LLMにまつわる"評価"を整理する
「LLMの評価」というフレーズを見て、どんなことを思い浮かべるでしょうか?
おそらく大半はLLMモデル自体の評価のことを思い浮かべると思います。新しいモデルが出てきた時に𝕏で見かける「GPT-4o のMMLUベンチマークは89%!」みたいなアレ。
ですが、プロダクト開発にLLMを使っている人の間では、プロンプト等が十分な品質を出しているかの確認などにも評価という言葉を使っていることは多いのではないかと思います。
うまい具合に後者を区別するためにいい感じの呼び名を付与したい気持ちがあるのですが、英語圏での例を見てみるとシンプルに"Evals"と呼んでることもあれば
- Evaluating LLM System
- Evaluating LLM-based Applications
などなど表現の仕方は様々になっています。
そしてそのプロダクト開発文脈での評価も、実態としてはオフライン評価やオンライン評価などと呼ばれる違った目的の評価があり、"評価"という言葉だけを漠然と捉えていると認識齟齬や期待値のズレが起きるなぁと感じています。
という訳で、一記事にテーマを二つ混ぜちゃうのですが以下について考えてみようと思います。
- モデル自体の評価とLLMプロダクトの評価は何が違うのか
- LLMプロダクト開発の中での評価は具体的にどんなことをするのか
用語の定義
本編に入る前に軽く私が思う、「評価」という言葉をこういう意味合いで捉えている、という定義を書いておきます。
「LLMシステムのアウトプットに対して、事前に定義した品質基準や指標に照らし合わせ、システムの性能や品質を測定、判断すること」
この定義には、以下のような行為が含まれます。
- 期待するアウトプットと実際のアウトプットを比較し、スコアをつける
- 評価基準に基づいて、システムの出力が許容できるものかどうかを判断する(合格/不合格の判定)
- 評価結果を数値化し、システムの性能を定量的に測定する
後述するオンライン評価などは次のような違う意味合いのものも含んでいたりするのですが、一旦この記事内で評価という言葉だけを使っている時は基本上記の意図で使っています。
- ユーザーからのフィードバックの収集と分析
- システムの利用状況のモニタリングと分析
- A/Bテストなどを通じた、異なるバージョンのシステムの比較
モデル自体の評価とLLMプロダクトの評価は何が違うのか
まず大枠として、目的が大きく異なっています。
モデル自体の評価の目的
特定のタスクにおいて
