Slackコメント読み上げずんだもん(Rust、Tauri)





要旨
Python(任意の書き馴れた言語 or ChatGPTなどで自動生成しやすい言語)でスクリプトを書いてRustに移植したらTauriでそのまま簡単にデスクトップアプリに出来るじゃん!という話です。
Rustに移植するモチベーションは勝手に湧いてきたものとします。
最初からRustで書けるならそれでいいのでは、というと、そうです。
GitHubは以下です。
想定読者
- Slackのコメントを自動で読み上げさせたい人
使ってみてください(もっといいアプリは既に世の中にあるかもしれません)。
このアプリは再生デバイスを任意に選べるのが特徴です。
ゆるい社内ミーティングなどで使うと楽しいかもしれないです。 - Rustを普段書かないがRustで何か作ってみたい人
モチベーションが上がるきっかけになると嬉しいです。
お手元のスクリプトをRustで書きなおすところから始めるのはハードルが低いと思うので、そのまま勢いでデスクトップアプリにすると少しハッピーになれるかもしれません。
デスクトップアプリにすると非プログラマにも配布出来ますよ。 - Rustで何か作っている人の読み物を読みたい人
ある程度Rustを書ける人には読みごたえはないかもしれないです。
作った経緯
SlackのHuddleを使ってミーティングをすることがあります。
1人が画面共有してプレゼンする形式の場合は、Huddleミーティングを開始したときに出来るスレッドに、参加者が感想や質問を書くことが多いです。
ですが、発表者が画面共有をして話していると(特にディスプレイが1枚の場合)、操作している画面を見ているためスレッドのコメントにすぐに気づけないです。
そのため、映している画面が違う、マイクの不調など早く対処したいものや、その時話している文脈がないと拾いにくいコメントなどが流れてしまいます。
コメントがついたときにすぐにコメントを読み上げてくれれば上手くミーティングが進行するのではと思い本アプリを作り始めました。
ずんだもんを探す
読み上げソフトで有名(?)なものとしてずんだもんを聞いたことがありました。
「ずんだもん 読み上げ」で検索するとVoiceVoxというソフトが見つかり、これを使うとよさそうです。
インストーラーをダウンロード・実行してインストール。
キャラクター(音声)がたくさんありましたが、ずんだもんを選びテキストをいれて再生ボタンを押すと読み上げてくれました。
Slack通話に読み上げ音声を載せる(オプション)
発表者だけがSlackのコメントに気づければ十分ではありますが、読み上げソフトの音声が通話に乗るとこれはこれで盛り上がるかもしれないと思ったので、方法を探しました。
このステップは完成したアプリでも特に必須な事項では無いです。
デスクトップ音声orアプリ音声をどうにかSlack通話の自分のマイクとして載せたいです。
いわゆるオーディオミキサーというものを使うと、マイク音声とアプリ(VoiceVox)音声をミックスして出力できるようです。
今回はマイクとPC内アプリの音声をミックスしたいので、仮想オーディオミキサーソフトであるVoiceMeeter Bananaというものを使いました。
この辺り知見がある方はご自分で使っているもので代用できるかと思います。
VoiceVoxとVoiceMeeterの設定
VoiceVox(ずんだもん)とVoiceMeetter(ミキサー)を起動します。
-
ずんだもん側の設定
VoiceVoxの設定/オプションから再生デバイスをVoiceMeetter Inputにします。

-
ミキサー側の設定
使用しているマイクをINPUTに設定します。
VoiceVoxの音声はVIRTUAL INPUTSが対応します(Voice Meeter側では設定不要)。

VoiceVoxで適当な音声を読みあげさせることでミキサーと上手く連携できていることが確認できました。

Slackの音声出力にずんだもんの声が載るかの確認
Slackのマイク設定でVoiceMeeterを指定し、マイク入力が出来ているかを確認しました。
入力レベルのゲージが変動していることから、VoiceVoxの音声がVoice MeeterにとりこまれてSlackのマイクとして設定できていることが確認できました。

この時点で、人の手でSlackのコメントをコピペしてVoiceVoxにはればSlack通話でずんだもんに喋らせることは出来るようになりました。
しかし、いちいちコピペするようでは使い物にならないので、プログラムを書きます。
実装方針
- Slackのスレッドからテキストを拾う
SlackのAPIで出来そうです。 - VoiceVoxとプログラムを連携
VoiceVox起動後はlocalにWebアプリが立ち上がり、以下のエンドポイントでそのドキュメントを見ることが出来ました。
http://localhost:50021/docs
各種APIが用意されており、これらを使う事でテキストを渡せば音声データを返してくれる仕組みを作れそうです。
Slack API
アプリを作成し、OAuth & Permissions以下のhistory関係の権限を与えます。
publicチャンネルでしか使わない場合は channels:historyのみ設定すればよいです。

Workspaceにインストールして、生成されたOAuth Tokenをメモしておきます。
このトークンを使って以下のAPIにチャンネルIDとタイムスタンプのパラメータを渡すと該当スレッドのメッセージ一覧を取得できます。
GET https://slack.com/api/conversations.replies
動作確認は以下のTesterからも出来ます。
VoiceVox API
-
speakers API
