自炊PDF本に短時間で詳細な目次を付与するツール
概要
一般に, 自炊(紙媒体の本から電子媒体の本を得る作業)して作ったPDF本には目次が付いていない. 目次が必要であれば, 何らかの手段で自分で付与する作業が発生する. 目次付与を行うツールはいくつか存在するが(関連ツールを参照), いずれも
- 入力
- 目次を付与したいPDF
- 目次内容を記述したテキストベースのファイル(以下「データファイル」)
- 出力
- 目次が付与されたPDF
という入出力形式を取る. このうち, データファイルを準備するための汎用性があり, かつ, 手入力よりも有意に効率的な手法は, 私の知る限り全く整備されていない. というわけで, それっぽいツールを作った.
以下は, データファイル生成プロセス. 1つのツールが, 1つの矢印に当たるデータ加工を行う.

関連ツール(参考)
- pdf への目次付与ツール
- これらのツールへの入力補助ツール
作ったもの
概要
想定作業フロー順に以下に分かれる.
下に行くほど後の工程. どのツールも独立しているので, 入力形式さえ問題なければ, つまみ食い適用可能.
-
ocr-japanese-doc-by-line:
- 入力: pdf, zip
- 出力: txt
- Google Cloud Vision API を使って, 横書き1段組の日本語文章を含む画像/pdf/zip ファイルを読み, 1つのテキストファイルを出力する. 目次をいい感じにOCRするのに使う.
-
tesseract-zip-pdf-dir:
- 入力: pdf, zip
- 出力: txt
- 上の tesseract 版. 英語等のアルファベット主体の言語用.
-
tidy-toc:
- 入力: txt
- 出力: txt
- テキストファイルに対して, 対話的にクリーニングと整形をする.
-
re-numbering:
- 入力: txt, yaml
- 出力: txt
- 一般に, 目次をOCRして得たテキストに書いてあるページ番号は, PDF本のページ番号と一致しない. その整合性が取れるように, テキストファイル内のページ番号を移動幅を細かく制御しながら一斉にスライドさせる.
-
2ymltoc:
- 入力: txt
- 出力: yaml
- 上の作業を経て, 体裁やページ番号が整ったテキストファイルを, pdftoc-rs の想定するyaml形式に変換する. 第X章やChapter X 等のキーパターンを検知してお手軽に階層構造を表現する.
- 【おまけ】toc-data-storage:
- (大雑把に)tidy-tocした目次データを置いたレポジトリ. 理工系書籍メイン. 既存データの修正や新規データ追加のプルリク貰えると嬉しい.
- 【おまけ】collect-zips:
- 上のOCRツールに食わせるzipファイルの移動と名前変更を行う.
pdftoc-rs を使って目次付与することを典型シナリオとして想定しているが, この想定は必須ではない. 他の目次付与ツールを使いたければ, 2ymltoc に代わる整形ツールを用意すればよい.
データ構造と役割分担
ここは読み飛ばしても問題ない.
re-numbering や 2ymltoc は, 入力のテキストファイルの各行が
(あれば構造的情報) 見出し ページ番号
という, スペース区切りで, 各行の末尾にページ番号が来るテキストファイルを想定している.
たとえば, 以下のようなもの.
Chapter 1 Introduction 1
1.1 hello world 1
1.2 have a nice day 10
....
Chapter 2 We Love Caffeine 30
2.1 coffee 31
1. Introduction 1
1.1 hello world 1
1.2. have a nice day 10
....
2. We Love Caffeine 30
2.1. coffee 31
Introduction 1
hello world 1
have a nice day 10
....
We Love Caffeine 30
coffee 31
tidy-toc はこのようなテキストファイルを作ることを目的にしてクリーニングや整形を行う.
ハンズオン
実際にどう使うのかを例示するために, 一冊分の目次データファイルを目次画像から生成する過程を以下に書く. 各ツールの詳細は, それぞれの README.md や (ツール名) --help を参照.
サンプルは, 東大出版の「線形代数の世界」とする. この本の目次PDFはこちら.
目次画像の OCR
日本語のファイルなので, ocr-japanese-doc-by-line で OCR する. インストール済だと仮定する. 以下のコマンドで your-directory に OCR 結果 la_ocred.txt が出力される.
# ocr by ocr-gcv.py
# similar command also works for zip file
/path/to/your-python3/ /path/to/ocr-gcv.py /path/to/la.pdf -d your-directory
# output: la.txt in your-directory
以下は, 出力されたテキストファイルの最初10行.
