TiDBでIDを1つずつインクリメントさせたい - AUTO_INCREMENTとSEQUENCE
この記事について
TiDBを採用するケースの多くはMySQLからの移行ですが、TiDBはその高い互換性により、ほとんどのケースにおいて少ない労力で移行することができます。ただし、どうしても避けられない問題がいくつかあり、そのうちの1つ、そしてもっとも多くのユーザーが直面する問題がMySQLとTiDBにおけるAUTO_INCREMENTの挙動の違いです。
この記事ではMySQLとTiDBにおけるAUTO_INCREMENTの違いについて簡単に説明し、違いを埋めるための方策の1つとしてSEQUENCEオブジェクトをご紹介します。詳細は記事本文中に掲載する公式ドキュメントおよび関連ドキュメントをご参照いただくとして、本記事ではSEQUENCEオブジェクトの概要、基本的な使い方とその挙動、SEQUENCEオブジェクトを利用してMySQLのAUTO_INCREMENTと同等のID生成を実現する方法などについて記述します。想定読者として、TiDBの知識は不要ですが、SQLの基本的な文法を理解していることが望まれます。
あらかじめお断りしておくと、SEQUENCEオブジェクトの採用はMySQLと同等のID生成を実現するための完全な解決策となりません。しかし、限られたユースケースではSEQUENCEオブジェクトが有効となる場合がありますので、ぜひ最後まで読み進めていただければと思います。また、本記事では主にSEQUENCEオブジェクトの紹介にとどまりますが、後日、SEQUENCEオブジェクトの性能を検証し、ORMマッパーなどのアプリケーションで利用する場合の注意点などについて触れる予定です。
TiDBにおけるAUTO_INCREMENTの制約
TiDBをご存知でない方に向けて、TiDBにおけるID生成について簡単に説明します。MySQLが基本的に単一サーバーで稼働することを前提としているのに対し、TiDBは分散システムであり、機能別に複数のコンポーネントが複数台で協調しながら稼働します。
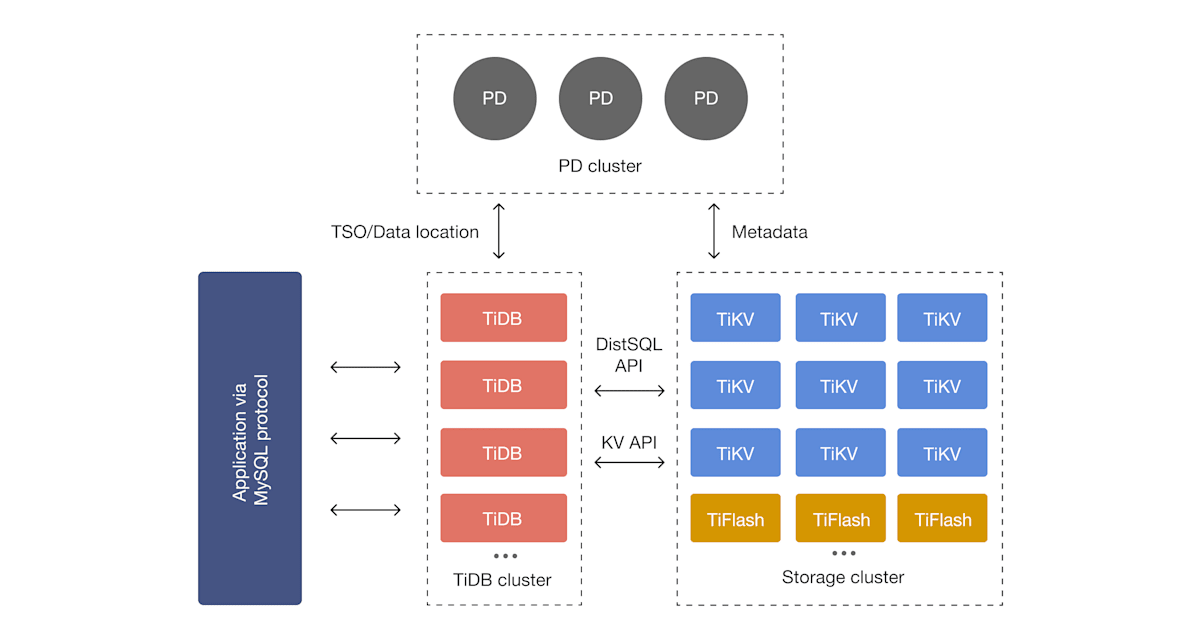
(公式ドキュメント "TiDB Architecture" より転載)
そして、各TiDBノードはIDを迅速に採番するために一定の範囲でIDをキャッシュしています。TiDBノードが複数ある場合、ロードバランサーによりDBクライアントのアクセスは分散するため、TiDBにおけるID自動生成(AUTO_INCREMENT)は各TiDBノードがそれぞれキャッシュしたIDから払い出されます。結果として、例えばTiDBノードがAとBの2台ある場合、IDの増加は、1->2->30001->3->30002...のようになる場合があります。
| アクセスしたTiDBノード | A | A | B | A | B |
|---|---|---|---|---|---|
| 採番されるID | 1 | 2 | 30001 | 3 | 30002 |
このように、MySQLのID自動生成と近い動作を実現することが可能ですが、それもあくまで"近い"であって"同じ"というわけではありません。詳細は公式ドキュメントまたは拙記事TiDBのAUTO_INCREMENTは2種類あるをご参照ください。
ところで、TiDBにおけるID自動生成の方法は、AUTO_INCREMENTだけではありません。単調増加が求められないのであれば、AUTO_RANDOMも選択肢に上がるでしょう。AUTO_RANDOMの場合、一定のルールに従ってIDがランダムに採番されます。AUTO_RANDOMは書き込みが多いワークロードで有効です。そして、実はもう1つ方法があります[1]。それが本記事で紹介するSEQUENCEオブジェクトです。SEQUENCEオブジェクトについてすこし掘り下げてみましょう。
TiDBのSEQUENCEの概要と特徴
TiDBにおけるSEQUENCEオブジェクトはMaridDBでのそれに類似したものです。ほとんどの操作は同じ文法で行うことができます。
SEQUENCEオブジェクトはAUTO_INCREMENTによるID生成と似ていますが、その特徴のいくつかを抜き出すと、以下のとおりです。
- 連続したIDの生成が可能です
- SEQUENCEオブジェクトはあくまでオブジェクトであり、テーブルではなく、列に指定するデータ型や属性でもありません
- IDの生成をカスタマイズして、増分の幅や上限、循環の有無、キャッシュなどを指定できます
次は実際にSEQUENCEオブジェクトを操作して、具体的にどのような操作ができるのか、従来のテーブルに対してどのように利用することができるのかを見ていきましょう。
