DuckDBにdltでロードしたデータをdbtで整形してevidenceで可視化した
はじめに
以前の記事では、dltを使ってSpotify Web APIからデータをDuckDBにロードしてみました。この記事は、続編です。
dltでは、ELTのExtractとLoadができるので、Transformの部分をdbtを使ってみます。また、dbtで整形したテーブルをevidenceで可視化してみます。
使用するツール
dbt
dbt (data build tool)は、ほぼSQLだけでデータを整形し、データウェアハウスやデータマートの構築ができるツールです。dbtについては、こちらの本を参考してみてください。
evidence
evidenceは、MarkdownとSQLでデータの可視化ができる、いわゆる「BI as Code」なツールです。
この記事では詳細な使い方は紹介しませんが、コードでBIを作れてUIもめちゃくちゃ綺麗なので良いです。以前、evidenceでevidenceの紹介記事を書いてみたので、こちらも読んでくれると嬉しいです。
dbtでTransformしてみる
今回のコードは前回と同じGitHubのリポジトリで公開しています。
加工前のデータをDuckDBにロードする
今回は、以前使用したアーティストのtop tracksを取得するAPIではなく、アーティストの全曲を取得してみます。
Spotify Web APIでは、アーティストの全曲を1つのAPIでは取得できないので、以下の流れで3つのAPIを使う必要があります。
- アーティストのアルバム一覧からアルバムのIDを取得する: Get Artist's Albums
- アルバムのIDからアルバムのトラック一覧を取得し、トラックのIDを取得する: Get Album Tracks
- トラックのIDからトラックの情報を取得する: Get Track
dltでは、このような多段にAPIを使ってデータを取得することも簡単にできます。
例えば、アルバム一覧からアルバムIDを取得して、アルバムIDからトラック一覧を取得してトラックIDを取得するときは、"resources"の"params"に以下のように記述します。
"resources": [
# https://api.spotify.com/v1/artists/{artist_id}/albums
{
"name": "albums",
"endpoint": {
"path": f"artists/{artist_id}/albums",
"params": {
"market": "JP"
}
}
},
# https://api.spotify.com/v1/albums/{album_id}/tracks
{
"name": "tracks",
"endpoint": {
"path": "albums/{album_id}/tracks",
"params": {
"market": "JP",
"album_id": {
"type": "resolve",
"resource": "albums",
"field": "id"
}
}
}
},
],
アーティストのIDから全曲を取得するdlt sourceは以下のようにしました。
今回使用するdlt source
# Base URL
base_url = f"https://api.spotify.com/v1/"
# REST API configuration
config: RESTAPIConfig = {
"client": {
"base_url": base_url,
"auth": (
{
"type": "bearer",
"token": access_token,
}
if access_token
else None
)
},
"resources": [
# https://api.spotify.com/v1/artists/{artist_id}/albums
{
"name": "albums",
"endpoint": {