- モデルが目標とする精度を満たしているかを確認する
- 複数のモデルを比較できるようにする
LLMプロダクトの評価の目的
LLMシステムがプロダクト要件を満たしているかを確認する。
前者は性能評価をして横並びでモデル同士を比較できるようにする目的ですが、後者は特定のプロダクトでのシステム全体の振る舞いを検査しています。
それぞれについて、より具体的に見ていきます。
モデル自体の評価
LLMを性能評価している世にあるベンチマークたちはLLMの特定の側面の性能を測ることを目的としています。
ベンチマークは
- MMLUやTruthfulQAなどLLMとしての機能全般について測っているもの
- MT-Benchなどよりhumanityよりの側面について測れるようにしているもの
- SWE-Benchなどより具体的なタスクにおける性能を測るもの
などなど様々なベンチマークがありますが、このようなベンチマークたちがあるおかげで我々は複数のモデルの性能を比較することができます。
上記はどちらかというとモデルの消費者目線な性能評価の話ですが、実際にモデルを作っている方々は自分たちが作ったモデルがいいベンチマーク結果を出すかの確認に使っているのでしょう、多分。(モデル公開したことないので分からない)
LLMプロダクトの評価
一方"LLMプロダクトの評価"の文脈では「LLMを使った機能の要件が十分に満たされているか」を確認する品質保証的な意味合いが強いです(後述しますがそれ以外のニュアンスもあります)。
LLMをシステムに組み込んで使うとき、LLMに渡すインプットにはある程度制約があります。その期待されるインプット空間とそれに対応する期待するアウトプットを定義し、実際にシステムを動かして期待する品質に達しているか・妥協できるレベルかをジャッジします。
"システム"というものも実に様々なものを含みます。一番シンプルな形としてはLLMに対して単一のプロンプトを送るだけの場合もあれば、Agentic Workflowと呼ばれる複数のプロンプトを分岐させていくフローを組んだり、RAGなどで過去の文脈情報を引っ張ってくるなどいろんな処理が含まれます。
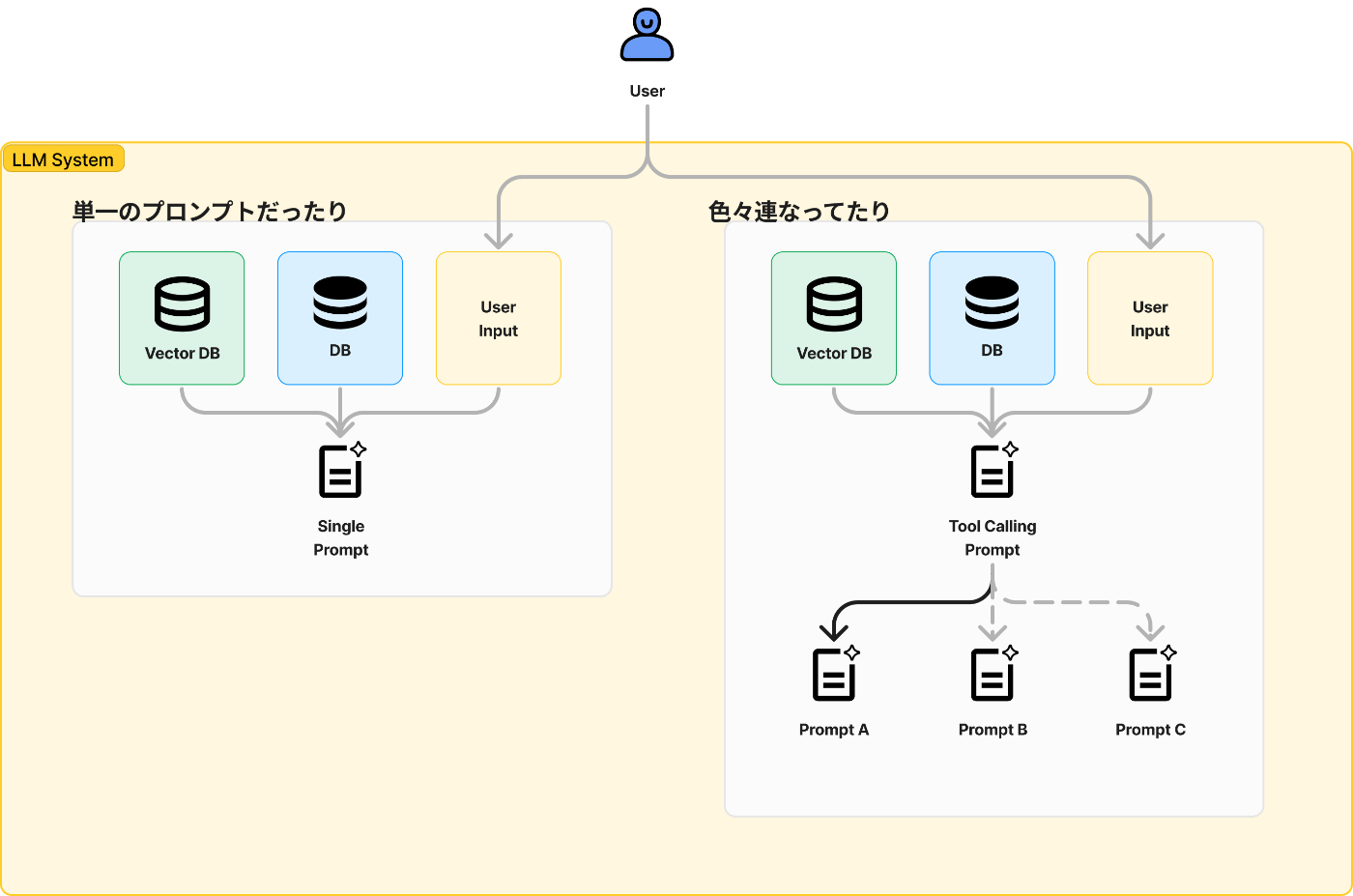
このため利用者目線では評価する対象はシステムが返してくる応答だけではあるのですが、それを改善するためには
- プロンプトを変える
- エージェント設計を変える
- 入れるデータを変える
- モデルを変える
など様々な手段が考慮に上がります。
