Codecraftersで最高難易度の「Build your own SQLite」にGoで挑戦してみた
はじめに
- ソースコードはこちら
- 技術書以外で、コードを書くことを通じてソフトウェアエンジニアリングの勉強がしたい
- BTreeとかB+Treeとか聞いたことはあるけどよく分からない。実際にBTreeからどうやってデータを取ってくるか知りたい
- SQLiteの内部構造が知りたい
といった方におすすめの内容となっています!
この記事では、Codecraftersについての説明に始まり、SQLiteの内部構造(一部)、BTree(B+Tree)を実際にコードでtraverseする方法、ビッグエンディアンとリトルエンディアン、Goで実装する際の注意点、Build your own SQLiteの各Stepの説明をしていきます。
Codecraftersとは?
Codecraftersは、
Programming challenges for seasoned developers.
つまり、「経験豊富な開発者のためのプログラミング課題集」となります。
具体的には、HTTP・DNSサーバ、インタプリタ、今回解説するSQLiteの実装など、いわゆるすでに世界で広く使われているものを再実装することでそれらの内部構造についての知識をつけたり、技術面接対策をしたり、新しいプログラミング言語で複雑なコードが書けるようになるための良い材料となります。
最高難易度のBuild your own SQLite
2024年8月時点で10個ほどコースがあるのですが、その中でBuild your own SQLiteは最高難易度が設定されています。

Build your own SQLiteの各Stepの難易度表。ほぼ全てHard
他のコースは、コース全体の数%〜10%弱くらいHardがあるくらいですが、ほぼ全てのStepがHardなのは2024年8月時点ではBuild your own SQLiteだけです。ちなみに、Hardの難易度の目安は、「熟練開発者が実装に1時間以上かかる」です。
コースの進め方としては、「最初にSQLiteの内部構造の公式ドキュメントのリンク貼るから、それ読んでガンバッテ!」みたいな感じなので、おそらくほぼ全てのStepで難易度がHardに設定されているのは、公式ドキュメントを自力で読み込んで実装に落とし込まなければいけないのが要因だと思います。
逆に言えば、公式ドキュメントの内容が理解でき、かつ、いくつかのGoで実装する際の落とし穴を回避できれば、それほど詰まることなく最後まで到達できます!
Build your own SQLiteは有料コースなので、ソースコードを公開するのはナシか? と最初は思ったものの、Codecrafters側が「ぜひあなたの回答をGithubにpushしてみんなに共有しよう!」と言っているので、ガンガンソースコード載せます😆
BTree
世の中にBTreeの解説は山ほどあるのでここでは深くは説明しません。簡単に言うと、二分探索木に似つつ、ファンアウトを大きく=ツリーの高さを低く=ディスクシークの回数を減らすことにより、二分探索木の欠点を補った木構造です。
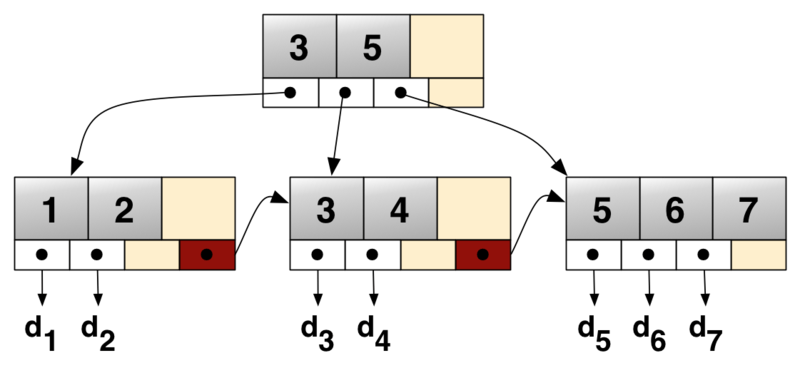
https://en.wikipedia.org/wiki/B%2B_tree
SQLiteの内部構造
https://www.sqlite.org/fileformat.html#the_database_header を参考に解説してきます!
