将棋エンジンを作る、P2P通信対戦をする、対戦AIを作る
Claude Codeを使ってどこまで複雑なアプリを自分が作れるかのログ。
2025年9月にはCodex CLIも仲間入りした。
使っている技術
- turbo(Node.jsのモノレポ構成)
- web: UIの代表例
- React: UIコンポーネント
- Zustand: 状態管理
- WebRTC: P2Pをサーバレスで実現してwebブラウザでの対戦を実装
- desktop
- Tauriを使い、UIはReactを使う予定
- WebとUIの資産を共通化することを計画している
- 今のところはサーバーを用意しないつもりなので、Desktopの方がWebよりマシンパワーを生かした動作が出来ると期待
- core: ゲームルールを置く(全部Rustに置き換えたので削除予定)
- Node.js
- rust-core: ゲームルール、対局時間管理、USI対応、NNUE
- AI
初期はNode.jsで書いていたがパフォーマンスを出せる期待のある & デスクトップ版への展開も出来るRustで書くことにする(Electronを使えばNode.jsでもいい、要するに好み)
エンジン部分が(主に探索の)パフォーマンスが欲しいのであって、デスクトップアプリ(UI)レイヤーはそこまでパフォーマンスセンシティブでは無さそう。
- AI
- web: UIの代表例
最新状況
初期に作った超弱い対戦CPUがある。Node.jsで適当に作らせたもので、将棋ルールがやっとわかるくらいの自分よりも弱い。
Rustで書いているエンジンとの統合をすればきっと少しは強くなると思うが、GUIも刷新したいと思っているんでしばらくは弱いまま。
このページは近日中に全置換えされる予定。
生成AIでvibe codingってのをやってみたい
将棋を最近覚えたのでアプリを作ってみたくなった。
現代は生成AIが0→1の実装は得意なのでとりあえず動くものは出来るだろうと期待。
オセロ(reversi)は簡単すぎて学習済のデータでプロンプト1発で出来てしまいそうだが、将棋くらいだとそこそこ人間も頑張らないといけないとだろうなと思いながら着手。
webの人間なので最初はwebアプリを目指すが、ある程度色んな環境で使いまわせるようにcoreロジックとUIを分けて作ることを意識して生成AIに指示を出して進めた。
最初はChatGPTと一緒に要件定義をふわっとやってGitHub isseusを作成して、Codexでタスクをやらせるというのを試みた。
が、あんまりCodexがやるタスクのクオリティに満足できず、しばらくしてClaude CodeのMAXプランを契約した。ここからコーディング(の依頼)がとてもやりがいあるものになった。
数日である程度は動くwebアプリが出来た。
GitHub Pagesにdeployすることにした。
通信対戦したい
それらしいアプリはできたものの、将棋の知らないルール(特殊勝利条件などや、打ち歩詰めなどの禁止された手)がそこそこあり、調べつつ実装した。
1人でボードを操作できるようになったが、将棋は1対1の対戦ゲームなので、自然な発想として通信対戦をしたくなる。
zennの記事で
を見て久しかったのでこれを参考に、シグナリングサーバー無しでのP2P通信を実現したいと考えた。
今のアプリではゲームエンジンは使っていないので、Bevy前提のcrateは使わずに進められるかをClaude Codeと考えた。
zenn記事を読ませたり、記事中のGitHubレポジトリをgit cloneしてきてソースコードを読ませたりして、指示だけでP2P通信を実装させようとしたが難航した。
いきなり将棋の通信対戦機能を作りたいと依頼してもうまくいくわけもないので、単なるテキストのやり取りを出来るChat機能だけを実現するのをゴールとして初期実装をした。
紆余曲折があったが、参考記事のcrateは使わずClaude CodeのContextからは忘れてもらって、WebRTCを使うという方針で実装方針を立てなおしてとりあえず動くものが出来た。
最初に出来たのが以下(Reactコンポーネントでもなく、単なるhtmlにRustでbuildしたWASMのWebRTC機能を読ませたもの)。
これが動いたとき、こんな簡単にP2P通信できるんだっていう感動があった。
いい時代になった。
紆余曲折
これが出来るまでにClaude Codeが作業をよく投げだす事態にあった。
P2P通信が出来るようになった、との報告があり、確かにブラウザを2つ起動してコネクションを確立しているが、実際はシグナリングサーバーをlocalで立てている、という実装を提出された。
作業報告の最後の注釈で、「シグナリングサーバーをlocalで立ててそれ経由で通信できます、TODOとして真のP2Pを目指します」と書かれていた。
これを複数回繰り返し、結局サーバレスP2Pを諦めて同じ方針に落ち着き続ける挙動が見られたので、contextをリセットして要件をまっさらな状態で一緒に考えるという文脈を作ることで上記のものが出来た。
途中で libp2p というcrateを生成AIが見つけて使おうとしたがやめた。
結局 web-sys(JavaScriptラッパーで、大体のJavaScriptのAPIを呼べる理解をしている)でWebRTCを書いた。
これをベースに、将棋アプリで通信対戦が出来るようになったのが以下の変更。
参考記事がRustだったのでRustでWebRTCの実装を持っていてJavaScriptでWASMをロードして使うという実装になっているが、この時点のコードだとRustを介在させず純粋にJavaScript(TypeScript)でWebRTCを書いても良かったが、Rustで書かれていると無条件の満足感が生まれるのでよしとした。
友達に触ってもらって確かに通信対戦できることを確認できて満足した。
触っていると気づくUI不具合やバグは色々出た。
サーバーを絶対の状態のstoreと出来ないので、お互いのclientの情報で乖離が出たとき(盤面リセットを片方のプレイヤーだけが実施する等)には正常には進行不可能な状態になるなど。
client間で状態の整合性を取り続ける工夫を入れる必要があるが、今はそこの品質はいいかなということで深入りはしていない。
開発スタイル
プロンプト
ある程度アプリが出来てコードベースが大きくなる & タスクの応用度が上がってくると、的外れな生成をすることが目立つようになった。
よく言われているplanモードで実装計画を立ててから実装させるというのが本当によく効いた。
むしろこうしないと何もうまくいかない。
また、実装計画を立ててそのまま実装、だと作業途中でコンテキストウィンドウがいっぱいになって、 /compact でコンテキストを圧縮した後に露骨に作業品質が落ちるのが見られる。
複雑なタスクをやらせつつ、コンテキストウィンドウの問題を何とかするために、実装計画をドキュメントファイルとして吐き出させて、実装時にはドキュメントを参照させて必要分のコンテキストを補うという方法をとるようになった。
また、TDDで進めないと作業チェックが最後の最後のユーザーサイドでの結合テストだけになってしまうので、実装計画を立てるタイミングでタスクの細分化と、テストケースを考えることもセットで行った。
ある程度繰り返すと使い捨てでいい実装計画(詳細が書かれすぎてそのうちすぐに実装との乖離が出る)ドキュメントが出てくるので、こいつらをどう処理するか(消してしまうか、残しておくか)で少し悩んだ。
一旦はarchiveディレクトリに移してgit管理はしておく、ということにした。
CI
タイプチェック、format、lint、自動テストはだいぶ早いうちに導入した。
これはやっておいてよかったというか、やっていなかったら一瞬でコードベースが破綻していたと思う。
MCP
PlaywrightのMCPを登録していると指示をしたときや時折自主的にブラウザ操作を自分でやってくれる。
上手くいくこともあればいかないこともあって、大体はうまくいかない。
consoleにログを流すコードを書いて自分で確認するというのは部分的に小さく成功することもある。
Windows WSL環境で開発をしているが、ちょっと前(2020年くらい?)はWSLとホストの連携周りのトラブルやGUIアプリをWSLで動かすのに難があったが、今のWSL2、Ubuntu環境では特に設定なくPlaywrightでブラウザ操作していてこれはこれで感動した。
いい時代になった。
対戦AIを作る
Claude Codeに雑に作らせるととても雑な対戦AIは出来た。
将棋は詳しくないが違和感のある手を普通に打ってくる。
例えば人間が先手で以下の進行が発生する。
26歩→33歩(ここは自然)→25歩→55角
これが強い手なのか、自分には将棋の感覚が備わっていないが、将棋の対局をYoutubeで見るには見たことが無い進行ではあるし、実際自分が適当に差しても勝ててしまう。
世の中にフリーで遊べる将棋のサイトのAIの方が何倍も強い。
それはそうと、勝手に手を指してくれるAIが出来たのはとても嬉しい。
ここまでの開発はP2Pで少し停滞したのと、細かい将棋のルールを抑えるのにちまちま時間を使ったくらいで、概ね作業はずっと前に進んでいた。
定跡を搭載
今まさに詰まっている。
簡単な序盤の定跡をJSONファイルなどで手で(生成AIに手伝ってもらいつつ)作って対戦AIに読ませる、という事自体は小さく成功したが、これだけでは満足できない。
将棋エンジンを調べてみた。
一番有名そうなのが
であり、ここの方がなんと定跡ファイルを公開されている!(MITライセンス)
ということでここのYaneuraOu形式の定跡ファイルをなんとか取り込めないかという試みを始めた。
課題
定跡ファイルが470 MBある。
Webアプリでこの要領のファイルをアプリで読ませてきびきび動かすことは現実的ではないと思う。
ここでフロントエンドのパフォーマンスを最適化するための施策を打つ必要が出てきた。
やりたいことは
- 定跡を対戦AIに搭載できるように実装を拡張する
- YaneuraOuさんの定跡ファイルのパーサーを作る
- 自前のアプリで使える形式に圧縮する
である。
パーサーを作ることについてはCLIツールでよいのでスクリプトをClaude Codeに書かせようとするとPythonで書き始めたので、Node.jsで書くように指示しなおした。
しかしNode.jsで作ったファイル操作スクリプトを実行するとclaudeの端末が落ちることが頻発した。
heap limitのエラーが出ていて、最初はNode.jsのスクリプトが悪いのかと思っていたが、claude自体がnpmパッケージで配布されているようにNode.jsで動いているのでclaudeのプロセス内で大きなファイルを扱うプロセスを呼ぶとメモリがいっぱいになってしまうらしい(?)。
対応としては人間がファイル操作スクリプトの実行をする、もしくはプロンプトで定跡ファイルを使ったスクリプトを実行するときはファイルサイズに気を付けて一部だけ読んでスクリプトを動かす、などの指示をした。
Node.jsで色々試行錯誤したが(自分が定跡ファイルのファイル形式をちゃんと見ず、また知識が無かったのもあって)ろくなものが作れず、Claude Codeが出来たと言っている生成物を読ませる対戦AIの実装は全く機能しなかった。
コードはだめだが、アプローチとしてWebWorkerを使うことと、一気に大きなファイルを読み込ませるのではなく、定跡ファイルを分割して少しずつバックグラウンドで読ませていく、というアイデアだけは抽出できた。
今までで一番大きな詰まり方をした。
コードベースは単発スクリプトや生成データ、それを読み込むアプリの実装で散らかり、リトライするたびに発散する一方である。
CLIツールのパフォーマンスが気になったのでNode.jsではなくRustでCLIを作り出し、パフォーマンスは確かによくなったが正しい処理を出来ているのかちゃんと判断できない、Node.jsの残存コードが残ったまま、など新たな問題を産んだ。
ここで一度立ち止まってちゃんとソースコードを自分で把握し、発散しきったものを整理することにした。
ファイル整理
大体整理した
区切りがついた時点のcommit
- 単発開発用の一時ドキュメントをarchiveに移す
- 未参照コード・ファイルを消す
- 呼び出してはいるが不要な処理を消す
- TODOのように実装途中でそれらしくごまかしている箇所を消す
- TypeScriptのclass構文をなくす
などなど
CLIツールはNode.jsではなくRustにしたことで実行時パフォーマンスが明らかによくなったので嬉しい
将棋エンジン調査
どうも、チェスのエンジンの実装を参考に将棋用に作ったエンジンも多いらしい。
確かにボードゲームとして将棋とチェスはそこそこ似通っているので、対戦AIの作り方で同じ考え方が通じるところもあるのだろう。
C++製が多い。
YaneuraOu
多分国内で一番有名どころ?
