OpenAI API で開発してての学び
トークン量について
私たちのモデルは、テキストをトークンに分解して理解し処理します。トークンは、単語や文字の塊になります。例えば、「hamburger」という単語は、「ham」、「bur」、「ger」というトークンに分解されますが、「pear」という短くて一般的な単語は1つのトークンです。多くのトークンは、例えば「こんにちは」と「さようなら」のように空白から始まります。
与えられたAPIリクエストで処理されるトークンの数は、入力と出力の長さによって異なります。大まかな目安として、英語のテキストでは1トークンは約4文字または0.75語です。考慮すべき制限の1つとして、テキストのプロンプトと生成された補完がモデルの最大コンテキスト長を超えないようにしなければなりません(ほとんどのモデルでは2048トークン、または約1500語です)。
GPT-3.5 だと大体 4096 トークンです。
| LATEST MODEL | DESCRIPTION | MAX TOKENS | TRAINING DATA |
|---|---|---|---|
| gpt-3.5-turbo | Most capable GPT-3.5 model and optimized for chat at 1/10th the cost of text-davinci-003. Will be updated with our latest model iteration. | 4,096 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-0301 | Snapshot of gpt-3.5-turbo from March 1st 2023. Unlike gpt-3.5-turbo, this model will not receive updates, and will only be supported for a three month period ending on June 1st 2023. | 4,096 tokens | Up to Sep 2021 |
| text-davinci-003 | Can do any language task with better quality, longer output, and consistent instruction-following than the curie, babbage, or ada models. Also supports inserting completions within text. | 4,097 tokens | Up to Jun 2021 |
| text-davinci-002 | Similar capabilities to text-davinci-003 but trained with supervised fine-tuning instead of reinforcement learning | 4,097 tokens | Up to Jun 2021 |
