こんにちは!
シェルフィー株式会社で SRE を担当している石田です。
弊社では、本番のワークロードにて Fluent Bit を使っております。
今回、Fluent Bitの処理について理解を深めたので記事を書いてみました。
世界中で使われているとても有名なミドルウェアなので、参考になればとても嬉しいです。
はじめに
弊社では、ECS on Fargate で稼働しているバッチジョブのログをサイドカーコンテナ(Fluent Bit)を使い Datadog に連携しています。
ログのサイズが 16 KB 以上ある場合、shim-logger の仕様により、そのログは分割されてしまうため、 Fluent Bitにて分割されたログの再結合処理を行う必要性があります。
この点についてはDeNAさんの記事がわかりやすいので、詳細はそちらを参考にしてもらえたらと思います。
AWS ECS on Fargate + FireLens で大きなログが扱いやすくなった話 | BLOG - DeNA Engineering
上記の記事を参考に、Multiline 処理を実装しました。結果としては、一部ログは結合されていたのですが、本来結合されるべき全てのログが結合されているわけではありませんでした。
これに対して、結合されるべきログが全て結合されるような対応を行いました。
この件を纏める前に Fluent Bit自体の仕組みについて理解する必要性があると感じたので、この記事ではその点に焦点をあてて記載します。
環境構成について
- Fluent Bit V1.9.10
- Ubuntu 22.04.3 LTS
前提知識
スレッド
プロセス間通信、pipe
ファイルディスクリプタ(fd)
本記事におけるゴール
Fluent Bitの動きの仕組みを理解する。
そのためには、大きく分けて下記の3つを理解する必要があります。
- プロセス間通信
- スレッドプール
- イベントループモデル
様々な技術が使われていますが、それぞれに対する深掘りはこの記事では取り扱いません🙇♂️
それぞれの技術要素が Fluent Bitでどのように使われているのか?に焦点を当てていきます。
そもそも Fluent Bitとは?
Fluent Bitは、ログデータの収集、処理、および転送を行うためのオープンソースのログプロセッサおよびフォワーダーです。
下記のように様々なソースからログデータを収集し、収集したログをユーザが決めた宛先に転送するためのミドルウェアです。