将棋AIの水匠が公開されていてこれを使って遊ぶYoutube動画をしばしばみる。
定跡ファイルを公開されていて、界隈の研究の底上げにも貢献されていそう。
Fairy-Stockfish
Apery
C++版 もあるが、こちらは開発終了していて、Rust版に移行しているらしい。
- Rust製
- アルファベータ探索アルゴリズム
- KPPT(King-Piece-Piece-Turn)評価関数
- マルチスレッド並列探索
stoat
比較的最近作られた将棋エンジン。
chessのエンジンを作っている方が将棋のエンジンも作り始めているみたい。
dobutsu
動物将棋?というおそらく将棋ライクなゲームのエンジン。
tenuki-d
将棋AIのTanukiを作っている方?
Tanukiをもじったネーミング。
- Dart製
JapaneseChess
将棋は海外だと JapaneseChess と呼ぶのだろうか。
Juliaで書かれている。
This Japanese Chess Engine works with the "Shogi Dokoro" Shogi UI frontend system.
と記載があり、 Shogi DokoroというUIシステムが世の中に知られているらしい。
bonanza
Mar 17, 2025にpublic archiveになっている。
名前を聞いたことがあるので、当時(~2018年?)有名だったのであろう将棋AIと思われる。
cshogi
Pythonライブラリと書かれているので、将棋エンジン本体というよりは開発者・ユーザー向けの補助ツールの側面が強いのかな。
Aperyの名前が出てきて、一部はAperyを流用しているとのこと。
やねうら王、Aperyが日本国内だと有名なのかな。
python-dlshogi2
無印のpython-dlshogiもあった。
cshogiと同じ作者の将棋エンジン。
DeepLearningShogi
これがdlshogiと呼ばれているもの?
hachu
将棋だけでなく大、中、小(漢字は多分これ)将棋のAIエンジンらしい。
将棋派生のゲームなら同じ感じでAIエンジンを作れるだろうのでまとめて作っているのか。
チェスおよびチェス派生にも対応しているらしい。
nshogi-engine
2024年に作られ、最近も開発が続いていそうなエンジン。
Cudaのコードがある。
Topics
reinforcement-learning monte-carlo-tree-search shogi alphazero gumbel-alphazero
とそれらしい単語が並んでいて、alphazeroというのが囲碁のエンジン?らしい。
将棋より確か先に囲碁の方が対戦AIが人間より強くなったんだったか。
thunderlight-shogi
ここにあるリンクはどうもアクティブではないが、一時期特定のプラットフォーム上で将棋が遊べるサイトがあり、そのソースコードがOSSになっているらしい。
自分が作り切ろうとしている範囲はこのOSSくらいのものかなという気がしている(時間と好奇心のどちらかが途絶えたら終わりの予定)。
座標
調べものをしたり実装を見たりしていて色々な座標系があって混乱したので、ChatGPTに表を作ってもらった。
ここの理解が間違っていると、コードを書くときにの脳内将棋盤座標のマッピングがずれて正しい機能実装およびテストが書けない。
将棋座標 4 方式の早見表
| 視点 / 用途 | 表記フォーマット | 筋 (file) の並び | 段 (rank) の並び | 例:中央の「3四」 |
|---|---|---|---|---|
|
日本式 (棋譜・現実盤) |
数字(1-9) + 漢字(一-九)
|
右端 1 ➜ 左端 9 | 上段 一 ➜ 下段 九 | 3四 |
|
USI (プロトコル着手) |
数字(1-9) + 英字(a-i)
|
右端 1 ➜ 左端 9 | 上段 a ➜ 下段 i | 3c |
|
SFEN 盤面文字列 (FEN 互換) |
1段=9 文字を / 区切りで 9段並べる |
左端 9 ➜ 右端 1 (数字は逆向き) |
上段 (一段) ➜ 下段 (九段) | 1行目 7文字目 (行=2, 列=2) |
|
BitBoard index (行優先 0–80 の代表例) |
整数 0 … 80
|
左端 9 ➜ 右端 1 | 上段 ➜ 下段 |
38index = (rank-1)*9 + (9-file)
|
代表マスの具体例
| 日本式 | USI | SFEN (row,col)
|
BitBoard |
|---|---|---|---|
| 1一 | 1a | (0, 8) | 8 |
| 2八 | 2h | (7, 7) | 70 |
| 5五 | 5e | (4, 4) | 40 |
| 7七 | 7g | (6, 2) | 56 |
| 9九 | 9i | (8, 0) | 72 |
SIMD対応でのトラブルシューティング
SIMD(Single Instruction, Multiple Data)
ChatGPT o3のSIMDについての解説
SIMD(Single Instruction, Multiple Data)最適化とは
一つの命令で複数データを同時に処理し、演算の並列度を上げて性能を引き出す手法
― これをアプリケーション側・コンパイラ側の工夫で実現することが「SIMD最適化」です。
- 背景となる CPU の仕組み
用語 概要 代表的な ISA
スカラ命令 1 命令 = 1 データ x86 の ADD rax, rbx など
SIMD 命令 1 命令 = N データ(同種演算を並列) AVX2 (256bit)、AVX-512 (512bit)、NEON (128bit) など
例:AVX2 vaddps ymm0, ymm1, ymm2 は 256bit = 32bit×8 個の浮動小数点を一度に加算
CPU には ベクタレジスタ(ymm0、zmm0 …)があり、幅が広いほど一命令で扱えるデータ量が増える
- なぜ速くなるのか
演算器を水平展開
同じ演算を 4〜16 倍の並列度で実行(命令数と分岐が減少)
メモリ帯域が有効活用される
連続データを一括ロード/ストアすることでキャッシュヒット率が高まる
命令デコーダの負荷が軽くなる
命令本数そのものが減り、フロントエンドのボトルネックが緩和
-
SIMD 最適化のアプローチ
レイヤ 方法 Rust での例 注意点
自動ベクトル化 コンパイラがループを解析して SIMD 命令を生成 rustc -C target-cpu=native -C opt-level=3
LLVM が自動判定 分岐が入る・メモリアラインが悪いと崩れる
明示的インストリンシック CPU 固有命令を直接呼び出し core::arch::x86_64::_mm256_add_ps 可読性・移植性とバーター
高水準 SIMD API ポータブルな抽象レイヤ 1.70 以降の標準 std::simd::*
packed_simd_2, wide, simdeez など コンパイラ対応・安定度を確認
ランタイム分岐 起動時に CPU 機能検出 → 最適版を選択 cpufeatures, is_x86_feature_detected!("avx2") ビルドフラグ target-feature と組合せ -
実践での最適化ステップ
ホットスポット計測
perf, cargo flamegraph で重いループを特定
メモリ連続性を確保
Vec<T> / スライスを AoS→SoA に再構成することも
自動ベクトル化をまず試す
インライン化、制御フロー削減、#[inline]、#[repr(align(32))] など
インストリンシック or std::simd へ差し替え
性能を測りつつ段階的に(AVX-512 は AVX2 よりレーン数が多いがクロック低下にも注意)
CPU フィーチャ検出でフォールバック
旧世代 CPU や ARM Mac でも動くように
- 注意すべき落とし穴
アラインメント違反アクセス → セグフォ or パフォーマンス低下
loadu 命令なら動くが遅い。可能なら 16/32/64 バイト境界にそろえる
分岐の多いアルゴリズム → ベクトル化に不向き
分岐をマスク演算に変換できるか検討
メモリ帯域の飽和 → 演算よりメモリがボトルネックなら恩恵が薄い
クロックダウン(Intel AVX-512 など)
高度最適化ほど「省エネ/熱制約」の影響が大きい
- Rust での簡単な例(AVX2 256bit 加算)
#![feature(portable_simd)]
use std::simd::{f32x8, SimdFloat};
pub fn add_arrays(a: &[f32], b: &[f32], out: &mut [f32]) {
assert_eq!(a.len(), b.len());
assert_eq!(a.len(), out.len());
let chunks = a.len() / 8;
for i in 0..chunks {
let idx = i * 8;
// 安全:インバウンドかつ 8 要素境界
let va = f32x8::from_slice(&a[idx..]);
let vb = f32x8::from_slice(&b[idx..]);
let vc = va + vb;
vc.write_to_slice(&mut out[idx..]);
}
// 余り要素はスカラで処理
for i in (chunks * 8)..a.len() {
out[i] = a[i] + b[i];
}
}
std::simd はプラットフォームに応じて AVX2 / NEON などへ自動マップ
RUSTFLAGS="-C target-cpu=native" で最適コード生成を促進
まとめ
SIMD 最適化は「同一演算をまとめて処理 → 演算器を並列利用して高速化」するテクニック
まずは 自動ベクトル化 + プロファイル計測、必要に応じて 手動 SIMD を導入
Rust なら std::simd や インストリンシック、CPU フィーチャ検出クレートを活用すると保守性と性能のバランスが取りやすい
これらを意識してコードを設計・リファクタリングすると、NNUE 評価関数のような大量並列アルゴリズムでも レイテンシを抑えつつスループットを最大化 できます。
SIMD対応を入れたところ、CI上でWASM buildが失敗した。
発覚したタイミングは以下のcommit。
- feat: 反復深化中に合法手が見つからない場合のフォールバックを追加
https://github.com/SH11235/shogi/pull/27/commits/9d77f8e268eee93118fbdfe64517a3d82919b541
Claude Codeが言うにはWASMでは並列処理が未サポートという事らしい。
WASMでのSIMD/並列処理の制限
1. 並列処理(Rayon)
- WASMは単一スレッドモデルのため、Rayonなどの並列処理ライブラリは使用できません
- Web Workersを使った並列処理は可能ですが、SharedArrayBufferやAtomicsが必要で、セキュリティ制
限があります
2. SIMD最適化
- WASM MVPではSIMD命令はサポートされていません
- WASM SIMD提案は存在しますが、まだ全ブラウザで有効ではありません
- 現在のコードのsrc/ai/nnue/simd/wasm32.rsは将来のWASM
SIMD対応を見据えたものですが、実際には使用されていません
3. 現在のWASM版の動作
// src/ai/nnue/mod.rsで条件分岐されているはず
#[cfg(target_arch = "wasm32")]
mod wasm32; // 将来のSIMD対応用
#[cfg(not(target_arch = "wasm32"))]
mod native; // x86_64やARM向けのSIMD実装
実際にはWASM版では:
- 基本的なスカラー演算のみ使用
- SIMD最適化なし
- 並列処理なし
- そのため、ネイティブ版と比べて性能は劣る
4. テーブル制限エラーの原因
「Only 1 table definition allowed in MVP」エラーは、以下の複合的な要因で発生:
- lazy_static!マクロが複数のグローバルテーブルを生成
- 複数のwasm-bindgen外部関数定義
- 依存クレートも含めた全体でテーブル数が制限を超える
ChatGPT o3に聞くにはそんなことは無い、という話と確かな情報源
Vector instructions: With a massive 236 new instructions — more than the total number Wasm had before — it now supports 128-bit wide SIMD (single instruction, multiple data) functionality of contemporary CPUs, like Intel’s SSE or ARM’s SVE. This helps speeding up certain classes of compute-intense applications like audio/video codecs, machine learning, and some cryptography.