最終的なアウトプットの品質が期待に満たない場合に、原因の切り分けや個別のチューニングをするために、上記のような個々のコンポーネントたちに対して評価が実行できる環境を整えることが必要になってきます。
ちなみにこのセクションでは「モデル自体の評価とLLMプロダクトの評価は何が違うのか」をテーマとしていますが、実際のところこの精度改善の手段として、モデル自体の評価ベンチマークを見て「こっちのモデルに差し替えても良さそう〜」のような判断に使ったりします。
話を戻すと、この「LLMプロダクトの評価」というのは行為としては間違いなく"評価"しているのですが、目的は要件を満たしているかの品質保証です。なので最近はもっと品質保証よりの呼び方をする方が誤解を招きづらいのではないかと考えています。
機械学習品質マネジメントガイドラインの中では機械学習を使ったプロダクト・システムのことを機械学習利用システムと呼称しています。それに倣うと「LLM利用システム品質保証」とか、もう少し短くすると「LLMシステムQA」あたりの呼び方がちょうどいい塩梅なのではないでしょうか。
という訳でこの記事では今後はLLMシステムQAという表記で進んでみようと思います。
以上、「モデル自体の評価」と「LLMシステムQA」は目的が異なることを見てきました。
次にLLMシステムQAの中でも"評価"という行為が一口に言っても様々な目的で行われているため、それについて整理していきたいと思います。
余談: 品質とは何か
先のセクションで品質保証という単語が出てきましたが、これもまた評価と同様にやや漠然としているので私なりの考えをここに書いていきます。
念の為断りを入れておくのですが、ここで書く品質の考え方は私個人の経験に基づくものであり、体系的なものではありません。より詳しい情報については、以下の資料を参照することをおすすめします。
QA4AI:
機械学習品質マネジメントガイドライン:
さて、システム全体を見た時、品質には様々な側面があります。LLMシステムの応答がタスクに対して期待する振る舞いをしているかという機能要求もあれば、パフォーマンスや可用性などの非機能要求もあります。しかし、今回は冒頭で定義した評価という行為が対象とする、ユーザがLLMシステムを使う時の品質、つまり利用時品質に焦点を当てて話を進めます。
利用時品質という語彙は機械学習品質マネジメントガイドラインから引用しているのですが、その中では
システムがその全体として利用時に満たすことが期待される
