Apache Iceberg のメリットとは?
この 資料は?
流しのエバンジェリストシリーズ AWS を中心として色んなサービスの基礎を学ぼうの中で 2025/04/12(土) 13:30〜に開催されたAmazon S3 Tables + Amazon Athena / Apache Icebergに登壇した時の資料です。
コードを記載している箇所が多いため、PowerPoint よりもブログの方が視認性が良いと考え、ブログ形式でまとめました
発表内容
自己紹介
某 SaaS 系企業で Infrastructure Engineer として活動しています。最近は Cursor、Devin、ChatGPT、Notion AI など、AI ツールと親しむことが主な業務になっています。自社サービスでは扱うデータ量が多いため、Amazon S3 Tables や Apache Iceberg に関心があり登壇しました

AWS Community では AWS Community Hero に認定されていますが、最近は育児で活動を控えているため、メリハリをつけて頑張りたいと考えています。
イントロダクション
Apache Iceberg が注目されている理由について説明します。
Apache Iceberg の概念
Apache Iceberg は、巨大な分析データセット向けのオープンテーブル形式です。SQL テーブルのように扱える高性能なテーブル形式を使用し、Spark、Trino、PrestoDB、Flink、Hive、Impala などの分散処理エンジンが同時かつ安全に操作できるようにします。
| Layer | 例 |
|---|---|
| 分散処理エンジン | Spark、Trino、PrestoDB、Flink、Hive、Impala |
| Table Format | Iceberg |
| Storage | S3、MinIO |
Apache Iceberg のメリットとは?
以下機能を持つことで、巨大な分析データセットを扱うことができます。
- 柔軟な SQL クエリをサポート
- スキーマの完全な進化対応
- 透過的な(隠れた)パーティション
- タイムトラベルとロールバック
- データ圧縮
RDBMS でも類似の構成を作ることは可能ですが、RDBMS は基本的にスケールアップで対応します。一方、Iceberg はスケールアウトで PB 級ファイルの処理に強みがあります。トランザクション処理(OLTP)においては RDBMS に優位性がありますが、ログ分析などデータレイクのデータ処理では Iceberg ベースの分散処理が優れています。
Apache Iceberg Architecture
ここでは Iceberg に対する CRUD 操作で、何が起こっているのかを整理します。
主に、dremio / Apache Iceberg: An Architectural Look Under the Coversからの引用をさせていただきます。
Component
Apache Iceberg には 3 つのレイヤーがあります
- Iceberg Catalog
- Metadata Layer
- Metadata File
- Manifest List
- Manifest File
- Data Layer
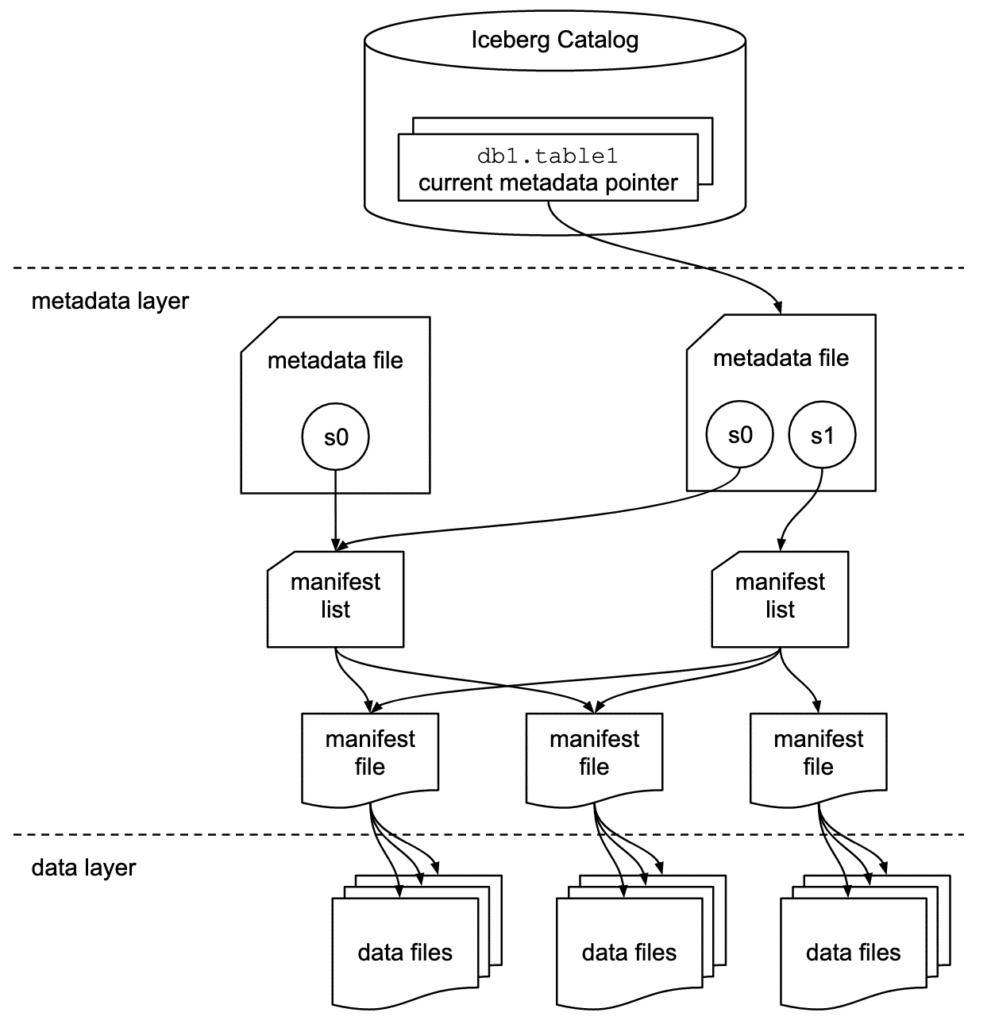
引用元:dremio / Apache Iceberg: An Architectural Look Under the Covers
Iceberg Catalog
アトミック操作をサポートし、Catalog 内の各テーブルのメタデータ位置を管理します
Metadata File
メタデータファイルにはスキーマ、パーティション、スナップショットなど、テーブルに関連する情報が含まれます。
Manifest List
マニフェスト ファイルのリストです。マニフェスト リストには、そのスナップショットを構成する各マニフェスト ファイルに関する情報が含まれます。
Manifest File
データ ファイルだけでなく、各ファイルに関する追加の詳細と統計も追跡します。大規模な並列処理と再利用の効率性のために、データ ファイルのサブセットを追跡します。データ ファイルからデータを読み取る際の効率とパフォーマンスを向上させるために使用される多くの有用な情報が含まれています。
具体的な操作例
Quickstartの Docker-Compose を利用して、データを追加することで、各レイヤーの動きを確認します。
Docker-Compose
version: "3" # Docker Compose ファイルのバージョン指定
services:
# Apache Spark + Iceberg の実行環境
spark-iceberg:
image: tabulario/spark-iceberg # Spark + Iceberg 対応の公式イメージ
container_name: spark-iceberg
build: spark/ # ローカルの `spark/` ディレクトリからビルド
networks:
iceberg_net:
depends_on:
- rest # Iceberg REST カタログサービス起動後に起動
- minio # MinIO ストレージ起動後に起動
volumes:
- ./warehouse:/home/iceberg/warehouse # データ保存用の倉庫ディレクトリをマウント