"path": f"artists/{artist_id}/albums",
"params": {
"market": "JP"
}
}
},
# https://api.spotify.com/v1/albums/{album_id}/tracks
{
"name": "tracks",
"endpoint": {
"path": "albums/{album_id}/tracks",
"params": {
"market": "JP",
"album_id": {
"type": "resolve",
"resource": "albums",
"field": "id"
}
}
}
},
# https://api.spotify.com/v1/tracks/{track_id}
{
"name": "track_details",
"endpoint": {
"path": "tracks/{track_id}",
"params": {
"market": "JP",
"track_id": {
"type": "resolve",
"resource": "tracks",
"field": "id"
}
}
}
}
],
}
# REST API source
source = rest_api_source(config)
GitHubも参考にしてください。
dbt側でDuckDBにロードしたテーブルをソースにする
ここからが本題です。
Spotify Web APIから取得しただけでは不要なカラムが大量にあって使いにくいので、dbtを使って整形したテーブルを作っていきます。
今回は、以下のような図のアーキテクチャを考えます。Bronze、Sliver、Gold、Platinumがレイヤーの名前です。今回は【dbt】命名規則を参考に、カラーモデル名を採用してみました。

Bronzeレイヤーが、dltでロードした生のテーブルとしています。dbtでは、jinja関数のsourceを用いてソースのテーブルを参照することが推奨されています。以下のようなYAMLファイルを書くことで、dltでロードしたテーブルをsource関数で参照できるようにします。
version: 2
sources:
- name: bronze
schema: naniwa_danshi
tables:
- name: albums
- name: track_details
- name: tracks
dbtで整形する
整形するSQLクエリをmodels/の下に作成します。以下のように、レイヤーごとにディレクトリを分けて実装します。
└── models
├── datalake.yaml
├── sliver
│ ├── sliver_track_details.sql
│ └── sliver_tracks.sql
├── gold
│ ├── gold_albums.sql
│ └── gold_tracks.sql
└── platinum
└── platinum_tracks.sql
実装したクエリは以下の通りです。
models/に作成したクエリ
Silver
with final as (
select
id as track_id,
album__id as album_id,
duration_ms,
external_ids__isrc as isrc,
external_urls__spotify as spotify_url,
popularity
from {{ source('bronze', 'track_details') }}
)
select * from final
with final as (
select
id as track_id,
name as track_title
from {{ source('bronze', 'tracks') }}
)
select * from final
Gold
with final as (
select
id as album_id,
name as album_title,