品質として定義されています。これはプロダクトの実現したいことから落として定義されるはずで、それも一度作ったら終わりというものではなく、実際の使われ方によって随時アップデートされていきます。
この利用時品質をもう少し分類する考え方として、私の経験から、LLMが出力した結果を見ていく中で出てくる課題は、以下の3つの分類のいずれかに当てはまると考えています。
- ガードレール: 安全性(エログロ、政治的な発言をしない)、異常な出力をしない(同じ単語をひたすら繰り返すなど)などプロダクト要求関係なく守りたい品質
- プロダクト要件から落とし込まれる品質
2. ネガティブ: 「こういう答えが出ないで欲しい」
3. ポジティブ: 「こういう答えが返ってきて欲しい」
これらの分類は、製品やサービスの品質を評価するための狩野モデルに当てはめて考えることができます。
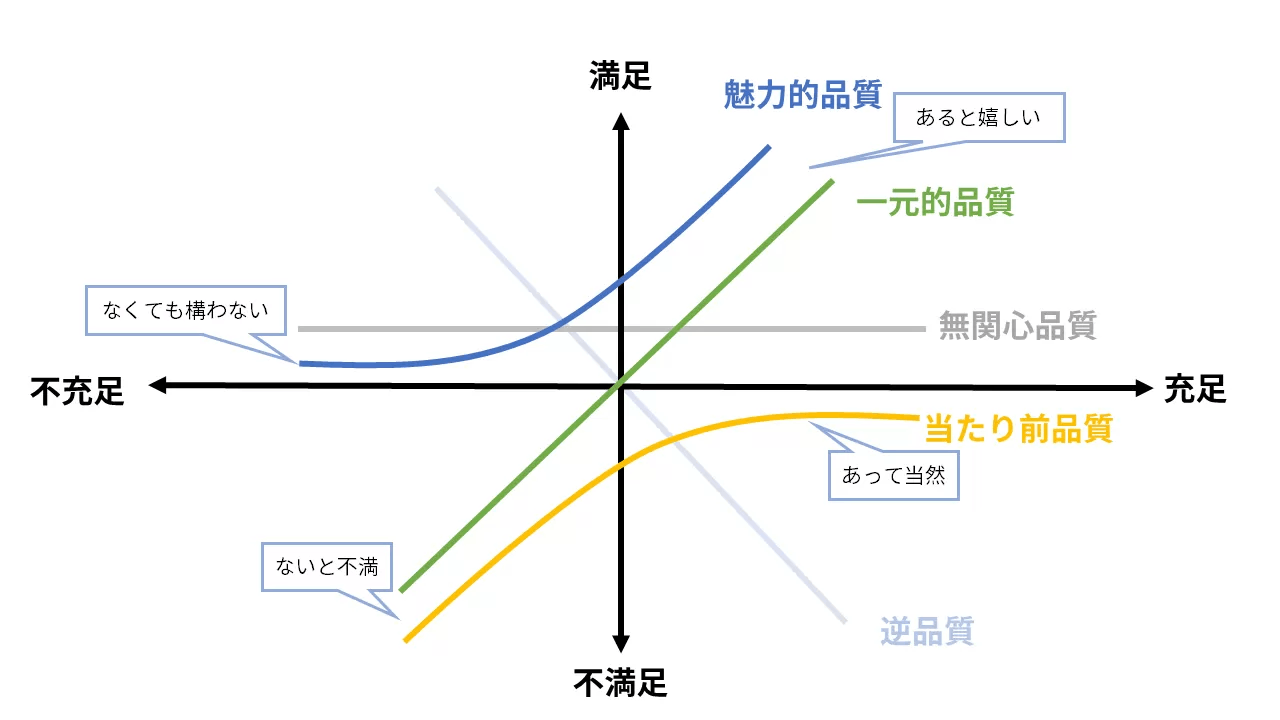
狩野モデルでは、品質を「当たり前品質」「一元的品質」「魅力的品質」の3つに分類します。これに当てはめると、ガードレールは「当たり前品質」、ネガティブな要求は「当たり前品質」と「一元的品質」、ポジティブな要求は「一元的品質」と「魅力的品質」に対応すると考えられます。
この分類と言い換えの何が嬉しいかという話ですが「このフェーズではここの品質まで磨きこもうという会話がしやすくなる」という点です。
例えば、魅力品質の部分を社内だけで作るデータセットで磨き込むのは無理があり、ユーザの実際の使い方などから継続的に改善する必要があります。なのでとりあえずリリースまでは当たり前品質とクリティカルな一元的品質までは担保して、その後満たせるようにしていく、といった具合です。
このように品質を階層的に捉えることで、チーム内での期待値のすり合わせがしやすくなるでしょう、多分。
それでは品質という言葉に関して考えるのはここまでにして、次にLLMシステムQAの中でも色々ある評価の定義・目的について見ていきます。
LLMシステムQAにおける"評価"の種類
最近"評価"という言葉が使われる時、人により文脈により思い思いの目的を想定してそうだな〜と感じることがありました。
例として次のような目的を念頭に使われることがあります。
- 精度を改善していくにあたっての目標を定める、課題を洗い出す
- プロダクトの機能としてリリースする前の品質判断をする
- 実際にユーザに対してポジティブな影響を与えているかを計測する
- ダイナミックに評価結果を使うことによって精度を改善する
