LangSmithのPlaygroundが色々アップデートされていて便利
いつからかは分からないですがLangSmithのPlaygroundがものすごくアップデートされていました。19日にリデザインしたよ!という記事が出ていましたが、2-3週間前から触れたような...。
以前は単一のプロンプトを送れるくらいで、且つGeminiに長い間対応していなかったこともあり、あまりガッツリは使っていなかったのですが、久しぶりに使ってみると次のような機能が増えていて(前からあったかもだが)すごい!となりました。
- Outputのスキーマ定義やtool callingできるようになっとる
- 複数のプロンプト並列実行して比較
- fine-tuningのモデルも指定できる
- データセットを用いて実行できる
本記事ではこんな変更点を紹介した後に、「最近こんな感じで使ってみてるがどうでしょう」というワークフローを紹介していきます。
LangSmithのPlaygroundとPrompts
変更点などを話す前に、まずはLangSmithをそんなに触ったことがない方向けにPlaygroundと、組み合わせて使っていくと強力なPromptsについて解説していきます。
PlaygroundはLLM APIの実行をモデルやプロンプトなどをいじりながら試せる実行環境です。次の図のようにシステムプロンプトや最終的に送るプロンプト、プロンプトに埋め込むインプットなどを指定することができます。

モデル名の部分をクリックするとモデルを変えたり、temperatureなどの諸々のパラメータを変更することができます。

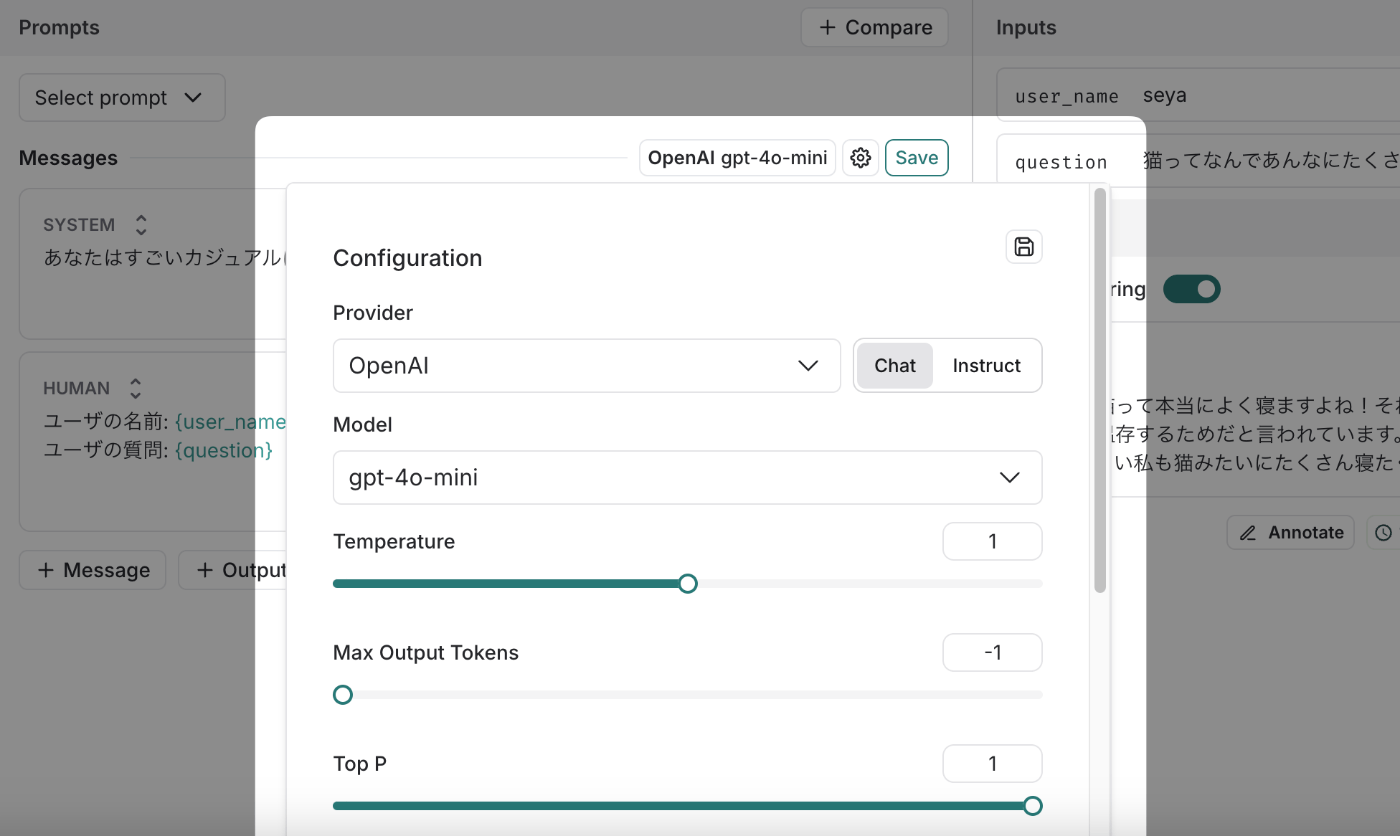
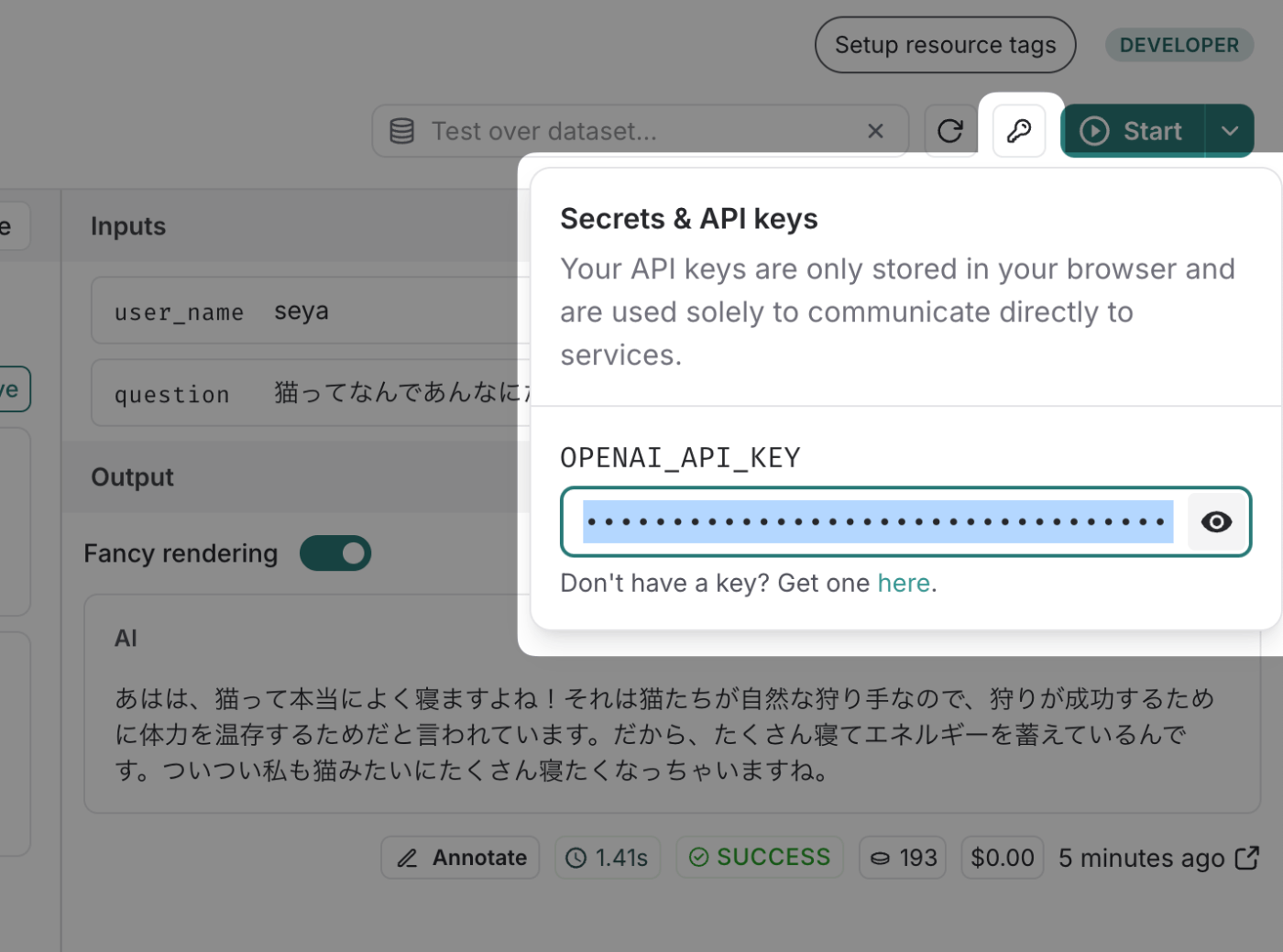
実行に際してはLangSmithがAPI費用費を賄ってくれる訳ではなく、自分のAPI Keyを右上の鍵アイコンのところから登録する必要があります。
次にPromptsです。Promptsは名前の通りプロンプトを保存・アップデートしていく、例えるとプロンプトのGitHubのようなイメージです。
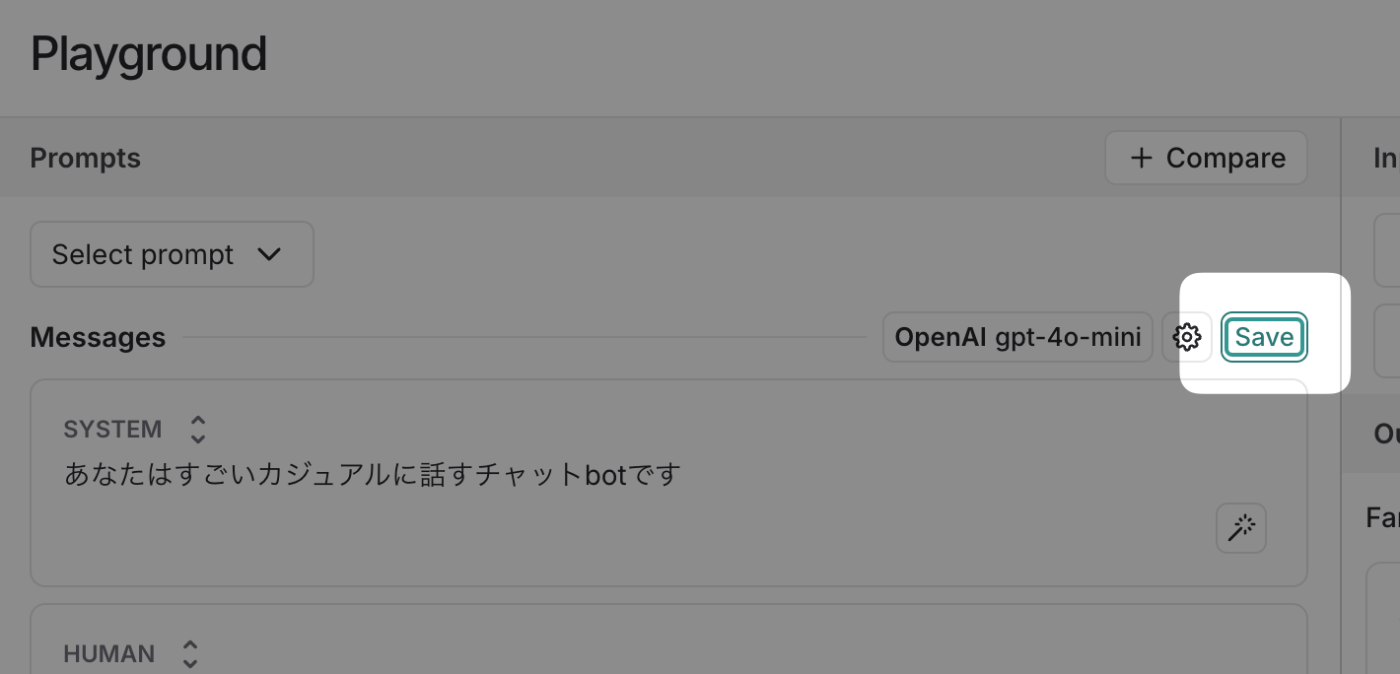
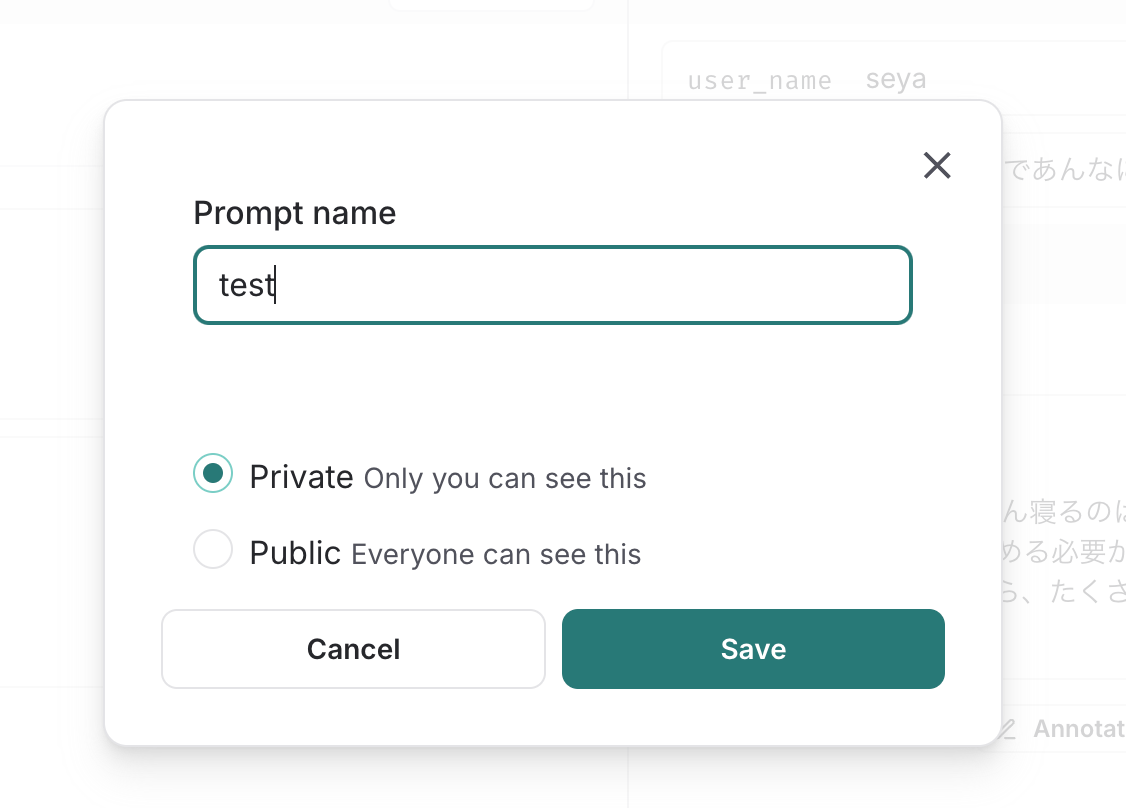
