Amazon EMR 7.12 で Apache Iceberg v3 の Row Lineage を検証
はじめに
Iceberg Advent Calendar 2025の 12/01 投稿記事です。
目的
Amazon EMR 7.12 now supports the Apache Iceberg v3 table format
Amazon EMR 7.12 が Iceberg v3 をサポートしたので、EMR Serverless で Row Lineage(行レベル系譜追跡) を検証してみました。
Deletion Vectors(削除ベクトル)検証は ⇩ 参照
環境
- EMR : 7.12
- Apache Iceberg: v3 or v2
- Catalog: AWS Glue Catalog
- Storage: Amazon S3
AWS 環境作成
EMR Studio を作成する
作成手順はAWS Document参照
EMR Application を作成する
作成手順はAWS Document参照
Script
test_row_lineage.py
from pyspark.sql import SparkSession
# Sparkセッション作成
spark = SparkSession.builder \
.appName("Iceberg-v2-v3-Row-Lineage-Comparison") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.glue_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.glue_catalog.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog") \
.config("spark.sql.catalog.glue_catalog.warehouse", "s3://your-bucket-name/warehouse/") \
.getOrCreate()
print(f"✅ Spark Version: {spark.version}")
# テスト対象バージョンリスト
versions = [
{"version": 2, "db": "test_db_v2", "table": "row_lineage_test_v2"},
{"version": 3, "db": "test_db_v3", "table": "row_lineage_test_v3"}
]
for config in versions:
version = config["version"]
db = config["db"]
table = config["table"]
full_table_name = f"glue_catalog.{db}.{table}"
print(f"\n{'='*60}")
print(f"Testing Iceberg v{version}")
print(f"{'='*60}")
# データベース作成
spark.sql(f"CREATE DATABASE IF NOT EXISTS glue_catalog.{db}")
print(f"✅ Database '{db}' created")
# テーブル作成
spark.sql(f"""
CREATE OR REPLACE TABLE {full_table_name} (
id BIGINT,
name STRING,
value INT
) USING iceberg
TBLPROPERTIES (
'format-version' = '{version}',
'write.delete.mode' = 'merge-on-read'
)
""")
print(f"✅ Iceberg v{version} table created")
# format-version確認
result = spark.sql(f"SHOW TBLPROPERTIES {full_table_name}('format-version')").collect()
print(f"✅ Format Version: {result[0][1]}")
# 初期データ挿入
spark.sql(f"""
INSERT INTO {full_table_name} VALUES
(1, 'Alice', 100),
(2, 'Bob', 200),
(3, 'Charlie', 300)
""")
print("✅ Initial data inserted")
# UPDATE操作
spark.sql(f"""
UPDATE {full_table_name}
SET value = 150
WHERE id = 1
""")
print("✅ UPDATE executed")
# DELETE操作
spark.sql(f"""
DELETE FROM {full_table_name}
WHERE id = 3
""")
print("✅ DELETE executed")
# スナップショット履歴確認
print(f"\n--- Snapshot History (v{version}) ---")
snapshots = spark.sql(f"SELECT * FROM {full_table_name}.snapshots")
snapshots.select("snapshot_id", "operation", "summary").show(truncate=False)
# 最終データ確認
print(f"\n--- Final Data (v{version}) ---")
spark.sql(f"SELECT * FROM {full_table_name} ORDER BY id").show()
print("\n" + "="*60)
print("✅ Row Lineage comparison completed!")