"評価"という行為自体も「一個作ったら全部に万能に使える」という性質のものではなく、評価のためのデータセットを作るのに時間がかかりますし、数もそこそこ多くなります。
なので、上述したような目的の内、何がいつ・どのくらいの頻度で求められるかを踏まえた上でどんな評価を作っていくかの戦略が必要になってきます。
これらのような目的を分けられる語彙として、機械学習界の先人たちが既にオフライン評価・オンライン評価という呼び方をしてくれているのでこれらについて見ていきます。
概要
オフライン/オンラインの違いはざっくり言うと「実際のプロダクトを通じた評価かどうか」です。
オフライン評価は、開発段階において、事前に設定した評価基準やデータセットを用いてLLMシステムの品質を測定します。これは、いわば「実験室」での評価、とでも呼ぶと意味合いがイメージしやすいかもしれません。主な目的は、LLMシステムが期待通りの性能を発揮するかどうかを検証し、問題があれば繰り返し修正することです。
対してオンラインでは実際にLLMを使った機能をリリースした後にユーザからのフィードバックをもらったり、機能の使われ具合を見たりA/Bテストでアルゴリズムやモデルの違いを検証したりします。
なので同じ"評価"というフレーズを使いつつも、オフラインの方は上述してきたLLM QAの意味合いが近く、オンラインの方はデータ分析によってインサイトを得て継続的に改善する意味合いが強いです。
ただし、オンラインで得られたデータやフィードバックが次の改善の方向性を見出すこと、ひいてはオフライン評価の補強に繋がるので完全に切り離された概念同士ではありません。
ざっくり概要だけご紹介したので、それぞれに対してもう少し具体的に見ていきます。
オフライン評価
オフライン評価ではLLMを使ったシステムによるアウトプット自体を評価します。
プロダクト開発では機能要件を定義してから実装し、その機能がうまく動いているかをテストしますが、その機能が実際のユーザに役に立っているかなどはまた別の検証スコープです。そういった意味合いで"アウトプット自体"という表現をしています。
オフライン評価では、まずプロダクトで満たしたい要件があり、そこから期待するインプットとアウトプットのペアによるデータセットとそれが求める品質を満たしているかを確認する指標となる評価基準を定義します。
例えば以下はドラえもんに似させて話すロールプレイするLLMシステムを評価する時のデータセットと評価基準の一例です。
インプットとアウトプットのペアのデータセットの具体例(ドラえもんを模倣する場合)