試しに先ほどのプロンプトを保存してみます。「Save」をクリックした後にプロンプト名を入力して更に「Save」を押下します。
するとこのようにプロンプトが保存されました。
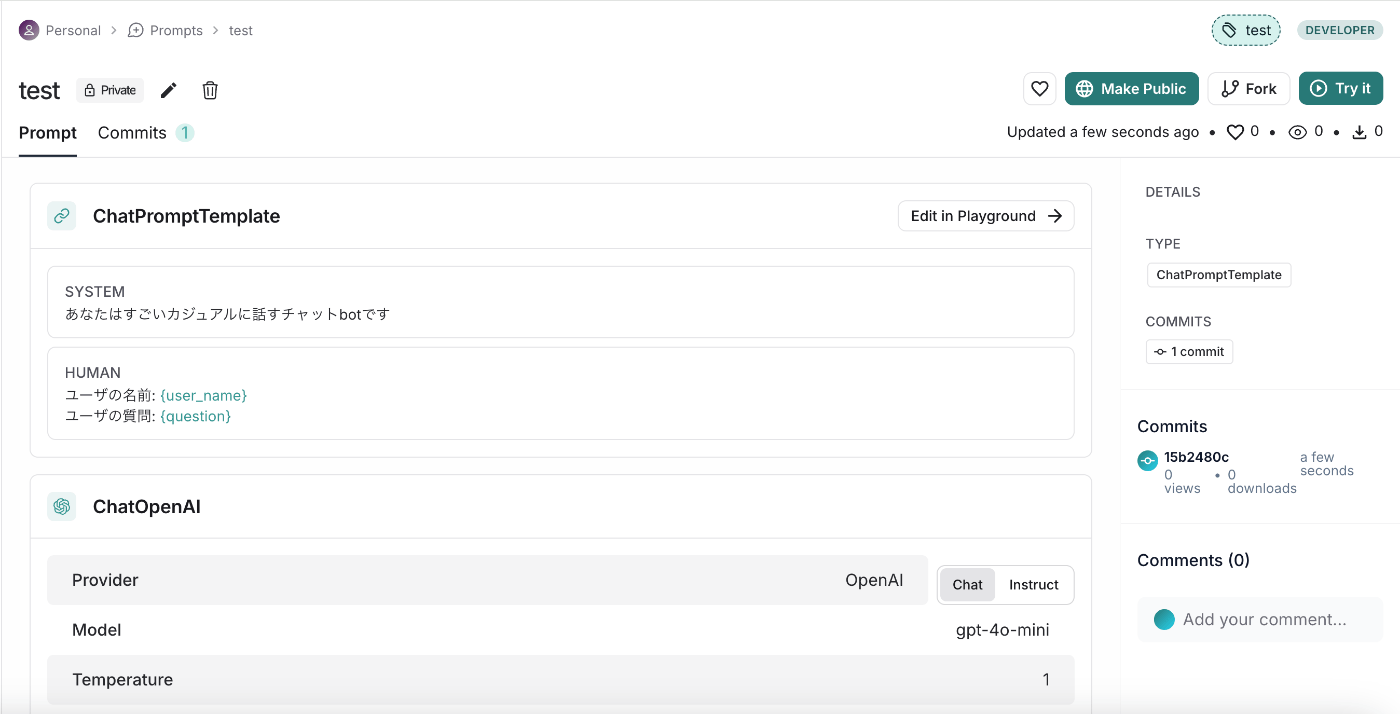
こちらはLangChainを使って次のようにimportすることができます。(LANGCHAIN_API_KEYが環境変数にセットされている必要があります。)
from langchain import hub
prompt = hub.pull("test")
こちらのPromptsには後述するようなOutputのスキーマやTool Calling、またはマルチターン会話も含まれますが、それらもPythonオブジェクトとしてちゃんと入ってきます。
例えばこんな感じの色々入れたプロンプトを作って上記のように pull をすると次のようなオブジェクトたちが取得できます。

input_variables = ['question', 'user_name']
input_types = {}
partial_variables = {}
metadata = {
'lc_hub_owner': '-',
'lc_hub_repo': 'everything',
'lc_hub_commit_hash': '0618090bd2fed2cac63a560c014f30c5c6af75d8f57e121c0b58409998736318'
}
messages = [
SystemMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=[],
input_types={},
partial_variables={},
template='あなたはすごいカジュアルに話すチャットbotです'
),
additional_kwargs={}
),
HumanMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=['user_name'],
input_types={},
partial_variables={},
template='ユーザの名前: {user_name}'
),
additional_kwargs={}
),
AIMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=[],
input_types={},
partial_variables={},
template='AIの返信'
),
additional_kwargs={}
),
HumanMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=['question'],
input_types={},
partial_variables={},
template='最終的な質問: {question}'
),
additional_kwargs={}
)
]
schema_ = {
'title': 'extract',
'description': "Extract information from the user's response.",
'type': 'object',
'properties': {
'correctness': {
'type': 'boolean',
'description': 'Is the submission correct, accurate, and factual?'
