【Amazon Forecast】AWSの基礎を学ぼう


概要
「AWSの基礎を学ぼう」で”Amazon Forecast”のおさらいに参加した感想です。
「AWS エバンジェリストシリーズ AWSの基礎を学ぼう」とは
以下、Connpassページより引用
Amazon Web Services (AWS)は現在200を超えるサービスを提供し、日々サービスの拡充を続けています。
このAWS エバンンジェリストシリーズでは週次でAWSのサービスをひとつづつ取り上げながらその基礎を説明していく 初心者、中級者をターゲットとした講座です。午後の仕事前にスキルアップを一緒にしませんか?
注意点 登壇者による発表内容はアマゾン ウェブ サービス ジャパンとして主催しているものではなく、コミュニティ活動の一環として勉強会の主催を行っているものです。
毎週ありがとうございます!
Amazon Forecastとは?
機械学習を使用して精度の高い予測を行うフルマネージド型のサービスです。
Amazon.com と同じテクノロジーをベースとし、機械学習を使って時系列データを付加的な変数に結びつけて予測を立てます。Amazon Forecast を使用する際に、機械学習の経験は必要ありません。必要なのは過去のデータと、予測に影響を与える可能性があるその他の追加データだけです。たとえば、シャツの特定のカラーの需要は、季節や店舗の所在地によって変わることがあります。こうした複雑な関係性は、過去のデータのみに基づいて判断することは困難で、それを認識することに理想的に適しているのが機械学習です。Amazon Forecast は、ユーザーがデータを提供すると、それを自動的に精査し、何が重要かを識別して、予測を立てるための予測モデルを作成します。このモデルの精度は、時系列データのみに基づく場合と比べ、最大で 50% 高くなります。
AWS News Blogに上がっているデータでやってみる
元ネタ