- ./notebooks:/home/iceberg/notebooks/notebooks # Jupyter ノートブック用ディレクトリをマウント
environment:
- AWS_ACCESS_KEY_ID=admin # MinIO に接続するための認証情報
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888 # Jupyter Notebook のポート
- 8080:8080 # Spark UI のポート
- 10000:10000 # Thrift サーバー(Hive Server 2)
- 10001:10001 # Spark Thrift JDBC/ODBC サーバー
# Iceberg REST カタログサービス
rest:
image: apache/iceberg-rest-fixture # Iceberg の REST API カタログのサンプル実装
container_name: iceberg-rest
networks:
iceberg_net:
ports:
- 8181:8181 # REST カタログサービスのポート
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/ # Iceberg データの格納場所(仮想S3パス)
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO # S3 互換の IO 実装を使用
- CATALOG_S3_ENDPOINT=http://minio:9000 # MinIO を S3 エンドポイントとして利用
# オブジェクトストレージ (S3互換) の MinIO サーバー
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin # 管理者ユーザー名
- MINIO_ROOT_PASSWORD=password # 管理者パスワード
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio # S3 URL の中で `warehouse.minio` を使えるように
ports:
- 9001:9001 # MinIO 管理コンソール
- 9000:9000 # S3 API エンドポイント
command: ["server", "/data", "--console-address", ":9001"] # データ保存先とコンソールポートの指定
# MinIO クライアント (mc) を使って初期セットアップを実行
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: |
/bin/sh -c "
# MinIO にホスト追加(接続設定)
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
# 既存の warehouse バケットを削除
/usr/bin/mc rm -r --force minio/warehouse;
# 新しい warehouse バケットを作成
/usr/bin/mc mb minio/warehouse;
# バケットのアクセス権を public に設定
/usr/bin/mc policy set public minio/warehouse;
# コンテナを終了させないように待機
tail -f /dev/null
"
# 各サービスが属する仮想ネットワーク
networks:
iceberg_net:
CREATE TABLE
テーブル作成時に、カラム情報を含む Metadata File が生成されます。
■ CREATE TABLE
パーティションを持ったテーブルを作成します
CREATE TABLE db1.table1 (
order_id BIGINT,
customer_id BIGINT,
order_amount DECIMAL(10, 2),
order_ts TIMESTAMP
)
USING iceberg
PARTITIONED BY ( HOUR(order_ts) );
■ 俯瞰図
metadata file が作成されます
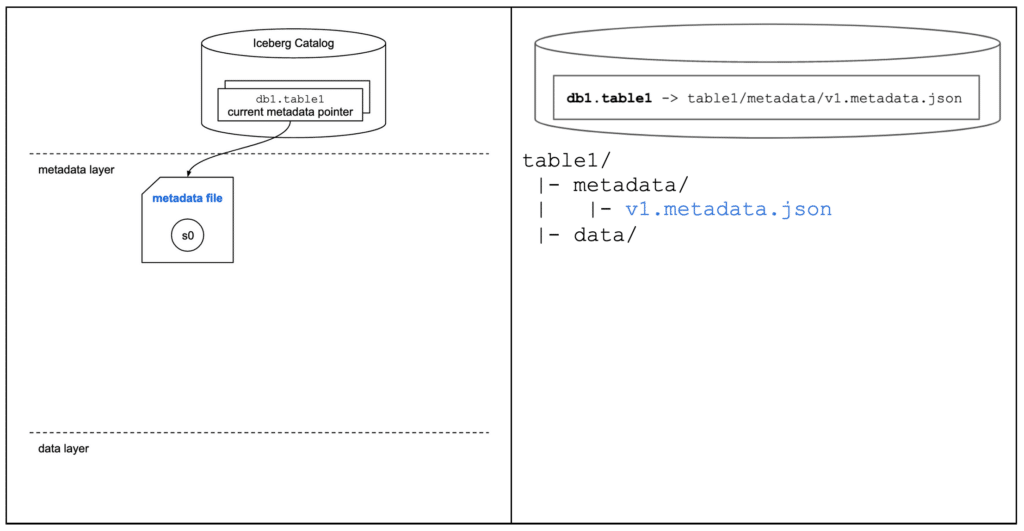
引用元:dremio / Apache Iceberg: An Architectural Look Under the Covers
■ tree
Storage を確認すると、metadata file が作成されていることが確認できます
# 事前にAccess Keyを作成
% mc alias set myminio http://localhost:9000
Enter Access Key:
Enter Secret Key:
% mc tree --files myminio
myminio
└─ warehouse
└─ db1
└─ table1
└─ metadata
└─ 00000-924287d4-14f2-4927-a5bb-1e1f2da418c6.metadata.json # Metadata File
■ Metadata File 確認
metadata file の中身を確認します
mc cp -r myminio/warehouse/db1 .