}
},
'required': ['correctness']
}
structured_output_kwargs = {}
その他にもコミットログを持ってバージョン管理もしてくれたり、Forkして別のプロンプトとして管理し始めることも可能です。
余談ですが、Prompts機能は従来はPrompt Hubと呼ばれるプロンプトシェアサービスみたいなものがあり(今もある)、その中にprivateなプロンプトを保存できる、というだけでちょっと独立したサービス感があったのですが、現在はPlaygroundとも相まってとても使い勝手が良くなったように感じます。
大まかなPlaygroundとPromptsの概要をお伝えしたので、次に具体の使い道としてすごい!と感じた箇所をあげていきます。
LangSmith Playgroundのアップデート、ここがすごい!
PlaygroundとPromptsの概要を確認したところで、最近増えた機能として何が素晴らしいと感じたかをご紹介していきます。
Outputのスキーマとかtool callingできる
Output Schemaをクリックすると次のようにどんなフォーマットでデータが返ってきて欲しいかを指定することができます。

すると結果がちゃんとそのフォーマット通りに返ってきました!

ただ、LangSmithというよりはOpenAIのStructured Outputなりの問題な気もしますが、フォーマット通りでなかったり生成内容がすごい残念になることもちょいちょいあります。それ込みで比較できるので大変ありがたいです。
Tool Calling も同様です。

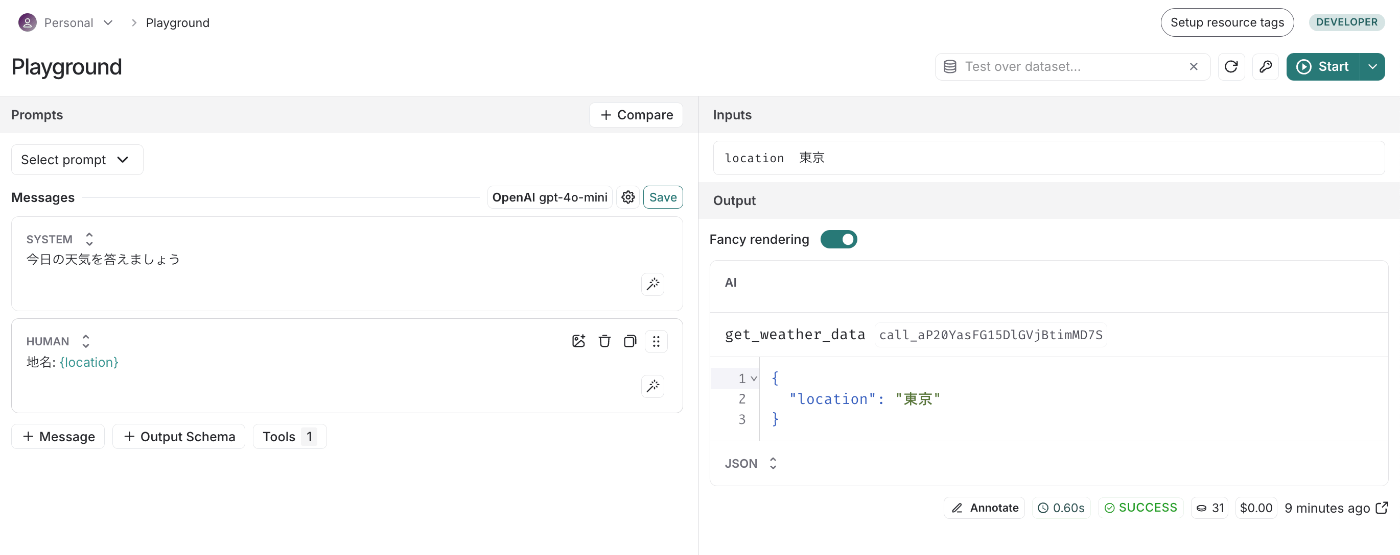
「description変えたらちゃんと呼んでくれるかな〜」みたいな調整もしやすいですね。
複数のプロンプト並列実行して比較
いっぱい並べられます。助かります。
最大個数はちょっと不明です。連打しまくったらアルファベットを使い果たして記号が名前につき始めました。少なくとも30個くらいは並列できるみたいなので困ることはないでしょう。

ここはもう一声! ページ遷移すると実験している設定全部消える
いっぱい並べられるのはいいのですが、Promptsに保存できるのは一つの設定のみです。複数の設定をいろいろ作って実験している最中に迂闊にも他のページに遷移すると全部消えます。(消えない時もある。再現条件不明。)
一応後述するデータセットと組み合わせて実行する機能を使うとExperimentsの方には記録は残るのですが、そこから同じPlaygroundの状態で再開できる訳ではないのでできれば復元できると嬉しい。頼む!もしくはExperimentの名前がもっと分かりやすい名前にして欲しい!