AWS News Blog - Amazon Forecast – Now Generally Available
今回のデータの抜粋
1分単位と中々細かい
| カラムID | カラム和訳 | 値1 | 値2 |
|---|---|---|---|
| Date | 日付 | 16/12/2006 | 16/12/2006 |
| Time | 時間 | 17:24:00 | 17:25:00 |
| Global_active_power | 有効電力 | 4.216 | 5.360 |
| Global_reactive_power | 無効電力 | 0.418 | 0.436 |
| Voltage | 電圧 | 234.840 | 233.630 |
| Global_intensity | 強度 | 18.400 | 23.000 |
| Sub_metering_1 | サブメーター1 | 0.000 | 0.000 |
| Sub_metering_2 | サブメーター2 | 1.000 | 1.000 |
| Sub_metering_3 | サブメーター3 | 17.000 | 16.000 |
Create dataset group
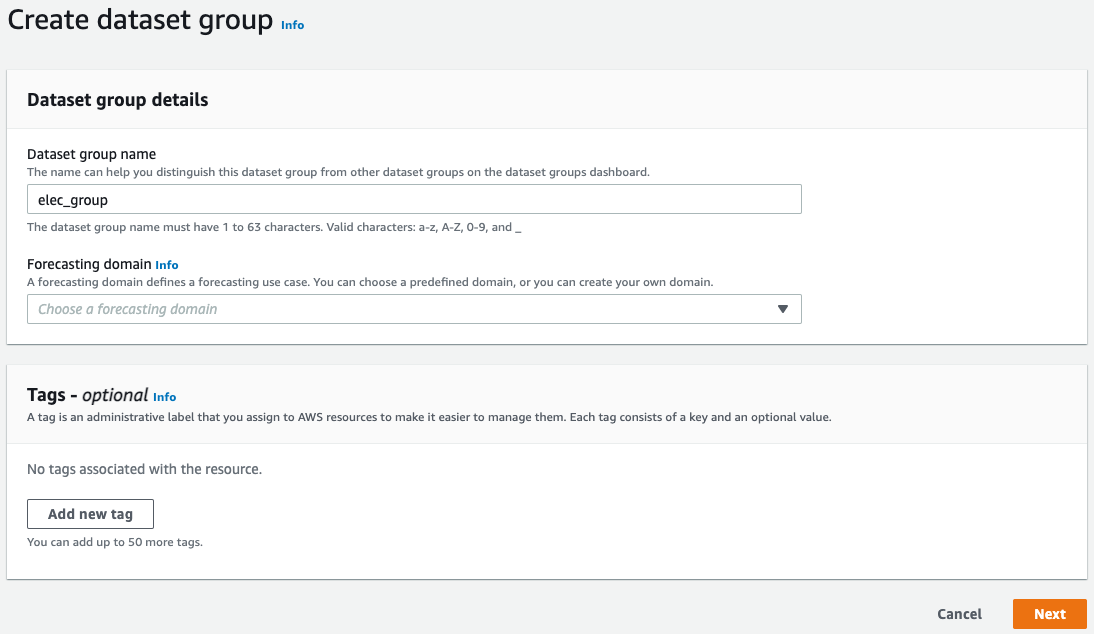
Dataset group
予測を行うためのデータセット・データセット群。予測対象の時系列データ、マッピング定義であるスキーマを用意し、Amazon Forecastに読み込み、学習を行う。データセットは、メインの時系列データ、関連する時系列データ、メタデータ3種類からなる。各種データセットはデータセットグループでまとめることが出来る。
Forecasting domain
| データセットドメイン | 説明 |
|---|---|
| RETAIL ドメイン— | 小売の需要予測 |
| INVENTORY_PLANNING ドメイン | サプライチェーンとインベントリの計画 |