GET http://localhost:50021/speakers
docsのページからもどんなレスポンスなのか確認できます。
音声作成時には、ここのstyles[i].idを使ってどのキャラクターの音声を使うかを指定します。

ちなみにずんだもんのidは1, 3, 5, 7, 22, 38でした。

-
audio_query API
POST http://localhost:50021/audio_query
このAPIは「喋らせたいテキスト」と「スピーカー(speakers APIで見たid)」の2つのパラメータを投げると、音声を合成クエリを返します。
例えば「スラック読み上げずんだもん」というテキストとずんだもん(id = 1)を指定すると以下のレスポンスになりました。

audio_query_response.json
{
"accent_phrases": [
{
"moras": [
{
"text": "ス",
"consonant": "s",
"consonant_length": 0.13345441222190857,
"vowel": "u",
"vowel_length": 0.07529271394014359,
"pitch": 5.570389747619629
},
{
"text": "ラ",
"consonant": "r",
"consonant_length": 0.03259693831205368,
"vowel": "a",
"vowel_length": 0.21256236732006073,
"pitch": 5.874223709106445
},
{
"text": "ッ",
"consonant": null,
"consonant_length": null,
"vowel": "cl",
"vowel_length": 0.07669832557439804,
"pitch": 0
},
{
"text": "ク",
"consonant": "k",
"consonant_length": 0.0785050019621849,
"vowel": "u",
"vowel_length": 0.08580038696527481,
"pitch": 6.071834564208984
}
],
"accent": 2,
"pause_mora": null,
"is_interrogative": false
},
{
"moras": [
{
"text": "ヨ",
"consonant": "y",
"consonant_length": 0.0595722571015358,
"vowel": "o",
"vowel_length": 0.1041618064045906,
"pitch": 5.868217945098877
},
{
"text": "ミ",
"consonant": "m",
"consonant_length": 0.0805741548538208,
"vowel": "i",
"vowel_length": 0.10161403566598892,
"pitch": 5.744770050048828
},
{
"text": "ア",
"consonant": null,
"consonant_length": null,
"vowel": "a",
"vowel_length": 0.13067732751369476,
"pitch": 5.752403736114502
},
{
"text": "ゲ",
"consonant": "g",
"consonant_length": 0.06305412203073502,
"vowel": "e",
"vowel_length": 0.11421031504869461,
"pitch": 5.730293273925781
}
],
"accent": 4,
"pause_mora": null,
"is_interrogative": false
},
{
"moras": [
{
"text": "ズ",
"consonant": "z",
"consonant_length": 0.07837282121181488,
"vowel": "u",
"vowel_length": 0.11602171510457993,
"pitch": 5.758909702301025
},
{
"text": "ン",
"consonant": null,
"consonant_length": null,
"vowel": "N",
"vowel_length": 0.0835566595196724,
"pitch": 6.106016635894775
},
{
"text": "ダ",
"consonant": "d",
"consonant_length": 0.030238667502999306,
"vowel": "a",
"vowel_length": 0.12950901687145233,
"pitch": 6.111021995544434
},
{
"text": "モ",
"consonant": "m",
"consonant_length": 0.08292045444250107,
"vowel": "o",
"vowel_length": 0.15916754305362701,
"pitch": 5.876179218292236
},
{
"text": "ン",
"consonant": null,
"consonant_length": null,
"vowel": "N",
"vowel_length": 0.16144533455371857,
"pitch": 5.7281999588012695
}
],
"accent": 1,