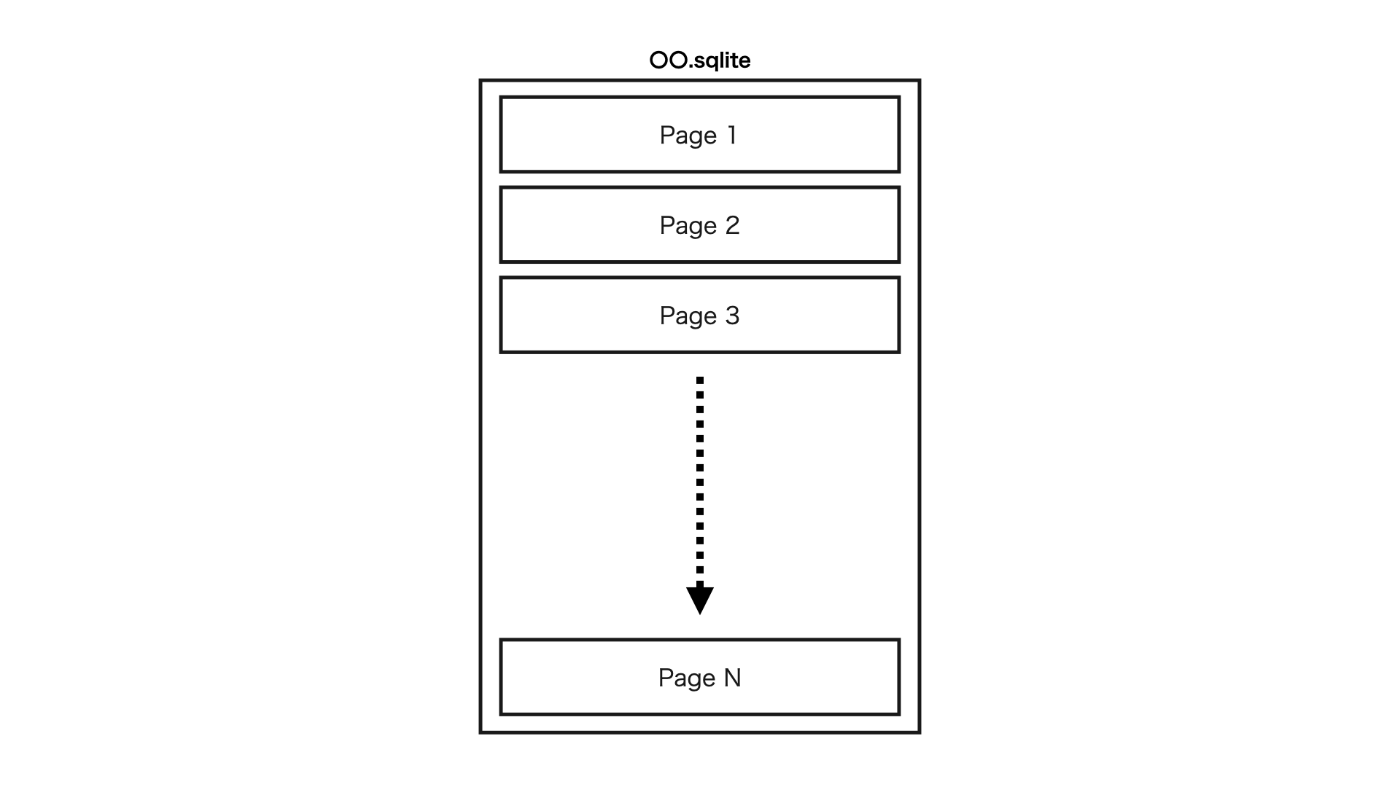
Pages
SQLiteファイルの構成要素です。〇〇.dbあるいは〇〇.sqliteのSQLiteのファイルは、以下の図のようにPageの集合で構成されます。
BTree Page Header
全てのPageに共通することとして、そのPageがどういうものなのかという情報を格納するHeaderがあります。これをBTree Page Headerといい、以下のフォーマットになります。

Headerの最初のバイトにPageの種類が格納されています。上の画像を見ると、4種類あるのが分かると思います。この種類によって、Headerのサイズ、Headerに続くCellの形式が変わってきます。
Cell
Headerで、Pageの種類が分かるので、Headerに続くCellの読み進め方が分かるようになります。
4種類の各PageのCell内容を可視化している良い記事があったので共有します。
Page1
Page1は他のPagesとは違った特性があります。
それは、ファイル自体の情報を格納したHeaderがあるという点です。これを Database Headerと呼びます。

Pagesまとめ
- SQLiteのデータベースファイルは、Pageで構成されている
- 各Pageには、BTree Headerが存在する
- Pageの種類によってHeaderの後に続くPayloadの読み方が変わる
- Page1にはBTree Headerに加えて、Database Headerが存在する
Cell
Pageのメインコンテンツです。
例として、Table Leaf Pageを挙げます。Table Leaf Pageでは、Cellには実際のデータが格納されています。つまり、Cellを読むことによって、あるテーブルの、ある行の、それぞれのカラムに対する値を取ってくることができます。
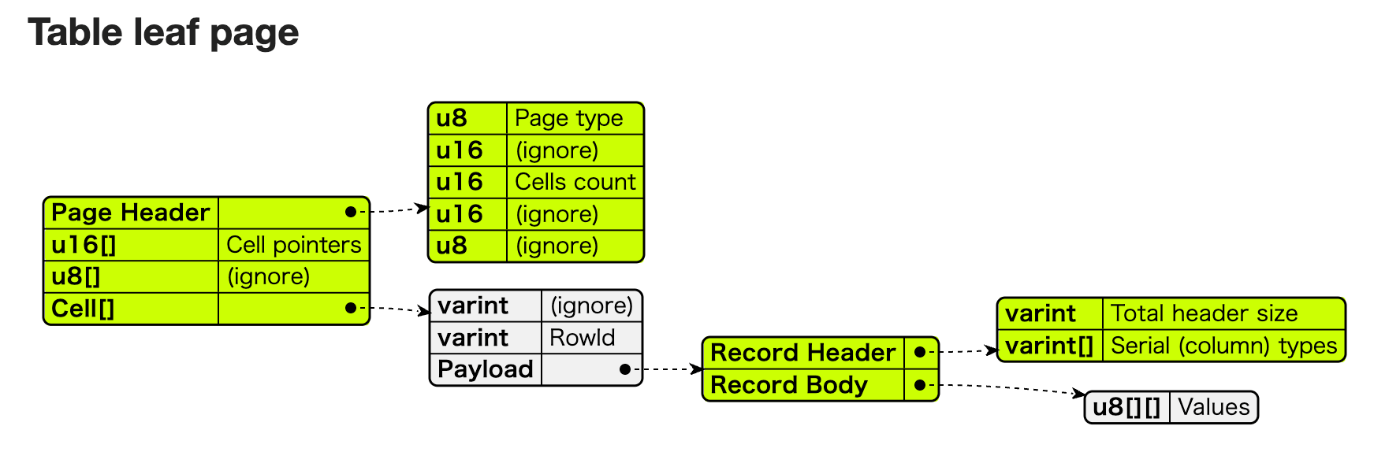
https://saveriomiroddi.github.io/SQLIte-database-file-format-diagrams/
行番号は上の図のRowIDに該当します。
PayloadのRecord HeaderのSerial Typesは、カラムの型を格納しています。
とりうるSerial Typesは以下の通りです。
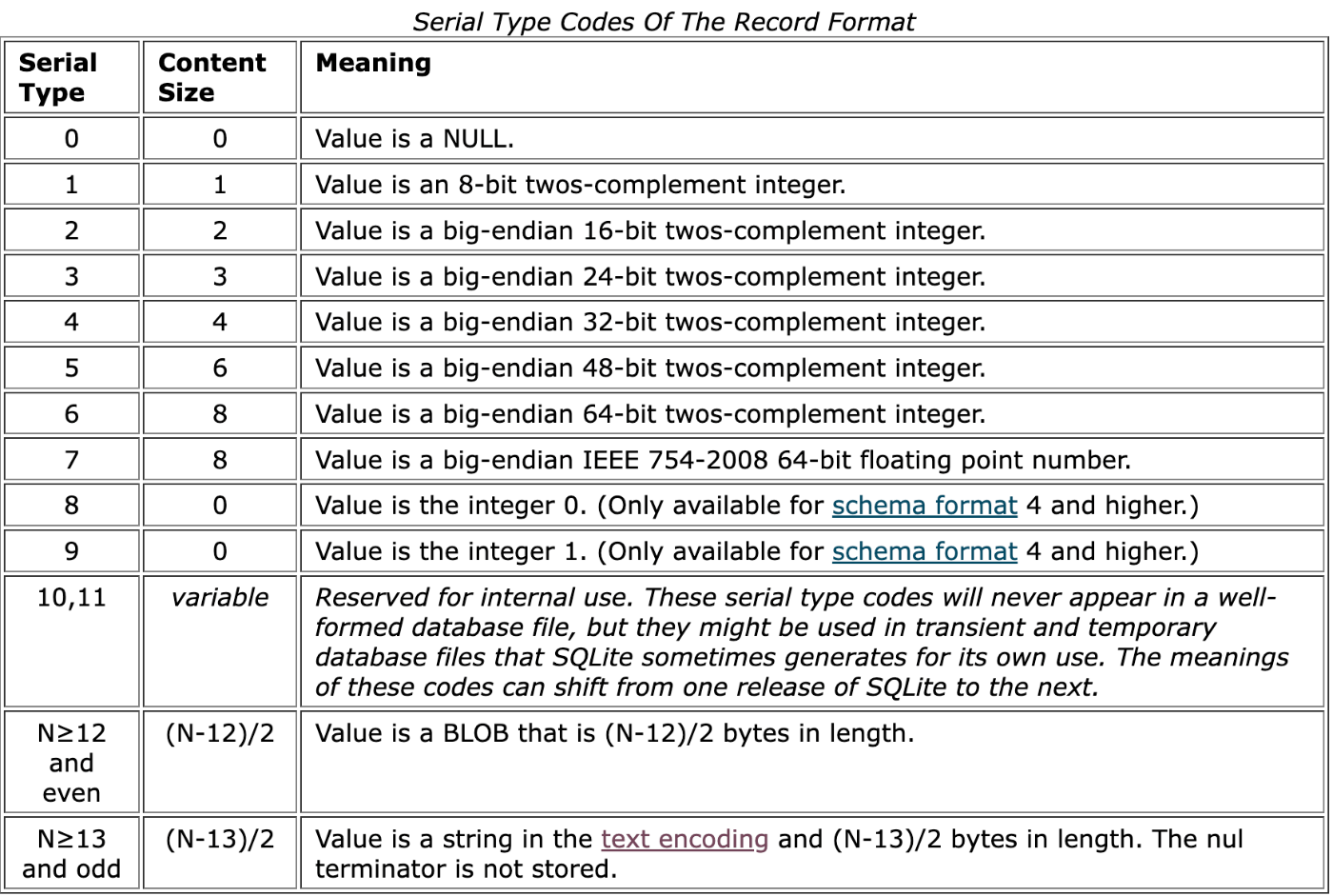
Serial Typesを読み終えると、いよいよ実際のデータ(Record Body)を取得する段階に入ります。
各Serial Typeで、読み取るべきバイト数が明確になるので、Serial Typesに格納されているカラム順に、読み取るべきバイト数分ずつ読んでいきます。
例えば、Serial Typesが2, 3, 7の順番で格納されていた場合、Record Bodyを取得するには2バイト、3バイト、8バイトと読んでいきます。(Serial Typeが7の場合、Content Sizeが8と公式ドキュメントに書いてあるので、8バイト読む)。