| EC2 CAPACITY ドメイン | Amazon Elastic Compute Cloud (Amazon EC2) のキャパシティを予測 |
| WORK_FORCE ドメイン | ワークフォースプランニング |
| WEB_TRAFFIC ドメイン | 今後のウェブトラフィックの見積もり |
| METRICS ドメイン | 収益およびキャッシュフローなどの予測メトリクス |
| CUSTOM ドメイン | その他すべての時系列予測のタイプ |
Create target time series dataset
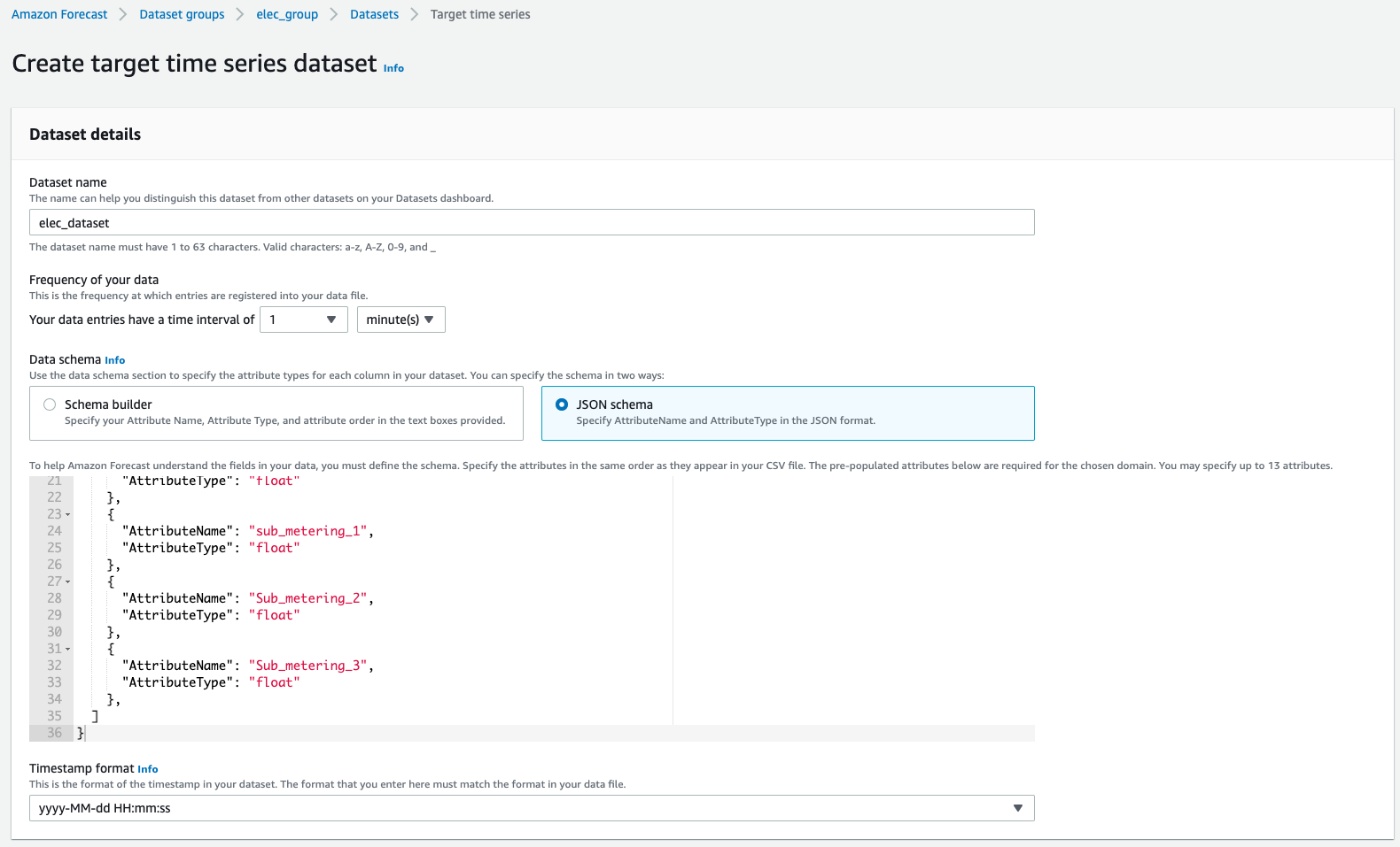
Dataset
Dataset groupと同じ説明になるので割愛
Frequency of your data
Blogでは1時間単位になっているけど1分単位にしてみる。独自性を出して失敗するぱてぃーん
Data schema
GUIかJSONのどちらかでDatasetの定義を実施する
今回は以下で定義。なお元データは日付と時間が分かれていたので頑張ってyyyy-MM-dd HH:mi:ss形式に変換
{
"Attributes": [
{
"AttributeName": "timestamp",
"AttributeType": "timestamp"
},
{
"AttributeName": "global_active_power",
"AttributeType": "float"
},
{
"AttributeName": "global_reactive_power",
"AttributeType": "float"
},
{
"AttributeName": "voltage",
"AttributeType": "float"
},
{
"AttributeName": "global_intensity",
"AttributeType": "float"
},
{
"AttributeName": "sub_metering_1",