を出されたので、WASMでもSIMDは実現可能らしい。
Claude Codeの言うように、WASM版ではSIMD最適化を除外する対応自体はやっておいてPull Requestにし、これはmergeせずにCloseして記録に残すこととした。
実際はwasm buildに使っているactionがメンテが停止した古いものだったのと、crateのバージョンの問題だった。
localマシンと同じようにwasm-packをインストールしてbuildすればSIMD最適化を含んだWASM buildは問題なく実施出来た。
-
chore: CI上でのwasm build方法更新
https://github.com/SH11235/shogi/pull/27/commits/878a4af4d855b21cadcc3bd14a01cb821c2f5066 -
chore: wasm buildエラー解消のためパッケージ更新
https://github.com/SH11235/shogi/pull/27/commits/dca206228f77fabf679ed91d650a3d5b2e91805d
Rayon crateとSIMDの質問
ChatGPTに聞いた話をメモしておく。
Rustではrayon crateが並列処理を書くときにつかうものとして有名なようです
SIMD実装時にrayon crateは有用ですか? それともrayon無しで書いた方がパフォーマンスやメンテナンス性で有利ですか?
Web検索
SIMD と Rayon ─ “どちらか”ではなく“うまく棲み分ける”もの
| レイヤ | 目的 | 代表 API |
|---|---|---|
| SIMD(単一コア内並列) | 同じ演算を 128‑512 bit 幅ベクトルで一括処理し、命令数を削減 |
std::simd, インストリンシック |
| Rayon(マルチコア並列) | データをチャンク分割して複数スレッドへワークスティール実行 |
par_iter(), join(), ThreadPool
|
結論だけ先に
- 高速化ポテンシャルの最大化: 外側 を Rayon でスレッド並列、内側 を SIMD でベクトル化するハイブリッドが最速になることが多い。
- 維持コスト: Rayon はスレッド生成やワーク分割を自動化してくれるため メンテナンス性が高い。一方 “SIMD だけ/手動スレッドだけ” は制御自由度は高いがコード量とバグリスクが増す。
- 使わないほうがよいケース: 1 コアで数 µs 未満しか仕事がない 極小 ループ、あるいはメモリ帯域が律速でスレッドを増やしても帯域が飽和している場合。
1. 並列化の階層と相乗効果
┌─────────────┐ (Rayon: マルチスレッド)
│Board batch │ par_chunks(16K)
└─────┬───────┘
▼
┌─────────────┐ (SIMD: 8~16 値同時)
│ NNUE eval │ f32x8 + f32x8 …
└─────────────┘
- Rayon が扱うのは「ボード 1 万局面 を 16 チャンクに分割し、16 スレッドで並列評価」のような タスク粒度。
- SIMD は「1 局面の評価関数内で 256 bit レジスタ×8 個を回して畳み込み」のような ループ内部のベクトル化。
- それぞれが 別のボトルネック を潰すため、併用すれば乗算的なスピードアップが期待できる。ベンチマークでも “Rayon + SIMD” が単独より高い倍率を示している。
2. パフォーマンス上の判断ポイント
| 判断軸 | Rayon 併用が 向く | Rayon 併用が 向かない |
|---|---|---|
| 処理量/粒度 | 1 スレッドあたり数百 µs 以上の仕事 | 数 µs〜十数 µs の超短ループ |
| メモリ帯域 | キャッシュに乗る/演算密度が高い | 帯域飽和で CPU が待ち状態 |
| 同期頻度 | ループ終端のみ(reduce, collect など) |
頻繁なロック・共有更新がある |
| ターゲット | ネイティブ、サーバ WASM (threads 対応) | ブラウザ WASM(threads 未対応) |
計測が最重要
Rayon のスレッド切り替え・ワークスティールには 1 タスクあたり ≈15–50 µs の“固定費”がある。Criterion やcargo flamegraphで 「スレッド 1 つで十分か?」を測るのが最短ルート。
3. 具体的な実装パターン
use rayon::prelude::*;
use std::simd::{f32x8, SimdFloat};
pub fn eval_batch(weights: &[f32], inputs: &mut [f32]) {
// ① Rayon: バッチをスレッドごとに分割
inputs.par_chunks_mut(256).for_each(|chunk| {
// ② SIMD: 各チャンク内部を 8 要素ずつ処理
for values in chunk.chunks_exact_mut(8) {
let v = f32x8::from_slice(values);
let w = f32x8::from_slice(&weights[..8]);
(v * w).write_to_slice(values);
}
});
}
- par_chunks_mut がチャンク粒度を自動調整(with_min_len, with_max_len でチューニング可)。
- SIMD で実際の演算を高速化。
- スレッドプール制御は ThreadPoolBuilder::new().num_threads(n) で CPU 物理コア数に合わせるとオーバーサブスクライブを避けられる。
4. メンテナンス性の観点
観点 Rayon あり Rayon なし(手動スレッド)
コード量 ループ置換 + α で完結 crossbeam 等でスレッド生成・キュー実装
安全性 データ競合を型で防止、&mut 分割で静的保証 ミューテックス・チャネル管理が必要
ポータビリティ cfg(target_has_atomic) 判定で WASM などは自動シングルスレッド 自前で判定が必要
チューニング 分割サイズやプールサイズを API で変更 動的スケジューラを作るなら大変
結論: ほとんどのケースで Rayon の方が保守コストは低い。特殊要件がなければ Rayon + SIMD の二段構え が無難。
5. まとめ
- 役割が異なるため併用が基本
- SIMD = コア内ベクトル化
- Rayon = マルチコア分散
- 使わない判断は “小さすぎる仕事量” と “帯域飽和”
- 保守性は Rayon が圧倒的に楽
- 計測して閾値を見極める — Criterion, perf, rayon::current_num_threads() などでプロファイル
SIMD 実装時でも Rayon は有用か?
— 答えは Yes。まずは Rayon + SIMD で書き、ボトルネックが見えたらスレッド数・チャンク長・スケジューリングを調整し、オーバーヘッドが厳しい所だけ Rayon を外してみる進め方を推奨。
SIMDとRayonの併用をWASM buildで使うことの質問メモ
SIMDおよびrayonの併用はWASM build時にも有用ですか?
個人的に大きなポイント抜粋
環境依存
Cross-origin isolation を設定できないホスティング(GitHub Pages 既定設定など)は
SharedArrayBuffer が使えず Rayon がシングルスレッド化。ヘッダを返せる CDN/Edge(Cloudflare Pages、Vercel Edge Functions など)は問題なし。
以下は回答ほぼコピペ
Web検索
TL;DR
-
SIMD は WASM でもほぼどこでも動く(
simd128は Wasm 2.0 正式入り) -
Rayon 併用は “スレッド対応の WASM ランタイム” なら効果大
- ブラウザでは
SharedArrayBufferが必要 → cross‑origin isolation を有効化 - Rust 側は nightly +
atomicsでビルド、JS 側はwasm-bindgen‑rayonでプール初期化 - スレッドが使えない環境では Rayon は自動でシングルスレッド落ち(SIMD のみ動作)
- ブラウザでは
1. 現在のサポート状況
| 機能 | ブラウザ | Node.js / ランタイム | 仕様 |
|---|---|---|---|
| SIMD (v128) | Chrome 91+ / Firefox 90+ / Safari 15+(デフォルト有効) | Node 16.4+、Wasmtime、Wasmer ほか | Wasm 2.0 で 128‑bit SIMD(236 命令)追加 |
| Threads (+Atomics) | ○ ※COOP/COEP ヘッダ必須(SharedArrayBuffer 解禁) |
○(標準で有効) | 共有メモリ + Web Workers |
| Rayon in WASM |
wasm-bindgen‑rayon が Web Workers + SharedArrayBuffer で実装 |
ネイティブ std::thread がそのまま動く |
クレート側でフォールバックあり |
2. ビルド手順(Rust → wasm32-unknown-unknown)
# ❶ SIMD だけ
RUSTFLAGS="-C target-feature=+simd128" \
cargo build --target wasm32-unknown-unknown --release
# ❷ SIMD + Rayon (threads)
# - nightly で std を再ビルド
# - atomics & bulk‑memory を有効化
RUSTFLAGS="-C target-feature=+simd128,+atomics,+bulk-memory" \
cargo +nightly build \
--target wasm32-unknown-unknown \
-Z build-std=std,panic_abort
JS 側(wasm-bindgen)
import init, { initThreadPool } from "./pkg/your_lib.js";
await init(); // 通常初期化
await initThreadPool(navigator.hardwareConcurrency); // Rayon 用プール
✔ SIMD だけなら nightly 不要
✔ Rayon 併用時は nightly + atomics が必須(安定化は議論中)
3. 併用したときの性能と落とし穴
Mandelbrot デモ実測
実装 レンダ時間
シングルスレッド + SIMD 約 270 ms
Rayon 8 threads + SIMD 約 85 ms(≈3×短縮)
ハイブリッド構成(外側 Rayon / 内側 SIMD)が最速になる傾向はネイティブと同じ。
ただし…
オーバーヘッド
Rayon のスレッド生成 + Web Worker 起動は初回数 ms〜数 10 ms。
粒度が数 µs〜数 100 µsしかないループ では元が取れない。
メモリ帯域
JS↔WASM 間コピーが混ざると帯域が頭打ち。
SoA 配列 + バッチ処理が有効。
環境依存
cross‑origin isolation を設定できないホスティング(例: GitHub Pages デフォルト)は
SharedArrayBuffer が使えず Rayon がシングルスレッド化。
4. サーバサイド WASM(WASI / Wasmtime 等)
- SIMD: wasm32-wasi でも常時有効
- Threads:
- Wasmtime 28+ は wasm32-wasi-threads を正式サポート(--wasi threads)
- Rayon はそのまま動く(std::thread ベース)
- クロスオリジン制約が無いため設定は簡単
5. 実プロジェクトでの指針
ターゲット 推奨構成
Web ブラウザ 必須: COOP=same-origin, COEP=require-corp ヘッダ
大規模: SIMD + Rayon + wasm-bindgen‑rayon
軽量/レガシー: SIMD だけ/Rayon を cfg(target_feature="atomics") でガード
Node / Deno nightly + atomics ビルドで SIMD + Rayon
Edge / サーバランタイム
(Wasmtime, Wasmer) wasm32-wasi-threads ターゲットでビルドし、Rayon も通常使用
まとめ
- SIMD は WASM でも標準化済み ― +simd128 フラグで即利用可能
- Rayon 併用は threads 対応環境で大きな加速
- ブラウザなら wasm-bindgen‑rayon + cross‑origin isolation
- 非対応環境でもフォールバックが効く
- 判断基準は「処理粒度」と「ホストが threads を許すか」
→ まず SIMD + Rayon 版を計測し、必要なら --features=single_thread 等で簡易ビルドを併配布。
最適化最適化最適化...