V
目次
はじめに….. …... iii
この本の使い方・・・・ viii
第1章線形空間......... ... ... 1
......
1.1 体|.. ...... ... .…...... 1
1.2 線形空間の定義 ・・・・ …...... 6
... ... . .. .. .. . . . . . . . .. .. ... ..
1.3 線形空間の例 ..... ............. ...... 12
明らかに, 不要な文字が大量にある. たとえば,
- 画像ファイル自体のページ番号
- e.g., 1行目の
V
- e.g., 1行目の
- 見出しとページ番号の間のピリオドの羅列
- はじめに
….. …...iii - 第1章線形空間
......... ... ...1
- はじめに
- 何の情報も含まないゴミ文字から成る行
- 6,9 行目
tidy-toc: OCR で得たテキストファイルのクリーニング
OCR で得たテキストファイルをクリーニングする.
オプションは色々あるが, よく使うのは以下.
-
-c,--clean: ページ番号手前のピリオド等の無意味な連続文字列を削除する- はじめに
….. …...iii -> はじめに iii
- はじめに
-
-a,--adjust: 各項目のナンバリング箇所や全角文字間のスペース調整- § 1. 集合と写像 -> §1. 集合と写像
- 俺 の 自 炊 -> 俺の自炊
-
-s,--select: 不要な行の削除- 上のサンプルの
V
- 上のサンプルの
-
-m,--merge: (内容的に)本来は一行なのに二行に分かれている部分をマージ- 東京の夏は\n地獄 31\n -> 東京の夏は地獄 31\n
-
-p,--page: ページ番号が欠けている, または前後比較して昇順になっていない箇所の修正を促す -