| code-davinci-002 | Optimized for code-completion tasks | 8,001 tokens | Up to Jun 2021 |
GPT-4 だと 8192 トークンに伸びてます。嬉しい!
| LATEST MODEL | DESCRIPTION | MAX TOKENS | TRAINING DATA |
|---|---|---|---|
| gpt-4 | More capable than any GPT-3.5 model, able to do more complex tasks, and optimized for chat. Will be updated with our latest model iteration. | 8,192 tokens | Up to Sep 2021 |
| gpt-4-0314 | Snapshot of gpt-4 from March 14th 2023. Unlike gpt-4, this model will not receive updates, and will only be supported for a three month period ending on June 14th 2023. | 8,192 tokens | Up to Sep 2021 |
| gpt-4-32k | Same capabilities as the base gpt-4 mode but with 4x the context length. Will be updated with our latest model iteration. | 32,768 tokens | Up to Sep 2021 |
| gpt-4-32k-0314 | Snapshot of gpt-4-32 from March 14th 2023. Unlike gpt-4-32k, this model will not receive updates, and will only be supported for a three month period ending on June 14th 2023. | 32,768 tokens | Up to Sep 2021 |
トークン量の確認
プロンプトがどのくらいのトークン量なのかはこちらからテキストエリアにペタッと貼れば確認することができます。
ただし、GPT-3 の場合なので、GPT-4 などを使う場合はもう少し減るかもしれません。
プログラマブルに確認する方法として一つにリクエストのレスポンスを見るという方法があります。
API のレスポンスにはこんな感じで usage というオブジェクトが存在します。

ただ、リクエストを送る前に判定したいこともあるでしょう、私はありました。
すごいざっくりでいいのであれば、英語の場合は 1 Token = 4 characters ぐらいみたいなので、文字列の length を 4 で割ったらそこまでズレていないトークン量は手に入ると思います。
それに関してはこちらの Tiktoken というライブラリを活用すればできるみたいです。