Pageに含まれる全てのCellを取得したいときは、BTree Page Headerで取得したCellCount分ループを回せばOKです。
バイトオーダー
いわゆるバイト列をどういった順番で書き込む&読み込むかという話です。
方法としては、大きくリトルエンディアンとビッグエンディアンの2つの方式があります。
これについても世の中にたくさん記事があるのでここでは詳しく解説しません。良いイメージ図があったので貼っておきます。
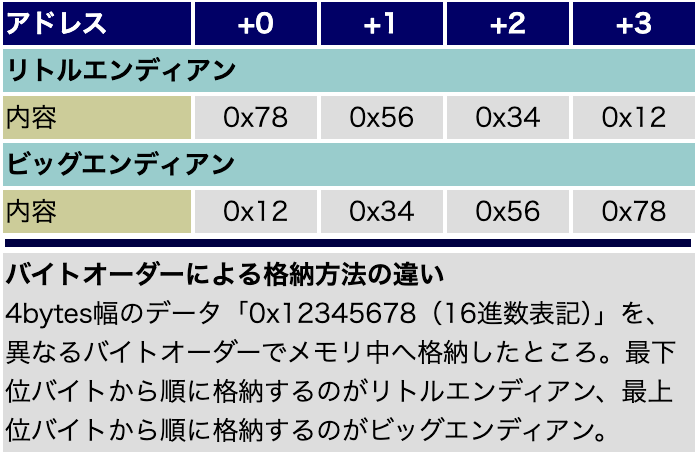
https://atmarkit.itmedia.co.jp/icd/root/70/5784470.html
SQLiteでは、基本的にビッグエンディアンが使われています。 そのため、間違ってバイト列をリトルエンディアンで読んでしまうと、全く違う値を取ってきて上手く動作しないということに繋がります。
Build your own SQLiteの各Stepの解説
Print Page Size
Page Sizeの情報はDatabase Headerに格納されています。
以下のoffset=16, size=2のところに、
The database page size in bytes
と書いてあるので、16バイト目から2バイト分をビッグエンディアンで取って来れば良いです。
func NewFileHeader(f *os.File) (*FileHeader, uint, error) {
buf := make([]byte, FileHeaderSize)
if _, err := f.Read(buf); err != nil {
return nil, 0, err
}
headerStrBuf := string(buf[0:fileHeaderInitStringSize])
if headerStrBuf != fileHeaderString {
return nil, 0, errors.New("invalid file header")
}
var pageSize uint16
if err := binary.Read(bytes.NewReader(buf[16:18]), binary.BigEndian, &pageSize); err != nil {
return nil, 0, fmt.Errorf("failed to read integer: %v", err)
}
return &FileHeader{pageSize}, FileHeaderSize, nil
}
Print number of tables
まず、Page1に具体的にどんな情報が格納されているかというと、sqlite_masterテーブルというテーブルの内容が格納されています。

sqlite_master
つまり、sqlite_masterテーブル(Page1)で、typeがtableであるものの個数を数えれば良いです。
