Gemma 3 をブラウザ上で動かして PWA へ搭載する
はじめに
Gemma は Google が開発していることで有名な、オープンで軽量な LLM である。
最小モデルとして1Bのモデルもリリースされており、エッジデバイスでの実行も視野に入れられている。
Google のドキュメントでは、このようなモデルによる推論をブラウザで実行するための方法も紹介されていた。
現代の Web アプリケーション開発者にとって馴染みがある React で実行できるコードを用意したので紹介したい。
併せて PWA としてオフラインで動作させられることも確認した。
繰り返すが、モデルによる推論を、「ブラウザで」実行する。
LM Studio など専用のアプリケーションで実行したものへブラウザからアクセスする、のではなく、ブラウザ上で実行する。
手っ取り早くコードを pull して動かしたい場合はこちらのリポジトリを参照されたい。
WebGPU API と MediaPipe Solutions
今回のアプローチで Gemma を動かすにあたっては、大きく2つのレイヤーに依存している。
ひとつは WebGPU API 。
こちらはより下層にあるシステムがもつ GPU デバイスへのアクセスを抽象化したインターフェース。
従来の WebGL よりも高性能で、モダンな GPU の機能をより効率的に活用できるとされている。
そのため推論を利用したいブラウザで navigator.gpu が存在している必要がある。
もうひとつが MediaPipe Solutions 。
こちらは Web や LLM に限定されない領域で AI や ML の適用を補助してくれるツール群の総称。
提供されているライブラリやツールを活用すると、ブラウザ上で画像認識をしたり Android で LLM を呼び出したりできる。
今回はこの中でも特に @mediapipe/tasks-genai という Web ブラウザ上での LLM を呼び出すための NPM を利用している。
構築の手順
核になる部分だけかいつまんで紹介する。
モデル
まずは処理の実行に必要なモデルを手元へ落としてくる必要がある。
利用できるモデルと取得方法の一覧は次のページに詳しい。
Gemma-3 1B を試すなら Hugging Face のアカウントを作って次のページからダウンロードする。
Files and versions から gemma3-1b-it-int4.task を選択する。
前述のライブラリから呼び出せるように変換がなされているので、ダウンロード以外に必要な手順はない。
(逆にオリジナルの Gemma 3 は、そのままでは今回のアプローチで動かないので注意)
ダウンロードしたモデルは後述の createFromOptions 関数で指定している path に対応する場所へ配置しておくこと。
コードベース
任意の方法で Web アプリケーションの雛形を用意したら、前述の @mediapipe/tasks-genai パッケージを依存へ追加する。
当該ライブラリ呼び出しのための TS のサンプルは次の通り。
(https://github.com/shiba-hiro/gemma-playground-web より)
import { FilesetResolver, LlmInference } from "@mediapipe/tasks-genai";
export const SUPPORTED_MODELS = {
GEMMA3_1B: "gemma3-1b-it-int4",
GEMMA2_2B: "gemma2-2b-it-gpu-int8",
} as const;
export type SupportedModel =
typeof SUPPORTED_MODELS[keyof typeof SUPPORTED_MODELS];
type WasmFileset = Parameters<typeof LlmInference["createFromOptions"]>[0];
let wasmFileset: WasmFileset | null = null;
const modelToFilePath = {
[SUPPORTED_MODELS.GEMMA3_1B]: "/gemma3-1b-it-int4.task",
[SUPPORTED_MODELS.GEMMA2_2B]: "/gemma2-2b-it-gpu-int8.bin",
} as const;
type Options = {
maxTokens?: number;
topK?: number;
temperature?: number;
};
export const generateResponse = async (
inputPrompt: string,
model: SupportedModel,
options: Options = {},
): Promise<string> => {
if (!wasmFileset) {
wasmFileset = await FilesetResolver.forGenAiTasks(
// cp -r ./node_modules/@mediapipe/tasks-genai/wasm ./public/wasm
"/wasm",
);
}
const llmInference = await LlmInference.createFromOptions(wasmFileset, {
baseOptions: {
modelAssetPath: modelToFilePath[model],
},
...options,
});
return llmInference.generateResponse(inputPrompt);
};
下記ドキュメントのサンプルコードでは wasm のディレクトリを CDN の URL で指定している。
手元で完結させたい場合は上掲のコードのようにライブラリ内部のディレクトリを public 配下にでも置いておけばよい。
実行時の諸注意
普段、大手プロバイダーの Web API 経由で LLM を触っているのに比べると、大きく次の2点に留意する必要がある。
なお、これらの諸注意は上掲の私のサンプルコードで Gemma-3 1B を動かした場合のもの。
ひとつは速度。
実行するマシンの性能やモデルサイズに依存することではあるが、ごく短いテキストを生成させるだけでも数分を要する。
LM Studio で Qwen-2.5 14B などを手元で動かしたことがある、という方もいると思うが、ブラウザで動かす Gemma-3 1B の場合それとは比較にならないほど遅い。
気長に待とう。
もうひとつは精度。
さすが小型にしてあるだけあり、雑な「こんにちは」みたいなプロンプトだと碌な生成はされない。
ハッキリ回答させようと思うと、次のようなプロンプトを投げかける必要がある。
You are a helpful assistant.