cat db1/table1/metadata/00000-924287d4-14f2-4927-a5bb-1e1f2da418c6.metadata.json | jq
{
"format-version": 2, # version
"table-uuid": "baebb4a5-7438-416f-aca4-708244f4a6b9", # tableを識別する為のUUID
"location": "s3://warehouse/db1/table1", # tableデータの配置先
"last-sequence-number": 0, # tableに割り当てられた最大のSEQ
"last-updated-ms": 1743930313741, # 最終更新時間
"last-column-id": 4, # tableに割り当てられた最大のカラムID
"current-schema-id": 0, tableに割り当てられたスキーマID
"schemas": [ # table構成
{
"type": "struct",
"schema-id": 0,
"fields": [
{
"id": 1,
"name": "order_id",
"required": false,
"type": "long"
},
{
"id": 2,
"name": "customer_id",
"required": false,
"type": "long"
},
{
"id": 3,
"name": "order_amount",
"required": false,
"type": "decimal(10, 2)"
},
{
"id": 4,
"name": "order_ts",
"required": false,
"type": "timestamptz"
}
]
}
],
"default-spec-id": 0, # writerが使用するデフォルトのspec id
"partition-specs": [ # partitionの仕様list
{
"spec-id": 0,
"fields": [
{
"name": "order_ts_hour",
"transform": "hour",
"source-id": 4,
"field-id": 1000
}
]
}
],
"last-partition-id": 1000, # partitionの仕様毎に割り当てるID
"default-sort-order-id": 0, # defaultのsort仕様ID
"sort-orders": [ # sort仕様
{
"order-id": 0,
"fields": []
}
],
"properties": {
"owner": "root",
"write.parquet.compression-codec": "zstd" # parquetの圧縮形式
},
"current-snapshot-id": -1, # スナップショットID
"refs": {}, # スナップショットの参照map
"snapshots": [], # 有効なスナップショットのリスト
"statistics": [], # テーブル統計のリスト
"partition-statistics": [], # パーティション統計のリスト
"snapshot-log": [], # スナップショットログ
"metadata-log": [] # メタデータログ
}
INSERT
データを INSERT すると、Manifest List、Manifest File、Data File が生成されます
■ INSERT
Insert でデータを挿入します
INSERT INTO db1.table1 VALUES (
123,
456,
36.17,
TIMESTAMP '2021-01-26 08:10:23'
);
■ 俯瞰図
metadata file、manifest list、manifest file、data file が作成されます
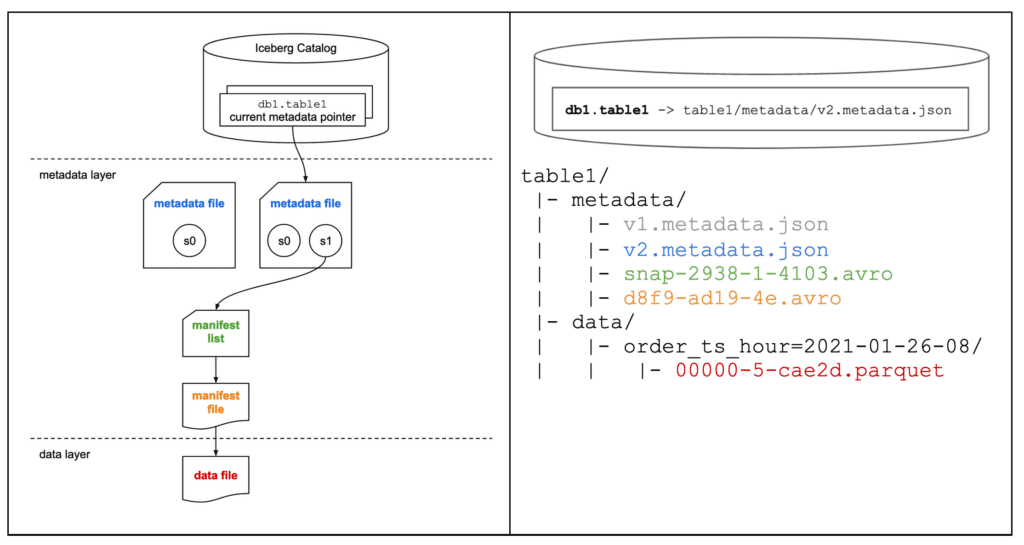
引用元:dremio / Apache Iceberg: An Architectural Look Under the Covers
■ tree
Storage を確認すると、metadata file、manifest list、manifest file、data file が作成されていることが確認できます
% mc tree --files myminio
myminio
└─ warehouse
└─ db1
└─ table1
├─ data
│ └─ order_ts_hour=2021-01-26-08
│ └─ 00000-1-e1aa7b04-e8f0-4020-827e-97468f26d127-0-00001.parquet # Data File
└─ metadata
├─ 00000-924287d4-14f2-4927-a5bb-1e1f2da418c6.metadata.json # Metadata File1
├─ 00001-6162490f-fe52-4472-80a0-45108d7d4187.metadata.json # Metadata File2
├─ 481eade7-929e-458e-81a1-86643a5900ea-m0.avro # Manifest File
└─ snap-5032443478505933848-1-481eade7-929e-458e-81a1-86643a5900ea.avro # Manifest File
■ Metadata File 確認
metadata file の中身を確認します
mc cp -r myminio/warehouse/db1 .