SEQUENCEの基本的な使い方
基本的な操作を見てみましょう。テーブルを作成するようにSEQUENCEを作成することができます。
-- IF NOT EXISTSが使える
tidb:4000 > CREATE SEQUENCE IF NOT EXISTS seq1;
Query OK, 0 rows affected (0.52 sec)
tidb:4000 > CREATE SEQUENCE IF NOT EXISTS seq1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
Note (Code 1050): Table 'test.seq1' already exists
-- SEQUENCEはテーブルと同様に管理されているのでSHOW TABLESで出てくる
tidb:4000 > SHOW TABLES;
+----------------+
| Tables_in_test |
+----------------+
| seq1 |
+----------------+
1 row in set (0.00 sec)
-- DESCでは確認できない
tidb:4000 > DESC seq1;
Empty set (0.00 sec)
-- デフォルトでは1000までキャッシュし、循環はしない
tidb:4000 > SHOW CREATE SEQUENCE seq1\G
*************************** 1. row ***************************
Sequence: seq1
Create Sequence: CREATE SEQUENCE `seq1` start with 1 minvalue 1 maxvalue 9223372036854775806 increment by 1 cache 1000 nocycle ENGINE=InnoDB
1 row in set (0.00 sec)
SEQUENCEオブジェクトを"参照"または"検索"することはできず、NEXTVALまたはNEXT VALUE FORでクエリするたびにIDが更新されます。
-- 値を参照するというようなことはできない
tidb:4000 > SELECT * FROM seq1;
ERROR 1051 (42S02): Unknown table ''
-- NEXTVALで"次の"値を取得する
tidb:4000 > SELECT NEXTVAL(seq1);
+---------------+
| NEXTVAL(seq1) |
+---------------+
| 1 |
+---------------+
1 row in set (0.01 sec)
tidb:4000 > SELECT NEXTVAL(seq1);
+---------------+
| NEXTVAL(seq1) |
+---------------+
| 2 |
+---------------+
1 row in set (0.00 sec)
-- 以下のような構文も可
tidb:4000 > SELECT NEXT VALUE FOR seq1;
+---------------------+
| NEXT VALUE FOR seq1 |
+---------------------+
| 3 |
+---------------------+
1 row in set (0.01 sec)
-- LASTVALは"現在のセッション"で最後に取得された値を参照する
tidb:4000 > SELECT LASTVAL(seq1);
+---------------+
| LASTVAL(seq1) |
+---------------+
| 2 |
+---------------+
1 row in set (0.00 sec)
tidb:4000 > ^DBye
... (再ログイン)
-- セッションが変わったのでLASTVALでは値を参照できず、NULLが返る
tidb:4000 > SELECT LASTVAL(seq1);
+---------------+
| LASTVAL(seq1) |
+---------------+
| NULL |
+---------------+
1 row in set (0.00 sec)
-- SETVALで値を更新する
tidb:4000 > SELECT SETVAL(seq1, 100);
+-------------------+
| SETVAL(seq1, 100) |
+-------------------+
| 100 |
+-------------------+