チェスや将棋の歴史がそこそこあるためか、最適化手法はたくさん知られていて、生成AIは有名な手法は網羅的に知っているので最適化の案をたくさん出してくる。
良かれと思ってそのタスクを進めると、またその先に最適化タスクが発生する。
対戦AI全体像が完成する前に、枝葉末節の最適化タスクをするのは早くモノが欲しい人間視点だと優先順位が間違っている。
この辺は(知らない知識が知れて楽しいのでいいのだが)ある程度の塩梅で切り上げないとMVPさえ完成しない。
何年、何十年の研究や試行錯誤の成果を光速で駆けぬている感じで、全てを吸収しきるのは難しい。
ただ、詳しく知らずとも恩恵を受けられるのはいいことでもある(production codeだと慎重になる具合は変わるけど、趣味開発なら、まあ)。
開発スタイル
2025/07/17時点のやりかた
おそらく作業タスクの難易度があがっている事と、コードベースが大きくなっていることから既存のコードを破壊しないように作業する事が難しくなっており、Planモードで計画を立ててそのままGoではうまくいかなくなってきた。
以前に作ったPhase1~4の大枠の実装計画がある。
今はPhase3の将棋エンジン内部の実装をやっていて、Phase4がWebへの組み込みとなっている。
Phase3のタスクが項目として10数個あるが、これを読んでそのまま走らせるとすぐに破綻する。
実装計画をドキュメント化する
Planモードを使う。これは特に最近始めたものでもない。
この段階で、もし方針で迷うポイントがあれば、選択肢を列挙させてどう迷うのかも述べさせる。
別のセッションでコンテキストをリセットしてから作業させるので、全てファイルに出させる。
このドキュメントは開発用の一時ドキュメントであり、Git管理し続けるのも違うかなと思っていて、これをPull Request本文に使う(この辺はどうしたもんか試行錯誤中)。
プロンプト(Planモード)
〇〇の機能を実装します。
// 何かしらの公式ドキュメントなど参考ドキュメントがあれば読ませる
// リンクを貼って検索させるよりはMarkdownなどファイルに落として読ませる方がいい
// OSSをgit cloneしてきて特定ファイルを読ませるのも手
参考としてpath_to_document を読んで。
実装計画を立ててドキュメントを作って。
実装計画をレビューする
自分が詳しいものは自分でレビューする。
詳しくないものは頑張って知識をいれてレビューする......のは個人開発をサクサクすすめたいモチベーションからするとテンポが悪いので、ChatGPT o3にレビューをさせる。
タスクを細分化する(任意)、実装する
完成した実装計画が大きなスコープである場合は手動でタスクをピックアップする。
ピックアップしたタスクの実装計画が詳細に作れていない場合は再度実装計画を立てて詳細化する。
プロンプト(Planモード)
path_to_document を読んで実装しましょう。
→ToDoリストが作られる
このリストから作業量が大きくなりそうなのが見込めた場合はPlanモードを続けて
プロンプト
タスクnまで実装が終わったら作業を区切りましょう
(ToDoリストで新情報が出た場合)タスクn+1以降について、実装計画ドキュメントを更新して
この後 auto-accept edits で自由に作業をさせる。
途中で実装を諦めてTODOとして作業を止めて、形だけの関数をおくようなこともあるが、タスクの細分化をうまくやっておくと、これの発生確率が落とせる。
基本的にはContextの /compact が発生しない範囲でタスクが完了するのが望ましい。
作業をcommitする
必要なドキュメントはcommitするが、実装計画は恒久的にメンテナンス・参照したいものでは無いのでcommitに入れない(長期のタスクの場合は一旦git管理することもある)。
この時点でformatter, linterが通過する状態にする。
CLAUDE.mdでの指示、もしくはHooksの設定で品質チェックを自動で行うようにしておくのもいい(CLAUDE.mdでの指示はときどき無視される)。
タスクの区切りは基本的にtestを書くところまでとし、既存のテストが通過するところまで整える。
大きな破壊的変更を入れたいのでテストが壊れたまま無視して進んで最後に直すこともあるが、この進め方は難航することがある印象(そもそも破壊的変更を入れる行為自体が設計ミスなので難航するのは順当ではある)。
ここまでを繰り返す。
Pull Request作成、レビュー
ここで実装計画を本文に使い、localにある実装計画ドキュメントは削除する。
レビュアーに以下を使う。
- Claude Code Actions: CIで自動レビューが走る
- Copilot: 手動で依頼
- ChatGPT o3: Pull Request差分のファイルをChatGPTのUIにアップロード(10ファイルまでOK)してレビュー依頼
それぞれで間違った指摘や対応がいらない無駄な最適化を提案してくることがあるので、レビュアー同士のコメントを相互にレビューさせる。
大体はo3にレビューコメントのレビューをさせている。
軽微なものはlocal Claude Code内で妥当な指摘であるなら修正しましょう、として直している。
Pull Request内での@claude でClaude Code Actionsを活用して修正作業をさせてもいいが、修正内容の承認ステップ・commit前の目視での差分チェックを踏める、localでの作業の方が好み。
人間でもそうだが、大きなPull Requestを作るとここのレビューコストがとても上がるので、タスクを細分化しておくのがここでも効いてくる。
Claude Code Actionsのレビューはデフォルトのものを日本語で出力させるようにだけして使っているが、2回目以降のレビューコメントがほぼ同じでノイズになりがちなので、Claude Code Actionsのレビューは一回だけでいいと感じている。
もし大きな変更指摘があった場合はGitHub Issueに切り出して今やらない判断をするか、別ブランチ(別Pull Request)で対応する。
Claude Codeが路頭に迷ったとき
ビルドエラー、リントエラー、テストエラーなどがあったとき、局所的な変更だけを続けてハマり続けることがある。
auto-accept editsのままだとトークンとContextを食い続けて何も改善しないので、escなどで作業を止めて、プロンプトで現状の問題が何かを確認する。
問題が整理されているなら、コンテキストをリセットして再度作業させる。
ChatGPT o3に該当ファイルを渡してみてもらう。
など、ハマり方によって試行錯誤する。
人間がちゃんと実装を読むのでもいい。
この時タスクが大きいとやっぱりコストが跳ね上がるので、タスクの細分化は全体に効いてくる。
GitHub Copilot
VSCode内ではあんまり使わなくなった。
UIのA form label must be associated with an input.biomelint/a11y/noLabelWithoutControl みたいなVSCodeで赤線が出る軽微なlint errorとかを Fix Using Copilot でさっと直させるのに使う。
あとはファイル全部を読ますには大掛かりな微調整をCopilot Chatで済ます。
リファクタ
rust-coreにコアロジックを書いており、crate分割はしていなかったが、wasm buildやデスクトップ向けbuildなどで資材を分けたくなることが想定され、コアロジックなのにwasm buildを意識しないといけないのが気になってきた。
そこでcrate分割をした。
テストやscriptとして使うものも分離出来て、crateの責務が明確になって気分がよい。
多分Claude Codeさんもこの方が理解しやすくなったんじゃないかな。
まだ実装はできていないが、Web向けWasm buildのインターフェース、USI(Universal Shogi Interface)プロトコル(将棋AIの大会?などで使われる一般的なものらしい)、デスクトップ(Tauri)向けインターフェース、みたいにアダプタを作って対応環境を増やしていける。
2025/07/25
crate分割はやっててよかった。
設計が無い状態で無秩序に進むと破綻する未来がすぐにくるので、設計を綺麗にしておく恩恵というか、綺麗に保ち続ける事に適切にコストを払い続けないと破綻する。
Rustでコア部分を実装しているが、並列処理周りのムズカシイ話がbuildエラーとして先に潰せたり、cargo fmt , `cargo clippyP が標準であるのでフォーマッターやリンターの設定に悩むこともなくてとても快適。
Rustでコア部分を作るという判断はよかった。今の生成AIツール時代なら自分の言語に対するリテラシーの足りない部分は補いやすい(いくらでも自然言語で質問が出来るので)。
将棋の座標系
例えばエクセルのような行・列のindexと将棋でのそれは異なっていて、将棋盤を先手番目線で見たときに右上が1一、左下が9九という座標になっている。
実装上はこれを認識したうえで、プログラムで効率的に管理できる座標系を持つ必要がある。
また、USIという標準的なプロトコルで表す座標系も異なる。
ということでtestを書く(書かせたのを読む、testエラーにClaude Codeが詰まっている原因を考える)ときに、頭が混乱したのでドキュメントにした。
これを作成する前後で、ここまでの実装が先手番・後手番目線が逆で実装されていたことが判明(重大な不具合)して、修正も入った。
並列処理とパフォーマンステストは難しい
上手く設計すれば、最善手を探索するのをシングルスレッドからマルチスレッドにするとコア数に応じたパフォーマンス改善を測れる。
しかし、この並列処理が入ってくると関連テストがどうしてもflaky testになりがちでCIの実行の度に結果が変わったり、localでも安定しなかったりする。
基本的にパフォーマンステストはrelease buildでのみ実行し、debug buildではスキップするというのがよさそうだ。
のように、Rustだと以下のコンフィグ設定でdebug buildでの実行をスキップできる。
#![cfg(not(debug_assertions))]
時間管理と探索部の残り時間チェックの仕組みが、シングルスレッドの時は機能したがマルチスレッドになると元の設計が破綻していたようで、すぐに無限ループに落ちる(時間が来ても停止しない)不具合に悩まされた。
vibe codingではやり直しコストは手で書くよりは低く見積もれるので、並列探索と時間管理結合部分の実装を丸々捨てて、再設計した。
Claude Code Opusと、ChatGPT o3の両方を使って、最小構成の実装から初めて、並列処理のパフォーマンスは出ないが、並列処理にしても確実に停止シグナルは受け付けるという状態で少しずつ改善を測る。
GUIで使ってもハングしまくる
ここ数週間バグ取りを続けていた。
GUI部分は一旦世の中で使われているものを使わせていただいて、
AI同士で対局させようと試みたが、初手~数手でハングしたり、40手くらいでハングしたりと大量のバグが明らかになった。
しかし、40手でも自動でさしてくれたというのは喜ばしい。とてもとても。
バイブコーディングの弊害というか、最小構成でGUIと連携して動かすという発想を持たずに良かれと思ってエンジンの強化タスクを進めてきたのが問題だったか。
動かない原因を特定して直してもまた動かなくなるのと、Claude Codeに依頼してすんなりタスクが終わることもなくなってきたので、思い切ったコード整理を始めた。
具体的には数千行のサイズのファイルがあるとClaude Codeが部分的に切り取ってファイルを読もうとする挙動があるため、大きなファイルから目をつけてモジュール分割・リファクタリングをした。
この判断は正しかったと思っていて、リファクタリングの過程で未実装機能が発覚したり、能動的にバグを発見したりすることが出来た。
コードが散らっているとまともに作業が出来ないのは人間だけでなく生成AIでも同様(うまくコンテキストを渡さないと生成AIに望みのタスクを完成させられないので自明ではある)。
ハングしまくる問題のある程度が解消出来てきたところ、ShogiHome(Electron、Node.js製)だと初手からハングするが、ShogiGUI(多分C++製だと勝手に思っている)だと対局がちゃんと進むという課題に当たったのが今。
Claude CodeやCodexなどで調査したり質問したりしたところ、システムコールの動作の違いでハングしたりしなかったりしているのではという結論になった。
低レイヤーの話で、普段の自分に馴染みが無いところにぶつかってしまった。
こういうよく分からない課題にぶつかっていくらでも時間をかけていいというのも、趣味プログラミングのいいところかもしれない。
以下、Claude Codeなどに調査してもらったメモ。
ハングの傾向分析
ハングの傾向分析
- 共通パターン
すべてのハング箇所で共通しているのは:
- サブプロセス/パイプI/O環境での実行
- engine_core APIの呼び出し
- 正確に6秒間のハング(秒読みのタイムアウト時間)
- 具体的なハング箇所
これまでに特定したハング箇所:
-
is_subprocess_or_piped() - atty::is() の呼び出し
-
ポジション確認 - engine.has_position() の呼び出し(コメントアウトで回避)
-
エンジン可用性チェック後 - おそらく adapter.is_engine_available() の後の処理
-
根本原因の推測
コメントにも記載されている通り:
// NOTE: has_legal_moves check is implemented but disabled due to MoveGen hang issue
// ...