出典: https://fluentbit.io/
Fluent Bit全体構成について
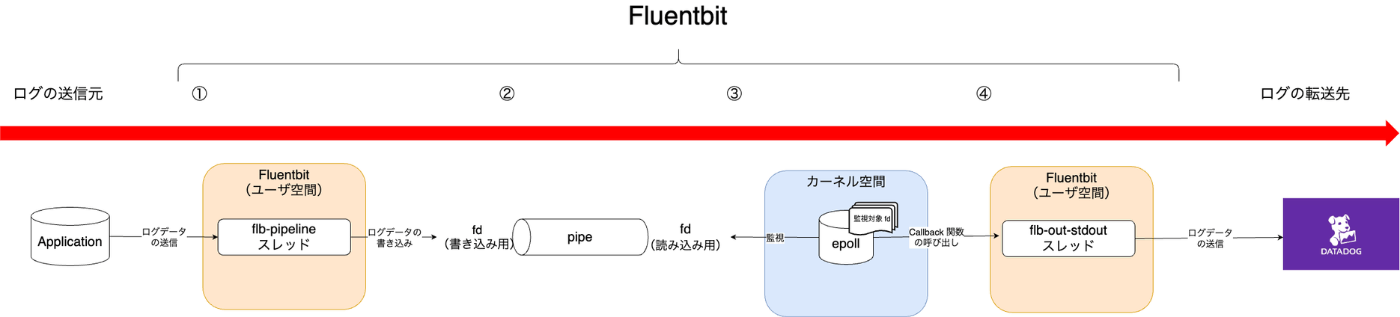
まず初めに、Fluent Bitの全体構成について概略図を明記します。
データの処理の流れは、下記のように左から右に流れていきます。(順番の通りです。)
以降の説明は、この概略図に則り説明をしていきます。(転送先は Datadog と仮定)
プロセス間通信について
4 種類のスレッドについて
スレッド同士の通信について議論する前に、スレッドそのものについて確認をします。
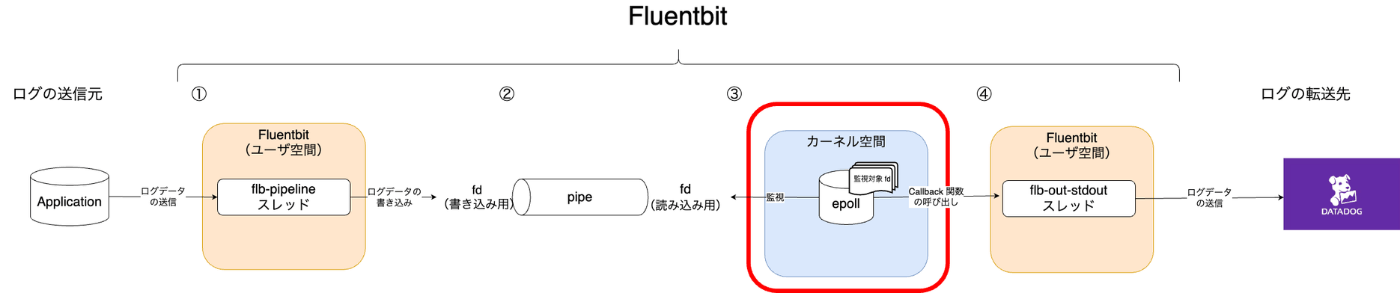
全体構成における赤枠の部分。(番号が少し飛んでいるけど、①と④のところです。)
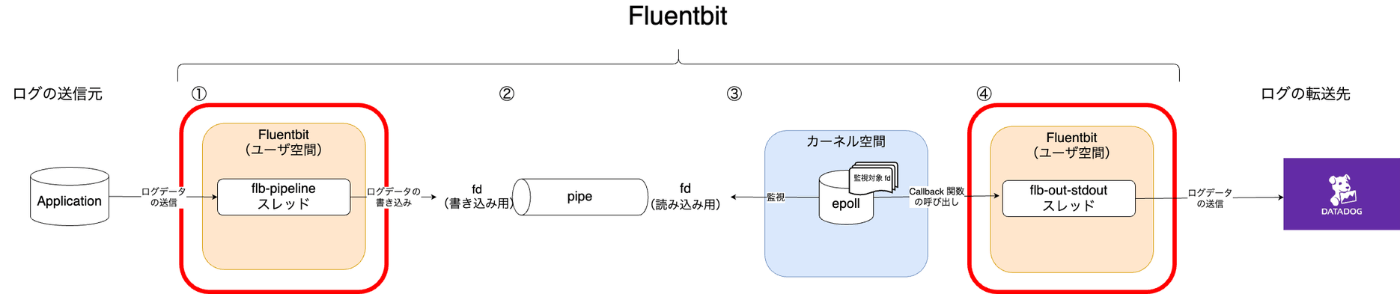
Fluent Bitにおけるスレッドは 4 種類存在します。
PID SPID TTY TIME CMD
139199 139199 pts/5 00:00:00 fluent-bit
139199 139200 pts/5 00:00:00 flb-pipeline
139199 139201 pts/5 00:00:00 flb-logger
139199 139202 pts/5 00:00:00 flb-out-stdout
今回、その中でもデータの入力と、加工、出力を担う flb-pipeline と flb-out-stdout について記載していきます。
flb-pipeline
このスレッドは、アプリケーションから tcp 経由で送られてきたデータの受信を行います。( Fluent Bitは起動のタイミングで内部的に軽量な HTTP サーバーを起動している)
Input プラグインについて
もう一つの側面としては、ログデータに tag を付与したり、マルチライン(複数行に分かれているログを一つに結合する)処理など。
Filter プラグインについて
このスレッドの役割は上記以外にもありますが、詳細については Fluent Bitの公式ドキュメントを参照して下さい。
flb-out-stdout
このスレッドは、外部サービスへのログ転送を担当しています。
例えば、CloudWatch や Datadog や Splunk など様々な送信先にログを送ってくれたりします。
https://docs.Fluent Bit.io/manual/pipeline/outputs