有志の npm パッケージもあったりしました。
節約法
そんなトークンですが節約する方法がいくつかあります。
英語
残念ながら日本語(というか英語以外?)はトークン量的には大分不利なようです。
今めっちゃテキトーに文章を書いてみましたが、同じ意味の文章でも2倍ぐらいのトークン量となっています。
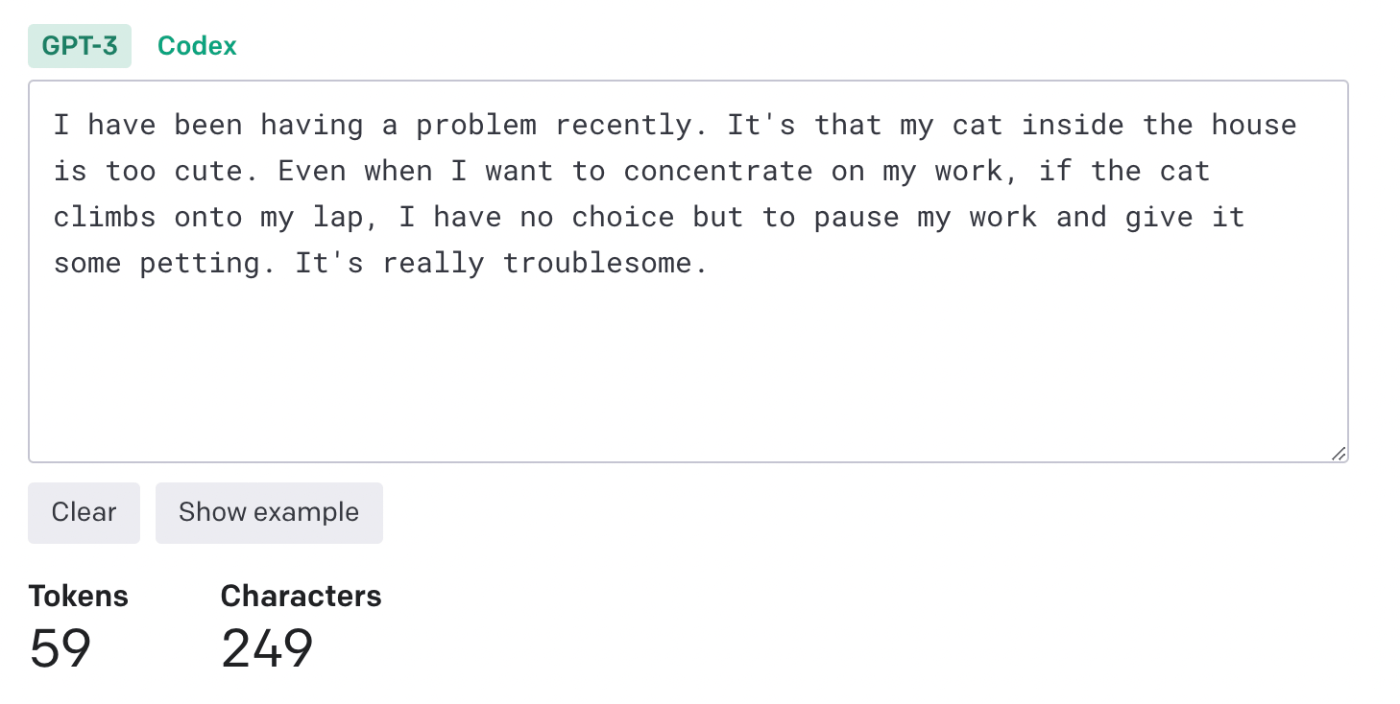
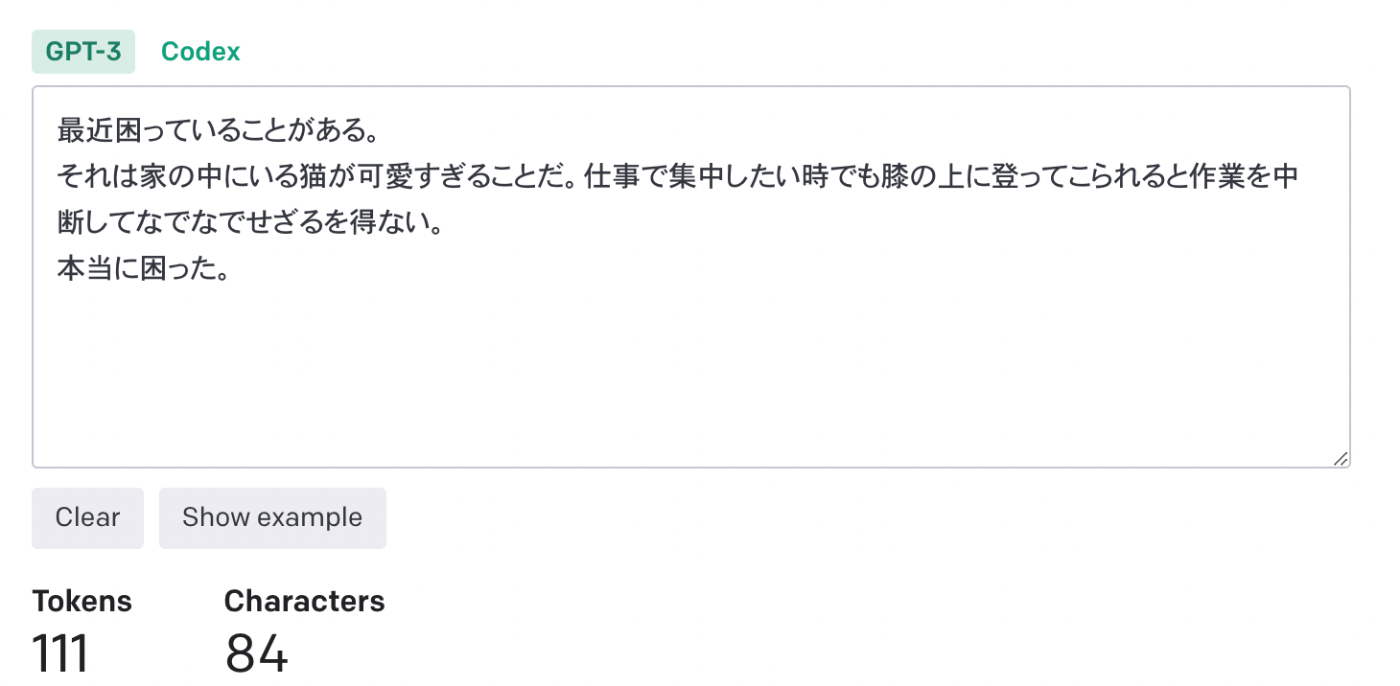
なのでとりあえずプロンプトは英語で書くのが基本となるでしょう。使いたいデータが日本語の場合はその限りではないかもしれないですが...。
要約する
長いなら要約してしまえばいいじゃないというシンプルな発想ですが、自分で頑張って要約してもいいですし、これも ChatGPT さんにお願いしてもらうのはアリだと思います。
また、Langchain というツールの中に ConversationSummaryMemory という正に要約のためのものがあるのでこれを活用してみるのもいいと思います。
絵文字で圧縮
多少できる模様です。時代は象形文字。しかし失われた情報もそれなりにあるもよう。
こちらは React コードが Lossless で圧縮できた事例です。
やってほしいことを分割する
これもそらそうだろという話ではありますが、一度のプロンプトでなんとかしようとするのではなく、独立したタスクが複数あるのなら分割するのも手です。
あとこれはトークン量というよりお金的な話なのですが、分割した結果 GPT-4 じゃなくて 3.5-turbo でも十分だな、という処理は 3.5-turbo にしておくと料金が大分安くなります。
回答を安定させたい
いざシステムに組み込んで使おうという時に、毎回微妙に違う回答をされてこいつぅ!となることがよくあります。
正直まだ安定させる方法やテストする方法全然分かってないのですが、今の所の工夫
リクエストのパラメータ
temperature と top_p というパラメータをいじれば安定させることができます。
temperature は高い値ほど回答のばらつきが大きくなります。安定させたい場合はとりあえず 0 にしておけばいいです。
「0」と「2」の間でどのサンプリング温度を使用するか決めてください。0.8のような高い値は、出力をよりランダムにします。一方、0.2のような低い値は、出力をより焦点を絞った、決定論的なものにします。
top_p はサンプリングする対象を絞ることにより安定性を増すことができるみたいです。
温度によるサンプリングの代わりに、核サンプリングと呼ばれる手法があります。この方法では、モデルはtop_p確率の質量を持つトークンの結果を考慮します。つまり、0.1とすると、上位10%の確率質量を持つトークンだけが考慮されます。
それぞれ安定性を増すために有効なパラメータですが、両方を同時にいじることは推奨されていないようです。(なんでだろう)
We generally recommend altering this or temperature but not both.