| インプット | 期待するアウトプット |
|---|---|
| 今日の天気はどうですか? | のび太くん、今日はいい天気だよ。公園に遊びに行くといいね! |
| 宿題を手伝ってください! | のび太くん、宿題は自分でやらないと力がつかないよ。でも、難しいところはボクが教えるから頑張ろう! |
| しずかちゃんに叱られました... | のび太くん、しずかちゃんに叱られるのは、のび太くんが悪いことをしたからだよ。反省して、謝ったほうがいいね。 |
| ジャイアンにいじめられています... | のび太くん、いじめは絶対にダメだ!ボクがジャイアンに話をするから、一緒に解決しよう。 |
評価基準の例
- キャラクターの口調や言葉遣いが適切であるか
- ドラえもんらしい優しい口調で話しているか
- 「のび太くん」など、キャラクターらしい呼び方をしているか
- キャラクターの性格や行動原理に沿った応答となっているか
- ドラえもんとして、のび太を助けようとする姿勢が見られるか
- 問題解決に向けた建設的な提案をしているか
- キャラクターの知識や設定に矛盾がないか
- 秘密道具についての説明に矛盾がないか
- 他のキャラクターとの関係性が設定通りであるか
- 文脈に合った自然な応答となっているか
- 質問や相談に対して的確な返答ができているか
- 会話の流れが不自然になっていないか
これらを元にインプットデータを使ってシステムを回してアウトプットを生成し、そのアウトプットを評価基準に照らし合わせて評価したり、期待するアウトプットと見比べて課題を洗い出したりします。
既にちょっと触れましたが、この評価という行為は次のようなことを目的に行われます。
精度を改善していくにあたっての目標を定める、課題を洗い出す
LLM使ったシステムを開発していくにあたっては一回プロンプトを書いたら終わりというケースはほぼあり得なく、何回も繰り返し結果を見ながらチューニングしていく必要があります。
この時に求める品質(=期待するアウトプットと評価基準)が定義されずに闇雲にチューニングしていくと、まずそのチューニング作業自体が非常に疲れますし、結果としてできるものの品質もその作業者の主観に大きく寄ってしまいます。
なのでいわゆる正解データを用意して、それを指標にどれくらい近づいているかを判断することによって品質のブレも少なく、またチューニング作業もゴールが明確な状態で進めることができます。
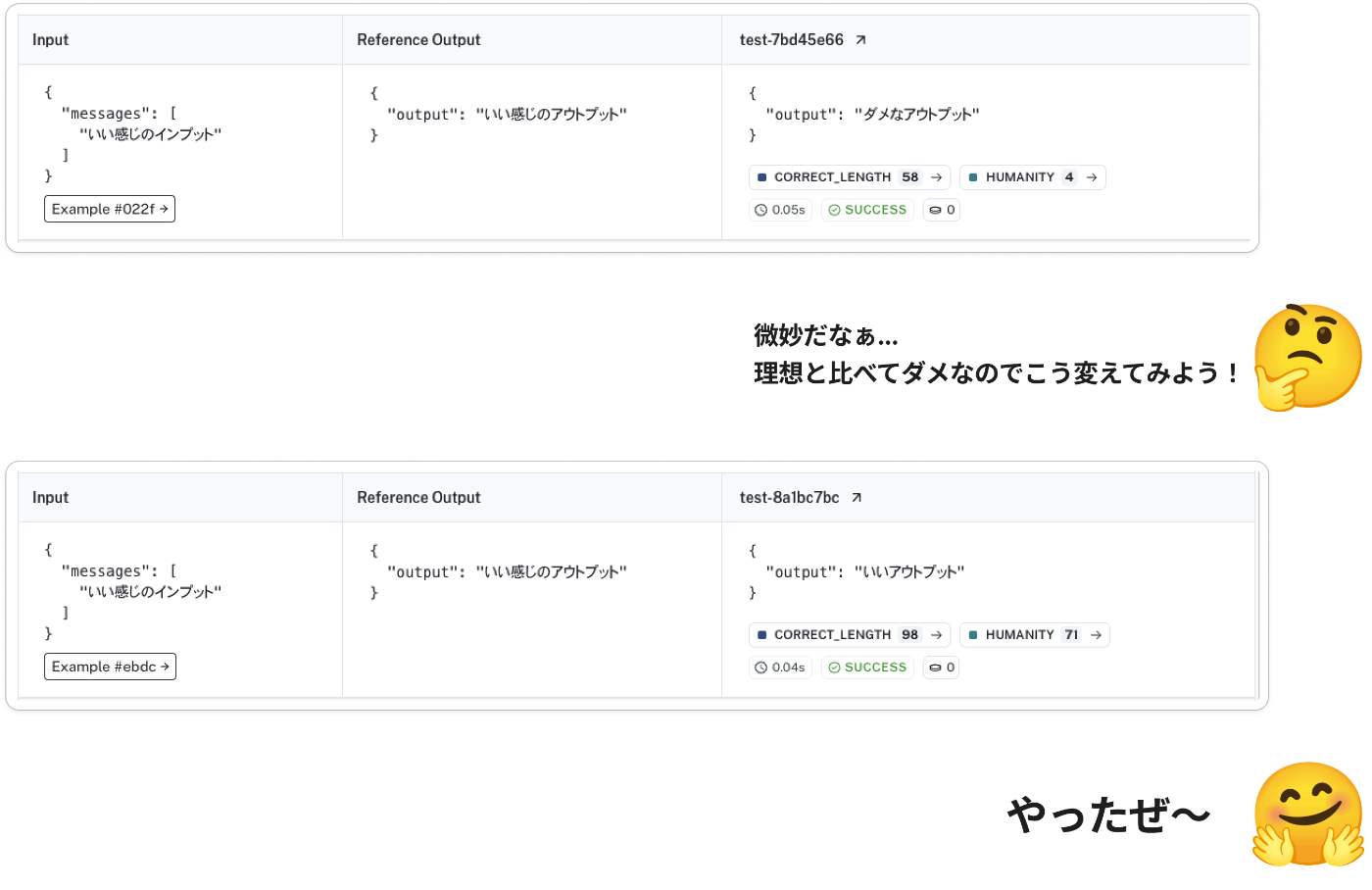