"pause_mora": null,
"is_interrogative": false
}
],
"speedScale": 1,
"pitchScale": 0,
"intonationScale": 1,
"volumeScale": 1,
"prePhonemeLength": 0.1,
"postPhonemeLength": 0.1,
"outputSamplingRate": 24000,
"outputStereo": false,
"kana": "スラ'ック/ヨミアゲ'/ズ'ンダモン"
} -
synthesis API
POST http://localhost:50021/synthesis
audio_query APIのレスポンスをそのままこのAPIのリクエストに使うと対応する音声データが返ってきます。

audio_query APIのレスポンスaudio_query_response.jsonを使って、以下のcurlコマンド(Widowsを使っているのでGit Bashを使いました)でリクエストwavファイルを出力すると、ずんだもんが読み上げた音声データが手に入りました。curl -X 'POST' \ 'http://localhost:50021/synthesis?speaker=1&enable_interrogative_upspeak=true' \ -H 'accept: audio/wav' \ -H 'Content-Type: application/json' \ -d @audio_query_response.json > outout.wav
音声再生部分の仮実装
VoiceVox本体にテキストを入力して再生する際はVoiceVoxの設定画面から再生デバイスを選択することが出来たので、VoiceMeeterを指定できました。VoiceVox APIを使ったプログラムを書く際には、再生デバイスを指定できるように書く必要があります。
この辺り詳しくないのでChatGPTに聞いて簡単なスクリプトを準備しました。
Pythonでは再生ライブラリにpydubやsimpleaudioがありますが、これらでは直接出力デバイスを指定できないようです。
代わりに、pyaudioというライブラリを使えば自身のPCのオーディオデバイス一覧から使いたいものを選択できるようです。
pyaudioをインストールし、以下のPython3のコードを実行すると出力デバイスを選んで適当なWAVファイルを再生できました。
pip install pyaudio
import pyaudio
import wave
# 再生するWAVファイルのパス
wav_path = "output.wav"
# PyAudioの初期化
p = pyaudio.PyAudio()
# 利用可能なオーディオデバイスの一覧を表示
info = p.get_host_api_info_by_index(0)
num_devices = info.get('deviceCount')
for i in range(0, num_devices):
if (p.get_device_info_by_host_api_device_index(0, i).get('maxOutputChannels')) > 0:
print("Output Device id ", i, " - ", p.get_device_info_by_host_api_device_index(0, i).get('name'))
# 再生するオーディオデバイスのIDを指定(上記の一覧から選択)
output_device_id = int(input("Enter the output device id: "))
# WAVファイルを開く
wf = wave.open(wav_path, 'rb')
# ストリームを開く
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True,
output_device_index=output_device_id)
# 音声データをチャンク単位で読み込みながら再生
data = wf.readframes(1024)
while data:
stream.write(data)
data = wf.readframes(1024)
# ストリームを閉じる
stream.stop_stream()
stream.close()
# PyAudioを終了
p.terminate()
まとめ
ここまでの作業で以下の要素を確認できました。
- VoiceVoxでずんだもんに喋らせる
- オーディオミキサーを使って特定のアプリの音声をSlack通話の音声に載せる(任意)
- Slack APIを使って特定のスレッドのメッセージを監視する
- VoiceVoxのAPIを使ってテキストから音声データを得る
- 任意の音声デバイスでVouceVox APIで取得した音声を再生する
以上を組み合わせれば目的が達成できます。
実装(Python スクリプト)
Python 3.7.9で動作確認しました。
.envファイルを作成(.env_sampleをコピー)してSlackトークンなど各種必要な情報を入れて実行します。
実装(Rust スクリプト)
Pythonでとりあえず動くコードが出来たので、同じ内容のものをRustで書き直しました。
オーディオ系のライブラリにcpalがあり
これをラップしたrodioというライブラリを使いました。
$ rustup -V
rustup 1.26.0 (5af9b9484 2023-04-05)
info: This is the version for the rustup toolchain manager, not the rustc compiler.