さらにもう一声! プロンプト全部の枠で同時に変更して欲しい
Playgroundではプロンプトの差分を見ることももちろんあるのですが、モデルであったり Structured Outputsのある/なし、temprature の値などプロンプト以外のものの差分も色々検証します。そんな折にプロンプトを変えたくなった時に一つ一つコピペで変えて周るのが...手間!
なんかうまい感じのUI思いついて実装いただきたいです。
データセットを用いて実行できる
実験を何度もしていると、いつも決まったインプットを入力していてめんどくさいな〜という気持ちになります。そんな時にデータセットを作って、それに対して実行する機能を活用すると便利です。
まずはプロンプトのインプットと同じ型を持ったデータセットを作ります。ちなみに、このデータセットはそのまま後の評価データセットとして育てていっても良いですが、とりあえず「作業効率化のための暫定データセット」くらいの軽い気持ちで作る感覚でいいと思います。

次にPlaygroundに戻って作ったデータセットを指定します。

するとデータセットにある全てのExampleに対して実行してくれました。神!

ちなみにデータセットを対象に実行した場合は行毎、つまりは上図で言うと「プロンプトA、プロンプトB、プロンプトC」毎にExperimentが作られます。これらを同時に選択すると後かでも比較して見ることができます。


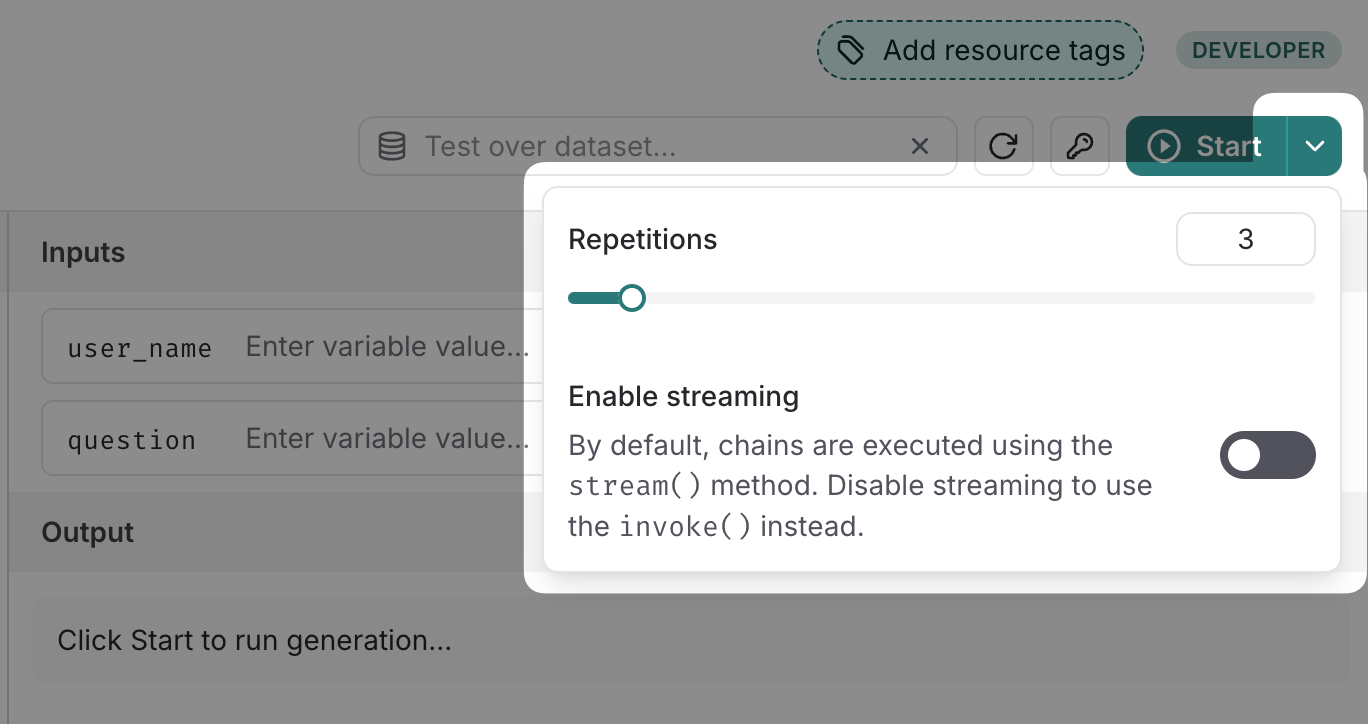
繰り返し実行できる
地味なのですがStartの横のプルダウンから何回繰り返して実行するかを選べます。同じ条件下でも何度か出力したいことはよくあるので便利!
ワークフロー
以上、ものすごく良くなったLangSmithのPlaygroundなのですが、一例として私が最近どういう風に使っているかをご紹介します。
まず前提として、Playgroundが必要なのはLLMでなんとかしたい機能が新しく出た際の初期フェーズのみです。ある程度実現したいことも分かってきて、評価データセットを構築していく段にはそれを軸に手元で評価用のスクリプトとか用意するようになると思うので使う機会はなくなります。(Evaluatorも全部LangSmithで完結させるならその限りではない)