ただ、BTree HeaderのCellCountの値を返すだけで現状テストは通ってしまいますし、僕自身はその実装のままです(修正面倒くさい...)。
BTree Headerの読み込み
func NewBTreeHeader(f *os.File, offset uint) (*BTreeHeader, uint, error) {
buf := make([]byte, 1)
if _, err := f.ReadAt(buf, int64(offset)); err != nil {
return nil, 0, err
}
var pageTypeNum uint8
if err := binary.Read(bytes.NewReader(buf), binary.BigEndian, &pageTypeNum); err != nil {
return nil, 0, err
}
pageType := PageType(pageTypeNum)
bTreeHeaderSize, err := pageType.GetBTreeHeaderSize()
if err != nil {
return nil, 0, err
}
buf = make([]byte, bTreeHeaderSize)
if _, err := f.ReadAt(buf, int64(offset)); err != nil {
return nil, 0, err
}
var cellCount uint16
if err := binary.Read(bytes.NewReader(buf[3:5]), binary.BigEndian, &cellCount); err != nil {
return nil, 0, err
}
var cellContentAreaStartsAt uint16
if err := binary.Read(bytes.NewReader(buf[5:7]), binary.BigEndian, &cellContentAreaStartsAt); err != nil {
return nil, 0, err
}
var rightMostPointer uint32
if pageType == InteriorTableBTree || pageType == InteriorIndexBTree {
if err := binary.Read(bytes.NewReader(buf[8:12]), binary.BigEndian, &rightMostPointer); err != nil {
return nil, 0, err
}
}
return &BTreeHeader{
PageType: pageType,
CellCount: cellCount,
CellContentAreaStartsAt: cellContentAreaStartsAt,
RightMostPointer: uint(rightMostPointer),