print("="*60)
spark.stop()
JOB 実行
S3 や IAM の作成は省略しています
aws emr-serverless start-job-run \
--application-id xxx \
--execution-role-arn arn:aws:iam::xxx:role/EMRServerlessIcebergRole \
--name "test_row_lineage" \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://xxx/scripts/test_row_lineage.py"
}
}' \
--region ap-northeast-1
検証
概要
3 つの操作を実行し、スナップショット履歴でデータの変更履歴を追跡できることを確認します。
- INSERT: 初期データ 3 件を挿入
- UPDATE: 1 件のレコードを更新
- DELETE: 1 件のレコードを削除
これらの操作を Iceberg v2 と v3 の両方で実行し、動作を比較します。
Script 結果概要
v2 の場合
| 操作 | レコード変更 | データファイル変更 | ファイルサイズ変化 | 累計ファイル数 |
|---|---|---|---|---|
| INSERT | +3 件 | +3 ファイル | +2,706 bytes | 3 ファイル |
| UPDATE | +1 件 / -1 件 | +1 ファイル / -1 ファイル | +932 bytes / -902 bytes | 3 ファイル |
| DELETE | -1 件 | -1 ファイル | -916 bytes | 2 ファイル |
v3 の場合
| 操作 | レコード変更 | データファイル変更 | ファイルサイズ変化 | 累計ファイル数 |
|---|---|---|---|---|
| INSERT | +3 件 | +3 ファイル | +2,706 bytes | 3 ファイル |
| UPDATE | +1 件 / -1 件 | +1 ファイル / -1 ファイル | +1,518 bytes / -902 bytes | 3 ファイル |
| DELETE | -1 件 | -1 ファイル | -916 bytes | 2 ファイル |
結果
UPDATE 時にファイルサイズが増加していることが確認できました。
- v2: 932 bytes
- v3: 1,518 bytes
v3 ではRow-lineage フィールド(_row_id と_last_updated_sequence_number)が追加されているためです。
なぜファイルサイズが増えるのか?
v3 の UPDATE 操作では、変更された行に対して元の行を追跡するための_row_idと_last_updated_sequence_numberカラムがデータファイルに追加されます。
- v2: 3 カラム (id, name, value) → 932 bytes
- v3: 5 カラム (id, name, value, _row_id, _last_updated_sequence_number) → 1,518 bytes
- 差分: 586 bytes (約 63%増)
深堀り
Iceberg テーブルは以下の図のように、Metadata file、Manifest list、Manifest file、Data file の階層構造で構成されています。v3 では各レイヤーに Row Lineage 関連のフィールドが追加されます。
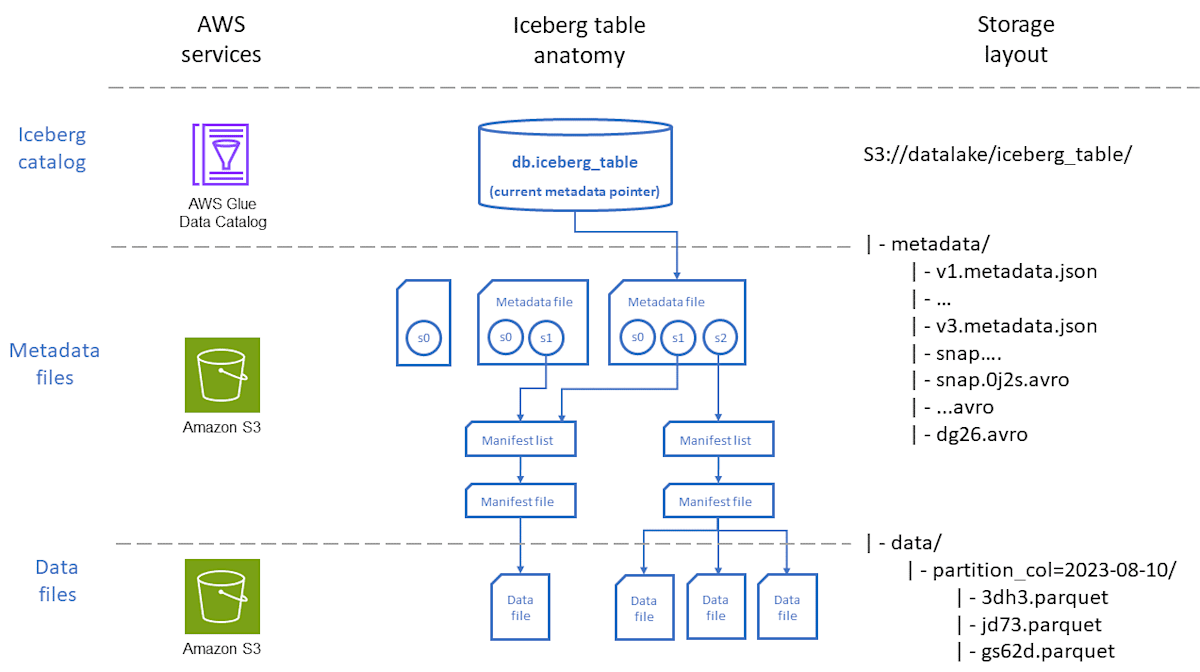
出典: AWS Prescriptive Guidance - Apache Iceberg on AWS
■metadata file で追加されたフィールド
- next-row-id