要求が発生した際は、そもそもどんなアウトプットが望ましいか、どんなインプットがあるか手探りの状態です。私は個人的にこの時期を ad hoc 実験フェーズと呼んでいるのですが、まずはとにかく色んな変数で試しつつ、色々実行結果も貯めて評価基準もこんな感じかな〜と探っていくのがこの時期です。
この時期から素早く実験を重ねつつも、後々に使えるデータセットや評価の糧となるものを作り始められるのがPlaygroundの強みになるのではないかなと思います。
なので、ワークフローとしては次のことができると良いのではないかなと考えています。
- まずPlaygroundで色々試す
- Playgroundでの実行結果に対してアノテーション(メモ)をしていき、後々評価基準を考える参考にしたり、データセットやFew-shotsなどに再利用できる形にする
アノテーションはPlaygroundの実行結果から次のように操作します。
- Expand detailed view
- 右上の鉛筆マークのAnnotate
- スコアをつける&アノテーション内容の入力

"アノテーション"とカッコつけて呼んではいますが、実態としてはメモをアノテーション機能使った残しているだけです。スコアも完全に雰囲気でつけていて、後から良かった/悪かったがなんとな〜く分かればいいかなくらいの気持ちです。
後から一覧として見たかったりデータセットを作りたくなった際には、まずはTracing projectsの中のPlaygroundを選びます。すると、右のフィルターのFeedbackにつけたスコアなどのカテゴリが表示されているので、こちらをチェックすることでアノテーションしたものだけを絞り込めます。ちなみにnoteは「アノテーションがついているもの」という意味です。


注意点としてデータセットを対象に実行している時はPlayrgroundのTracingには流れません!ではどこに行けばいいのかというとExperimentの方に行く必要があります。正直これは全部Playgroundの方に流して欲しいなぁ。

おわりに
以上新しくなったPlaygroundを見てきました。
前までは正直そんなにヘビーユースはしないかな〜と思ってたのですが、これらの諸々のアップデートが入った今、私は最近毎日触るようになってきています。
私と同じくしばらく触ってなかった〜という方もいらっしゃると思うので、LangSmithユーザの方はぜひご活用してみてください!
Discussion