info: The currently active `rustc` version is `rustc 1.74.0 (79e9716c9 2023-11-13)`
Pythonと同じく.envファイルを作成し、必要な値をセットして実行します。
PythonとRustのスクリプトが出来た時点のcommitは以下です(後の改修でここからいくらか効率化されています)。
Rustで書き直したところ、体感できるレベルで読み上げるまでの時間が短くなったので、実行時間について簡易的に測ってみました。
Python
Slack API request time: 0.27425646781921387 seconds
New message: コメントテスト7
VoiceVox API request time: 4.299270868301392 seconds
Rust
Slack API request time: 271.4027ms
New message: コメントテスト7
VoiceVox API request time: 754.1084ms
「コメントテスト7」という短いテキストを取得した場合において、Slack APIのレスポンス時間は大差ありませんが、VoiceVox API(audio_queryとsynthesisの合計)の時間は約3.5秒Rustの方が短くなっていました。
Pythonではaudio_query API、synthesis APIそれぞれで約2秒ずつかかっているようでした。
これ以上詳細は追っていないですが、雑にRustで書き直しただけで得をした気分になりました。
Rustスクリプトのリファクタリング
Rustのコードについて、ここからcore crateを作って主な処理をcoreに移し(後で名前衝突があったのでapp_coreにリネームされました)、既存のスクリプトはscriptプロジェクトを作成してcoreのロジックを呼ぶ形で書き直しました。
また、Slack APIの処理はslack.rs、オーディオ関係の処理をaudio.rsに分割しました。
デスクトップアプリを作る際のディレクトリ構成は以下のようなイメージになります。
rust_project_root/
│
├── core/ # core crate (共有コア機能)
│ ├── src/
│ │ └── lib.rs
│ │ └── slack.rs
│ │ └── audio.rs
│ └── Cargo.toml
│
├── script/ # scriptプロジェクト (既存のRustスクリプト)
│ ├── src/
│ │ └── main.rs
│ └── Cargo.toml
│
└── desktop/ # desktopプロジェクト (Tauriアプリ)
├── src-tauri/
│ ├── src/
│ │ └── main.rs # TauriのRustコード
│ └── Cargo.toml
├── src/ # Tauriのフロントエンドコード (React)
├── node_modules/
├── package-lock.json
├── package.json
機能追加
- スピーカーをenvで指定できるようにする
- スレッドのURLだけ設定すればいいようにした(URLからチャンネルとタイムスタンプを抽出する処理を追加)
.envファイルは以下のようになりました。
非機能の改修
- APIリクエストの度にreqwest clientを生成していたのを一度だけにする
- オーディオ再生の度に出力ストリームを作成していたのを一度だけにする(デスクトップ版では断念)
実装(Rust Tauri デスクトップアプリ)
セットアップ
Tauriを使ってデスクトップアプリを作っていきます。
create-tauri-appを使ってアプリの雛形を作成しました。
UIはReact、TypeScriptを選択しました。
$ cargo install create-tauri-app --locked
$ cargo create-tauri-app
✔ Project name · desktop
✔ Choose which language to use for your frontend · TypeScript / JavaScript - (pnpm, yarn, npm, bun)
✔ Choose your package manager · npm
✔ Choose your UI template · React - (https://reactjs.org/)
✔ Choose your UI flavor · TypeScript
Template created! To get started run:
cd desktop
npm install
npm run tauri dev
iconについては1024x1024pxのpngを用意すれば cargo iconコマンドで各種サイズのアイコン画像を生成してくれました。
実装一部紹介
デバイス一覧を画面に表示する部分について触れます。
Rust側ではcommandを用意します。
Rustスクリプトで使っていたデバイス一覧取得関数を呼び出す関数device_listを定義し、