出力形式を指定する
回答の形式をしっかり指定するとあまりぶれない印象があります。
例えば下記のような形で JSON にして返してくれよ、と伝えると、とりあえず30回ぐらいはこのプロンプト実行したと思いますが、これ以外のフォーマットで返したことはないです。
## constraints
out put as JSON in following property names, do not include new line since this string is going to be parsed with JSON.parse
{ "branchName": "branch name", "commitMessage": "commit message", "prTitle": "PR title", "componentName": "component name" }
あとは月並みな話にはなりますが、プロンプトを実行して「ここはいつも同じ感じにしてほしいなぁ」と思ったところをしっかり言語化してプロンプトに含めるというのを繰り返すという地道なプロセスを辿る必要があると思います。
【TypeScript ユーザ向け】ライブラリを使う
OpenAI が専用の API クライアント作ってくれているのでこれを使いましょう。
...しかし Origin が null になってしまうような環境(a.k.a Figma プラグイン)だとエラーが出てしまいますのでスニペットをここに記しておきます。(私が書いた訳でないのですが元となった stackoverflow のページが見つからず引用元が貼れないすまない)
createChatCompletion.ts
type Chat = { role: 'user' | 'assistant'; content: string };
async function fetchStream(stream: any) {
const reader = stream.getReader();
let charsReceived = 0;
let chunks: Uint8Array = new Uint8Array([]);
await reader
.read()
.then(function processText({
done,
value,
}: {
done: boolean;
value: Uint8Array;
}) {
if (done) {
console.log('Stream complete');
return chunks;
}
charsReceived += value.length;
const chunk = value;
console.log(
`Received ${charsReceived} characters so far. Current chunk = ${chunk}`
);
chunks = new Uint8Array([...chunks, ...chunk]);
return reader.read().then(processText);
});
const decorder = new TextDecoder();
const resultString = decorder.decode(chunks);
const response = JSON.parse(resultString);
return response;
}
export async function createChatCompletion(
chat: string,
previousChats: Chat[],
use35turbo?: boolean
) {
const DEFAULT_PARAMS = {
model: use35turbo ? 'gpt-3.5-turbo' : 'gpt-4',
messages: [...previousChats, { role: 'user', content: chat }],
temperature: 0,
};
const params_ = { ...DEFAULT_PARAMS };
const result = await fetch('https://api.openai.com/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
Authorization: 'Bearer ' + String(process.env.OPENAI_API_KEY),
},
body: JSON.stringify(params_),
});
const stream = result.body;
const output = await fetchStream(stream);
return output.choices[0].message.content;
}
LangChain ブラウザで使えるやったね
Next.js の ChatGPT Plugin スターター
Next Supabase のスターター
mdx 置いとくだけでサーチができるようになるらしい
独自データを元に回答してもらう
- embedding
- fine-tuning
- embedding と fine-tuning について
- embedding は主にサーチには優秀
- ただどうもその内容を構造化して使うというところはやってくれていないように見える
- 例: コンポーネントの Variants を JSON として Vectorstore に保存して、Buttonコンポーネントの Props を教えて、のような質問を投げたが Typical な答えしか返してくれなかった
- なので曖昧検索がうまくできるぐらいの期待値なのかも
なので fine-tuning をしてみたいのですが、現状 OpenAI の場合は GPT-3.5 はおろか GPT-3 までしかできません。
それでも与えた情報に対してだけならいい感じの回答してくれるようになるのかな?
MemoryGPT の解釈例なるほど
TS で LangChain 使って embedding 試した事例
知見集