AIフレンドリーなアーキテクチャをAIに訊いて採用してみた 【FHDアーキテクチャ】
CursorやWindsurfのAI用のIDE開発していると無限ループエラーやケアレスミス(ブラケットで閉じられていないだけみたいなやつ)のような簡単なエラーが解消されずに面倒だなと思うことはないでしょうか。
自分の場合は同時に複数のプロジェクトを回していると自律神経が不調となり軽い頭痛に見舞われ流ことがあり身体的にもしんどいです!
もちろんプロンプトの詳細度と具体性を高めればコード生成AIガチャに成功しやすくなるものの何度もプロンプトを長文で入力すると頭がさらに疲れてくるし開発の時間もかかってしまいます。そのため雑なプロンプトを投げ続けるためにはそもそもAIがエラーを吐きづらい仕組み、すなわちディレクトリ構造そのものをSSR排出率の高めの優良ガチャ設計にする必要があります。
そこでAIフレンドリーなアーキテクチャを新しい個人プロジェクトを立ち上げた際にAIから提案してもらうことにしました。
その名もFHD Architecture (Feature-Hexagonal-Domain Architecture)
ふ、フィーチャーヘキサゴナルドメインアーキテクチャー??
その名も FHDアーキテクチャです。Gemini 2.5 proと会話して生み出された呪文のようなアーキテクチャ名を提案してもらったのですがとりあえず「AIはんがそう言うんなら採用や!」のエイヤでネーミングと設計もろとも採用してみました。
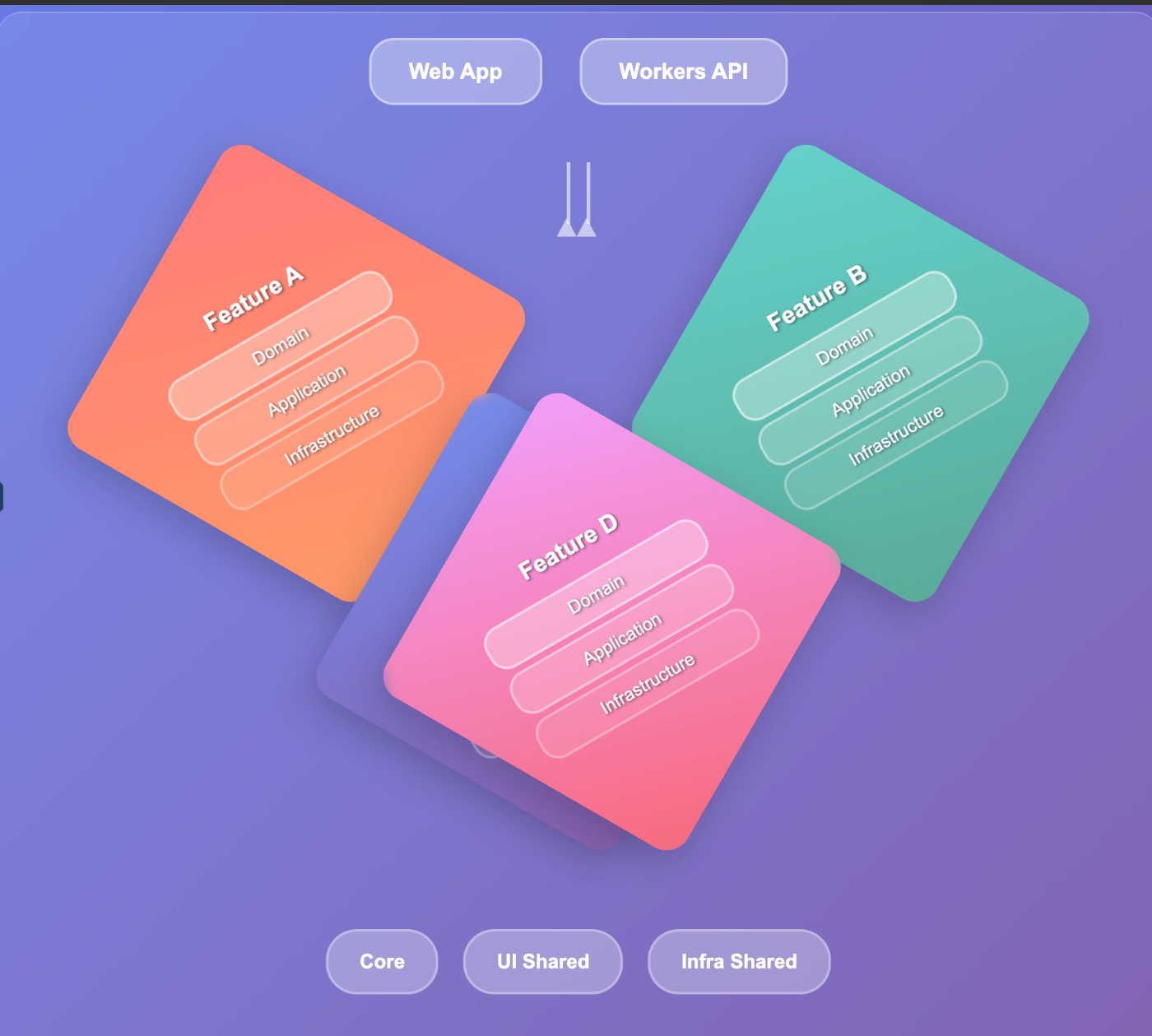
Claudeに図解説してもらったところ上記のような設計になります。Feature Cが埋もれてしまっているのはおいておいて、機能ごとにドメイン層、アプリケーション層、インフラストラクチャー層のクリーンアーキテクチャ要素を突っ込んだような設計です。
FHDアーキテクチャを提案するにあたり各アーキテクチャをAIに比較検討してもらった
HatakeHealth(仮名)は開発中のサービス名です。以下Gemini 2.5 pro出力の内容です
比較検討の前提
- AIコーディングツールの進化: 現在のAIコーディングツールは、局所的なコード生成やリファクタリングには長けていますが、システム全体のアーキテクチャを理解し、一貫性のある設計に基づいてコードを生成する能力はまだ発展途上です。したがって、AIが「迷わない」ように、明確な境界とパターンを提供することが重要です。
- 開発者の役割: AIはアシスタントであり、最終的な設計判断や品質担保は開発者の責任です。開発者がAIの提案を理解し、適切にレビュー・修正できるような構造が求められます。
- HatakeHealthの特性: 衛星データ処理、AIモデル連携、Cloudflareエコシステムといった技術要素、そして将来的なモバイル展開の可能性を考慮します。
各アーキテクチャの比較と考察
| アーキテクチャ | AIエラー低減 | 保守性・可読性 | 開発体験 (人間 & AI) | HatakeHealthへの適合性 | 特記事項 |
|---|---|---|---|---|---|
| モジュラー・フィーチャー・アーキテクチャ | ◎ (明確な機能境界、フィーチャー内レイヤー) | ◎ (機能単位で独立、レイヤーで関心分離) | ◎ (機能中心で直感的、AIもパターン学習容易) | ◎ (機能追加が容易、コアロジック共有、衛星データ処理やAIモデル連携をフィーチャーとして分離しやすい) | バランスが良い。クリーンアーキテクチャの利点を取り込みつつ、より実践的でAIフレンドリー。 |
| プラグイン型アーキテクチャ | △ (コアとプラグインの境界は明確だが、プラグイン内部の複雑性による) | ○ (プラグイン単位での管理、インターフェース依存) | ○ (AIツールの追加/変更は容易だが、コアシステムの設計が重要) | △ (アプリケーションの主要機能を「プラグイン」として扱うのは不自然。AI「ツール」をプラグインとして統合する考え方は有用だが、アプリケーション全体の構造としては不向き) | 主に「ツール」としてのAI(例: IDEのコード生成支援機能)をシステムに組み込む場合に有効。アプリケーションのビジネスロジックをプラグインとして分割するのは、依存関係管理が複雑になる可能性。 |