#[command]アトリビュートをつけるとUI側から呼び出せるcommandになります。
React側では上記のコマンドを呼び出します。
import { invoke } from "@tauri-apps/api/tauri";
invoke関数を使います。
const deviceList = await invoke<string[]>("device_list");が該当箇所です。
今回は引数が無いcommandですが、第2引数でパラメータを渡すこともできます。
もう一つ、設定を保存するcommand save_settingsについて触れます。
こちらはcommand呼び出し時にReactから以下の形式のオブジェクトを渡しています。
export interface Settings {
slackToken: string;
threadUrl: string;
voicevoxUrl: string;
speakerStyleId: string;
}
Rust側ではこれを受けるためのstructを用意します。
commandは以下です。
地味に詰まったポイント
-
命名規則
TypeScript, Reactでは変数をキャメルケース、Rustではスネークケースで書くため、やり取りするデータ(JSON)のプロパティ名を変換する必要がありました。
フロントエンドに返すデータの構造体に#[serde(rename_all = "camelCase")]をつければ自動的にスネークケースをキャメルケースにして返してくれるようになって解決しました(RustでWebバックエンドを作るときにもよくある話かもしれない)。 -
coreクレートの名前が衝突していた
desktop開発時にcoreから関数をインポートしようとCargo.tomlに追記してからコンパイルエラーが出始めました。エラー文は以下でした。error[E0433]: failed to resolve: could not find `option` in `core` --> src\main.rs:35:14 | 35 | .run(tauri::generate_context!()) | ^^^^^^^^^^^^^^^^^^^^^^^^^^ could not find `option` in `core` | = note: this error originates in the macro `tauri::generate_context` (in Nightly builds, run with -Z macro-backtrace for more info) help: consider importing one of these items | 4 + use serde::__private::Option; | 4 + use std::option::Option; |Rustの標準ライブラリにcoreクレートがあり、これと名前衝突したのが原因(おそらく自前のcoreの名前が優先)でした。coreクレートをリネームして解決した。crateに分割するときはあまり一般的すぎる名前をつけると何かのcrateの内部で使っているcrateと名前が衝突する可能性があるので気を付けないといけないという学びを得ました。
成果物
各OS向けのbuildを行ってくれるGitHub Actionsがあるのでこちらを使いました。
Ubuntuで音声系のライブラリが不足している旨で一度buildエラーが出ましたが、apt-get install libasound2-devの追記で解消しました。
Ubuntuでのbuildエラー
--- stderr
thread 'main' panicked at /home/runner/.cargo/registry/src/index.crates.io-6f17d22bba15001f/alsa-sys-0.3.1/build.rs:13:18:
PKG_CONFIG_ALLOW_SYSTEM_CFLAGS="1" PKG_CONFIG_ALLOW_SYSTEM_LIBS="1" "pkg-config" "--libs" "--cflags" "alsa" did not exit successfully: exit status: 1
error: could not find system library 'alsa' required by the 'alsa-sys' crate
--- stderr
Package alsa was not found in the pkg-config search path.
Perhaps you should add the directory containing `alsa.pc'
to the PKG_CONFIG_PATH environment variable
No package 'alsa' found
note: run with RUST_BACKTRACE=1 environment variable to display a backtrace
warning: build failed, waiting for other jobs to finish...