Provide a concise answer to a user question.
user: Hello!
assistant:
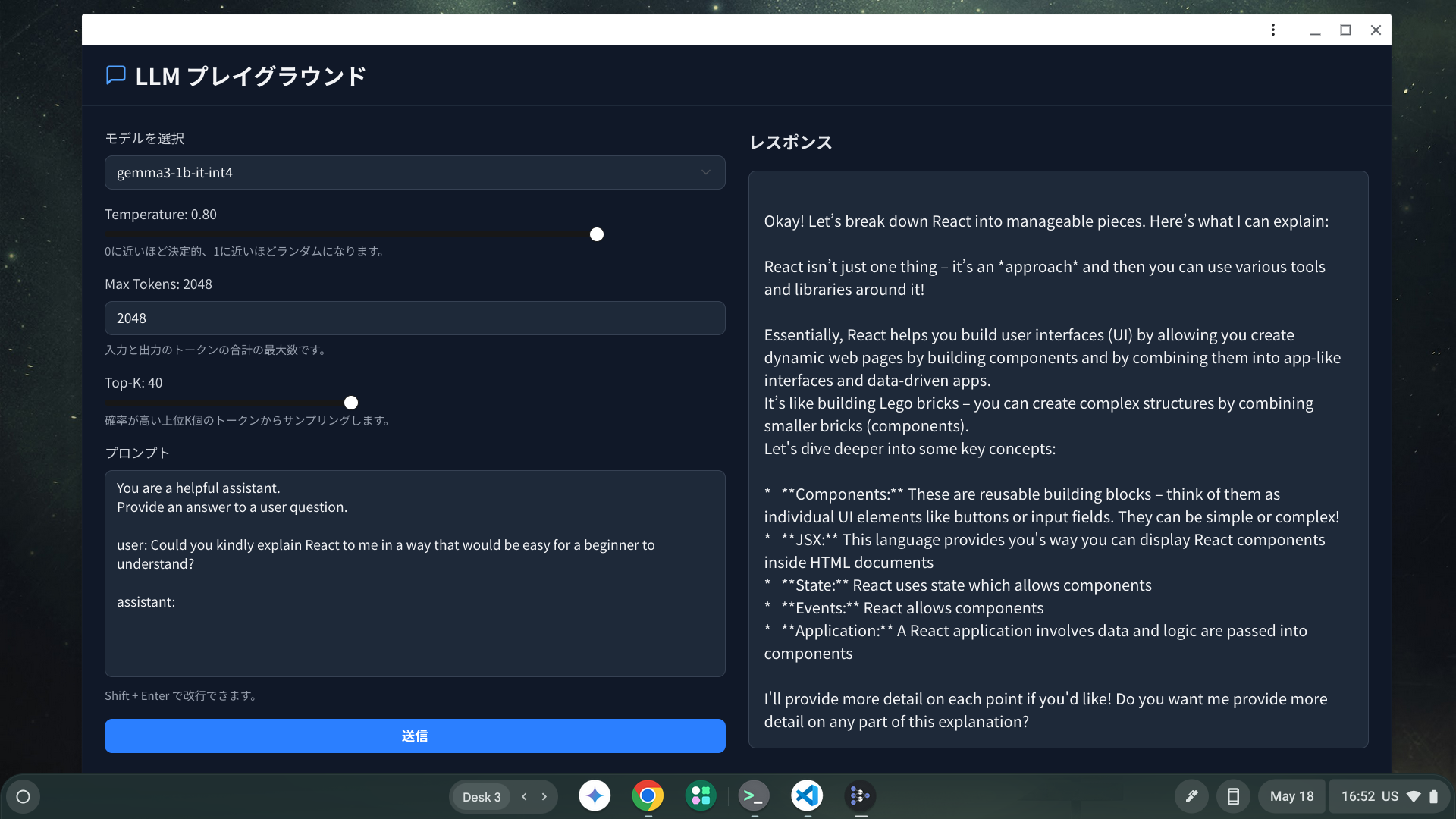
PWA 化させた場合の挙動
設定を組むことで、実行時に必要な wasm やモデルを PWA のキャッシュ対象へ含めることができた。
細かいことは vite.config.ts を参照されたい。
(雑に色々触っていたので不要な設定が含まれているかもしれない)
相変わらず低速度な推論ではあるものの、ネットワークを経由せずに wasm やモデルをロードし、推論を実行できることを確認した。
Chrome OS において PWA としてインストールして実行している様子。