}, bTreeHeaderSize, nil
}
ちなみに、他の人で、Pageの中の「CREATE TABLE」の文言の個数を数える回答がそこそこ多いですが、個人的には邪道に感じますし、その調子だと次以降のStepではごまかしが効かないので詰まってしまいます。
Print table names
sqlite_masterテーブルのtypeがtableである行のtbl_nameカラムの値を取って来れば良いです。
func newSQLiteMasterRow(c *cell.LeafTablePageCell) (*SQLiteMasterRow, error) {
objectType, err := c.SerialTypeAndRecords[0].String()
if err != nil {
return nil, err
}
if !isObjectType(objectType) {
return nil, fmt.Errorf("invalid object type: %s", objectType)
}
name, err := c.SerialTypeAndRecords[1].String()
if err != nil {
return nil, err
}
tableName, err := c.SerialTypeAndRecords[2].String()
if err != nil {
return nil, err
}
rootPage, err := c.SerialTypeAndRecords[3].Int()
if err != nil {
return nil, err
}
q, err := c.SerialTypeAndRecords[4].String()
if err != nil {
return nil, err
}
return &SQLiteMasterRow{
RowID: c.RowID,
ObjectType: ObjectType(objectType),
Name: name,
TableName: tableName,
RootPage: int(rootPage),
SQL: q,
}, nil
}
func NewSQLiteMasterRows(cs cell.LeafTablePageCells) (SQLiteMasterRows, error) {
rows := make(SQLiteMasterRows, len(cs))
for i, c := range cs {
row, err := newSQLiteMasterRow(c)
if err != nil {
return nil, err
}
rows[i] = row
}
return rows, nil
}
Count rows in a table
この段階ではWHERE句がないかつLeaf Table PageなのでCellCountを返せば良いです
Read data from a single column