Error failed to build app: failed to build app
Error: Command failed with exit code 1: tauri build
ワークフローファイルはmainブランチpush時に実行されるように指定しました。 buildが成功するとリリースのドラフトを作成し、そこにbuild資材を添付してくれるのですが、GitHubのリリースページへの反映に(たまたま?)ラグがあり、5回ほど再実行をしてやっとドラフトが出来たのを見つけました(累計分がたまっていました)。
以下のリリースページにてインストーラーがダウンロードできます。
-
Windows向け
SlackVoiceReader_0.0.1_x64-setup.exe
SlackVoiceReader_0.0.1_x64_en-US.msi -
Linux向け
slack-voice-reader_0.0.1_amd64.AppImage
slack-voice-reader_0.0.1_amd64.deb(DebianベースのLinuxディストリビューション(Ubuntuなど)向け) -
macOS向け
SlackVoiceReader_0.0.1_x64.dmg
SlackVoiceReader_x64.app.tar.gz
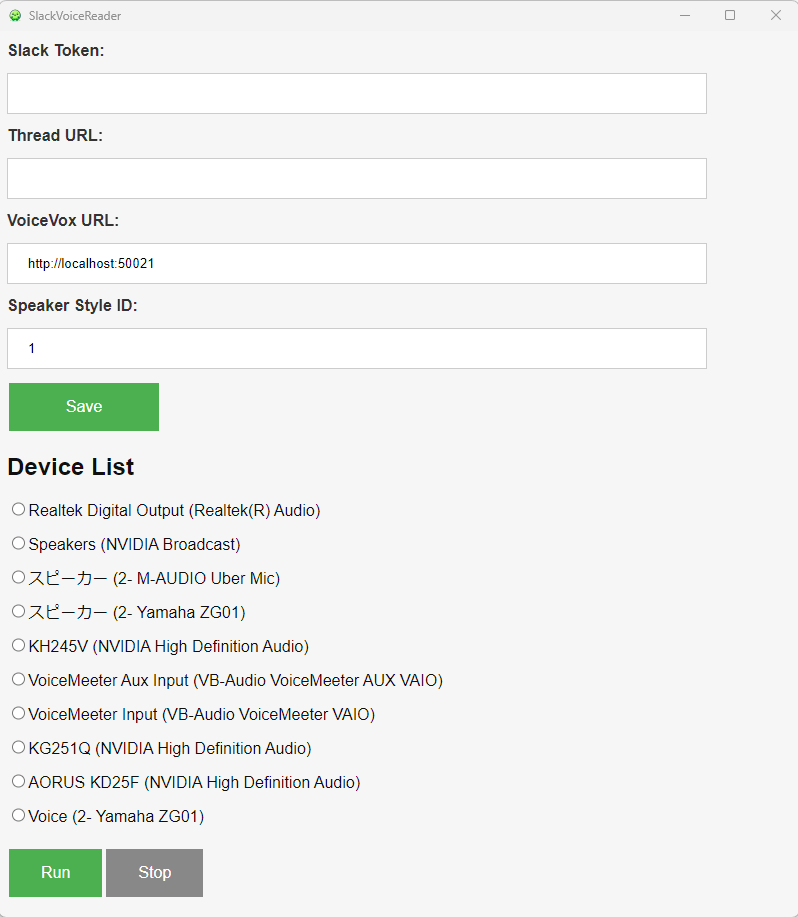
インストールしてアプリを起動すると以下の画面になります。
Slack APIを利用するためのトークンと、監視対象のスレッドURLを記載して保存し、音声機器を選択して「Run」をクリックすると監視・読み上げが始まります。
毎回設定値を入れるのは煩わしいので、保存すると次回起動時にも保存した設定を読み込むようにしました。
デバイスを選べるようにしたのはオーディオミキサーを選べるようにするためでした。
使ってみてのコメント
- 移動中など、マイクを使用できないときにコメント(読み上げ音声)でミーティングに参加できるかも。
ミーティングに参加している人(or Slackワークスペースの人)毎にidを振り分けて、読み上げ音声を変えると識別も出来そう。 - 特定のSlackスレッドだけ別の通知音(読み上げ音声)にすることで反応しやすくなる(あんまりこういう使い方はしていない)。
基本的にSlackの通知は切っている(メンションなどだけ通知音が鳴る)ので、メンションがつかなかったとしても早く気づきたいスレッドに仕込むなど。
例:「Notion」→「えぬおーてぃあいおーえぬ」 - ずんだもんが話している間に投稿されたコメントを拾う事が出来ない
現状
①Slack APIでテキスト取得
②VoiceVoxでテキストから音声作成
③再生
を直列でやっており、③が終わるまで新規に①の処理が走ることはない。
主に時間がかかるのは②・③の処理。
①については独立して実行してメッセージをためておく。
②・③の処理が終わったら読み上げたメッセージを削除する。
というような実装をすればメッセージの拾い漏れはなくなる。
漏れなくコメントを読み上げさせる必要性は今のところないけれど、オプションとして機能追加してもいいかもしれない。 - エラーメッセージ
VoiceVoxが起動していない、Slack APIの認証が通らない、該当スレッドが見つからない、など色々な事情でエラーになり得るが、アプリの画面には適切なメッセージが出せていない。
使用上の注意点
ユーザー体験関連
- リンクが貼られたときに不要な読み上げ時間が流れる
https://zenn.dev/sh11235 のように、リンクテキストをそのまま「えいちてぃてぃぴーえす...」と読み上げてしまいます。リンクテキストを見つけたら省略する改修が必要に感じました。
2023/12/25 以下で対応しました。
- 英単語
アルファベットの記号名をそのまま読むので、人が聞き取って解釈するのが難しい。よく出てくる単語については辞書を作るなどしておくといいかもしれない。
通話の音声にも読み上げ音声を載せるためにVoiceMeeterなどサウンドミキサーを使ってアプリ音声とマイク音声をミックスする場合
-
自分の声も聞こえてしまう問題
読み上げ音声と同時に自分のマイク音声もVoiveMeeterアプリの音声として聞こえてしまいます。これを何とかするために、VoiceMeeterアプリの音量を下げる(Windowsだと音量ミキサー)と自分のマイク音声だけでなく読み上げ音声のボリュームも下がってしまいます(VoiceMeeterアプリにマイクを接続して声を出すとどういう事情か分かると思います)。
何とかするには2つ方法を考えています。- 本アプリがVoiceMeeterともう一つ別のスピーカーの両方でサウンドを流すようにし、ユーザーがVoiceMeeterアプリのアプリ音量を0にする(アプリの改修が必要)。
- 本アプリを起動する端末ではマイクを使わない(ご家庭のサブPCや、オフィスの共用PC/共用SlackアカウントなどでSlack通話に入り、アプリを起動させるなど)
-
VoiceMeeterのGain値設定
そのままだと多くの人のマイク音声より大きな音量に感じられたので、Gainを-5~-15くらいに下げるとよさそうです。
Discussion