1 row in set (0.00 sec)
tidb:4000 > SELECT NEXTVAL(seq1);
+---------------+
| NEXTVAL(seq1) |
+---------------+
| 101 |
+---------------+
1 row in set (0.00 sec)
SEQUENCEオブジェクトではID生成の仕方をカスタマイズすることができます。一定の範囲で値を循環させることができるので、IDだけでなく、例えば所定の範囲の係数を順に割り当てるなどのような使い方もできます。アプリケーション側でこのような連続したID生成の仕組みを実装するのはなかなか骨が折れると思いますが、SEQUENCEオブジェクトを使うと容易に実装することが可能です。
-- インクリメントをカスタマイズ
---- 3から、2ずつ増える、最小値は1、最大10、値を3つキャッシュ、循環する
tidb:4000 > CREATE SEQUENCE seq2 START 3 INCREMENT 2 MINVALUE 1 MAXVALUE 10 CACHE 3 CYCLE;
Query OK, 0 rows affected (0.52 sec)
tidb:4000 > SELECT NEXTVAL(seq2);
+---------------+
| NEXTVAL(seq2) |
+---------------+
| 3 |
+---------------+
1 row in set (0.01 sec)
tidb:4000 > SELECT NEXTVAL(seq2);
+---------------+
| NEXTVAL(seq2) |
+---------------+
| 5 |
+---------------+
1 row in set (0.00 sec)
tidb:4000 > SELECT NEXTVAL(seq2);
+---------------+
| NEXTVAL(seq2) |
+---------------+
| 7 |
+---------------+
1 row in set (0.00 sec)
tidb:4000 > SELECT NEXTVAL(seq2);
+---------------+
| NEXTVAL(seq2) |
+---------------+
| 9 |
+---------------+
1 row in set (0.01 sec)
-- 一巡すると最小値から始まる
tidb:4000 > SELECT NEXTVAL(seq2);
+---------------+
| NEXTVAL(seq2) |
+---------------+
| 1 |
+---------------+
1 row in set (0.01 sec)
tidb:4000 > SELECT NEXTVAL(seq2);
+---------------+
| NEXTVAL(seq2) |
+---------------+
| 3 |
+---------------+
1 row in set (0.00 sec)
tidb:4000 > SELECT NEXTVAL(seq2);
+---------------+
| NEXTVAL(seq2) |
+---------------+
| 5 |
+---------------+
1 row in set (0.00 sec)
次に、SEQUENCEオブジェクトをテーブルに組み込んでみます。
-- 新規SEQUENCEオブジェクトを生成する
tidb:4000 > CREATE SEQUENCE IF NOT EXISTS seq1;
Query OK, 0 rows affected (0.13 sec)
-- 作成したSEQUENCEオブジェクトをid列に指定する
tidb:4000 > CREATE TABLE t (id BIGINT PRIMARY KEY DEFAULT NEXT VALUE FOR seq1);
Query OK, 0 rows affected (0.11 sec)
tidb:4000 > INSERT INTO t VALUES(); INSERT INTO t VALUES(); INSERT INTO t VALUES();
Query OK, 1 row affected (0.01 sec)
Query OK, 1 row affected (0.00 sec)
Query OK, 1 row affected (0.00 sec)
-- id列に想定通りの値が挿入されている