また、このスレッドはスレッドプール内で実行されています。
Fluent Bitは複数の宛先( Datadog、標準出力、AWS ClooudWatch、Splunk など)にデータを送信することができ、この送信先毎に各スレッドが割り当てられます。
スレッドプールを作成する理由は、単一のスレッドだと各送信先のコンテキストの切り替え処理や、コネクションの生成処理などにより処理が遅延してしまうためです。
そのため、各転送先毎にスレッドを作成して、より効率的にデータを処理できるようにしています。
flb-pipeline と flb-out-stdout の関連性
下記構成図における赤枠について説明する。
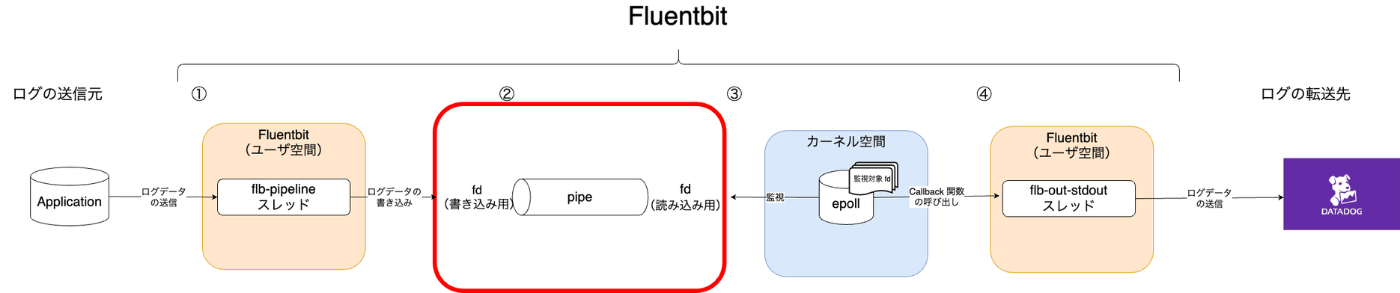
前述の通り、flb-pipeline スレッドと flb-out-stdout スレッドはそれぞれ役割、責任が異なります。
それぞれのスレッドで加工したデータを次のスレッドに引き渡す必要性があるのですが、
この、スレッド間におけるデータの引き渡し方法についてお話ししていきたいと思います。
結論から言うと、flb-pipeline スレッドは、外部からの入力データを加工・処理したデータを pipe 経由で flb-out-stdout スレッドに渡しています。
pipe 経由でデータを引き渡すためには、
- 読み込み用の fd (ファイルディスクリプタ)と書き込み用の fd が必要である。
- またこれらの fd を pipe によって繋ぐ必要がある。
実際に Fluent Bitによって作成された fd と pipe はこちら
fluent-bi 139199 ishida 32r FIFO 0,13 0t0 361237 pipe
fluent-bi 139199 ishida 33w FIFO 0,13 0t0 361237 pipe
ファイルディスクリプタ(fd)33 番が書き込み専用であり、32 番が読み込み専用であることや、2 つの fd が pipe 361237 で繋がっていることがわかります。
まとめると、
- flb-pipeline スレッドが書き込み用 fd に対してデータを書き込む
- flb-out-stdout スレッドが読み込み専用 fd からデータを読み込む
という方法でプロセス間通信を行っています。
pipe の作成処理のコードを確認する
(ここはコードの解説なので余力のある方が見てください!)