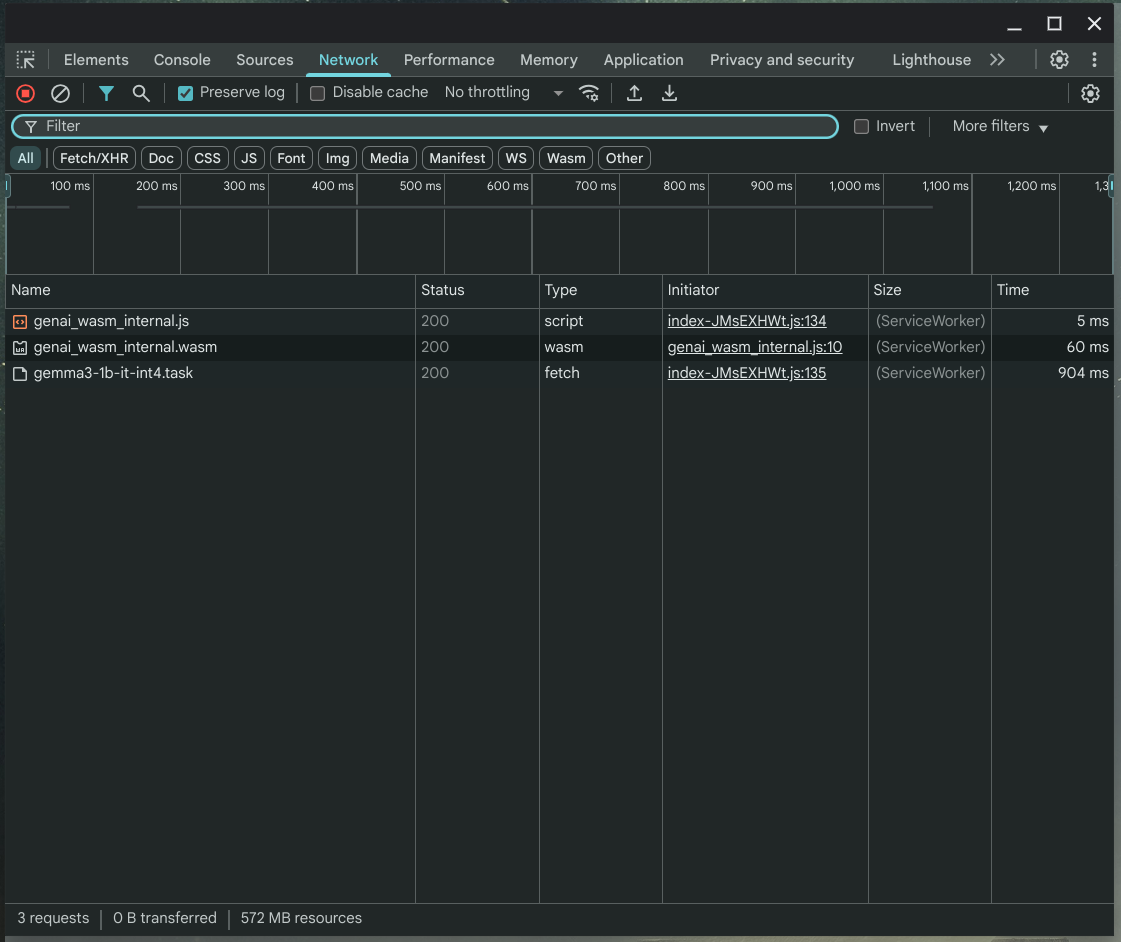
DevTools の Network の様子。
ServiceWorker がちゃんと仕事しているのがわかる。
まとめ
ブラウザ上での LLM による推論の実行は、まだエコシステムや精度の面で実用へのハードルはありつつ、すでに現実のものとなっている。
必要なアセットをキャッシュすれば、ブラウザからの手軽(マシンスペックは必要だが・・・)なアクセスと、プライベートな推論実行との両取りができる。
ブラウザで完結し、推論実行用の特別な環境設定やアプリケーションの導入がない分、ビジネス上の新しいインパクトを生める余地があると考える。
ブラウザで AI が動くというのが純粋にちょっと感動するので、よければ試してみてほしい。
参考資料
Discussion