tidb:4000 > SELECT * FROM t;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
+----+
3 rows in set (0.01 sec)
-- id列に付与したSEQUENCEオブジェクトには引き続きクエリ可能
tidb:4000 > SELECT NEXTVAL(seq1);
+---------------+
| NEXTVAL(seq1) |
+---------------+
| 4 |
+---------------+
1 row in set (0.00 sec)
tidb:4000 > INSERT INTO t VALUES();
Query OK, 1 row affected (0.00 sec)
-- 付与したSEQUENCEオブジェクトは先程のクエリでインクリメントされたので
-- 払い出されるIDはその次の値となる
tidb:4000 > SELECT * FROM t;
+---+
| a |
+---+
| 1 |
| 2 |
| 3 |
| 5 |
+---+
4 rows in set (0.01 sec)
-- SEQUENCEオブジェクトを参照しているテーブルを再作成する
tidb:4000 > TRUNCATE TABLE t;
Query OK, 0 rows affected (0.11 sec)
tidb:4000 > INSERT INTO t VALUES(); INSERT INTO t VALUES(); INSERT INTO t VALUES();
Query OK, 1 row affected (0.00 sec)
Query OK, 1 row affected (0.00 sec)
Query OK, 1 row affected (0.01 sec)
-- 生成されるIDはリフレッシュされず、続きの番号が付与される
-- つまり、SEQUENCEオブジェクトは参照元テーブルの影響を受けない
tidb:4000 > SELECT * FROM t;
+----+
| id |
+----+
| 6 |
| 7 |
| 8 |
+----+
3 rows in set (0.00 sec)
-- テーブル作成時には存在しないSEQUENCEオブジェクトを指定可能だが
tidb:4000 > CREATE TABLE t2 (id BIGINT PRIMARY KEY DEFAULT NEXT VALUE FOR seq2);
Query OK, 0 rows affected (0.10 sec)
-- 値を挿入時にエラーが起きる
tidb:4000 > INSERT INTO t2 VALUES();
ERROR 1146 (42S02): Table 'test.seq2' doesn't exist
-- SEQUENCEオブジェクトの利用は排他的ではない
tidb:4000 > CREATE TABLE t3 (id BIGINT PRIMARY KEY DEFAULT NEXT VALUE FOR seq1);
Query OK, 0 rows affected (0.09 sec)
tidb:4000 > INSERT INTO t3 VALUES();
Query OK, 1 row affected (0.00 sec)
-- seq1から続きの番号が払い出される
tidb:4000 > SELECT * FROM t3;
+----+
| id |
+----+
| 9 |
+----+
1 row in set (0.00 sec)
この例からわかることはSEQUENCEオブジェクトは独立したオブジェクトであり、参照元となるテーブルに従属しているわけではないということです。この点は運用上の注意が必要です。
SEQUENCEで連番を正確に採番する方法
SEQUENCEオブジェクトの基本を確認できたので、本題に入りましょう。SEQUENCEオブジェクトを使ってMySQLと同等のID生成を実現するにはどうすれば良いでしょうか。結論としては、以下のようにNO CACHEを指定してSEQUENCEを作成することで実現可能です。
tidb:4000 > CREATE SEQUENCE IF NOT EXISTS seq NO CACHE;
Query OK, 0 rows affected (0.11 sec)
tidb:4000 > SHOW CREATE SEQUENCE seq\G
*************************** 1. row ***************************
Sequence: seq