cat db1/table1/metadata/00001-6162490f-fe52-4472-80a0-45108d7d4187.metadata.json | jq
{
"format-version": 2,
"table-uuid": "baebb4a5-7438-416f-aca4-708244f4a6b9",
"location": "s3://warehouse/db1/table1",
"last-sequence-number": 1, # tableに割り当てられた最大のSEQ
"last-updated-ms": 1743930733913, # 最終更新時間
"last-column-id": 4,
"current-schema-id": 0,
"schemas": [
{
"type": "struct",
"schema-id": 0,
"fields": [
{
"id": 1,
"name": "order_id",
"required": false,
"type": "long"
},
{
"id": 2,
"name": "customer_id",
"required": false,
"type": "long"
},
{
"id": 3,
"name": "order_amount",
"required": false,
"type": "decimal(10, 2)"
},
{
"id": 4,
"name": "order_ts",
"required": false,
"type": "timestamptz"
}
]
}
],
"default-spec-id": 0,
"partition-specs": [
{
"spec-id": 0,
"fields": [
{
"name": "order_ts_hour",
"transform": "hour",
"source-id": 4,
"field-id": 1000
}
]
}
],
"last-partition-id": 1000,
"default-sort-order-id": 0,
"sort-orders": [
{
"order-id": 0,
"fields": []
}
],
"properties": {
"owner": "root",
"write.parquet.compression-codec": "zstd"
},
"current-snapshot-id": 5032443478505933848, # スナップショットID
"refs": { # スナップショットの参照map
"main": {
"snapshot-id": 5032443478505933848,
"type": "branch"
}
},
"snapshots": [ # 有効なスナップショットのリスト
{
"sequence-number": 1,
"snapshot-id": 5032443478505933848,
"timestamp-ms": 1743930733913,
"summary": {
"operation": "append",
"spark.app.id": "local-1743930728462",
"added-data-files": "1",
"added-records": "1",
"added-files-size": "1269",
"changed-partition-count": "1",
"total-records": "1",
"total-files-size": "1269",
"total-data-files": "1",
"total-delete-files": "0",
"total-position-deletes": "0",
"total-equality-deletes": "0"
},
"manifest-list": "s3://warehouse/db1/table1/metadata/snap-5032443478505933848-1-481eade7-929e-458e-81a1-86643a5900ea.avro",
"schema-id": 0
}
],
"statistics": [],
"partition-statistics": [],
"snapshot-log": [ # スナップショットログ
{
"timestamp-ms": 1743930733913,
"snapshot-id": 5032443478505933848
}
],
"metadata-log": [ # メタデータログ
{
"timestamp-ms": 1743930313741,
"metadata-file": "s3://warehouse/db1/table1/metadata/00000-924287d4-14f2-4927-a5bb-1e1f2da418c6.metadata.json"
}
]
}
■ Manifest List 確認
Manifest List の中身を確認します
---
from fastavro import reader
with open("db1/table1/metadata/snap-5032443478505933848-1-481eade7-929e-458e-81a1-86643a5900ea.avro", "rb") as f:
avro_reader = reader(f)
for record in avro_reader:
print(record)
---
{
"manifest_path": "s3://warehouse/db1/table1/metadata/481eade7-929e-458e-81a1-86643a5900ea-m0.avro", # manifest fileの場所
"manifest_length": 7082, # manifest fileの長さ(byte)
"partition_spec_id": 0, # partitison仕様ID
"content": 0, # manifestのfile type
"sequence_number": 1, # dataが追加された時のSEQ
"min_sequence_number": 1, # 最小SEQ
"added_snapshot_id": 5032443478505933848, #追加されたsnapshot id
"added_files_count": 1, # status ADDEDを持つエントリー数
"existing_files_count": 0, # status EXISTINGを持つエントリー数
"deleted_files_count": 0, # status DELETEDを持つエントリー数
"added_rows_count": 1, # status ADDEDでの行数
"existing_rows_count": 0, # status EXISTINGでの行数
"deleted_rows_count": 0, # status DELETEDでの行数