| Vertical Slice Architecture | ◎ (機能コンテキストが明確、AIの集中力向上) | ○ (機能ごとの独立性は高いが、共通ロジックの重複リスク) | ◎ (機能単位で完結、開発しやすい) | ○ (機能単位での開発効率は高い。しかし、衛星データ処理のような横断的なコア機能や、ドメインエンティティの共有をどう扱うかが課題。純粋なVSではpackagesのような共有層の概念が薄い) |
モジュラー・フィーチャーと類似する点が多いが、よりUIからDBまでを一体として捉える傾向。モノレポで共有パッケージを活用すれば、VSの良さを取り入れつつ欠点を補える。 |
| Hexagonal Architecture (Ports & Adapters) | ○ (ビジネスロジックとインフラの分離が明確) | ◎ (コアロジックの独立性、アダプタの差し替え容易) | ○ (概念理解が必要だが、一度理解すれば明確) | ◎ (衛星データAPI、Vertex AI連携、D1といったインフラ部分をアダプタとして分離するのに非常に適している。ドメインロジックの保護に有効) | モジュラー・フィーチャーやVertical Sliceの「ドメイン層」「インフラ層」をより厳密にしたものと捉えられる。単独で全体の構造を規定するより、他のアーキテクチャの構成要素として強力。 |
| AI-Driven Fitness Functions | ○ (設計原則の自動チェックによる間接的効果) | ○ (品質維持に貢献) | △ (設定や運用にコスト) | △ (アーキテクチャそのものではなく、品質維持の仕組み。どのアーキテクチャでも導入可能) | 設計パターンを強制したり、アンチパターンを検出するのに役立つ。AIが生成したコードが規約違反していないかをチェックするのに有効。 |
| Atomic Composable Design | △ (UIコンポーネントレベルの話) | ○ (UIの再利用性と一貫性) | ○ (UI開発効率向上) | △ (主にフロントエンドUIの設計思想。バックエンドやビジネスロジックには直接影響しない) |
packages/ui-shared の設計で参考にすべき考え方。AIがUIコンポーネントの粒度や再利用性を理解しやすくなる。 |
検討と推奨
まず、「プラグイン型アーキテクチャ」についてですが、提示された例は「AIコーディングツールそのもの」をアプリケーションのプラグインとして扱うようなニュアンスが強いです。これはIDEの拡張機能(例: Copilot)のアーキテクチャとしては理解できますが、HatakeHealthのようなサービス全体のアーキテクチャとして採用するのは、責務の分割が不自然になる可能性があります。ビジネス機能を「プラグイン」として実装するのは、マイクロサービスに近い考え方ですが、それならば最初からマイクロサービスアーキテクチャを検討する方が自然です。
HatakeHealthプロジェクトへの推奨は、依然として「モジュラー・フィーチャー・アーキテクチャ」をベースとしつつ、そこに「Hexagonal Architecture」の思想を強く取り入れ、さらに「Vertical Slice」の利点を意識することです。
具体的には以下のようになります。
-
基本構造: モジュラー・フィーチャー・アーキテクチャ
-
packages/features/[feature_name]を基本単位とします。 - 各フィーチャー内は
application,domain,infrastructure(これがHexagonalのAdapterに相当)というレイヤー構造を持ちます。 - フロントエンド (
apps/web) のページやコンポーネントも、可能な限りこれらのフィーチャーに対応するように構成します(Vertical Slice的な発想)。
-
-
Hexagonal Architectureの適用:
-
packages/features/[feature_name]/domain: ここがヘキサゴンの「内部(コアビジネスロジック)」。純粋なTypeScript/JavaScriptで記述され、外部ライブラリやフレームワークへの依存を最小限にします。AIが最も安全にコードを生成・変更できる聖域です。 -
packages/features/[feature_name]/domainで定義されるリポジトリインターフェースやサービスインターフェースが「ポート」の役割を果たします。 -
packages/features/[feature_name]/infrastructure: ここが「アダプター」。Cloudflare D1/KV、Google Earth Engine API、Vertex AI、Clerk SDKなどとの具体的な連携コードを配置します。AIが外部サービスとの連携コードを生成する際の主な場所です。