cast(release_date as date) as release_date,
album_type,
total_tracks,
external_urls__spotify as spotify_url
from {{ source('bronze', 'albums') }}
)
select * from final
with all_track_details as (
select
track_details.track_id,
tracks.track_title,
track_details.album_id,
track_details.popularity,
track_details.spotify_url
from {{ ref('sliver_track_details') }} as track_details
left join {{ ref('sliver_tracks') }} as tracks
using (track_id)
),
-- Remove duplicates by track_title
-- Keep the one with the largest popularity
final as (
select * exclude (row_num)
from (
select
row_number() over (
partition by track_title
order by popularity desc
) as row_num,
*
from all_track_details
)
where row_num = 1
)
select * from final
Platinum
with final as (
select
tracks.track_title,
albums.album_title,
tracks.popularity,
tracks.spotify_url,
albums.release_date
from {{ ref('gold_tracks') }} as tracks
left join {{ ref('gold_albums') }} as albums
using (album_id)
)
select * from final
クエリを実装したら、実行します。
dbt run
リネージを確認する
ref関数とsource関数を使用して実装しているので、dbtのドキュメント機能でリネージを追うことができます。以下のコマンドでドキュメントを生成してブラウザで見ることができます。
dbt docs generate
dbt docs server
ブラウザでは、以下のようなリネージグラフを見ることができます。クエリを書くだけで、このようにリネージも可視化できるのはdbtの便利なポイントだと思います。

evidenceで可視化する
可視化するマートテーブルを作成できたので、evidenceで可視化してみます。evidenceのはじめ方については他の記事を参照してみてください。
DuckDBがデータソースの場合は、sources/[datasource_name]の下にDuckDBのファイルを置き、初期クエリを書く必要があるようです。これに気づかなくて、少し手間取りました。
初期クエリ
select * from platinum_tracks
今回作ったものはこちらです。
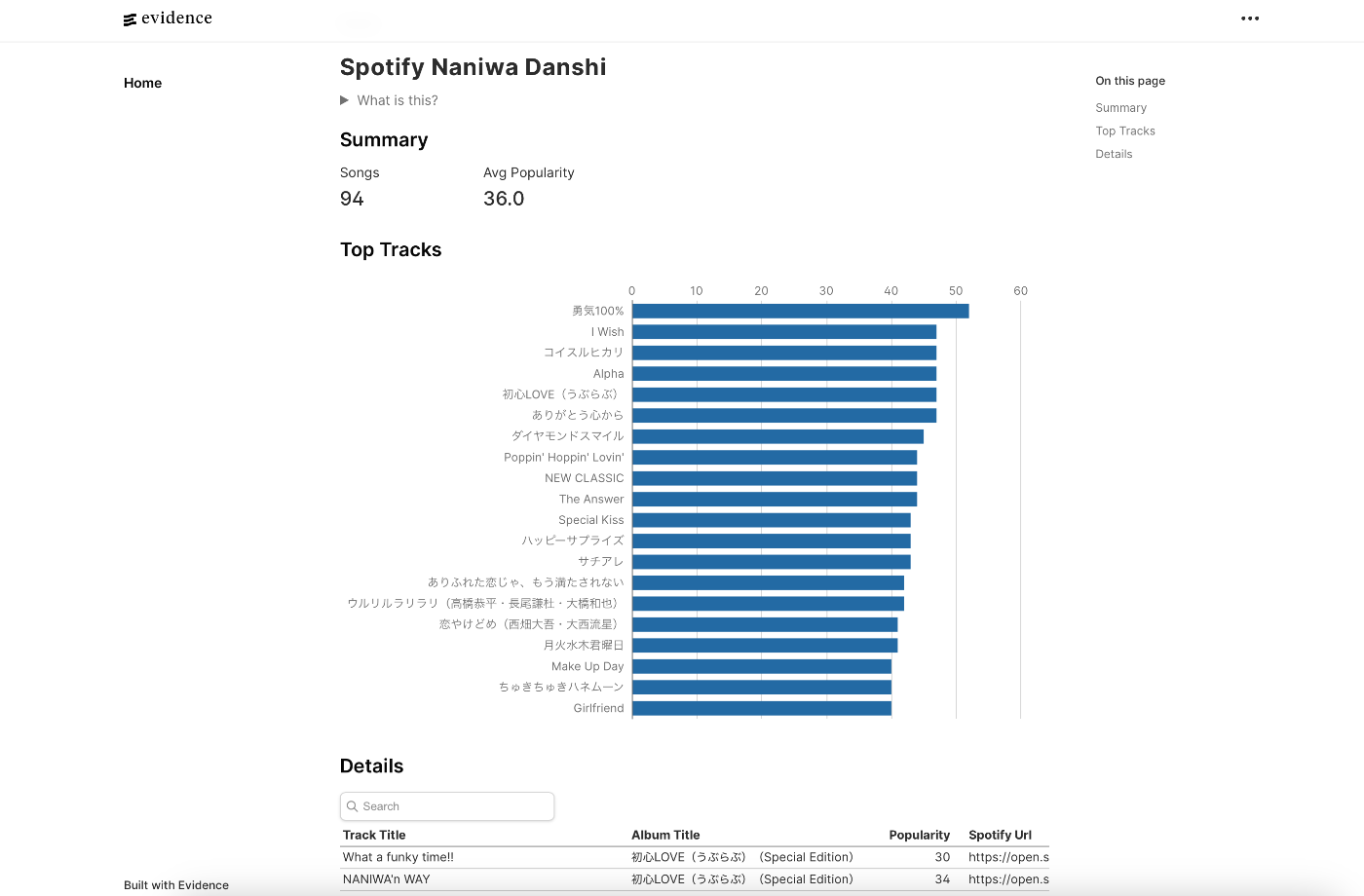
Evidence Cloudにアップしているので、実際に見てみてください。
また、リポジトリはこちらです。実装はこちらを参考にしてみてください。
おわりに
前回に引き続きdltを使ってデータをロードし、dbtを使ってデータ整形をしてみました。また、整形して作成したマートテーブルを使って、evidenceで可視化してみました。本当はdbtと相性がいいLightdashという可視化ツールを使ってみたかったのですが、DuckDBは対応してなかったです。どこかのタイミングでLightdashも触ってみたいです。
Discussion