"partitions": # 各partitions フィールドのSUMMRY
[
{
"contains_null": False,
"contains_nan": False,
"lower_bound": b'\xc0\xd4\x06\x00',
"upper_bound": b'\xc0\xd4\x06\x00',
},
],
}
■ Manifest File 確認
Manifest File の中身を確認します
---
from fastavro import reader
with open("db1/table1/metadata/481eade7-929e-458e-81a1-86643a5900ea-m0.avro", "rb") as f:
avro_reader = reader(f)
for record in avro_reader:
print(record)
---
{
'status': 1,
'snapshot_id': 5032443478505933848,
'sequence_number': None,
'file_sequence_number': None,
'data_file': {
'content': 0,
'file_path': 's3://warehouse/db1/table1/data/order_ts_hour=2021-01-26-08/00000-1-e1aa7b04-e8f0-4020-827e-97468f26d127-0-00001.parquet',
'file_format': 'PARQUET',
'partition': {
'order_ts_hour': 447680
},
'record_count': 1,
'file_size_in_bytes': 1269,
'column_sizes': [
{'key': 1, 'value': 40},
{'key': 2, 'value': 40},
{'key': 3, 'value': 40},
{'key': 4, 'value': 40}],
'value_counts': [
{'key': 1, 'value': 1},
{'key': 2, 'value': 1},
{'key': 3, 'value': 1},
{'key': 4, 'value': 1}],
'null_value_counts': [
{'key': 1, 'value': 0},
{'key': 2, 'value': 0},
{'key': 3, 'value': 0},
{'key': 4, 'value': 0}],
'nan_value_counts': [],
'lower_bounds': [
{'key': 1, 'value': b'\x00\x00\x00\x00\x00\x00\x00'},
{'key': 2, 'value': b'\xc8\x01\x00\x00\x00\x00\x00\x00'},
{'key': 3, 'value': b'\x0e!'},
{'key': 4, 'value': b'\xc09\xad/\xc9\xb9\x05\x00'}],
'upper_bounds': [
{'key': 1, 'value': b'\x00\x00\x00\x00\x00\x00\x00'},
{'key': 2, 'value': b'\xc8\x01\x00\x00\x00\x00\x00\x00'},
{'key': 3, 'value': b'\x0e!'},
{'key': 4, 'value': b'\xc09\xad/\xc9\xb9\x05\x00'}],
'key_metadata': None,
'split_offsets': [4],
'equality_ids': None,
'sort_order_id': 0
}
}
MERGE INTO / UPSERT
MERGE INTO / UPSERT での挙動を確認します。
■ 事前準備
別 TABLE を作成し、データも準備します。
CREATE TABLE db1.table2 (
order_id BIGINT,
customer_id BIGINT,
order_amount DECIMAL(10, 2),
order_ts TIMESTAMP
)
USING iceberg
PARTITIONED BY ( HOUR(order_ts) );
INSERT INTO db1.table2 VALUES (
123,
456,
100.01,
TIMESTAMP '2021-01-27 08:10:23'
),
(
124,
567,
200.02,
TIMESTAMP '2021-01-28 08:10:23'
);
■ MERGE INTO / UPSERT
準備したテーブルを元に MERGE INTO / UPSERT を行います
MERGE INTO db1.table1 t1
USING ( SELECT * FROM db1.table2 ) t2
ON t1.order_id = t2.order_id
WHEN MATCHED THEN
UPDATE SET t1.order_amount = t2.order_amount
WHEN NOT MATCHED THEN
INSERT *
;
■ 俯瞰図
metadata file、manifest list、manifest file、data file が作成されます
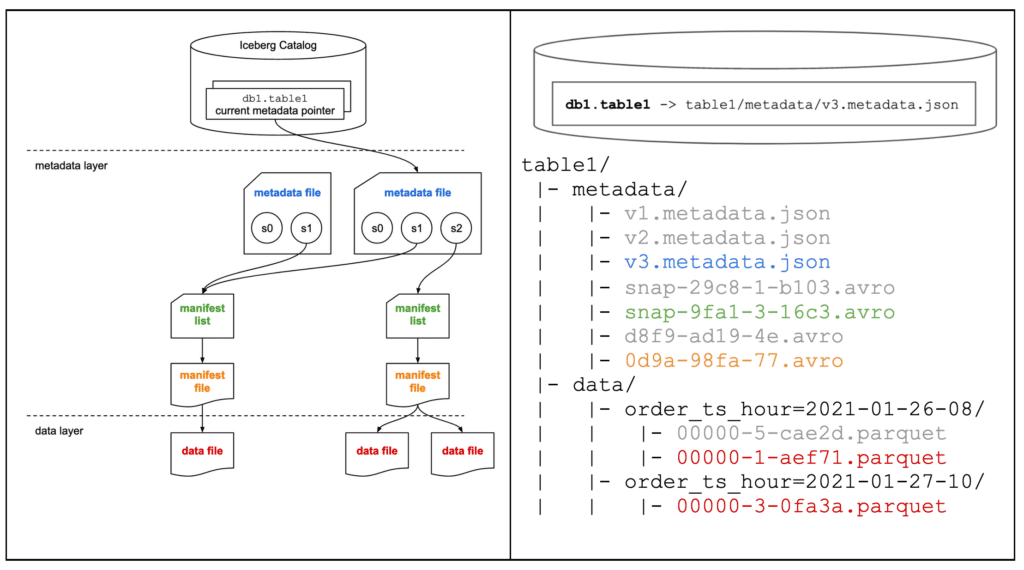
引用元:dremio / Apache Iceberg: An Architectural Look Under the Covers
■ tree
Storage を確認すると、metadata file、manifest list、manifest file、data file が作成されていることが確認できます
% mc tree --files myminio
myminio
└─ warehouse
└─ db1
├─ table1
│ ├─ data
│ │ ├─ order_ts_hour=2021-01-26-08
│ │ │ ├─ 00000-1-e1aa7b04-e8f0-4020-827e-97468f26d127-0-00001.parquet
│ │ │ └─ 00000-11-c0942a90-1adf-4507-9f80-0dd02276b849-0-00002.parquet
│ │ └─ order_ts_hour=2021-01-28-08
│ │ └─ 00000-11-c0942a90-1adf-4507-9f80-0dd02276b849-0-00001.parquet
│ └─ metadata
│ ├─ 00000-924287d4-14f2-4927-a5bb-1e1f2da418c6.metadata.json
│ ├─ 00001-6162490f-fe52-4472-80a0-45108d7d4187.metadata.json