-
-
Vertical Sliceの意識:
- ある機能(例: 「新しい畑を登録する」)を実装する場合、
apps/web/app/(features)/hatake-management/create/page.tsx(UI)、apps/web/app/(features)/hatake-management/create/_actions.ts(Server Action)、packages/features/hatake-management/application/createHatake.usecase.ts(ユースケース)、packages/features/hatake-management/domain/hatake.entity.ts(エンティティ)、packages/features/hatake-management/infrastructure/persistence/d1Hatake.repository.ts(DBアクセス) といったように、関連するコードが機能の文脈でグループ化されることを意識します。 - これにより、開発者もAIも、特定の機能開発時に必要なコンテキストが限定され、作業しやすくなります。
- ある機能(例: 「新しい畑を登録する」)を実装する場合、
このハイブリッドアプローチのAIコーディングとの親和性:
-
AIエラー低減:
- フィーチャーとレイヤーによる明確な境界が、AIの作業範囲を限定します。
- Hexagonalの原則により、ドメインロジックがインフラストラクチャの変更(例: DBの変更、AIモデルAPIの変更)から保護され、AIによる意図しない副作用を減らします。
- インターフェース(ポート)に依存したコーディングをAIに促すことで、AIが生成するコードの結合度を下げ、テスト容易性を高めます。
-
保守性と可読性:
- 機能ごとにコードがまとまっているため、特定の機能の修正や理解が容易です。
- ドメインロジックとインフラロジックが明確に分離されているため、コードの役割が明確になります。
- AIが生成したコードも、どのレイヤーに属し、どのような責務を持つべきかが明確なため、レビューしやすくなります。
-
開発体験:
- 開発者は特定の機能に集中して作業できます。
- AIは、既存のフィーチャーの構造や、レイヤー間の連携パターンを学習し、新しい機能やコードを提案しやすくなります。
- 例えば、「
hatake-managementフィーチャーに新しいユースケースを追加して、D1リポジトリを使って永続化する」といった指示をAIが理解しやすくなります。
実践ガイドラインの取り込み:
提示された「実践ガイドライン」は、このハイブリッドアプローチと非常に相性が良いです。
-
AIコード生成ルール:
-
1ファイル200行以内: 各ユースケース、アダプター、エンティティなどを小さく保つことで自然と達成しやすくなります。 -
#ai-generatedタグ: AIが生成した箇所を明確にするのは良い習慣です。
-
-
コンテキスト管理:
- モノレポツール (Turborepo/Nx) を使って、特定のフィーチャーやパッケージのみをビルド/テスト/リンティング対象とすることで、AIツールに渡すコンテキストを自然と絞り込めます。
-
パターン検出:
- 各フィーチャー内でのレイヤー構造や命名規則の一貫性を保つことで、AIがパターンを検出しやすくなります。
- Zencoderのようなツールも補助的に活用できます。
まとめ:
「モジュラー・フィーチャー・アーキテクチャを基盤とし、Hexagonal Architectureの原則(特にドメインとインフラの分離)を各フィーチャー内に適用し、Vertical Sliceの視点(機能単位での関心の集中)で開発を進める」というアプローチが、HatakeHealthプロジェクトにおいてAIコーディングとの親和性、保守性・可読性、開発体験のバランスが最も良いと考えられます。
このアプローチは、AIが生成するコードのエラーを局所化し、ドメインロジックを保護しつつ、開発者がAIの提案を理解し、効果的に活用するための強固な基盤を提供します。また、Cloudflareの各サービスや外部AI APIとの連携も、アダプターとして綺麗に分離・管理できるでしょう。
実際に開発していて感じたこと
MVP機能を概ね実装を終えた段階としての感想ですが無限エラーループは比較的に減った印象です。また、ファイルが長すぎることで生じるエラーも減りました。しかし放っておくと1ファイルあたり1000行を余裕で超えてきたりするものもあるため手放しではできないです。