"AttributeType": "float"
},
{
"AttributeName": "Sub_metering_2",
"AttributeType": "float"
},
{
"AttributeName": "Sub_metering_3",
"AttributeType": "float"
},
]
}
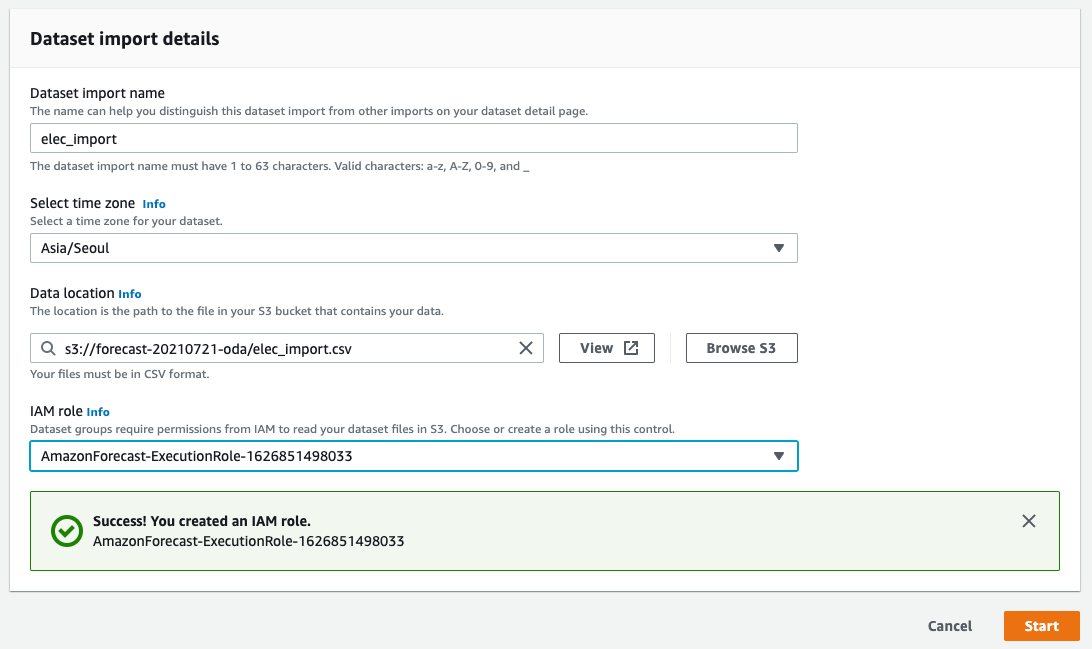
エラー1

なに、Customでもitem_idは必須なのか。
このデータのitem_idってなんや。わからんのでitem1で全部固定にしよう
% head -5 elec_import.csv elec_import.csv2
==> elec_import.csv <==
2006-12-16 17:24:00,4.216,0.418,234.840,18.400,0.000,1.000,17.000
2006-12-16 17:25:00,5.360,0.436,233.630,23.000,0.000,1.000,16.000
2006-12-16 17:26:00,5.374,0.498,233.290,23.000,0.000,2.000,17.000
2006-12-16 17:27:00,5.388,0.502,233.740,23.000,0.000,1.000,17.000
2006-12-16 17:28:00,3.666,0.528,235.680,15.800,0.000,1.000,17.000
==> elec_import.csv2 <==
item1,2006-12-16 17:24:00,4.216,0.418,234.840,18.400,0.000,1.000,17.000
item1,2006-12-16 17:25:00,5.360,0.436,233.630,23.000,0.000,1.000,16.000