│ ├─ 00002-996207dd-99fc-4ab2-b955-9a7885e736f2.metadata.json
│ ├─ 481eade7-929e-458e-81a1-86643a5900ea-m0.avro
│ ├─ 5d37e27f-ebd8-4073-938a-8395da71eeb6-m0.avro
│ ├─ 5d37e27f-ebd8-4073-938a-8395da71eeb6-m1.avro
│ ├─ snap-5032443478505933848-1-481eade7-929e-458e-81a1-86643a5900ea.avro
│ └─ snap-9167052220326752148-1-5d37e27f-ebd8-4073-938a-8395da71eeb6.avro
└─ table2
├─ data
│ ├─ order_ts_hour=2021-01-27-08
│ │ └─ 00000-4-18108e63-eec4-49fb-881f-c769c2a2d050-0-00001.parquet
│ └─ order_ts_hour=2021-01-28-08
│ └─ 00000-4-18108e63-eec4-49fb-881f-c769c2a2d050-0-00002.parquet
└─ metadata
├─ 00000-d361bc6b-4ef1-45a4-b9a8-69a10bfba201.metadata.json
├─ 00001-2c4225ed-f17e-48ce-99c4-3a1ebeef95dc.metadata.json
├─ 0b411675-93c4-491c-bf72-429de2fde74f-m0.avro
└─ snap-3831112830807775756-1-0b411675-93c4-491c-bf72-429de2fde74f.avro
SELECT
データ全体を検索した場合の流れを整理します。
■ SELECT
SELECT * FROM db1.table1;
---
124 567 200.02 2021-01-28 08:10:23
123 456 100.01 2021-01-26 08:10:23
■ 俯瞰図
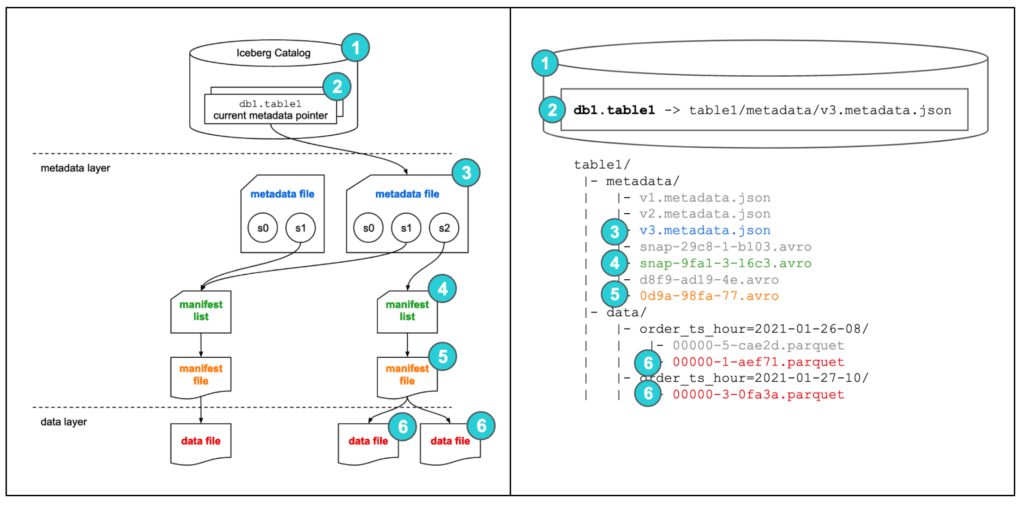
引用元:dremio / Apache Iceberg: An Architectural Look Under the Covers
SELECT PARTITION
パーティション指定で検索した場合の流れを整理します。
■ SELECT
SELECT * FROM db1.table1 WHERE CAST(order_ts AS DATE) = DATE '2021-01-26';
---
123 456 100.01 2021-01-26 08:10:23
■ 俯瞰図
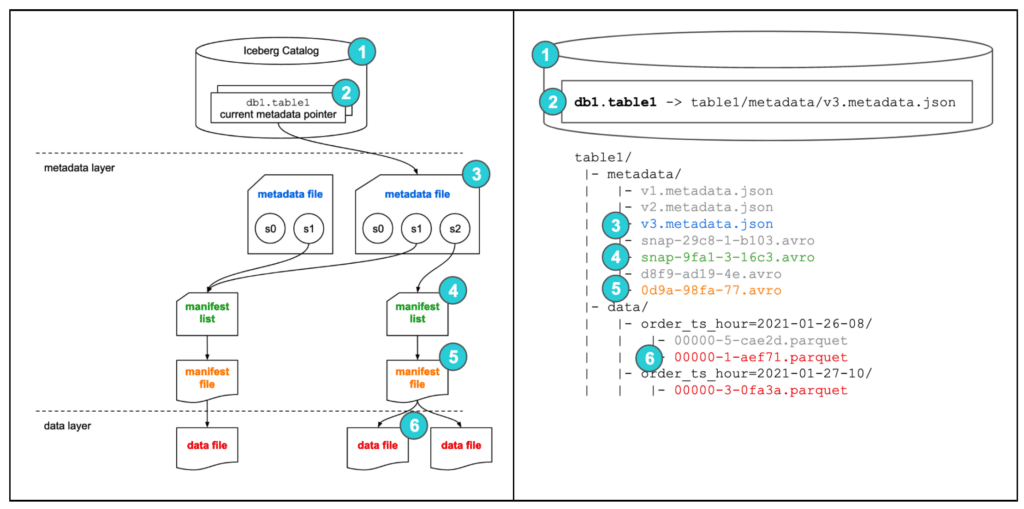
引用元:dremio / Apache Iceberg: An Architectural Look Under the Covers
TIME TRAVEL
過去の metadata/snapshot を使って、過去データにアクセスできることを確認します。
■ SELECT
desc db1.table1.history;
SELECT * FROM db1.table1.history;
---
made_current_at timestamp
snapshot_id bigint
parent_id bigint
is_current_ancestor boolean
---
2025-04-06 09:12:13.913 5032443478505933848 NULL true
2025-04-06 11:13:59.952 9167052220326752148 5032443478505933848 true
-- 日時指定
SELECT * FROM db1.table1 TIMESTAMP AS OF '2025-04-06 09:12:13.913';
-- ID指定
SELECT * FROM db1.table1 VERSION AS OF 5032443478505933848;
---
123 456 36.17 2021-01-26 08:10:23
■ 俯瞰図
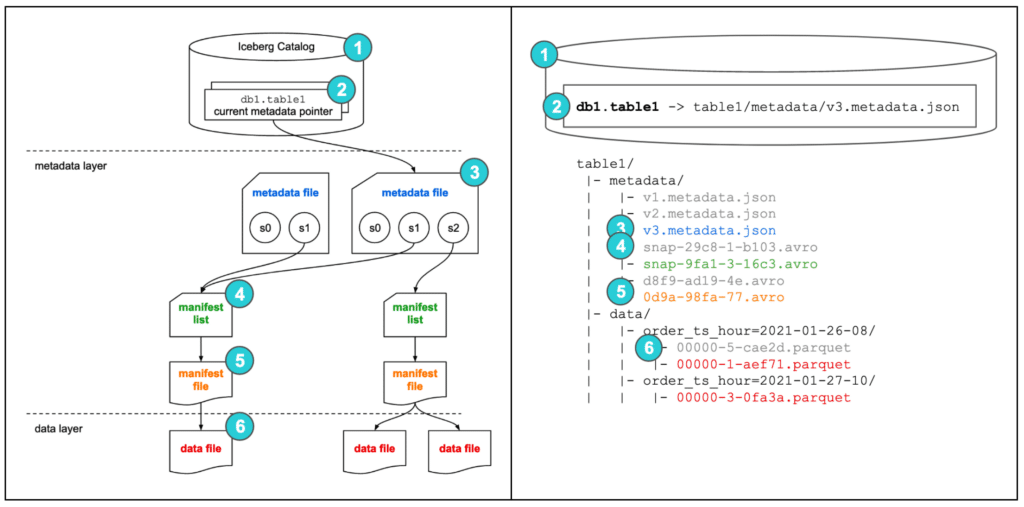
引用元:dremio / Apache Iceberg: An Architectural Look Under the Covers
ROLLBACK
過去の metadata/snapshot を使って、rollback させます。
■rollback
CALL system.rollback_to_snapshot('db1.table1', 5032443478505933848);
---
9167052220326752148 5032443478505933848
SELECT * FROM db1.table1;
---
123 456 36.17 2021-01-26 08:10:23
データファイルの圧縮
細分化された Parquet をまとめます。
■ 事前準備
テーブル作成
CREATE TABLE db2.table1 (
order_id BIGINT,
customer_id BIGINT,
order_amount DECIMAL(10, 2),
order_ts TIMESTAMP
)
USING iceberg
PARTITIONED BY ( HOUR(order_ts) );
9999 件のデータを一括挿入
INSERT INTO db2.table1 VALUES
(1,1,1,TIMESTAMP '2021-03-26 08:10:23'),
…略…
(9999,9999,9999,TIMESTAMP '2021-03-26 08:10:23');
一括で挿入したので parquet は 1 つであることを確認
% mc tree --files myminio
myminio
└─ warehouse
└─ db2
└─ table1
├─ data
│ └─ order_ts_hour=2021-03-26-08
│ └─ 00000-8-6f37f2e1-323d-4bc7-b7ca-ce582f4496ac-0-00001.parquet
└─ metadata
├─ 00000-4a5dbbd9-54a3-4582-a354-986d4f1cf713.metadata.json
├─ 00001-dee0c890-b1ca-46cc-bf87-86f3a25bf609.metadata.json
├─ b2a800e7-3619-41f4-bdc9-114b3f6bb2cd-m0.avro
└─ snap-4915081220485888938-1-b2a800e7-3619-41f4-bdc9-114b3f6bb2cd.avro
parquet には 9999 件のデータがあることを確認
% mc cp -r myminio/warehouse/db2 .