ファイルの行数が長いということはコンテキストが冗長化してしまうためAIの解答精度を高める上では悪手です。今回はスタイリングのファイルを切り分けなかったことが行数が増えやすい要因となってしまいました。
もちろん長文ファイルを防ぐべくFHDアーキテクチャ専用のルールをIDE側で設定しているのですがルールのコンテクストを考慮してくれている場合とそうでない場合とがありました。アニメキャラの設定を常時AIレスポンスに取り込むようルールを設定していますがたまに敬語に戻ってしまうことがあり「コンテキストが超えちゃったー」というシチュエーションが何度かあるためそれがFHDアーキテクチャ側のルールでも生じていると考えられるためです。
他、Application層がInfrastructure層のDTOに直接依存している箇所も生じたのでルールをもう少し工夫する必要がありそうです。
とはいえ将来的にReactNativeでアプリ化する拡張性を残せている点でFHDアーキテクチャの恩恵を受けていると思います。
実際のディレクトリ構成(現在は変更箇所あり)

技術スタックや要件定義書などを踏まえてFHDアーキテクチャを生成してもらいました。
packagesディレクトリ以下にビジネスロジックが格納されています。
hatakehealth/ (モノレポルート: Turborepo or Nx)
├── apps/ # デプロイ可能なアプリケーション群
│ ├── web/ # Next.js フロントエンド (Cloudflare Pages)
│ │ ├── app/
│ │ │ ├── (auth)/ # 認証機能 (UI)
│ │ │ │ ├── sign-in/
│ │ │ │ │ ├── page.tsx
│ │ │ │ │ └── _components/ # この認証フロー専用のUIコンポーネント
│ │ │ │ └── callback/
│ │ │ ├── (features)/ # 主要機能 (UI)
│ │ │ │ ├── dashboard/
│ │ │ │ │ ├── page.tsx
│ │ │ │ │ ├── _components/ # dashboard機能専用のUIコンポーネント
│ │ │ │ │ └── _actions.ts
│ │ │ │ ├── hatake-management/
│ │ │ │ │ ├── [hatakeId]/
│ │ │ │ │ │ ├── page.tsx
│ │ │ │ │ │ └── _components/
│ │ │ │ │ ├── create/
│ │ │ │ │ │ ├── page.tsx
│ │ │ │ │ │ └── _components/
│ │ │ │ │ └── _actions.ts
│ │ │ │ └── satellite-analysis/
│ │ │ │ ├── request/
│ │ │ │ │ ├── page.tsx
│ │ │ │ │ └── _components/
│ │ │ │ ├── results/[analysisId]/
│ │ │ │ │ ├── page.tsx
│ │ │ │ │ └── _components/
│ │ │ │ └── _actions.ts
│ │ │ ├── api/ # Next.js API Routes (限定的利用)
│ │ │ │ └── clerk-webhook/
│ │ │ │ └── route.ts
│ │ │ └── layout.tsx
│ │ │ └── global.css
│ │ ├── components/ # ★ Next.jsアプリケーション共通UIコンポーネント群
│ │ │ ├── ui/ # 基本的なUIプリミティブ (Button, Input, Card, Modalなど)
│ │ │ │ └── Button.tsx
│ │ │ ├── layout/ # アプリケーション共通レイアウト関連 (Header, Footer, Sidebarなど)
│ │ │ │ └── AppHeader.tsx
│ │ │ └── forms/ # 共通フォーム要素、フォーム関連フックなど
│ │ │ └── ControlledInput.tsx
│ │ ├── lib/ # Next.jsアプリケーション固有のユーティリティ、フックなど
│ │ │ ├── hooks/
│ │ │ │ └── useCurrentUser.ts