// but calling it from subprocess context causes a hang. The issue appears to be
// related to complex interaction between subprocess execution and engine_core APIs.
これは以下を示唆しています:
- サブプロセス環境とengine_core APIの間に相性問題がある
- 特にI/O操作やシステムコールが関係する処理でハングが発生
- デバッグビルドでdeadlock_detectorが動いていることも関係している可能性
- ハングのメカニズム
おそらく:
-
サブプロセス環境でstdin/stdout/stderrの状態チェック時にブロック
-
engine_coreのAPIが内部でI/O操作やロック取得を行う際にデッドロック
-
6秒後に外部からstopコマンドが来ると、何らかの形で処理が再開
-
次の調査箇所
現在のログでは、ポイント23.2の後でハングしているので:
- adapter.is_engine_available() の呼び出し
- またはその後のエンジン可用性チェックのロジック内
- 根本的な解決策の方向性
- サブプロセス環境での実行を前提とした設計に変更
- I/O操作やシステムコールを含むAPIの使用を避ける
- タイムアウト付きの操作に置き換える
- または、サブプロセス検出を完全に無効化して、常にセーフモードで動作させる
現在の回避策はこれらの問題箇所を一つずつスキップしていますが、根本的にはサブプロセス環境でのengine_core
APIの使用方法を見直す必要があるようです。
GUIアプリによるサブプロセスの違い
- パイプの作成方法
- ShogiGUI: 標準的な3つのパイプ(stdin/stdout/stderr)を作成
- ShogiHome: 特殊なパイプ設定や、stderrを別扱いしている可能性
- プロセス起動方法の違い
ShogiGUI の可能性
- CreateProcess with STARTF_USESTDHANDLES
- 全てのハンドルが適切に設定されている
ShogiHome の可能性
- CreateProcess with 特殊なフラグ
- stderrがリダイレクトされていない
- または、コンソールウィンドウが関連付けられている
- atty::is() がハングする理由
atty::is() は以下のようなシステムコールを使用します:
- Windows: GetConsoleMode() / GetFileType()
- Unix: isatty()
ShogiHomeの場合:
- ハンドルが不完全な状態
- コンソールモードの取得でブロック
- ファイルタイプの判定で予期しない動作
- 検証方法
以下の環境変数を設定して、動作の違いを確認できます:
// 強制的にパイプとして扱う
std::env::set_var("FORCE_PIPED", "1");
// または、atty::is() の呼び出しを完全にスキップ
- GUI別の回避策
// GUI検出ロジックの追加案
fn detect_gui_type() -> GuiType {
// プロセス名やコマンドライン引数から推測
// または特定の環境変数をチェック
}
// GUI別の処理
match detect_gui_type() {
GuiType::ShogiHome => {
// 全ての I/O チェックをスキップ
true
}
GuiType::ShogiGUI => {
// 通常の処理
is_piped_stdio()
}
}
- 根本的な解決
最も安全な解決策は:
// 常にサブプロセスモードとして動作
const ALWAYS_SUBPROCESS_MODE: bool = true;
// または起動時オプションで制御
if args.force_subprocess_mode {
// 全ての危険な操作をスキップ
}
- デバッグ提案
ShogiHomeで以下を試すと原因が特定できるかもしれません:
- 環境変数の設定:
SKIP_ATTY_CHECK=1
FORCE_SUBPROCESS_MODE=1 - 起動オプション:
エンジン設定で追加オプションを指定できる場合 - ラッパースクリプト:
エンジンをバッチファイル経由で起動し、環境を制御
このように、GUIアプリケーションの実装によってサブプロセスの扱いは大きく異なり、それが今回のような予期し
ないハングを引き起こす原因となっています。
ShogiGUIはC++製、ShogiHomeはElectron(Node.js)製というように、言語・フレームワーク選択がプロセスの扱い
の違いに影響しそうでしょうか?
● はい、まさにその通りです!言語・フレームワークの違いは、プロセスの扱いに大きく影響します。
C++ vs Electron のプロセス管理の違い
- C++ (ShogiGUI) の特徴
// Windows API を直接使用
CreateProcess(
NULL, command,
NULL, NULL, TRUE, // ハンドル継承を明示的に制御
CREATE_NO_WINDOW, // コンソールウィンドウなし
NULL, NULL,
&si, &pi
);
- 低レベルAPIを直接制御
- パイプのハンドル管理が明確
- バッファリングを細かく制御可能
- Electron/Node.js (ShogiHome) の特徴
// Node.js の child_process
const engine = spawn('engine.exe', [], {
stdio: ['pipe', 'pipe', 'pipe'], // または 'inherit'
windowsHide: true
});
- 高レベル抽象化による制御
- Node.jsのイベントループが介在
- libuv による I/O 処理
- 具体的な違いが生じる理由
パイプの実装
- C++: Win32 API の CreatePipe() を直接使用
- Node.js: libuv がクロスプラットフォーム抽象化層を提供
ハンドルの継承
- C++: SECURITY_ATTRIBUTES で明示的に制御
- Node.js: 自動的に処理されるが、詳細は隠蔽
コンソールの扱い
// Electron の場合、以下のような違いが生じる可能性
{
stdio: 'pipe', // 標準的なパイプ
detached: true, // 独立したプロセスグループ
shell: false, // シェル経由ではない
windowsVerbatimArguments: true // Windows特有の引数処理
}
- atty::is() がハングする原因
Electron/Node.js の場合:
- 疑似TTY (Pseudo-TTY):
- Node.js が疑似TTYを作成する場合がある
- GetConsoleMode() が予期しない動作
- ハンドルの状態:
- libuvの抽象化により、ハンドルが特殊な状態
- Windowsのコンソール API が混乱
- 非同期I/O:
- Node.js の非同期I/Oモデルとの相互作用
- ブロッキング呼び出しが想定外の動作
- 検証コード例
// デバッグ用:ハンドルの状態を詳細に調査
#[cfg(windows)]
fn debug_handle_info() {
use winapi::um::processenv::GetStdHandle;
use winapi::um::fileapi::GetFileType;
unsafe {
let stdin = GetStdHandle(STD_INPUT_HANDLE);
let file_type = GetFileType(stdin);
eprintln!("STDIN handle: {:?}, type: {:?}", stdin, file_type);
// FILE_TYPE_PIPE, FILE_TYPE_CHAR, etc.
}
}
- 推奨される回避策
// Electron環境を検出
fn is_electron_environment() -> bool {
// 親プロセス名をチェック
// または特定の環境変数(ELECTRON_RUN_AS_NODE など)
std::env::var("ELECTRON_RUN_AS_NODE").is_ok()
}
// 環境に応じた処理
if is_electron_environment() {
// 全ての tty チェックをスキップ
return true;
}
-
根本的な解決策
-
環境変数による制御:
USI_SKIP_TTY_CHECK=1
USI_FORCE_PIPE_MODE=1 -
起動時フラグ:
engine.exe --no-tty-check -
完全な回避:
- atty::is() の使用を完全に避ける
- 常にパイプモードとして動作
このように、C++とElectron/Node.jsの実装の違いが、低レベルのシステムコールの動作に影響を与え、予期しない
ハングを引き起こしている可能性が高いです。
ハングする問題解決
生成AI時代なので捨てて再設計して作り直すというのを1日で出来る。
いい時代だ。
Pull Requestとしては最悪の差分量だが、全捨て・再実装の力技で解決した。
MoveGenという指し手を生成するところが問題でハングしていて、Electron(Node.js)環境だとサブプロセスが上手く働かないというのがハングの原因だった。
ここの設計をやり直してシンプルなものとした結果、無事に動くようになった。
この作業はClaude CodeではなくCodexを使って実施した。
最近のClaude Codeはなかなか扱いが難しくなっている感じがあり、すんなりタスクを進めることが少なくなっていたので、別のコーディングエージェントを試したい機運が高まっていたのもある。
GPT5のモデルをつかっての設計書つくり・コーディングは思ったより品質があった。
ただ、Plusプラン(20$/month)だと枠をすぐに使い切ってしまった。
設計書を作るまでで枠を使い切ったので、その設計書をもとにClaude Codeにコーディングをさせると結構さくさく実装が進んでいた。
丁寧な設計書を作ってノイズになるコンテキストを作らないというのがClaude Codeのタスクをうまく進ませるコツであることを再認識した(最近雑にタスクやらせてたかもな...)。
Codex CLIの出来に満足したので、Claude CodeのMAXプラン200$と同じ価格でChatGPTのProプランがあるが、こっちも契約した。
遊ぶお金だと思えばいい・・・?かな。
vibe codingの弊害
1ヶ月くらい無駄な事をしていた。
バグが起きては解消の度に1レイヤー増やし(これが改善だと思い込み)、1レイヤー増やしで何も解決していなかった。
部分的に成功することもあったが、それは根本的な解決ではない短期的な改善でしか無かった。
任せたらそれらしいコードを書いてそれらしいポジティブな報告をしてくるものだからまあいいかで取り入れてしまうとバグの上にバグが重なり(バグでないにしても冗長だったり不要な設計が重なり)、本格的に検証し始めたときにコアな原因が全く見えない状態になる。
何回も楽という名の手抜きをしては後悔をしていたが(これも含めて楽しんではいる)、設計をちゃんとする事と設計通りに作れているかのレビューが大事だ(n回目)。