この時はある意味繰り返し改善していく中で都度評価をしている状態で、この評価は基本チューニング実行者が目検でやっていることが多いですが、LLMなどによる自動評価もあると課題を発見しやすくなるなどの効率化に寄与します。
プロダクトの機能としてリリースする前の品質判断をする
上記のチューニングの行為自体のゴールが定めた品質を満たすまで改善することなので、それが終わったら基本この目的も果たされてはいるのですが、リリース可能かどうかを判断する材料としても評価結果は重要です。
また、多様なインプットに対してタスクをうまくできるか、用意した評価データセットに対してだけうまくできているだけでないか、いわゆる汎化性能を見るために同じ観点だがインプットを違うバリエーションにしたデータセットを用意してテストすることもあります。
モデルやアルゴリズムを切り替える時のリグレッション確認をする
これはソフトウェア開発における単体テストのような目的ですが、チューニング中もそうですし、リリースした後でもより速い/安い/精度が高いモデルが出て変えたいな〜となったり、改善のためにアルゴリズムから変えることはよくあることです。
その時に今まで守ってきた評価観点を満たせているかを確認するために評価を行います。この目的に対してはある程度評価が自動で行えること、その結果が時系列で見られて過去の結果と比較できること、が望ましいです。
ダイナミックに評価結果を使うことによって精度を改善する
これはオフライン評価でもオンライン評価でもない話なのですが「実行時に出力した結果に対して評価を行い、評価結果と理由をインプットに出力を改善する」という手法があります。当然こちらは人間がリクエスト毎に評価のために待ち構えることはできないため自動評価前提です。
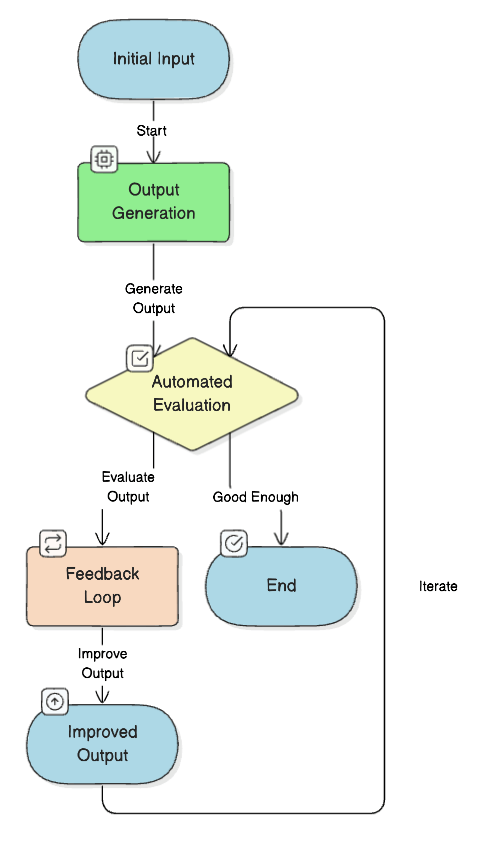
ただし最近出た論文だと少なくともError(コンテキストに存在しない情報生み出しちゃうとか)検知系の改善にはあまり有効な手段が見つかっていないこともあって使い所は注意が必要です。(お金も時間もかかるし)
オンライン評価
オンライン評価では実際のユーザにシステムを使ってもらう中でのLLMシステムの振る舞いを評価なり分析をしていきます。
これも"オンライン評価"と一口に言ってもいくつかの目的やHowがあります。
LLMのアウトプットに対してユーザからのフィードバックを得る
やはり社内だけの評価では全ての観点を網羅することは不可能です。なので実際のユーザに使われた上でのフィードバックは継続的にLLMのシステムの改善をしていく上で重要な鍵となってきます。