│ │ │ └── utils.ts
│ │ ├── public/
│ │ ├── next.config.js
│ │ ├── tsconfig.json
│ │ └── package.json
│ └── workers-api/ # Cloudflare Workers バックエンドAPI
│ ├── src/
│ │ ├── db/ # ★ Drizzle ORM 関連
│ │ │ ├── schema/ # Drizzle スキーマ定義 (例: users.ts, hatakes.ts)
│ │ │ │ └── hatakes.schema.ts
│ │ │ ├── migrations/ # Drizzle マイグレーションファイル
│ │ │ │ └── 0000_initial.sql
│ │ │ └── index.ts # Drizzleクライアントインスタンス化、DB接続関数
│ │ ├── entrypoints/ # APIエンドポイント定義 (Honoルーター等)
│ │ │ ├── auth.routes.ts
│ │ │ ├── hatake.routes.ts
│ │ │ ├── analysis.routes.ts
│ │ │ └── index.ts
│ │ ├── middleware/
│ │ │ └── auth.middleware.ts
│ │ ├── index.ts # Workerエントリーポイント
│ │ └── wrangler.toml
│ ├── drizzle.config.ts # ★ Drizzle Kit 設定ファイル
│ ├── tsconfig.json
│ └── package.json
├── packages/ # 共有コード、ビジネスロジック、ライブラリ群
│ ├── features/ # ビジネスロジックのコア
│ │ ├── auth/
│ │ │ ├── application/
│ │ │ │ └── verifyClerkToken.usecase.ts
│ │ │ ├── domain/
│ │ │ │ ├── session.entity.ts
│ │ │ │ └── iSession.repository.ts
│ │ │ └── infrastructure/
│ │ │ ├── clerk.adapter.ts
│ │ │ └── kvSession.repository.ts
│ │ ├── hatake-management/
│ │ │ ├── application/
│ │ │ │ ├── createHatake.usecase.ts
│ │ │ │ ├── getHatakeById.usecase.ts
│ │ │ │ └── listUserHatakes.usecase.ts
│ │ │ ├── domain/
│ │ │ │ ├── hatake.entity.ts
│ │ │ │ ├── hatake.value-objects.ts
│ │ │ │ └── iHatake.repository.ts # Port
│ │ │ └── infrastructure/
│ │ │ ├── persistence/
│ │ │ │ └── drizzleHatake.repository.ts # ★ Adapter (Drizzle ORM を使用)
│ │ │ └── dto/
│ │ │ └── hatake.dto.ts
│ │ ├── satellite-analysis/
│ │ │ ├── application/
│ │ │ │ ├── requestNewAnalysis.usecase.ts
│ │ │ │ └── getAnalysisResult.usecase.ts
│ │ │ ├── domain/
│ │ │ │ ├── analysisReport.entity.ts
│ │ │ │ ├── analysisRequest.value-objects.ts
│ │ │ │ ├── iAnalysisReport.repository.ts # Port
│ │ │ │ ├── iSatelliteDataProvider.ts
│ │ │ │ └── iAIModelOrchestrator.ts
│ │ │ └── infrastructure/
│ │ │ ├── persistence/
│ │ │ │ └── drizzleAnalysisReport.repository.ts # ★ Adapter (Drizzle ORM を使用)