この2つの fd がパイプで繋がれている実際のコードは下記
- _mk_event_channel_create 関数の pipe 関数にて fd とそれを繋ぐパイプが作成される
static inline int _mk_event_channel_create(struct mk_event_ctx *ctx,
int *r_fd, int *w_fd, void *data)
{
int ret;
int fd[2];
struct mk_event *event;
// ここでpipeとfdを作成している。
ret = pipe(fd);
if (ret < 0) {
mk_libc_error("pipe");
return ret;
}
(省略)
*r_fd = fd[0]; // 読み取り専用のfdがfd[0]に格納されている
*w_fd = fd[1]; // 書き込み専用のfdがfd[1]に格納されている
return 0;
}
2. pipe と fd の作成後、書き込み用の fd にデータを書き込む処理は下記
flb_pipe_w 関数に書き込み専用の fd 番号(th_ins->ch_parent_events[1])と実際のデータ(task)が渡されて、書き込みが行われいる。
int flb_output_thread_pool_flush(struct flb_task *task,
struct flb_output_instance *out_ins,
struct flb_config *config)
{
int n;
struct flb_tp_thread *th;
struct flb_out_thread_instance *th_ins;
(省略)
// ここで書き込み用fdにログデータを書き込んでいる
n = flb_pipe_w(th_ins->ch_parent_events[1], &task, sizeof(struct flb_task*));
(省略)
return 0;
}
3. 書き込み処理がされた後、flb-pipeline スレッドが読み込み専用の fd からデータを読み込むという処理の流れになる。
flb_pipe_r 関数に読み込み専用の fd と読み込まれるデータを格納する task 構造体が渡されている。
(省略)
else if (event->type == FLB_ENGINE_EV_THREAD_OUTPUT) {
/* 書き込まれたデータをここで読み込んでいる */
n = flb_pipe_r(event->fd, &task, sizeof(struct flb_task *));
(省略)
fluent-bit/src/flb_output_thread.c at b99fc4dc7b76bce27dedf0c0afee47c3ce29711f · fluent/fluent-bit
以上の3箇所のコードにより、Fluent Bitが内部的に生成する二者のスレッド間(flb-pipeline と flb-out-stdout)でのプロセス間通信が可能になる。
プロセス間通信における課題
ただし、プロセス間通信だけでは課題があります。
その課題とは、flb-pipeline スレッドによって書き込み処理が行われた直後、即座に flb-out-stdout スレッドに処理を移管できず、即時性が欠けてしまうということです。
別の実装方法としては、flb-out-stdout(データの読み取りスレッド)が逐一 fd からデータを読み込める状態にあるのか、ポーリングで確認するという実装方針もありますが、スレッドが CPU リソースを過剰に消費したり、他のスレッドの処理をブロックしてしまい、結果的に処理が遅くなってしまいます。
(ブロック、ノンブロッキングなどこの辺りは、ノンブロッキングI/Oと非同期I/Oの違いを理解する が参考になると思います。)
定期的に確認するのではなく、fd からデータが読み込めるタイミングになったら読み込み処理を行うというという即時性を担保するために、後述するイベントポールが使われます。
イベントループモデルと epoll について
赤枠部分について説明します。
イベントとは
一般的に、アプリケーションにおけるイベントとは、ユーザーによるデータの入力、クライアントからのコネクションの生成、ネットワーク経由のメッセージなどがあります。
flb-pipeline スレッドからのデータの入力がいつ発生するのか?いつ、読み込みができるのか?分からない状態で定期的に fd を監視するには非効率ですね。そのため、入力が完了し、読み込みができる状態になったタイミングでアプリケーション(スレッド)に通知し、処理をさせるのがイベントループモデルです。これにより効率的に CPU などのリソースを使うことができるので、結果的に早く処理を行うことができます。
そして、Fluent Bitにてイベントループモデルの核心が、後述する Event Poll(epoll)です。
Event Poll(epoll)について
epoll とは
fd に対するイベントを監視・検知し、ユーザ空間で稼働しているアプリケーションに対して通知してくれる機能で、epoll 自体はカーネル空間で動いています。
実際にイベント発生時の通知内容の例としては、下記のようなものがあります。
- イベントが発生した fd
- どんなイベントが発生したのか(ex:読み取り可能なデータが存在する、エラーが発生した、などなど)
実際に通知される構造体は下記です