- テーブルレベルでフィールドが追加されている
- 次に割り当てられる行 ID の値
- テーブル全体で一意な行 ID を管理するカウンター
- first-row-id
- スナップショットレベルでフィールドが追加されている
- そのスナップショットで追加された行の最初の ID
- 各操作で追加された行の範囲の開始点を示す
- added-rows
- スナップショットレベルでフィールドが追加されている
- そのスナップショットで追加された行数
- first-row-id と組み合わせて、追加された行の ID 範囲を特定できる
**例: Row ID の割り当て**
- Snapshot 1: INSERT 3 件 → 行 ID 0,1,2
- Snapshot 2: UPDATE 1 件 → 行 ID 3,4,5
- (注: パーティションテーブルではないため、1 件の UPDATE でも overwrite 方式で実行され、既存の 3 行すべてが書き換えられます。そのため 3 行分の新しい行 ID が割り当てられます)
- Snapshot 3: DELETE 1 件 → 行 ID 6 (削除マーカー)
- この時点での next-row-id は 7 となる
■manifest list で追加されたフィールド
- first_row_id
- そのマニフェストに含まれるデータファイルの最初の行 ID
- 行 ID の範囲を追跡でき、どのマニフェストにどの行 ID が含まれているかを特定できる。
■manifest file で追加されたフィールド
- first_row_id
- データファイル内の最初の行 ID
- row lineage 追跡の起点
■data file で追加されたフィールド
-
_row_id (UPDATE/DELETE 時のみ)
- システムカラムが追加
- 元の行 ID (UPDATE/DELETE 時のリネージ追跡用)
-
_last_updated_sequence_number (UPDATE/DELETE 時のみ)
- システムカラムが追加
- 最終更新シーケンス番号
Row Lineage フィールドの関係性
各レイヤーの Row Lineage フィールドがどのように連携して動作するかを図示します。
図の説明:
- 青色: Metadata File(テーブル全体の next-row-id を管理)
- 黄色: Snapshot(各操作での first-row-id と added-rows を記録)
- 灰色: Manifest List/File(ファイルレベルでの行 ID 情報)
- 赤色: UPDATE 操作で追加されたファイル(
_row_idフィールドを含む)
Row Lineage の活用例
Row Lineage を使うことで以下のようなユースケースが可能になります:
- データ品質管理: 特定の行がいつ、どの処理で変更されたかを追跡
- コンプライアンス: GDPR などの削除リクエストに対して、データの完全な削除を証明
- デバッグ: データの不整合が発生した際に、どのバッチ処理で問題が起きたかを特定
- Change Data Capture (CDC): 行レベルの変更履歴を効率的に取得
まとめ
本記事では、Amazon EMR 7.12 で利用可能になった Apache Iceberg v3 の Row Lineage 機能を検証しました。
主な発見:
- v3 ではメタデータ、マニフェスト、データファイルの各レイヤーで Row Lineage 用のフィールドが追加される
- UPDATE/DELETE 操作時にデータファイルに
_row_idと_last_updated_sequence_numberが自動付与される - EMR Serverless 7.12 で問題なく動作することを確認
Row Lineage は データガバナンスや監査要件が厳しいユースケースで有用な技術かと考えます。
Discussion