--ja: 日本語モード. 全角文字の存在を想定する.
これらを全部実行するなら以下.
tidy-toc /path/to/la_ocred.txt -mpcas --ja
対話的にクリーニングしている様子. 今回のサンプルでは, 運良く --merge は不要だったようだ.
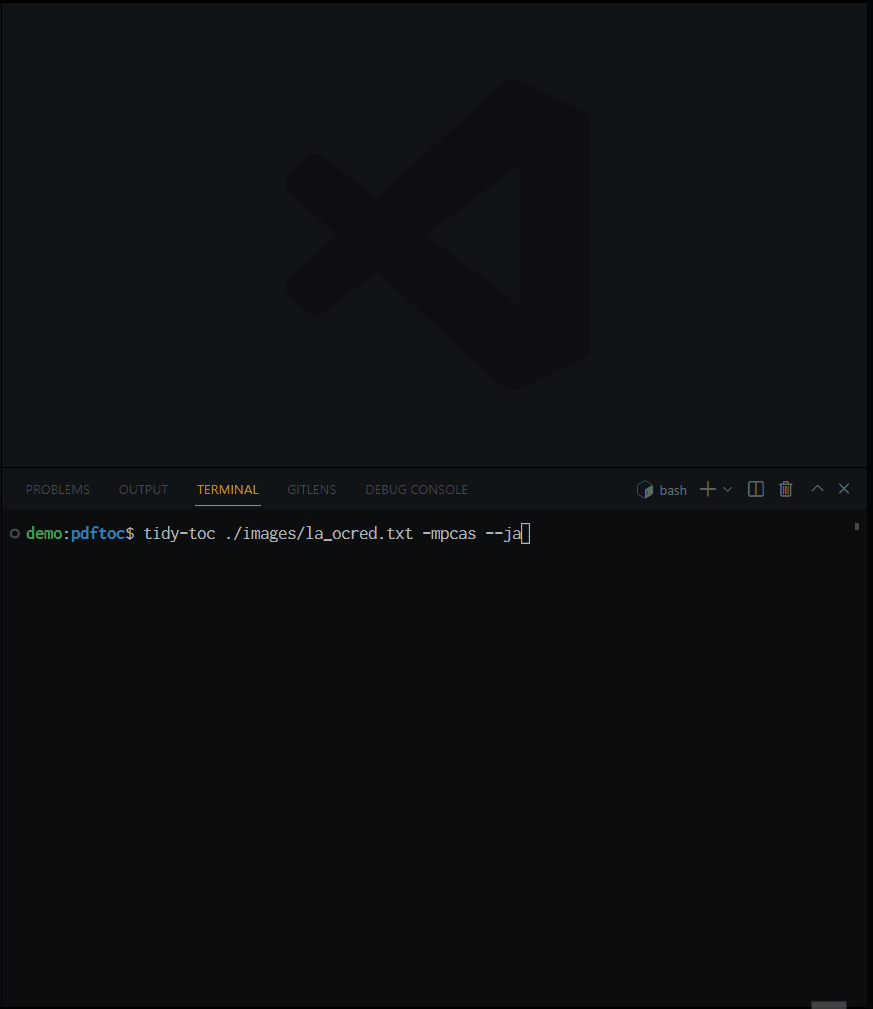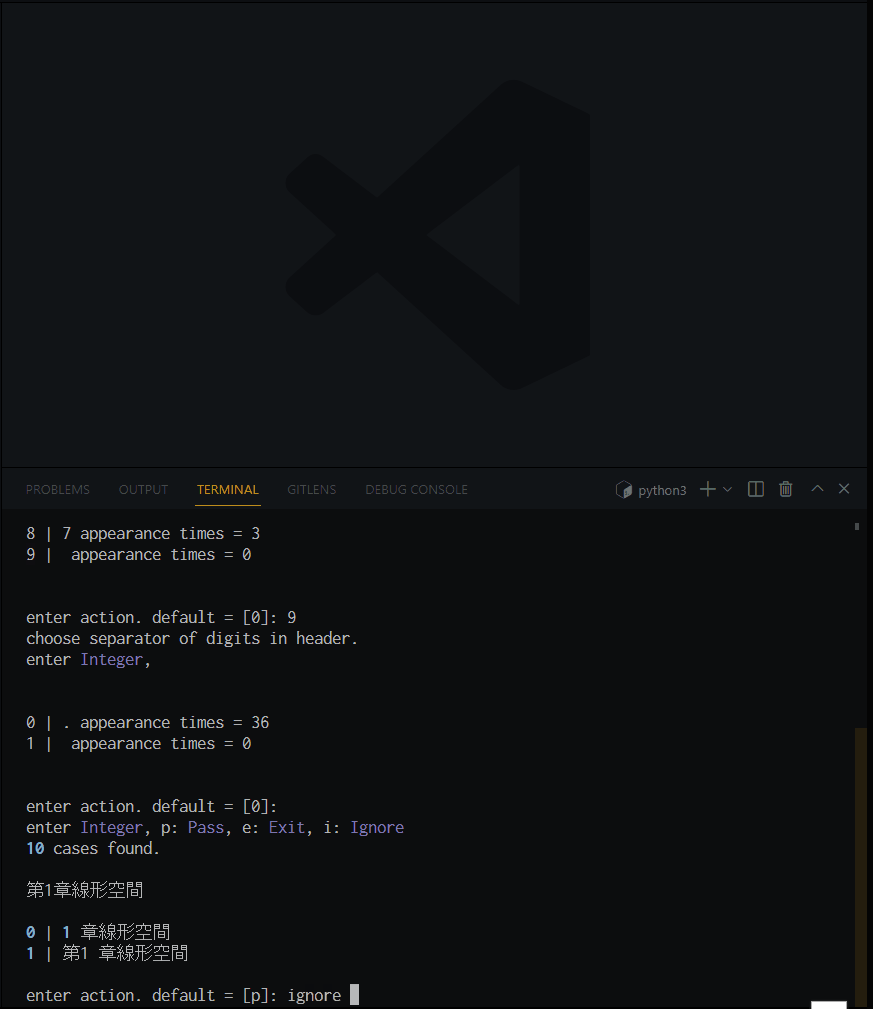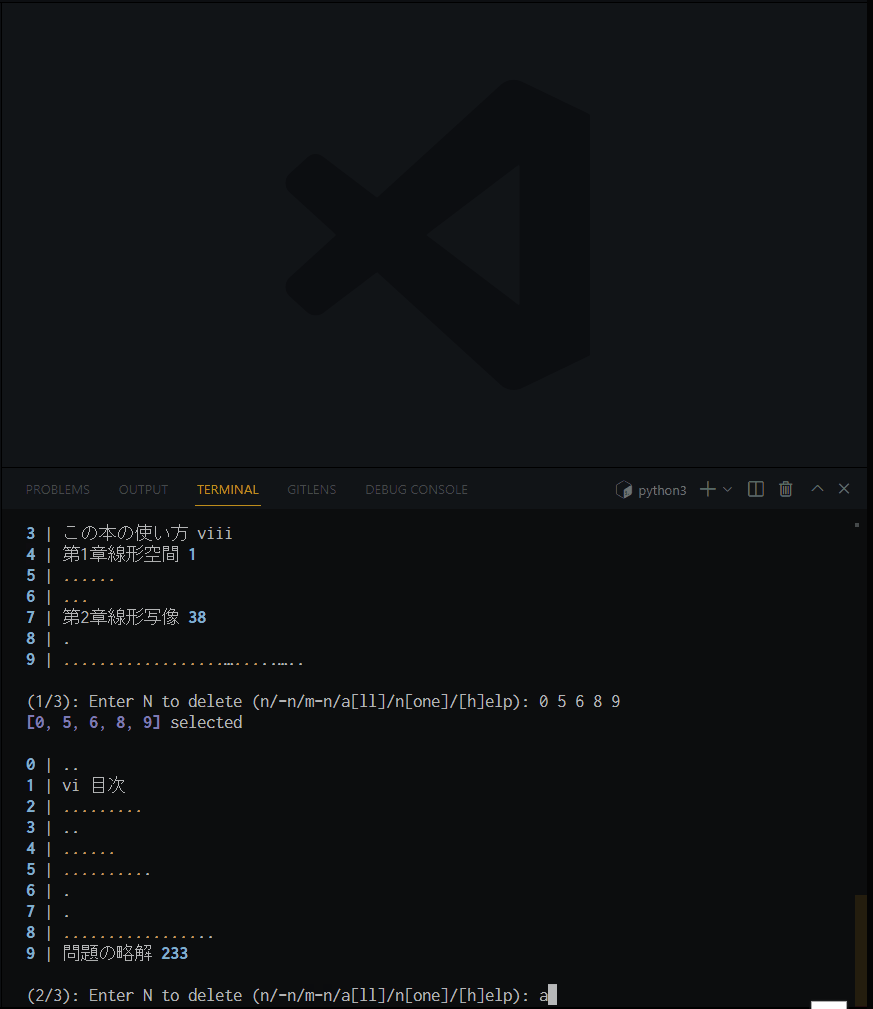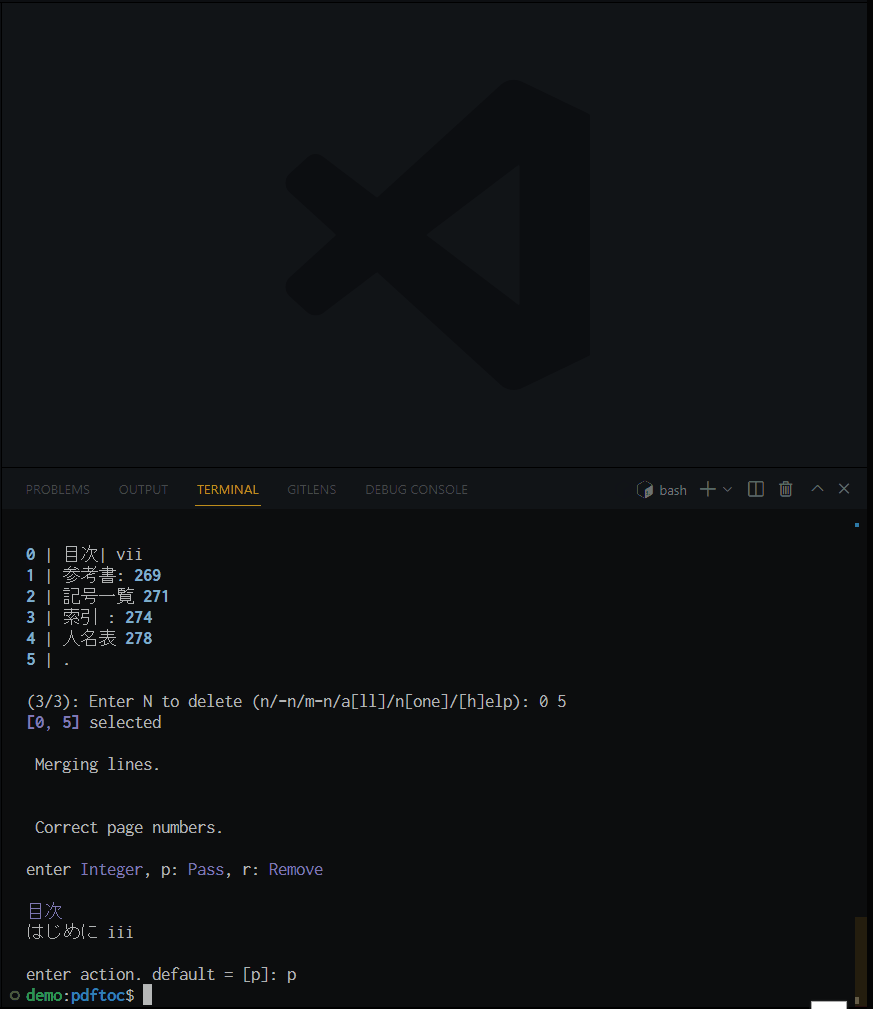
オプションで名前を指定しないと, (元のファイル名_cleaned).txt というファイルが出力される. 今回の出力結果は la_ocred_cleaned.txt.
