る場合は、バージョンの蓄積による性能影響が考えられます。
RocksDBレイヤーのメトリクスであるdelete_skipped_countは以下のパネルで確認できます。
- TiKV Details > Coprocessor Overview > Total RocksDB Perf Statistics
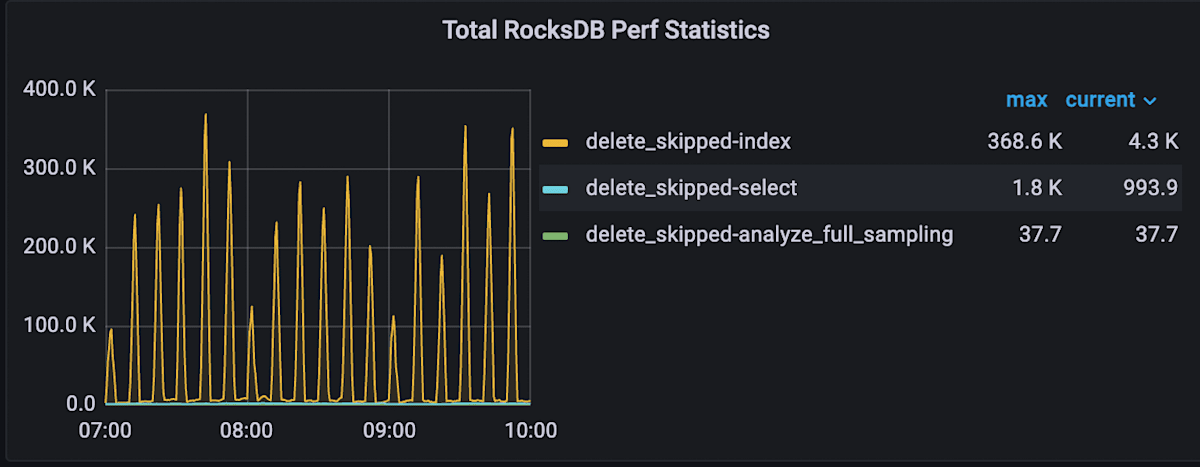
このチャートからはTiKVクラスタ全体でどの程度削除されたKeyがスキャンされたかを知ることができます。
リージョン単位で見つける
通常はここまですることは無いかもしれないですが、リージョン単位でも調べることができます。この方法はオンプレミスやPlaygroundなど、tikv-ctlが利用できる場合に限られます。
リージョン単位で確認する必要があるのはどのような時でしょうか。代表的な例として、ホットスポットが発生した場合が挙げられます。ホットスポットの発生状況はKey Visualizerから以下のように確認できます。
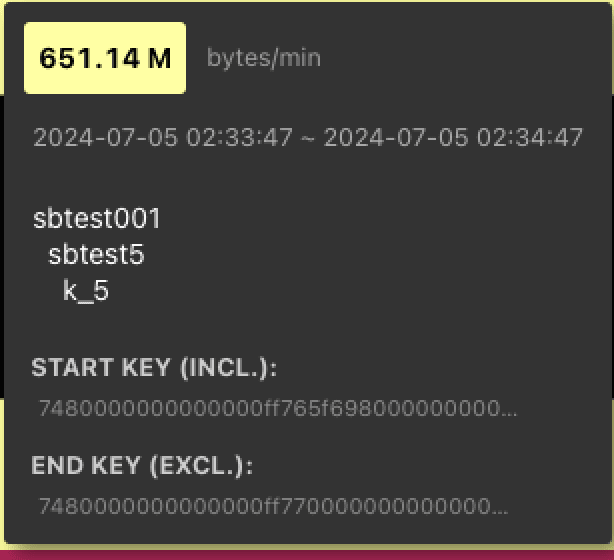
この情報からホットスポットが発生しているKeyの範囲を知ることができる。Keyの範囲を確認したら、以下のコマンドで該当するリージョンを特定することができます。tikv-ctlの使い方はドキュメントを参照してください。
$ tiup ctl:v8.1.0 tikv --host 127.0.0.1:20160 raft region --start 7480000000000000ff765f698000000000ff0000010380000000ff000138c303800000ff0000014035000000fd --end 7480000000000000ff7700000000000000f8
...
{
"region_infos": {
"128": {
"region_id": 128,
...
},
"142": {
"region_id": 142,
...
}
}
}
この出力結果からホットスポットはIDが128と142のリージョンから発生していることがわかります。次に以下のコマンドでリージョンの詳細情報を調べます。
$ tiup ctl:v8.1.0 tikv --host 127.0.0.1:20160 region-properties -r 128
Starting component `ctl`: /Users/shige/.tiup/components/ctl/v8.1.0/ctl tikv --host 127.0.0.1:20160 region-properties -r 128
mvcc.min_ts: 450916222206214149
mvcc.max_ts: 450917640705671184
mvcc.num_rows: 292142
mvcc.num_puts: 369916
mvcc.num_deletes: 94460
mvcc.num_versions: 464386
mvcc.max_row_versions: 138
writecf.num_entries: 464386
writecf.num_deletes: 0
writecf.num_files: 1
writecf.sst_files: 000364.sst
defaultcf.num_entries: 11912
defaultcf.num_files: 1
defaultcf.sst_files: 000359.sst
region.start_key: 7480000000000000ff765f698000000000ff0000010380000000ff000138c303800000ff0000014035000000fd
region.end_key: 7480000000000000ff7700000000000000f8
region.middle_key_by_approximate_size: 7480000000000000ff765f728000000000ff00c4570000000000faf9be04e3d43ffff0
ここではmvcc.のプレフィックスを持つメトリクスに絞って解説します。それぞれの項目は以下の通りです(参考)。
- mvcc.min_ts: リージョン内で最も小さい(古い)タイムスタンプ(TSO)
- mvcc.max_ts: リージョン内で最も大きい(新しい)タイムスタンプ(TSO)
- mvcc.num_rows: リージョン内にあるレコードの数。
- mvcc.num_puts: リージョン内にあるMVCCのPUTがされたバージョンの数
- mvcc.num_deletes: リージョン内にあるMVCCのDELETEがされたバージョンの数
- mvcc.num_versions: リージョン内にある全バージョンの数
- mvcc.max_row_versions: リージョン内にあるレコードの中で最も大きなバージョン数
これらの情報を見て、対象リージョンに対してcompactionを行うかどうかを検討することができます。
まとめ
この記事では、以下の事柄を確認しました。
- TiKVはMVCCにより1つのデータに対して複数のバージョンを持つ
- バージョンが蓄積されると読み書きの性能に影響が出る
- 古いバージョンはGC(compaction)を手動で行うことで減らすことができる。あるいはGCの設定値を変更することでアグレッシブに減らすことができるようになる。
- compactionを行うべきか、設定値を変更すべきかどうかはスロークエリでテーブル単位で、Grafanaを見ることでクラスタ全体、tikv-ctlを利用してリージョン単位で分析することができる。
特に書き込み頻度の多いワークロードをTiDBで扱っている場合は、MVCCによる古いバージョンの蓄積による影響を確認してみると良いでしょう。
Discussion