Codex CLIとClaude Codeはなんだかんだ両方使って作業している。
Claude Codeの調子が悪いとき(時間帯による性能差は明らかにあると思う)や、Context量からしてClaude Codeだとcompactを挟むことが推定されるタスクはCodex CLIに作業させている。
コードレビューは作業していない方にさせる、などでバランスが取れている感じはする。
最近のClaude Code、Codex CLI
ClaudeがSonnet 4.5をリリースした ので久しぶりにClaude Codeにコーディングさせてみた。
最近(9月にCodex CLIが盛り上がってきたころから)はほとんどCodex CLIで思い出したようにClaude Codeに雑用(ログ分析とか)をやらせる程度でコーディングをさせていなかった。
性能劣化があった期間で完全に使うモチベーションがなくなったClaude Codeだったが、Sonnet4.5で実装をやらせるとCodex CLIより早くコード編集をしてくれて、この体験自体はCodex CLIよりよかった。
Context WindowがCodex CLIよりすぐに枯渇するが、 /compactをして作業を継続させても以前より文脈を忘れずにタスク継続してくれる感じはあった。
どこかでも見たが、Codexと実装ドキュメントを整備して実装タスクをClaude Codeにやらせるというのは有効そうに思った。
早く結果が欲しく、結果のフィードバックを自分で十分に出来るタスクはClaude Codeにやらせて、時間がかかってもいいから中規模のタスクをある程度の品質で進めてほしいときはCodex CLIにやらせるという感じかなぁと。
Codex CLIの方を(比較的)信用してClaude Codeの方は重要度の低い作業をさせるという使い分けは変わらない。
探索部の破壊
ShogiHomeの初心者向けAI(0.5秒くらいで手をさす)と秒読み対局をさせても将棋のルールがぎりぎり正確に分かる程度の自分にも分かる悪手を連打しており、圧倒的棋力の低さがあった。
角で相手の歩をとってそのまま角がとられたり、持ち駒を打ってタダでとられたり。
NNUEの学習も回し始めて、ちょっとずつ強くなると期待したが全然そんなことは無く、そもそも探索部がバグっているという事が(色々な試行錯誤の末)分かった。
歴史的経緯として、シングルスレッドでの探索を作ってその後に並列探索を作るということを7月のClaude Codeにやらせ、並列探索のベンチマークをとったが思ったより性能が出ない(シングルと同じでは?)みたいなハマり方をして、なんやかんやあってちょっとはシングルより良くなったのかなみたいな不完全燃焼なところで終えていた。
この探索の実装が何かおかしいのでは?と一度中規模のリファクタリング(モジュール分割などの整理作業)をして、何となくコードはすっきりしたがベンチはやっぱり微妙というかシングルと変わらんな、みたいな結果だった記憶がある。
この過程で探索部がなぞの経緯ありそうなUnifiedSearchという名前に進化していた(シングルスレッド探索と並列探索の統合したエントリーポイントとしてモジュールが置かれた雰囲気ではあったが、ちょっと疑問のモジュール構成だった)。
とりあえず動くものが通しで出来ればと思ってやはり蓋をして進んだのだが、NNUE学習で棋力を上げたいというフェーズに来て、探索部の性能と信用性が課題になった。
診断スクリプトをつくったり、診断ログを仕込んで対局したりを1週間、数週間か、繰り返したのだが一向に状況が解消しなかった。
ShogiHomeで使うと全く手をささなくなったり、時間切れを頻発したりとクリティカルな問題が起こるがUbuntuのCLI実行では問題が無いなどよく分からない壁に当たってGUIの自作も早くやってしまうか・・・?など思っていたが、詰め込み過ぎた診断ログがGUIへ送る情報のノイズまみれになってGUIがbestmoveなどの情報を拾えていなかったのであった、というおそらく数か月の進捗やバグの大きな原因の一つがみつかった。
ロギングを見直してこれは解消し、この調子で性能を何とか上げようとするも、何をやってもうまくいかずというのが続いた。
設計が破綻していたら表面をいくらいじくりまわしても意味がないのであった。
そう、一度探索部を破壊して作り直すのがよい。
趣味開発ならリソースも期間もユーザー影響も、何のビジネス上の制約もないので好きに破壊して作ればいい。
ということで探索部を全部消して作り直すことにした。
シングルスレッド探索安定化
全面刷新をやって数万行消して書き直すというのをやった。
並列探索までやってしまうとまたバグの種があったときに見つけるのと再現手順を明らかにするのが大変になるのでシングルスレッド探索をきちんと作ることを目標として進めた。
ShogiHomeの初心者(居飛車)という対戦AIがいて、これに今までボコボコにされるか時間管理がバグっていて時間切れするか、不正手を打って負けるかしていたが、試行錯誤を経てやっと安定した。
探索のワーカースレッド管理 + 時間管理、TT (Transposition Table)、PV (Principal Variation)、手生成(MoveGen)それぞれにクリティカルなバグがあって、それぞれが絡み合って観測が難しい状態であった。大きな探索部モジュールを捨ててシンプルなところから積み上げることで、周辺のバグの観測を容易にし、無事解消に向かう事が出来た。
時間管理と探索結果のbestmoveを返すの兼ね合いがとてもとても難しいところに感じた。
一旦安定したところでGUIで対局をさせてみた。
先手番が自分の作っているエンジンで、どうもこういう動きを好むらしい(NNUE学習はまだやってない状態)。

将棋の駒の動かし方を知っている程度の自分よりもしかしたら強い可能性はある(自分自身は対戦は興味が薄くてやっていない)。
バグらずに、初心者視点で変な手(明らかに駒をタダであげるだけの手)をささずに終局まで動くのを初めて見ることが出来て、感動した。
初勝利の絵。

Claude Code, Codex CLIのContext Windowが一瞬でなくなる
デバッグのためやtestの検証のためにロギングを強化することがしばしばある。
自分の手でコマンドをうって端末に流したりファイル出力したりする分には問題ないが、コーディングエージェントのセッションでテストやコマンド実行を任せてその処理の中でログが数千・数万行と流れてしまうとそのままContext Windowが圧迫され、(APIリクエストボディにも載って?)一瞬でそのセッションがダメになってしまう。
メッセージ出力は適度に間引く必要がある。
コーディング・コードレビュー
作業はもっぱらCodex CLIにさせている。
計画立ては通常のgpt-5、コーディングはgpt-5-codexという使い分けをしている。
gpt-5-codex だと体感としてgpt-5よりコーディングが早い(誤差かも)のと、実装タスク後の報告が端的になってちょうどいい感じはある(gtp-5だと丁寧というか分量が多い報告になる)。
レビュー専用のcodexを用意して、gpt-5-codexが作業したコードと報告分を使ってレビューさせる使い方をしている。
レビュアーは設計ドキュメントを読ませてコンテキストを比較的綺麗に保ち、設計からのずれを補正する役割がある。コーディングタスクを進めている方はビルドやテストやリントエラーでコンテキストにノイズが徐々に蓄積したり、単に作業を一定量やると設計ドキュメントを忘れる頻度が高まるので。
ただ、クリティカルな指摘を適切にしてくれることは少なく、あくまで補助的レビューと考えている。
念入りに確認したい場合はClaude CodeのSonnet4.5にもレビューをさせている。
一方でブラウザでアクセスするChatGPTのProにコードレビューさせるのは比較的品質が高く、クリティカルな指摘もしてくれる印象がある(時間が10分とかかかるのがネックではある)。
報告文 + コード6000行くらいまではギリギリ載せられて、7000行とかになるとサイズ限界で弾かれる。
学習
ここにきて開発はそこまでしないがお金(電気代)がかかるようになった。
NNUEについては強いCPUがあればそれだけ効率的に学習プロセスを回せるので、マシン性能が欲しくなる。
メインPC(Windows)とサブPC(Ubuntu、こっちの方が強い)があるのでサブPCでCPUをたくさん使う処理を回してもメインPCでの作業に支障が無い(メインPCで通常の作業をしていても学習を回すリソースを食わない)状態が出来ている。
6回ほど学習のサイクルを回したが、まだそこまで強くはなっておらず、ShogiHomeの初心者(居飛車)にすら勝てない。
NNUE学習無しの駒の価値だけの評価関数だとパラメータ設定次第ではたまに勝つことがあるが、NNUE学習した評価関数を使うと学習が不十分だと局面の評価値が妥当なものにならず、駒価値だけの評価よりも低い精度の評価になってしまう。
どれくらい学習を回せば初心者の自分でも気づける違和感のある手を消せるようになるのか、あまり検討がつかないので正しい方向に向かえているのかあまり自信が無いところである。
どうも、empty_or_missing_pvというログが多発していてバッチ処理のうち8割程度のリザルトが時間内に有効な結果を返さず無駄になっていることが分かった。
PVを返すロジックやアスピレーションウィンドウのロジックに問題があるのではという見立てになり、エンジン本体の改良を実施した。
n度目の探索部安定化
10/7に初めてShogiHomeの数百行程度のシンプルな評価関数相手に勝利してから1ヵ月、NNUE学習まで始めるぞと息巻いていたが何日か学習を回してもうまくいかず、あれこれ弄っているうちに基本的な探索部がまだ調整不足であることが分かった。
ここまでに何度となく退行していたが、この1ヵ月も退行9割と進展のようなもの(ShogiHomeのAIにギリギリ勝てる)1割を繰り返しており、明らかな悪手の採用を除外しきれていなかった。
PVの検証ロジックを足せば足すだけ棋力が低下し、手を打つたびに悪い方向にしか行かないという日も続いた。
以下の時点が直近だと一番安定した手をさすがそれでもまだ探索性能(Node数の意味)の割には上手く手を選べていない感じがある。
ShogiHomeの対戦AIは数百行程度の簡単なSwitch文で書かれた評価関数なので、このAI相手に右肩上がりな勝ち方が出来ないようではエンジンの基本的な品質が担保できているとは言えないと考えた。
勝てはする状態は見つかるが、↑のcommitの状態からあれこれチューニングを施そうとしても全てが退行につながってしまう。
しかし、これが本来やるべき進め方(A/B計測を入れて少しずつ探索性能を強化する)であって、生成AIによかれで作らせた積み重ねはとても不安定な足場の上に出来上がった構造物でもろいのだなと感じた。
色んな実装を捨てたり再構築したりしながら、NNUE学習をする前の棋力向上を目指そうと思う。
自己対局ならぬ仮想敵対局
ShogiHomeの簡単なエンジンにも勝てないので、同じ評価関数を実装してShogiHomeの対戦AIを仮想敵とした自己(?)対局スクリプトを整えた。
これにより手動で自分がGUIで対局させてShogiHomeが出す形式のログをパースして分析する、という煩雑なステップが簡略化された。
最初からやっとけばよかったなぁ。
あとはSFENやUSIに加えてKIFというフォーマットを覚えた。