item1,2006-12-16 17:26:00,5.374,0.498,233.290,23.000,0.000,2.000,17.000
item1,2006-12-16 17:27:00,5.388,0.502,233.740,23.000,0.000,1.000,17.000
item1,2006-12-16 17:28:00,3.666,0.528,235.680,15.800,0.000,1.000,17.000
エラー2

target_valueはまぁ言われるかなと思った。global_active_powerをtarget_valueに切り替え。
エラー3
予約語以外はstring型ですよ。とのお知らせ。
勉強会の資料には書いてあるので、ここで身になることを実感。
データの持ち方を1時間軸で複数の電気情報を横に持っていたけど、item_idを切り替えて縦に持たないとダメなのかな。
ちとメンドイので残念ですが、floatからstringに切り替え
結果のスキーマ情報
{
"Attributes": [
{
"AttributeName": "item_id",
"AttributeType": "string"
},
{
"AttributeName": "timestamp",
"AttributeType": "timestamp"
},
{
"AttributeName": "target_value",
"AttributeType": "float"
},
{
"AttributeName": "global_reactive_power",
"AttributeType": "string"
},
{
"AttributeName": "voltage",
"AttributeType": "string"
},
{
"AttributeName": "global_intensity",
"AttributeType": "string"
},
{
"AttributeName": "sub_metering_1",
"AttributeType": "string"