% parquet meta db2/table1/data/order_ts_hour=2021-03-26-08/00000-8-6f37f2e1-323d-4bc7-b7ca-ce582f4496ac-0-00001.parquet
File path: db2/table1/data/order_ts_hour=2021-03-26-08/00000-8-6f37f2e1-323d-4bc7-b7ca-ce582f4496ac-0-00001.parquet
Created by: parquet-mr version 1.13.1 (build db4183109d5b734ec5930d870cdae161e408ddba)
Properties:
iceberg.schema: {"type":"struct","schema-id":0,"fields":[{"id":1,"name":"order_id","required":true,"type":"long"},{"id":2,"name":"customer_id","required":true,"type":"long"},{"id":3,"name":"order_amount","required":false,"type":"decimal(10, 2)"},{"id":4,"name":"order_ts","required":true,"type":"timestamptz"}]}
Schema:
message table {
required int64 order_id = 1;
required int64 customer_id = 2;
optional int64 order_amount (DECIMAL(10,2)) = 3;
required int64 order_ts (TIMESTAMP(MICROS,true)) = 4;
}
Row group 0: count: 9999 5.34 B records start: 4 total(compressed): 52.176 kB total(uncompressed):234.499 kB
--------------------------------------------------------------------------------
type encodings count avg size nulls min / max
order_id INT64 Z _ 9999 1.90 B 0 "1" / "9999"
customer_id INT64 Z _ 9999 1.90 B 0 "1" / "9999"
order_amount INT64 Z _ 9999 1.53 B 0 "1.00" / "9999.00"
order_ts INT64 Z _ R 9999 0.01 B 0 "2021-03-26T08:10:23.00000..." / "2021-03-26T08:10:23.00000..."
■ データ更新
データ更新を行い、挙動を確認します。
UPDATE db2.table1 SET order_amount = 100 WHERE order_id BETWEEN 1 AND 100;
新しい parquet が作成されていることを確認
% mc tree --files myminio
myminio
└─ warehouse
└─ db2
└─ table1
├─ data
│ └─ order_ts_hour=2021-03-26-08
│ ├─ 00000-14-29a95a5f-2a68-47e1-bd17-473c628b6dff-0-00001.parquet
│ └─ 00000-8-6f37f2e1-323d-4bc7-b7ca-ce582f4496ac-0-00001.parquet
└─ metadata
├─ 00000-4a5dbbd9-54a3-4582-a354-986d4f1cf713.metadata.json
├─ 00001-dee0c890-b1ca-46cc-bf87-86f3a25bf609.metadata.json
├─ 00002-df11d54c-2dc2-4aae-bf2f-b4bdb46a4bab.metadata.json
├─ 951d15e3-627a-42bb-8ba1-5e95d8c96b9d-m0.avro
├─ 951d15e3-627a-42bb-8ba1-5e95d8c96b9d-m1.avro
├─ b2a800e7-3619-41f4-bdc9-114b3f6bb2cd-m0.avro
├─ snap-2576179861753593642-1-951d15e3-627a-42bb-8ba1-5e95d8c96b9d.avro
└─ snap-4915081220485888938-1-b2a800e7-3619-41f4-bdc9-114b3f6bb2cd.avro
新しいデータが 9999 件ある。つまり毎度全データを Copy していることになり、書き込み性能が落ちる可能性がある。
% parquet meta db2/table1/data/order_ts_hour=2021-03-26-08/00000-14-29a95a5f-2a68-47e1-bd17-473c628b6dff-0-00001.parquet
File path: db2/table1/data/order_ts_hour=2021-03-26-08/00000-14-29a95a5f-2a68-47e1-bd17-473c628b6dff-0-00001.parquet
Created by: parquet-mr version 1.13.1 (build db4183109d5b734ec5930d870cdae161e408ddba)
Properties:
iceberg.schema: {"type":"struct","schema-id":0,"fields":[{"id":1,"name":"order_id","required":false,"type":"long"},{"id":2,"name":"customer_id","required":false,"type":"long"},{"id":3,"name":"order_amount","required":true,"type":"decimal(10, 2)"},{"id":4,"name":"order_ts","required":false,"type":"timestamptz"}]}
Schema:
message table {
optional int64 order_id = 1;
optional int64 customer_id = 2;
required int64 order_amount (DECIMAL(10,2)) = 3;
optional int64 order_ts (TIMESTAMP(MICROS,true)) = 4;
}
Row group 0: count: 9999 3.83 B records start: 4 total(compressed): 37.404 kB total(uncompressed):156.424 kB
--------------------------------------------------------------------------------
type encodings count avg size nulls min / max
order_id INT64 Z _ 9999 1.91 B 0 "1" / "9999"
customer_id INT64 Z _ 9999 1.91 B 0 "1" / "9999"
order_amount INT64 Z _ R 9999 0.01 B 0 "100.00" / "9999.00"
order_ts INT64 Z _ R 9999 0.01 B 0 "2021-03-26T08:10:23.00000..." / "2021-03-26T08:10:23.00000..."