KIFファイルを外にもっていくと(ShogiHomeやlishogi)対局の流れをGUIで再生できるので、コマンドラインで生活する世界から人間にやさしいGUIでの解析に繋ぐことができる。
将棋初心者の人間(自分)には妥当な読み筋が分からないので以下のサイトを使い始めた。
いまだとYaneuraOuのエンジンが評価関数として使われているらしい。
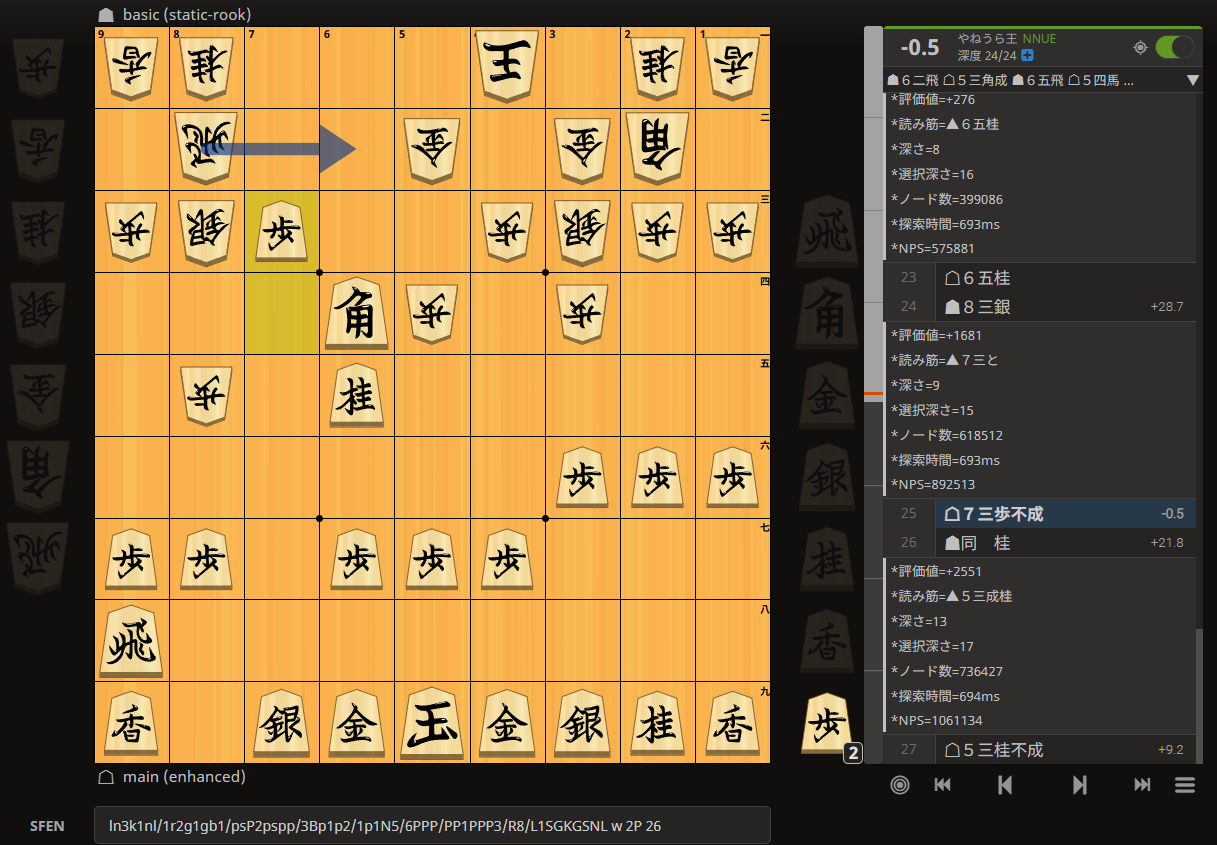
歩成らずが選ばれてしまった(これは自分でも成った方がいいと分かる)のだが、最善手は何だったかという答えをここで見た上で開発している評価関数の修正に当たりをつける事が出来る。
(→これはKIFファイル吐き出しのフォーマットが間違っていてト金を書いているはずなのに不成と解釈されてしまっている、別の不具合だった)
YaneuraOuをビルドして動かしてもいいのだけれど、NNUEファイルどうしようという問題があったのでそこまで活用はしていなかった(リリースページを見るに配布物もある?)。
あとGUIが無いと人間にSFENやUSIの棋譜では絵が想像できないというのもある。
よく理解せずに違う事を書いているかもしれないが、人力でNNUE学習の補正をかけて行っている感じがある。
既に誰でも触れるOSSや解析サイトがあるというのはとてもありがたい。
lishogiでやっている機能がGUI側でいうとまさに今自分が作りたいもののゴールな気がする。
これをデスクトップ版とWeb版の両方を作って、自作のエンジンを載せたい。
マルチスレッド探索なんもわからん
ので頑張って理解をすることにした。
YaneuraOuの探索部を完全に理解したまでをゴールにしたい。
C++は初見だけどまあ読むだけなら今ならたくさんの質問相手(Codex CLI, Claude Code, Gemini, ChatGPT, ...)があるので困らない。
エントリーポイント
将棋盤を初期化して、main関数でrunしているだけ。
YaneuraOu::run_engine_entry() を見に行く。
source/engine.cpp
void run_engine_entry() でエンジンを取り出す処理が書かれている。
このレポジトリには複数の将棋エンジンがあるらしい。
詰将棋はやっぱり探索の指向性が変わるのか、専用でエンジンを作っているらしい。
- やねうら王エンジン
source/engine/yaneuraou-engine/yaneuraou-search.cpp
- user-engine
- 実装: source/engine/user-engine/user-search.cpp
- USER_ENGINE 用のサンプルエンジン/自作エンジン用の雛形。
- tanuki-mate-engine
- dlshogi-engine
- 実装:
- source/engine/dlshogi-engine/FukauraOuEngine.cpp / .h
- source/engine/dlshogi-engine/dlshogi_searcher.cpp / .h
- yaneuraou-mate-engine
- 実装: source/engine/yaneuraou-mate-engine/yaneuraou-mate-search.cpp
- やねうら王版の詰め専用エンジン。
source/Makefile にあるようにどのエンジンを使うのかを指定する。
そのままだとNNUEでのエンジンで、駒価値だけのMaterial評価関数を使いたい場合はコメントアウト・コメントインで編集するか、makeのコマンドライン引数で上書きする。
cd source
make normal YANEURAOU_EDITION=YANEURAOU_ENGINE_MATERIAL
複数のエンジンから優先度の高いものを選ぶ、となっている。
source/engine.cpp のstd::get<0>(*m)(); // このエンジンを実行
ここでの std::get<0> がエンジン起動関数になっていて、USIが起動すると思ってよさそう。
デフォルトで選ばれるであろうやねうら王のエンジンの登録は
source/engine/yaneuraou-engine/yaneuraou-search.cpp にある。
以下の仕組みで起動時に自動で登録されるらしい。
- static EngineFuncRegister r(...) は「静的記憶域期間のオブジェクト」です。
- C++ では、プログラム開始時(main() に入る前)に、こうしたグローバル/名前空間スコープの static オブジェクトのコンストラクタが自動的に呼ばれます。
- つまり、「誰かが r を明示的に呼んでいる」のではなく、ランタイムが自動的に r のコンストラクタを実行します。
そうなると実装されているすべてのエンジンが優先度0で登録されてしまいそうだが、各エンジンのファイル先頭に #if defined (YANEURAOU_ENGINE) のような記載があり、対応するマクロが定義されているときだけコンパイルされるらしい。このマクロというのが先ほど見たMakefileでの YANEURAOU_EDITION = YANEURAOU_ENGINE_NNUE と対応すると思われる。
なので、実質1つのエンジンだけがコンパイルされて、登録済のどのエンジンを選ぶのかという優先度ロジックではその1つだけが選ばれるということになっている。
if defined の記載を消すなりカスタマイズすれば複数エンジンをビルドしてどうこう出来るのだろうが、これ以上は今はいいので追わない。
話が戻って
static EngineFuncRegister r(engine_main, "YaneuraOuEngine", 0); の第一引数の engine_main が source/engine.cpp での std::get<0>(*m)(); // このエンジンを実行 で呼ばれるという事である。
void engine_main()
はエンジンのClassを初期化してUSIに渡し、最後に usi->loop(); でUSIを起動している。
loopが(将棋エンジンをある程度触っていればおなじみの)USIプロトコルを受け取ってやり取りをしてくれるループだと思う。
ここからはUSIの話を追いかけるか、エンジンの探索部自体を直接探すかの分岐があるかと思うが、せっかくなのでUSIで探索などのコマンドを受け取ってエンジンの探索部を呼ぶ処理を見て行こうと思う。
C++構文のinclude は「文字列の貼り付け」相当らしく、 .cpp ファイルを張り付けるのは慣習としてあまり推奨されず、 .h ファイルをincludeするのが普通らしい。
USI
#if !defined(__EMSCRIPTEN__)`
...
#else
// yaneuraOu.wasm
// ここでループしてしまうと、ブラウザのメインスレッドがブロックされてしまう。
とありWebAssembly向けビルドも対応していそう。
loop関数をそのまま使えないので別の usi_command という関数を用意しているらしい。
source/wasm_pre.js に呼び出し用JavaScriptもあった。
loopの本筋に戻ると、やっているのはシンプルで標準入力を取得してそのままUSIコマンド実行関数を呼んでいるだけである。
"quit"が来たらUSIプロセスを終了する。
usi_cmdexec 関数が各種USIの処理をする関数で、
すぐに #if STOCKFISH ...... という記載が見られる。
ヘッダファイルのコメントを見ると、実際にビルドで使う想定は無いコードらしく、おそらくはStockfishのコードをリファレンスとして記載しておきたいということと思われる。
Stockfishはチェスの一番有名(?)なエンジンで、将棋エンジン開発者もここから最新の手法を取り入れるなどしているというのを聞く。
とりあえず今後は #if STOCKFISH のブロックは読み飛ばしてよさそうだ。
#if は実装本体用のif分岐ではなくコンパイル時に解決されるif分岐(コンパイル対象を分岐させる)用途の記法らしい。
ここまでC++の構文をCodexに質問するので8割くらいの時間を要しているが、多分これはそのうち減るだろう。
std::istringstream is(cmd);
is >> std::skipws >> token;
は見慣れなくて抵抗があったが解説を聞いてからは使うパターンを理解すればシンプルでいいなと思えるようになった。
Stochastic Ponder についての質問のやりとり
• だいたい想像されている通りで、「外したときに丸損になりがちな普通の Ponder を、外れてもある程度は役に立つ形にしたい」
というモチベーションの機能です。やねうら王のコメントでは:
// Stochastic Ponderはdlshogiで最初に実装された機能。
// やねうら王では、以下のように実装している。このため、Stockfishと差異が生じる。
//
// 1. GUIから送られてきた"position"コマンドのコマンドラインを丸ごと保存しておく。
// 2. GUIから送られてきた"go ponder"コマンドのコマンドラインを丸ごと保存しておく。
// 3. GUIから"go ponder"が送られてきたときに、1.で保存した局面の1手前の局面をrootとして、そこから探索する。
// 4. GUIから"ponderhit"が送られてきたときに、2.で保存しておいたコマンド列から"ponder"の文字列を取り除き(無視して)実行する。
という設計になっています(source/usi.h:212)。
普通の Ponder との違い
- 通常の USI_Ponder:
- bestmove X ponder Y の Y が来ると仮定して「X→Y のあとの局面」から深読み。
- 外れると、その局面に対する探索はほぼ丸損(TT に多少残る程度)。
- Stochastic Ponder:
- go ponder のとき、1手前の局面を root にして探索します(last_position_cmd_string から最後の手を削って positionし直す)。
何が嬉しいか(モチベーション)
- 相手が何を指すか読みにくい(ポリシーにノイズがある NN 系、自戦譜生成など)状況だと、普通の Ponder はヒット率が低く
- どの手が実際に指されても、その局面は親ノードのすぐ下のどこかになりやすい。
- そのぶん、TT(置換表)や歴史ヒューリスティックなどに「共通で使える情報」が溜まりやすい。
- ponderhit 時には一度止めて読み直しますが、
- TT、history、各種統計テーブルはクリアされません。
- したがって「完全に捨てている」のではなく、「1 手前からの探索結果を TT 等を通じて再利用しつつ、正しい root から
改めて本探索をする」かたちになります。
つまり、
- ヒットしたときに「そのまま続けて即着手」できる普通の Ponderに比べると即効性は弱いが、
- ヒットしなかったときでも「1手前からの探索で温めた TT/履歴が、いろいろな応手に対してそこそこ使い回せる」ので、
「外したときの損失を減らす」方向の工夫が Stochastic Ponder、という理解で良いです。
質問の通り、「探索本体は止めて再実行するので、直接の PV は捨てて TT を温める効果が主」という見方でほぼ合っています。
1手前の局面から「自分と相手の手をまとめて」読んでいる
これは自分がさした確定した手も巻き戻して読み直しているのでしょうか?