ここで、Cellの詳細を取得する必要が出てきました。
ポイントは、Cellにおけるカラムの格納順です。CellではSerial Typesが順番に並んでいるのですが、カラム名の情報はそこにはありません。
では、どのカラム順でSerial Typesが並んでいるかというと、sqlite_masterテーブルのsqlカラムにあるCREATE TABLE文のカラム順に並んでいます。それを念頭にCellの該当のカラムを読み込めば良いです。
varintを読むときの注意点
Cellではvarintが多用されていますが、このvarintをbinary.Uvarint()で取ってこようとしても上手くいきません。なぜなら、binary.Uvarintはリトルエンディアンのバイト列を読み取ることを前提としていますが、SQLiteはビッグエンディアンだからです。
ビッグエンディアンでvarintを読み取るときは、まず最初の1バイト(=オクテット)目を取得します。
ここで、そのバイトをバイナリで表した時に、実際の値の部分は最初のビットを除いた7ビットになります。
最初の1ビットは、「次のバイトを読むか」を判断する識別子になります。つまり、最初のビットが0ならそのバイトでvarintの読み込みは終わり、1なら次のバイトを読んで、今まで読んだ値の下位7ビットをシフトしてから論理和を取れば良いです。
// Uvarint decodes Big-endian bytes to uint64
func Uvarint(buf []byte) (uint64, int) {
var result int64
var bytesRead int
for bytesRead < len(buf) {
b := buf[bytesRead : bytesRead+1][0]
bytesRead++
result = (result << 7) | int64(b&0x7F)
if b&0x80 == 0 {
break
}
}
return uint64(result), bytesRead
}
Read data from multiple columns
「Read data from a single column」から取ってくるカラムの数を増やしただけなので、本質的にはそれほど難しくないです。
ただ、structの設計とかがまずいと細々したところで時間が溶けていく可能性があります。
Filter data with a WHERE clause
この段階ではフルスキャンを想定した実装になります。これも「Read data from a single column」がちゃんと理解して実装できていたら難しくありません。単にWHEREの条件に合うか合わないかでCellの取捨選択をすれば良いです。
Retrieve data using a full-table scan
フルスキャンなので「Filter data with a WHERE clause」と一見同じに見えますが、より大きなデータを扱うので、Pageの構造が変わってきます。