どんな形でフィードバックをもらうかは色々な形式があり、よく使う例としては Good/Bad の評価だったり

複数の結果を出してペアワイズでどちらがいいか判定してもらったり

テキストで入力してもらってフィードバックをもらうなど様々です。
実際の機能の使われ具合を分析する
ユーザーがLLMシステムをどのように利用しているかを分析することは、システム改善のための貴重な示唆を与えてくれます。アクセスログやイベントログなどを用いて、以下の様な分析を行うことが考えられます。
- 機能の利用状況: 機能がどれくらい利用されているのか
- ユーザーの行動パターン: ユーザーがどのような流れで機能を利用しているのか、どのような入力が多いのかを見るなど
- 問題点の発見: エラーの発生状況や、ユーザーが特定の箇所で離脱してしまう状況を分析することで、システムの改善点を見つける
これらの分析結果に基づいて、ユーザーインターフェースの改善や、LLMの出力内容の調整などを行うことができます。この辺りは機械学習絡まない機能開発とも強い差異はないのかもしれません。
以上、軽くですがオンライン評価について見てきました。
また、どの目的にせよA/Bテストを裏側では行い、モデルやアルゴリズムの違いを見ることも一つの分析のHowとしてあります。
LLMという機械学習コンポーネントを扱う手前フィードバックの取り方や、フィードバックや実際のロギングを活かした改善のワークフローなど固有の部分はあれど、大まかな考え方は通常のプロダクト開発における分析・機能改善とさして変わらないのではないかなと感じています。
おわりに
以上、LLMシステムを開発していく上で遭遇する様々な"評価"を見てきました。
私個人の所感としては「LLMのアウトプットに対して定義した品質に照らし合わせてスコアをつける or/and Yes/No判断する」以外の行為に対してあまり"評価"という言葉を使いたくないな〜と感じました。広義の言葉の意味で言うと間違いなく評価はしているのですが、その中でもオフライン評価/オンライン評価などの具体的なワードだったり、品質保証とかデータ分析などの他の語彙を目的に応じて使っていくとが雰囲気で話さなくなるのではないかと。
漠然と「評価が大事」くらいの解像度で進むのではなく、今携わっているLLMシステムで具体的に何が課題で、どんなところに評価が活躍するのかを考えていきたいですね。
それでは!
Discussion