• はい、その理解で合っています。やねうら王の Stochastic Ponder 実装では、内部の思考用の局面を「1手巻き戻す」ようにしています。
根拠になるコードは USIEngine::go()(source/usi.cpp:732 付近)です。
-
GUI から position ... が来るたびに、その行全体を last_position_cmd_string に保存します(usi_cmdexec 内)。
-
go ponder かつ Stochastic_Ponder = true のとき:
std::size_t last_space = s.find_last_of(' ');
std::istringstream iss(s.substr(0, last_space));
iss >> token; // 先頭の "position" を捨てる
position(iss); // 1 手前の局面を再セット- それが last_position_cmd_string になります。
-
そこから最後の手 X を削って position(iss) を呼ぶので、
- 内部の root 局面は「自分が X を指す前」の 1 手前に戻ります。
- つまり、「自分がすでに指した確定手 X も含めて、1 手前から読み直す」構造です。
もちろん実際の対局の盤面や GUI 側の局面は巻き戻っていません。
あくまで「エンジン内部での探索の root を 1 手前にする」だけで、
- 自分の候補手(実際に指した X も含む)+相手の応手
- それ以降の局面
をまとめて読んでおき、その結果(主に TT や history など)を、ponderhit 後の本探索や別応手のときにも活かしやすくする、という設計になっています。
› 1手前に戻って読んでも実際の対局の進行には発生しにくい局面(手待ちなどで偶然一致するなどしかない)を読むことになりま
すが、TTは局面の完全一致ではなく傾向が一致していればあとから活用できる情報がたまるのでしょうか?
TTの仕様に詳しくないためここの理解ができません
• いい視点です。ここをきちんと分けて考えると理解しやすくなります。
1. TT(置換表)は「完全一致」が前提
まず、TT そのものについて:
- やねうら王の TT は、Position の Zobrist ハッシュ(64bit など)をキーにして
- その局面の評価値
- 探索深さ
- ベストムーブ など
を保存しています。
- キーは「盤面+手番」を含むので、TT は基本的に「局面が完全一致したときにだけ」ヒットします。
- 「似た形」「傾向が近い局面」だから使える、というような「ファジーな再利用」はしません。
なので、
1手前の局面から読んでも、実際の対局では出てこない局面を読んでしまうのでは?
という疑問に対しては:
- その通りで、「実際の進行からは絶対に来ない局面」の TT エントリは完全に無駄です。
- ただし、1 手前から読んでいても、
- 実際の対局で通る経路(例: P0 → X → Y → …)上の局面は TT に積まれますし、
- 実際の本探索でも同じ局面に到達すれば、そこは TT からそのまま再利用されます。
という状態になっています。
2. それでも「1手前から読む」ことに意味があるのは?
おっしゃる通り、「X はもう指し終わっているのだから、1 手前から読むと“実際には起こらない別の手”もたくさん読むことになる」のは事実です。
Stochastic Ponder は、
- そこを割り切って「無駄になる分はある程度許容する」代わりに、
- 「1手前から読んだときに、実際に起こり得るいくつかの分岐の TT / 各種ヒューリスティックをまとめて温める」
ことを狙っている設計です。
具体的には:
- 実際の進行:
- ゲーム上は ... P0 -> X -> (相手の手) ...
- Stochastic Ponder の探索:
- root を P0 に戻してしまうので、
- P0 から見た自分の候補手(X 以外も含む)
- そこから相手の候補手
の木を読んでいきます。
- root を P0 に戻してしまうので、
- 実際の対局では、そのうち
- P0 -> X -> Y -> ... という一部分だけが現実に選ばれる
- その経路上のノードは TT に残っているので、本探索で再利用可能
という感じで、「P0 から読んだ木の一部分だけが実際の進行と一致し、その部分については TT が効く」という形になります。
3. TT 以外に「傾向」を溜めるテーブルもある
もう一つ重要なのは、「Stochastic Ponder の計算は TT 以外にも効く」という点です。やねうら王(Stockfish 系)の探索には、TT 以外にも:
- ButterflyHistory, ContinuationHistory, PawnHistory などの history テーブル
- captureHistory, correctionHistory 系
- move ordering 用のスコア(ttMoveHistory など)
のような「局面ではなく“手”や“パターン”に結び付いた統計」が多数あります。
これらは:
- 「同じ局面」ではなく、「同じ手(from/to や駒種)」・「似た局面での同じ手」であれば効いてくる
- P0 から読んだときに試した手の履歴は、
- その後の本探索(P1 からの探索)でも「move ordering」や「枝刈りの判断」に影響を与える
ので、
- TT は「完全一致しなければ効かない」が、
- history 系は「近い局面でも“同じ手”には効く」
という形で、「傾向の学習」がより広く効いてきます。
Stochastic Ponder は、こうしたヒューリスティックも含めて「手前から広く木を読んでテーブル類を温めておく」という側面が強いです。
4. まとめ
- TT 自体は「局面完全一致」が前提で、「傾向が近いだけ」では再利用できません。
- 1 手前から読む Stochastic Ponder では、
- 実際の進行と無関係な局面の TT は無駄になる一方で、
- 実際の進行に含まれる経路(P0 → X → Y → …)上の TT はちゃんと温まり、
- さらに history や各種ヒューリスティック(局面に依存しない“手の統計”)にも情報が溜まる
- なので、
- 「TT のために 1 手前から読む」というよりは、
- 「TT + ヒューリスティック全体を、少し広めの木で事前に温めておく」
→ ヒットしても外れても、ある程度は役に立つようにする
というモチベーションで Stochastic Ponder が使われている、という理解が近いと思います。
C++では ()も[]も色んな記号が演算子で、演算子オーバーロードを出来る。
これによってMapオブジェクトに値をセットする(obj[key] = value みたいな)とき(変更するとき)にon_changeコールバックを仕込む、みたいなことを書ける。
この言語機能を使って class OptionMaps でUSIオプションをKey / Valueで管理しつつ、Keyが更新されたときにエンジンにその状態を同期するイベントを呼ぶような事をやっている(thread 8って設定されたらエンジン本体も8スレッド探索するように状態を更新、みたいな)。
setoptionのon_changeについての質問やり取り
› const Option& OptionsMap::operator[](const std::string& name) const を使っている
void OptionsMap::setoption の
options_map[name] = value;
では、オプションのセットをしているのを理解できますが、このときにOptionのon_changeハンドラが呼ばれる話はどう読めば理解できますか
つながりが分かっていないです
• そこが一番つながりが見えづらいところなので、チェーンを一歩ずつ書き下します。
前提となる 3 つをまず押さえます。
- OptionsMap::setoption の中身(抜粋)
void OptionsMap::setoption(std::istringstream& is) {
// name と value をパースしたあと…
if (options_map.count(name))
options_map[name] = value; // ← ここ
else
sync_cout << "No such option: " << name << sync_endl;
}
- options_map の型
using OptionsStore = std::map<std::string, Option, CaseInsensitiveLess>;
OptionsStore options_map;
- Option::operator= の末尾
Option& Option::operator=(const std::string& v) {
// 型・範囲チェックなど…
if (type == "string")
currentValue = v == "<empty>" ? "" : v;
else if (type != "button")
currentValue = v;
// ハンドラが設定されているならハンドラを呼びだす。
if (on_change)
{
const auto ret = on_change(*this);
if (ret && parent != nullptr && parent->info != nullptr)
parent->info(ret);
}
return *this;
}
ここから、options_map[name] = value; がどう on_change までつながるかを展開します。
———
ステップ 1: options_map[name] で何が起きるか
options_map の型は std::map<std::string, Option, ...> なので、
options_map[name]
は C++ 的には
です。これは std::map の operator[] が呼ばれます。
- 戻り値の型は Option&(値オブジェクトへの参照)
- すでにキー name が存在していれば、その要素を指す Option& を返す
- 存在していなければ新規挿入して、その Option& を返す
つまり、この時点で「name に対応する Option オブジェクトそのもの」への参照を手に入れています。
———
ステップ 2: = value で何が起きるか
次に
options_map[name] = value;
全体を展開すると、
Option& opt = options_map.operator; // ← 1. ここで Option& を取り出す
opt.operator=(value); // ← 2. ここで Option::operator= が呼ばれる
という 2 段階です。
ここで 2 番目の行が、まさに Option::operator=(const std::string& v) の呼び出しになっています。
———
ステップ 3: Option::operator= の中で on_change が呼ばれる
Option::operator= の本体の最後を見ると:
// 適切な値の範囲であったので、
// ハンドラが設定されているならハンドラを呼びだす。
if (on_change)
{
const auto ret = on_change(*this);
...
}
- Option には OnChange on_change; というメンバがあり、
- Engine::add_options() などで
options.add("Threads", Option(4, 1, MaxThreads, [this](const Option&) {
resize_threads();
return thread_allocation_information_as_string();
}));
のように Option(..., OnChange f) の形で登録されたとき、この f が on_change に保存されています。
- Option::operator= が呼ばれると、
- 型チェック・範囲チェックを通ったあと currentValue を更新し、
- on_change がセットされていれば、そのコールバックを on_change(*this) で呼び出します。
これにより、options_map[name] = value; という 1 行の代入が、
- std::map::operator[] で対象の Option& を取ってきて
- Option::operator=(value) で値を更新し
- その中で on_change コールバックを自動的に実行する
という一連の処理になっている、というつながりになります。
———
よく混ざりがちなポイント
- OptionsMap::operator[](読み取り専用の const Option& operator[](const std::string&) const)
と、 - options_map[name](std::map の operator[])
は 別物 です。
- OptionsMap::setoption で使っているのは options_map[name] の方で、
- これは内部の std::map に対する書き込み用アクセス。
- OptionsMap::operator[] の方は、
const OptionsMap& opts = engine.get_options();
const Option& o = opts["Threads"]; // 読み取り専用アクセス
のように、外部から「読むだけ」のために用意されたラッパです。
setoption → options_map[name] = value; → Option::operator= → on_change
というチェーンを頭の中で展開できれば、だいぶスッキリすると思います。
Claude Code Opus 4.5
リリースされたので早速使ってみた。
Opusモデルだとコーディングが遅いと言われていて、先週まではSonnet4.5だと速くて性能もOpus4.1よりいい感じと言われていたが、Opus4.5は速いし性能も高いという事でらしい。
確かにCodex CLIより早くタスクを進めてくれるのと、Planモードで複数Agentを立ち上げて(?)早く計画を立ててくれるようになったのはとても進化を感じた。
使用感は良いのでしばらくはClaude Codeメイン、サブでCodex CLIを使っていこうと思う。
Claude Codeはフルで使っているとrate limitに引っかかるが、Codexの方は(Proプランだからか)rate limitに引っかかることはあまりないので、コーディングをClaude Codeに任せて、Codexでコードレビューや自分の学習のためのコード調査・解説に使っていく。
Claude Code(2025/07)→幻滅するところもありつつClaude Code(2025/08~09?)→Codex CLI(2025/09)→Codex CLI >= Claude Code Sonnet4.5(2025/09)→Codex CLI gpt-5.1-codex-max(~2025/11/27)→Claude Code Opus4.5
みたいな変遷をしている。なんだかんだ両方契約を続けていてそこそこサブスク費用が痛い(遊び代と思えばまあいいか)。