これ以前のStepでは、Leaf Table BTree Pageだけを扱えばよかったですが、今回のStepでは、RootPageがInterior Table BTreeになります。つまり、ちゃんとBTreeをtraverseしてLeaf Table BTreeまで辿り着く必要があります。
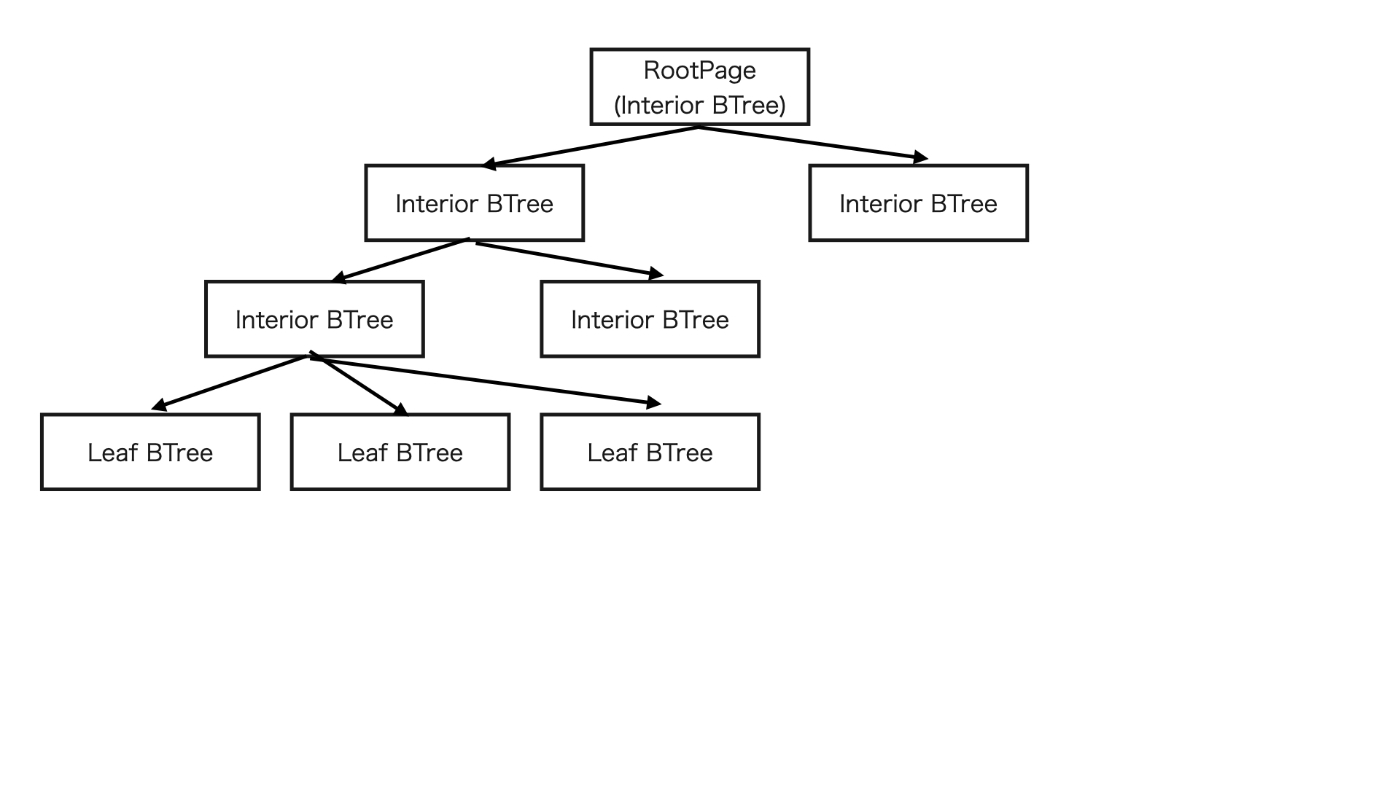
travarseする方法は色々ありますが、僕は再帰関数を使って実装しました。他にはキューを使ったやり方とかもあると思います。
ここで再帰関数が使えるのは、任意のInterior BTreeが、下位のBTreeに対し「もしあなたがLeaf BTreeならCellを全部読み込んで。そうでなければ下位のBTreeを全部見に行って」という同じ命令を下すことができるからです
func (db *sqlite) traverseInteriorTableToGetCells(t *TraverseBTree) (cell.LeafTablePageCells, error) {
b, bhSize, err := header.NewBTreeHeader(db.f, (t.PageNum-1)*db.PageSize())
if err != nil {
return nil, err
}
if b.PageType == header.LeafTableBTree {
return db.getLeafTablePageCells(t)
}
ip, err := page.NewInteriorTable(db.f, db.PageSize(), t.PageNum)
if err != nil {
return nil, err
}
cells, err := cell.NewInteriorTablePageCells(db.f, &cell.NewInteriorTablePageCellRequest{
PageType: ip.PageType,
PageOffset: uint64(ip.Offset),
HeaderOffset: uint64(bhSize),
CellCount: uint64(ip.BTreeHeader.CellCount),
})
if err != nil {
return nil, err
}
leafCells := make(cell.LeafTablePageCells, 0)
for _, c := range cells {
cs, err := db.traverseInteriorTableToGetCells(&TraverseBTree{
PageNum: uint(c.LeftChildPageNum),
Table: t.Table,
Columns: t.Columns,
Where: t.Where,
})
if err != nil {
return nil, err
}
leafCells = append(leafCells, cs...)