■ 設定変更
ALTER TABLE db2.table1 SET TBLPROPERTIES ('write.update.mode' = 'merge-on-read')
データ Insert
INSERT INTO db2.table1 VALUES
(10001,10001,10001,TIMESTAMP '2021-03-26 08:10:23'),
(10002,10002,10002,TIMESTAMP '2021-03-26 08:10:23'),
(10003,10003,10003,TIMESTAMP '2021-03-26 08:10:23');
新しい parquet が作成されていることを確認
% mc tree --files myminio
myminio
└─ warehouse
└─ db2
└─ table1
├─ data
│ └─ order_ts_hour=2021-03-26-08
│ ├─ 00000-14-29a95a5f-2a68-47e1-bd17-473c628b6dff-0-00001.parquet
│ ├─ 00000-18-a8d9e5dc-a0c5-4216-b108-c49365519782-0-00001.parquet
│ └─ 00000-8-6f37f2e1-323d-4bc7-b7ca-ce582f4496ac-0-00001.parquet
└─ metadata
├─ 00000-4a5dbbd9-54a3-4582-a354-986d4f1cf713.metadata.json
├─ 00001-dee0c890-b1ca-46cc-bf87-86f3a25bf609.metadata.json
├─ 00002-df11d54c-2dc2-4aae-bf2f-b4bdb46a4bab.metadata.json
├─ 00003-085328ea-6c3f-4da0-b68d-71c983545911.metadata.json
├─ 00004-2761695d-9bee-44c9-878f-403ab9fbaf6c.metadata.json
├─ 45bb2f5a-7436-472d-92db-96e982cf53cf-m0.avro
├─ 951d15e3-627a-42bb-8ba1-5e95d8c96b9d-m0.avro
├─ 951d15e3-627a-42bb-8ba1-5e95d8c96b9d-m1.avro
├─ b2a800e7-3619-41f4-bdc9-114b3f6bb2cd-m0.avro
├─ snap-1007360950315700422-1-45bb2f5a-7436-472d-92db-96e982cf53cf.avro
├─ snap-2576179861753593642-1-951d15e3-627a-42bb-8ba1-5e95d8c96b9d.avro
└─ snap-4915081220485888938-1-b2a800e7-3619-41f4-bdc9-114b3f6bb2cd.avro
parquet ファイルを確認すると 3 件しかない。別ファイルにすることで書き込み性能を上げている
(読み込み性能は逆に落ちる)
% mc cp -r myminio/warehouse/db2 .
% parquet meta db2/table1/data/order_ts_hour=2021-03-26-08/00000-18-a8d9e5dc-a0c5-4216-b108-c49365519782-0-00001.parquet
File path: db2/table1/data/order_ts_hour=2021-03-26-08/00000-18-a8d9e5dc-a0c5-4216-b108-c49365519782-0-00001.parquet
Created by: parquet-mr version 1.13.1 (build db4183109d5b734ec5930d870cdae161e408ddba)
Properties:
iceberg.schema: {"type":"struct","schema-id":0,"fields":[{"id":1,"name":"order_id","required":true,"type":"long"},{"id":2,"name":"customer_id","required":true,"type":"long"},{"id":3,"name":"order_amount","required":false,"type":"decimal(10, 2)"},{"id":4,"name":"order_ts","required":true,"type":"timestamptz"}]}
Schema:
message table {
required int64 order_id = 1;
required int64 customer_id = 2;
optional int64 order_amount (DECIMAL(10,2)) = 3;
required int64 order_ts (TIMESTAMP(MICROS,true)) = 4;
}
Row group 0: count: 3 78.67 B records start: 4 total(compressed): 236 B total(uncompressed):199 B
--------------------------------------------------------------------------------
type encodings count avg size nulls min / max
order_id INT64 Z _ 3 17.33 B 0 "10001" / "10003"
customer_id INT64 Z _ 3 17.33 B 0 "10001" / "10003"
order_amount INT64 Z _ 3 20.67 B 0 "10001.00" / "10003.00"
order_ts INT64 Z _ R 3 23.33 B 0 "2021-03-26T08:10:23.00000..." / "2021-03-26T08:10:23.00000..."
一応中身を確認して、3 件であった。
% parquet cat db2/table1/data/order_ts_hour=2021-03-26-08/00000-18-a8d9e5dc-a0c5-4216-b108-c49365519782-0-00001.parquet
{"order_id": 10001, "customer_id": 10001, "order_amount": 1000100, "order_ts": 1616746223000000}
{"order_id": 10002, "customer_id": 10002, "order_amount": 1000200, "order_ts": 1616746223000000}
{"order_id": 10003, "customer_id": 10003, "order_amount": 1000300, "order_ts": 1616746223000000}
SQL で紐づく data file を確認すると 2 ファイルある
SELECT file_path, file_size_in_bytes
FROM db2.table1.files;
s3://warehouse/db2/table1/data/order_ts_hour=2021-03-26-08/00000-18-a8d9e5dc-a0c5-4216-b108-c49365519782-0-00001.parquet 1338
s3://warehouse/db2/table1/data/order_ts_hour=2021-03-26-08/00000-14-29a95a5f-2a68-47e1-bd17-473c628b6dff-0-00001.parquet 39488
■ 圧縮
CALL system.rewrite_data_files(
table => 'db2.table1',
options => map(
'min-input-files', '1', -- 最小ファイル数
'target-file-size-bytes', '134217728' -- 128MB
)
);
1file になったことが確認できる
SELECT file_path, file_size_in_bytes
FROM db2.table1.files;
s3://warehouse/db2/table1/data/order_ts_hour=2021-03-26-08/00000-20-3e1e3f7b-b090-4628-beab-dd7a4b223e54-0-00001.parquet 39512
今後やりたいこと
OpenSearch のRoadMapを見ていると、iceberg 対応について記載があります。
通常の S3 でも Zero ETL で index にデータを取り込まないくても OpenSearch 検索は可能ですが、S3 Tables 化されることで、パーティションプルーニング、効率的なクエリ最適化により高速なクエリ処理が可能になることが期待できます。
これまで S3 直接では性能面・コスト面が難でしたが、改善される余地があればログ管理の方法を変えてみたい。

S3 Table に要望 : S3 Tables Glacier が欲しい
「今後やりたいこと」に記載した内容を実施すると、S3 Tables にデータが保持され続けます。
プロダクトの要件として数年単位でデータを保持する必要がある場合には S3 Tables にそのまま保持するのは高コストです。
S3 Tables でもライフサイクル管理をするためにも S3 Tables Glacier が欲しいです。
参考資料
https://iceberg.apache.org/
https://aws.amazon.com/jp/what-is/apache-iceberg/
https://www.dremio.com/resources/guides/apache-iceberg-an-architectural-look-under-the-covers/
Discussion