目次
はじめに iii
この本の使い方 viii
第1章線形空間 1
1.1 体|.. 1
1.2 線形空間の定義 6
1.3 線形空間の例 12
1.4 部分空間 17
1.5 次元 25
1.6 無限次元空間* · 32
所々で余計な文字が残ってしまっているが(今後改善されるかも?), PDFの目次として使う気が起きる程度にはマシになったということにする.
re-numbering: ページ番号調整
la_ocred_cleaned.txt の各行に書かれているページ番号は, 紙の本の目次にある数字を丸コピしただけで, 自炊PDF本における実際のページ位置を示しているわけではない.
実際のページ番号は, 一般に, 表紙や前付け, スキャン時の白紙スキップなどによって, 丸コピ数字からはズレる. この工程では, そのズレを解消する.
全節(1.1~8.4)のページ番号の整合性を確認するのは大変なので, 現実解として, 各章のページ番号を比較することにする. これは, 全ページの整合性を担保する方法ではないものの, 誤差はあっても±1ページに収まることがほとんどで, 十分に実用的.
さて, 実際のPDF本におけるページは, 以下のようになっているとしよう.
第1章 線形空間 8
第2章 線形写像 45
第3章 自己準同形 83
第4章 双対空間 133
第5章 双線形形式 158
第6章 群と作用 180
第7章 商空間 199
第8章 テンソル積と外積 214
他方で, la_ocred_cleaned.txt のページ番号は以下のようになっている.
第1章線形空間 1
第2章線形写像 38
第3章 自己準同形 76
第4章 双対空間 126
第5章 双線形形式 151
第6章 群と作用 173
第7章 商空間 ・ 192
第8章 テンソル積と外積 207
つまり, テキストファイルは, 一律-7ページ分ズレている. であれば, 第1章先頭以降のページ番号に一律で7を足せばよい. re-numbering を使ってそれを行うには, 以下のようにテキストファイルを編集すればよい: la_ocred_cleaned_marked.txt
目次
はじめに iii
この本の使い方 viii
+ 第1章線形空間 1 -> 8
- 第1章線形空間 1
1.1 体|.. 1
1.2 線形空間の定義 6
これを以下のコマンドによってスクリプトに食わせると, ページ番号がスライドされたテキストファイルが出力される:
la_ocred_cleaned_marked_renumbered.txt
re-numbering /path/to/la_ocred_cleaned_marked.txt -m
# printed
# 001 | 目次
# 002 | はじめに iii
# 003 | この本の使い方 viii
-m オプションをつけると, ページ番号をアラビア数字で振っていない行(処理されずに無視される)を 行番号 | 内容 の形式で指摘してくれる.
それによると, 前付けのページが該当している. その行は, 番号を手打ちするか, または行ごと削除する必要がある. (正確には, 使用する目次付与ツールが, ページ番号未指定の入力を許容するか否かの問題だが, 危なっかしいので未指定は避けたい.) このサンプルでは削除することにした:
la_ocred_cleaned_marked_renumbered2.txt.
これで, 手元のPDFの目次情報が記載された, tidy なテキストファイルが出来上がった.
2ymltoc: yaml 形式へ整形
最後に, そのテキストファイルを適当なフォーマットに変換する. ここでは, pdftoc-rs の想定する yaml 形式に移す.