/* Event reported by the event loop */
struct mk_event
{
int fd; /* 監視されているファイルディスクリプタ */
int type; /* イベントのタイプを示す整数値 */
uint32_t mask; /* 発生したイベントのタイプを示すビットマスク */
uint8_t status; /* イベントの内部ステータスを示すバイト */
void *data; /* カスタムデータの参照。これはイベントに関連付けられたユーザー定義のデータ */
/* イベントに対するcallback関数ポインタ */
int (*handler)(void *data);
struct mk_list _head;
struct mk_list _priority_head;
char priority; /* イベントの優先度 */
};
epoll が必要な理由
『flb-pipeline と flb-out-stdout の関連性』で記載したように、epoll を作成することで処理の即時性が向上するという点が挙げられます。
epoll が fd のイベントを検知、通知するまでの流れ
- epoll インスタンスに対して、監視をしたい fd と event の登録を行う。以降は、カーネル空間で epoll インスタンスが監視
- 監視対象の fd にデータが書き込まれたなどのイベントが発生
- epoll がユーザ空間で稼働しているアプリケーションに対して、監視対象の fd にイベントが発生したことを通知
- アプリケーションは、epoll インスタンスからの通知をもとに処理、加工
- flb-out-stdout スレッドが Datadog / Cloudwatch などに対してデータの送信

epoll 周りのコードを確認してみる
epoll インスタンスに監視対象の fd を追加する処理は下記。
- epoll_ctl 関数に epoll インスタンス自身の fd(ctx->efd)と監視対象の fd を渡している。
static inline int _mk_event_add(struct mk_event_ctx *ctx, int fd,
int type, uint32_t events, void *data)
{
int op;
int ret;
struct mk_event *event;
struct epoll_event ep_event;
(省略)
// 監視するイベントを ep_event 構造体に設定している
ep_event.events = EPOLLERR | EPOLLHUP | EPOLLRDHUP;
ep_event.data.ptr = data;
if (events & MK_EVENT_READ) {
ep_event.events |= EPOLLIN;
}
if (events & MK_EVENT_WRITE) {
ep_event.events |= EPOLLOUT;
}
// 監視対象のファイルディスクリプタを epoll インスタンスに登録する処理
// efd:epoll インスタンス自身のファイルディスクリプタ
// fd:監視対象のファイルディスクリプタ
// ep_event:監視対象のイベント(監視対象のファイルディスクリプタにどのようなイベントが発生した時に通知するか)
ret = epoll_ctl(ctx->efd, op, fd, &ep_event);
(省略)
}
2. 監視対象の fd に対してイベントが発生していないか epoll インスタンスが監視してくれている。下記がそのコード。無限ループ内で epoll_wait 処理が実行されている。この関数の戻り値はイベントが発生したファイルディスクリプタの数。
static inline int _mk_event_wait_2(struct mk_event_loop *loop, int timeout)
{
struct mk_event_ctx *ctx = loop->data;
int ret = 0;
while(1) {
ret = epoll_wait(ctx->efd, ctx->events, ctx->queue_size, timeout);
if (ret >= 0) {
break;
}
else if(ret < 0 && errno != EINTR) {
mk_libc_error("epoll_wait");
break;
}
/* retry when errno is EINTR */
}
loop->n_events = ret;
return ret;
}
また、epoll インスタンスに類似する機能として select / poll があるのですが、それらと epoll を比較すと下記のような特徴があります。
I/Oを多重化するためのシステムコール select,poll,epoll,kqueue
結果、select / poll がファイルディスクリプタを監視するのに計算量 O(n) に対して epoll はO(1) の計算量で監視を行うことができます。
まとめ
今回はFluent Bitの動作概要を記載しました!
探っていきたい領域がまだまだあるので、今後もこういった形でお伝えしていければと考えています!

「現場に馴染む」安全書類管理サービス「Greenfile.work」をつくる人として支えているプロダクトチームが日々向き合っていることや雰囲気をお届けします。
Discussion