Create Sequence: CREATE SEQUENCE `seq` start with 1 minvalue 1 maxvalue 9223372036854775806 increment by 1 nocache nocycle ENGINE=InnoDB
1 row in set (0.00 sec)
NO CACHEをつけることで連番がキャッシュされず、常に1つずつ採番されるようになります。キャッシュする場合、デフォルトでは各TiDBノードで1,000ずつキャッシュします。デフォルトではAUTO_INCREMENTと同じような動作になるのですが、NO CACHEによってSEQUENCEオブジェクトがTiDBノードでIDをキャッシュしなくなることで、TiDBノードが部分的に利用できなくなっても、あるいはスケールアウトにより追加されたとしても、どこで採番されても必ず連続したIDとなります。
AUTO_ID_CACHE 1 との違い
ここで改めてAUTO_ID_CACHE 1との違いを確認しましょう。AUTO_ID_CACHE 1は公式ドキュメントではMySQL compatibility modeと呼ばれていますが、実際には必ずしも"互換"であるとは言えない部分があります。
AUTO_ID_CACHE 1にすると、各TiDBノード内でIDをキャッシュしなくなり、代わりにTiDBノードの中からリーダーノードが選ばれて、そのノードからIDが払い出されます。リーダーノードだけがIDを払い出すことで確実に1つずつインクリメントされることが保証されます。これにより、MySQLのAUTO_INCREMENTとほぼ同じ動作をするようになります。
ところで、リーダーノードは迅速な払い出しのために一定の範囲でIDをキャッシュしています。リーダーノードがダウンしたり別ノードにリーダーを交代などすると、リーダーノード内にキャッシュされていたIDが利用できなくなって番号がジャンプする場合があります[2]。リーダーノードがダウンしたり交代するというのはあまり起こらないことですが、クラスタのバージョンアップやノードのスケールインなど避けることができない事態もあるため、このような仕様を念頭に置いて設計や運用を行う必要があります。
一方、SEQUENCEオブジェクトの場合、NO CACHEを設定すれば、上記のような問題を回避して、常にIDが1つずつインクリメントすることを期待できます。ただし、NO CACHEという設定から想像できるように、IDがキャッシュされていないので当然IDの払い出しにはそれなりにオーバーヘッドが発生しそうなことが想像できます。また、ORMとの相性はどうでしょうか。SEQUENCEオブジェクトに対応したORMはあまり多くはなさそうです。後日の記事ではSEQUENCEオブジェクトの性能やアプリケーション開発における利便性について見ていきたいと思います。
まとめ
本記事ではTiDBにおけるSEQUENCEオブジェクトの基本的な説明を行い、AUTO_INCREMENT、特にAUTO_ID_CACHE 1の場合との違いについて説明しました。下にこれまで触れた内容に多少追加してまとめます。
| 方式 | 採番の特性 | IDの連続性 | 高可用性時の動作 | 性能への影響 |
|---|---|---|---|---|
| AUTO_INCREMENT (デフォルト) | 各ノードごとにキャッシュして採番 | ×(ジャンプあり) | ノードごとに異なるID範囲 | 高速だが順序は不定 |
| AUTO_ID_CACHE = 1 | リーダーノードで採番集中管理 | △(基本連続だがズレる場合あり) | リーダー切り替え時にギャップが発生することも | やや遅延増 |
| SEQUENCE NO CACHE | 毎回1つずつ生成 | ◎(完全に連続) | ノードや障害に関係なく一貫 | 最も遅くなる可能性あり |
MySQLと完全に同等の動作を実現することは難しいですが、目的に応じてSEQUENCEを選択肢にいれることで設計の自由度が高くなります。MySQLからTiDBへ移行する際に無視できないAUTO_INCREMENTの課題を解決する参考になれば幸いです。
-
公式ドキュメントではTiDBの機能に依らないユニークなID生成の方法も紹介しています https://docs.pingcap.com/tidb/stable/dev-guide-unique-serial-number-generation/ ↩︎
-
これはv8.1.0以降の場合です。v8.1.0以前の場合はrebase処理によってなるべくIDがジャンプする幅を小さくしようとしますが、
AUTO_ID_CACHE 1のテーブルが多数ある場合に問題になる場合があります。詳細はドキュメントを参照ください。 ↩︎
Discussion