ymltoc /path/to/la_ocred_cleaned_marked_renumbered2 --ja
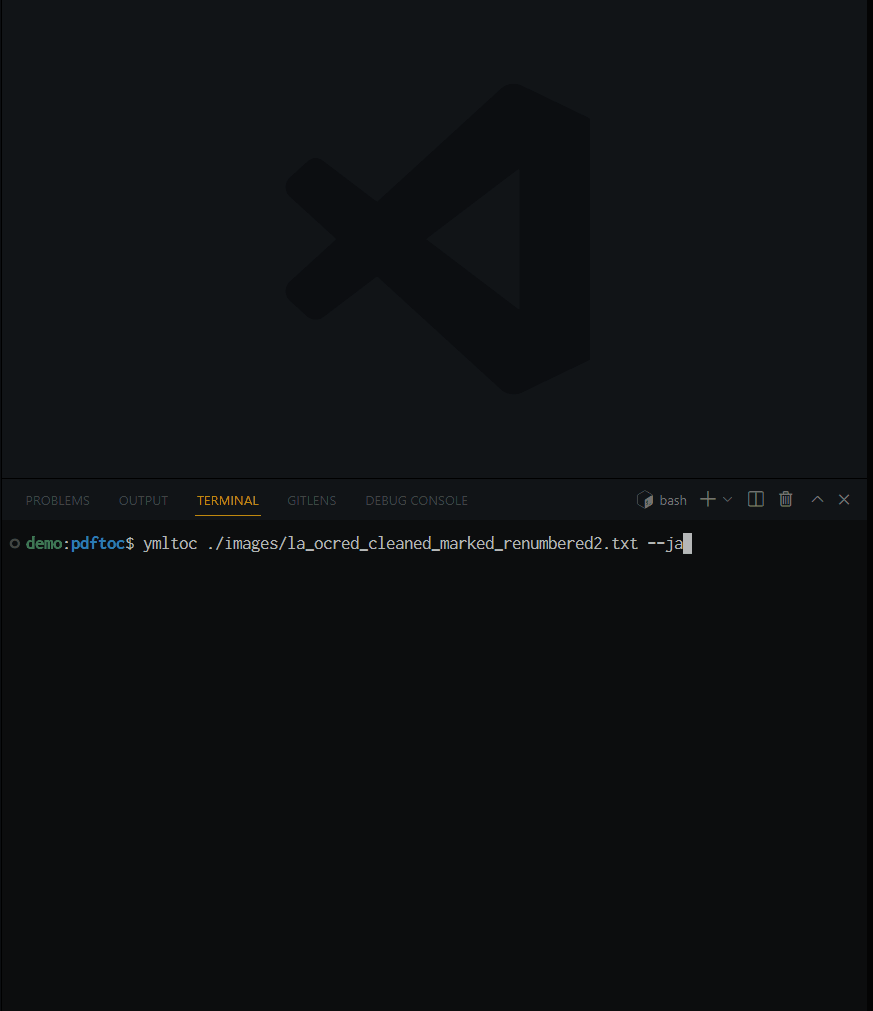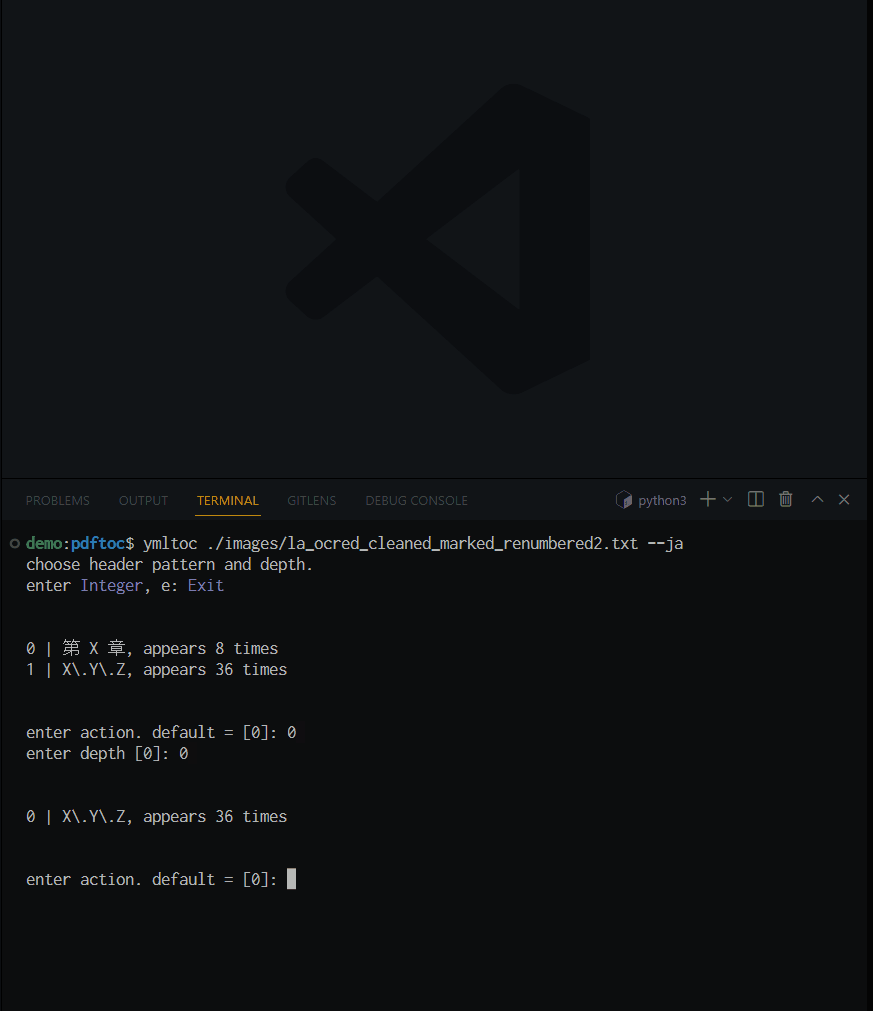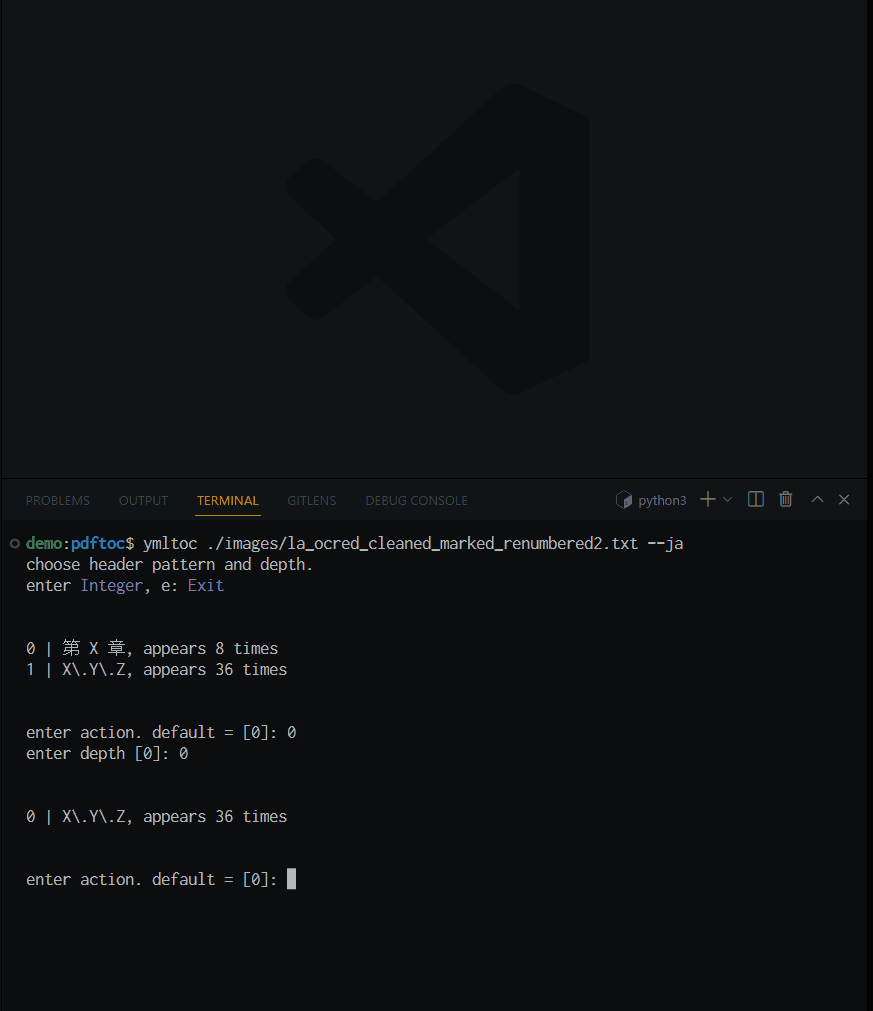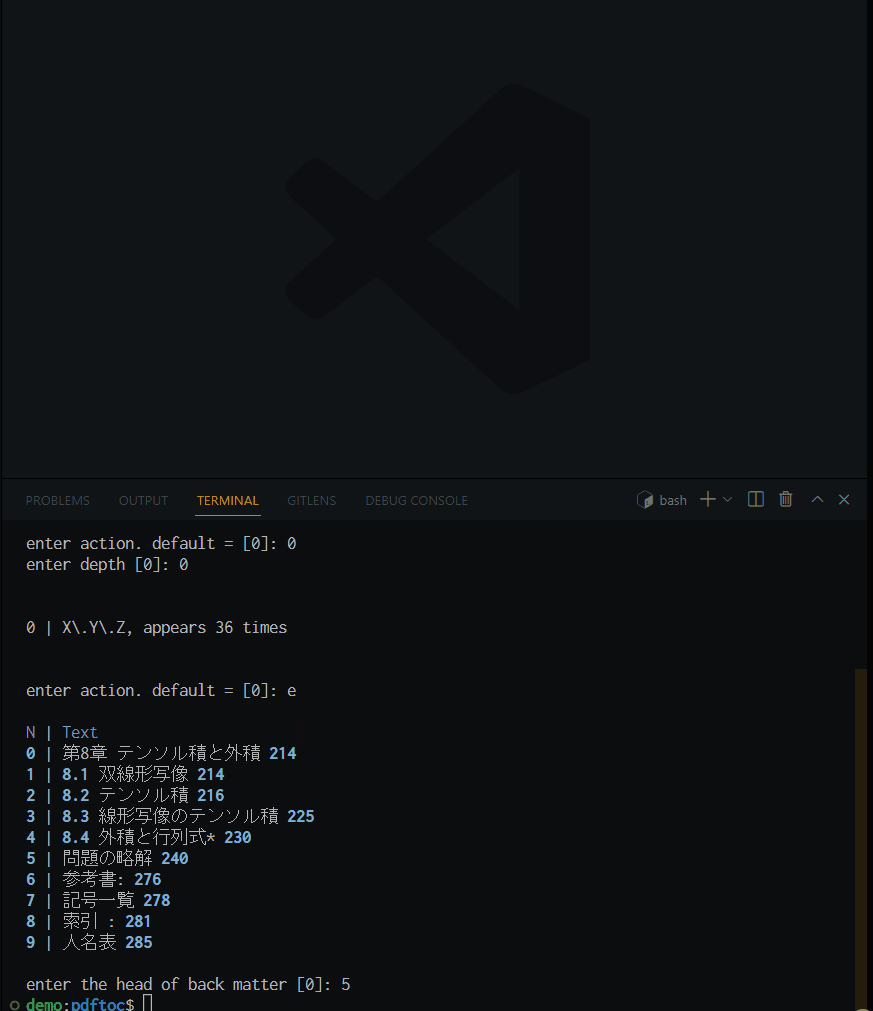
階層構造を持たせる見出しの形式と, 階層の深さを尋ねられるので, 好きなように答える.
ここでは, 第 X 章 を第0階層とした. すると, 第 X 章の後に現れる各行が自動的にネストされて(i.e., 第${0+1}階層として)出力される. 最後に奥付の位置を尋ねられたのは, この理屈で奥付が章の配下にネストされることを防ぐためだ.