},
{
"AttributeName": "Sub_metering_2",
"AttributeType": "string"
},
{
"AttributeName": "Sub_metering_3",
"AttributeType": "string"
}
]
}
Train predictor
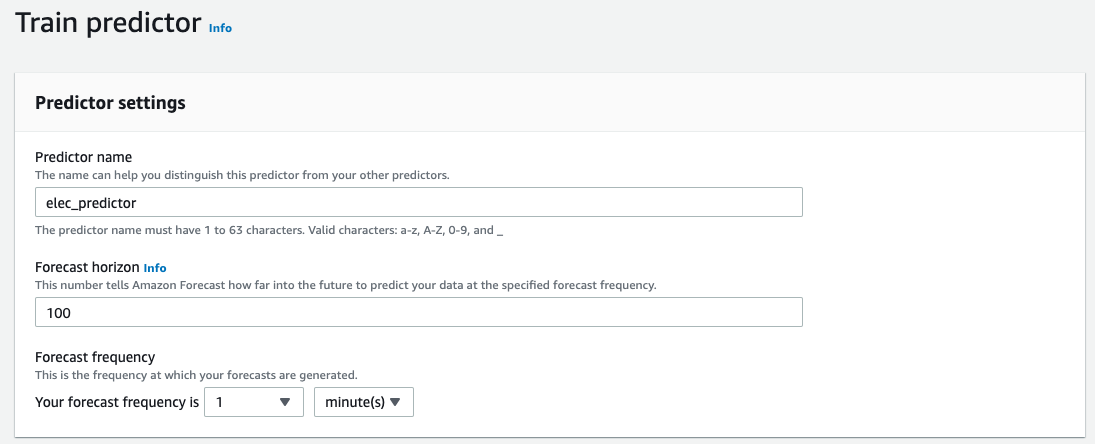
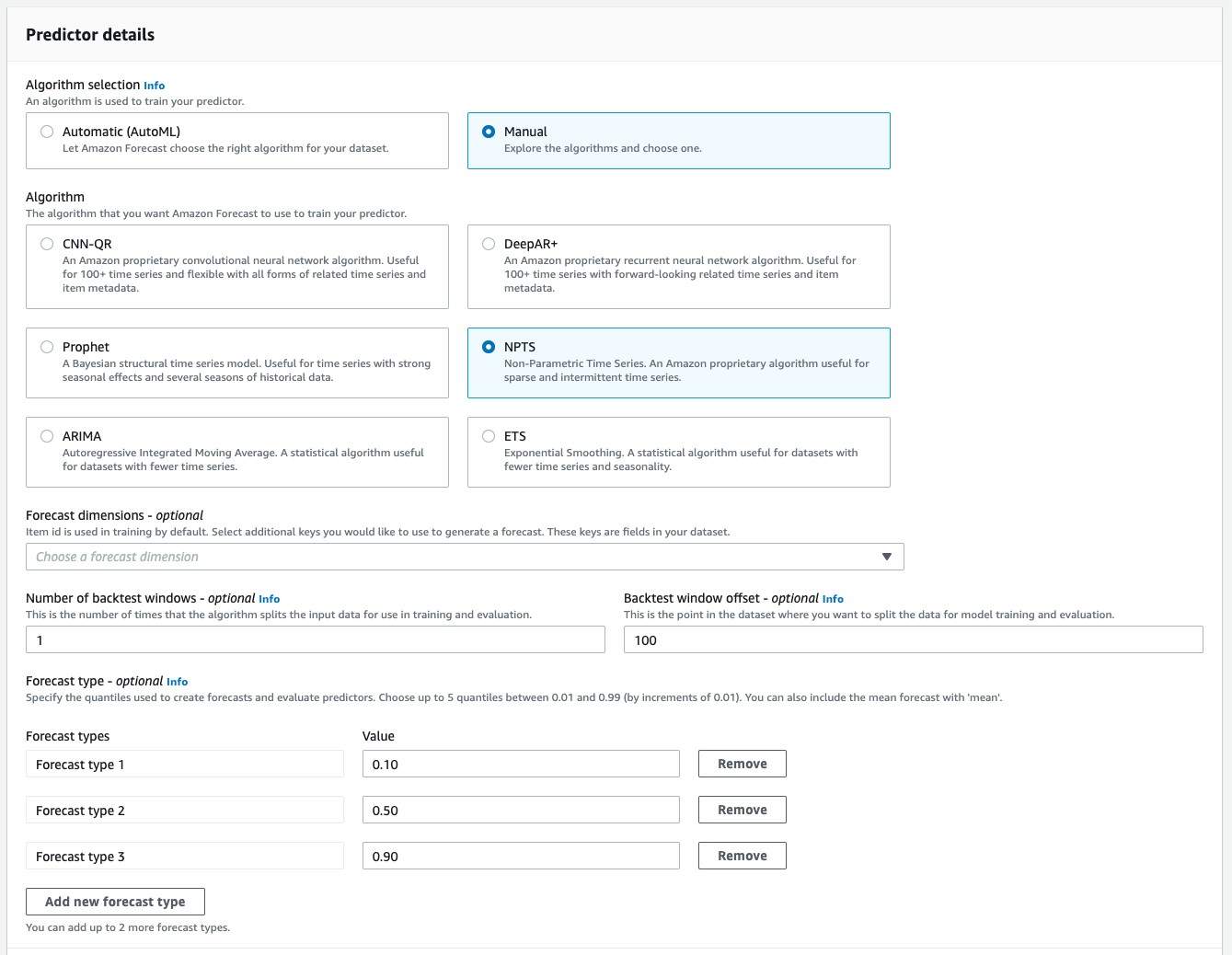
Predictor
読み込んだデータに対して、アルゴリズムや予測する期間を設定し、トレーニングを行いモデルを作成するまた予測精度に対する評価も行う。
Forecast horizon
モデルのトレーニング期間
Forecast frequency
データが1分単位なので1分で設定
Algorithm selection
AWSで準備されているアルゴリズムは6点
詳細はリンク先参照
今回は季節性もあるかなと思い「NPTS」でやってみる。
なお試しでNPTSでは1時間程度であるが、Autoやると10時間コースだったのでAutoは諦めた
Create a forecast
Forecast
トレーニングされたモデルのエンドポイントを作成し、時系列データの予測を生成する。
Forecast lookup
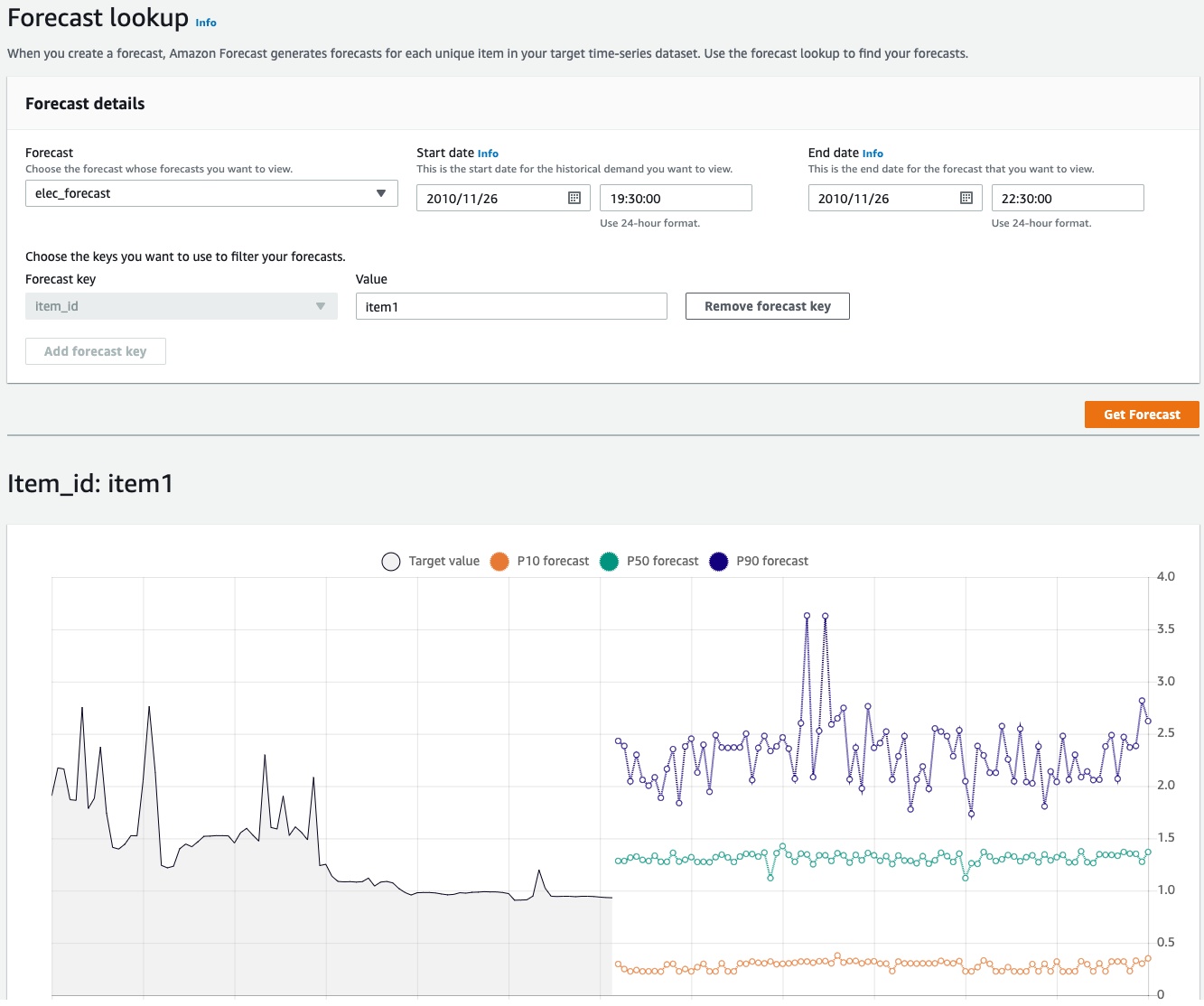
できました。
- Target valueが実際の値
- p10がこれより下回る可能性が10%
- p50がこれより下回る可能性が50%
- p90がこれより下回る可能性が90%
アルゴリズムが詳しくないけど、p90になると山の高まりが出ますね。
感想
ハンズオンでやるよりも調べながらなので頭には入りました。
同じデータでアルゴリズムを変えたりしてやるのは試してみたい
データセットを今回の形式に加工してやるのが、一番時間掛かったやも。
Discussion