}
cs, err := db.traverseInteriorTableToGetCells(&TraverseBTree{
PageNum: ip.RightMostPointer,
Table: t.Table,
Columns: t.Columns,
Where: t.Where,
})
if err != nil {
return nil, err
}
leafCells = append(leafCells, cs...)
return leafCells, nil
}
Retrieve data using an index
2024年8月時点ではこれが最後の問題です。
Index BTreeをtravarseしてWHEREの条件に合致するレコードのRowIDsを取ってきて、そのRowIDsをもとにInterior BTreeをtraverseすれば良いです。
つまり、Index BTreeと、Table BTreeで2回traverseする必要があります。
余談ですが、これで、Covering index (range) scanが速い理由が分かりますね!SELECTするカラムが全てIndex BTree上にあればTable BTreeを見にいく必要がないので、traverseが1回で済みます。
Index BTreeでもTable BTreeでも、traverseする際は、余分なPageを見に行かないことが大事です。でないとBTreeである意味がなくなってしまいます。
もう一度BTreeの図を載せます。
https://en.wikipedia.org/wiki/B%2B_tree
ここで、例えば4のデータが欲しい場合、全てのLeaf BTreeを見にいくのではなく、真ん中のLeaf BTreeだけを見に行けば良いです。なぜなら、4は、3より大きく5以下(開閉区間か閉開区間なのかはBTreeの実装によって異なります)なので、3と5の間にあるポインタが指し示すPageNumberに該当するPageを見に行けば良いです。
このように、BTreeでは見にいくPageを効率的に取捨選択できるので、素早い検索が可能になっています。
targetRowIDs, err := db.traverseInteriorIndexesToGetTargetRowIDs(traverse)
if err != nil {
return nil, err
}
pn, err := db.PageNum(table)
if err != nil {
return nil, err
}
cells, err := db.traverseInteriorTablesToGetCellsByPK(&TraverseBTreeByPrimaryKey{
PageNum: uint(pn),
Table: table,
Columns: columns,
PrimaryKeys: targetRowIDs,
})
return cells, nil
https://github.com/sgasho/codecrafters-sqlite-go/blob/d1da5895cb6665b6a26cb37253968aaacffd0195/app/sqlite/query_handler.go#L139-L154 traverseInteriorTablesToGetCellsByPKとしてPrimaryKeyをもとに検索するという印象を与えるメソッド名になってしまっていますが、実際はRowIDをもとに検索しています
実際最後までやってみてどうだったか
まず、「SQLiteのドキュメント読んでね」という指示を読み飛ばしていたので、Print table namesのところで引っかかり、2週間くらい放置していました...やっぱり問題文を読まない人は淘汰されるんですね...
ドキュメントを読み始めてからは、処理自体の実装は割とスムーズにいきました。ただ、頻繁にコードの設計を見直したりしていたのでそこで結構時間が取られました。
やっぱり普段の開発だと、設計とかがある程度固まっている状態からのJOINになるので(バックエンドならClean Architecture, フロントエンドならAtomic Designを参考にした設計などなど)、割とスムーズに開発ができるのですが、今回のように1から作ると自分の設計力がいかに低いか痛感させられます。
今回の課題で何回か設計を見直しましたが、それでも依存関係がpackageごとにごちゃごちゃしていたりと、お世辞にも綺麗な設計とは言えないですね。interfaceを使った依存関係の逆転とかもほとんど行っていないです。
あと、ドキュメント以外ほぼ頼るものがない状態で数千行にも渡るコードを書くというのが刺激的で良い体験になりました。
また、ファイルの読み書き(今回は主に読む方)も勉強になりました。ビッグエンディアンとかリトルエンディアンとか普段の開発でほとんど意識しないので...
まとめると、SQLiteやBTreeの知識がある程度血肉になったことに加え、ペラ1枚のドキュメントを頼りに1からゴリゴリ実装した経験が、今後のエンジニア人生でも役立つのでは? と密かに期待しています😊
Discussion