かくして, めでたく目的の目次付与用のデータファイルが完成した.la_ocred_cleaned_marked_renumbered2.yaml.
- 第1章線形空間 8
-
- 1.1 体|.. 8
- 1.2 線形空間の定義 13
- 1.3 線形空間の例 19
- 1.4 部分空間 24
- 1.5 次元 32
- 1.6 無限次元空間* · 39
- 第2章線形写像 45
-
- 2.1 線形写像の定義 45
- 2.2 線形写像の例 54
- 2.3 行列表示 63
- 2.4 核と像 71
- 2.5 完全系列と直和分解* 76
- 以下略
これを pdftoc-rs に食わせると, 目的の目次付きファイルが出力される.
pdftoc /path/to/線形代数の世界.pdf
# PDFToC 0.1.0
# input: "/path/to/線形代数の世界.pdf"
# toc: "/path/to/線形代数の世界.yaml"
# output: "/path/to/線形代数の世界.toc.pdf"
まとめ
- 自炊PDF本に目次付与するツールを使うなら, 目次内容を記述したテキストベースのデータファイルが必要
- そのデータファイルは, 本の目次の画像ファイルからスタートして, ツールのバケツリレーで生成することができる
- このバケツリレーを利用しつつ, 最終的に pdftoc-rs 以外のツール T で目次付与したい場合は, tidy なテキストファイルを受け取って, T が想定するフォーマットに整形するツールを書けばよい
- 【おまけ再掲】理工系書籍の目次データなら, toc-data-storage を探すと見つかるかもしれない
Discussion