│ │ │ ├── providers/
│ │ │ │ └── googleEarthEngine.adapter.ts
│ │ │ ├── services/
│ │ │ │ └── vertexAI.adapter.ts
│ │ │ └── dto/
│ │ │ └── analysis.dto.ts
│ ├── core/ # アプリケーション横断的なコア要素
│ │ ├── config/
│ │ │ └── env.ts
│ │ ├── errors/
│ │ │ └── AppError.ts
│ │ ├── types/ # グローバルな型定義 (Drizzleの型もここに集約・エクスポートする可能性あり)
│ │ │ ├── common.ts
│ │ │ └── db.types.ts # ★ Drizzleから生成される型や、それを拡張した型など
│ │ └── utils/
│ └── infra-shared/ # 共有インフラストラクチャクライアント/設定 (Loggerなど)
│ └── logger.ts
├── tsconfig.base.json
├── .eslintrc.js
├── prettier.config.js
└── package.json
そもそもアーキテクチャ(ディレクトリ構成)におけるコードAI生成のボトルネックとはなんだったのか
1. コンテキスト理解の困難
- AIが「どこに何を置くべきか」を判断するのに時間がかかる
- 抽象的な層名(
Services,Handlers,Managers)で配置先を迷う - ファイル名から責務が推測しにくい
2. 依存関係の複雑性
- 循環依存のリスクをAIが見落とす
- 依存の方向が複数存在し、AIが混乱する
- インターフェースと実装の対応関係が不明確
3. 機能境界の曖昧さ
- 新機能追加時に複数レイヤーを跨ぐ必要がある
- 関連コードが分散し、AIのコンテキスト把握が困難
- どの機能に属するコードか判断が困難
4. 命名規則の不統一
- ファイル名から責務が推測できない
- 同じ概念に対する異なる命名(
ServicevsHandlervsManager) - AIが一貫性のない命名を生成
5. レイヤー間の責務重複
-
ApplicationServicevsDomainServiceの区別が困難 -
ControllervsHandlerの使い分けが不明確 - AIが適切な層を選択できない
6. 外部依存の混入
- ドメインロジックに技術的詳細が混在
- AIが純粋なビジネスロジックを生成しにくい
- テスタビリティが低い
7. 検索・参照の困難
- 関連ファイルが散在し、AIが既存コードを参照しにくい
- 機能追加時の影響範囲が不明確
- 既存コードの再利用を見落とす
FHDアーキテクチャによるボトルネックの解消したと思われる点(Cursorユースケース)
Cursorでの実際の動作改善
1. コンテキスト理解の高速化のイメージ
# 従来アーキテクチャでのCursor
User: "ユーザー作成機能を追加して"
Cursor: "どこに配置しますか?Controllers? Services? どのレイヤーですか?"
→ 🐌 判断が挟まれる
# FHDアーキテクチャでのCursor
User: "ユーザー作成機能を追加して"
Cursor: "packages/features/user-management/ に作成します"
→ ⚡ 即座に判断しやすい
2. 明確な配置ルール
// Cursorが迷わず生成
packages/features/user-management/
├── domain/
│ ├── user.entity.ts // ← Cursorが確信を持って配置
│ └── ports/user.repository.ts // ← インターフェース自動生成
├── application/
│ └── createUser.usecase.ts // ← .usecase.ts で役割明確
└── infrastructure/
└── user.repository.impl.ts // ← .impl.ts で実装と判断
3. 依存関係の自動修正
// Cursorの自動エラー検知と修正提案
// ❌ domain層でのフレームワーク依存を即座に検知
import { Request } from 'express'; // in domain/user.entity.ts
// Cursorの即座の修正提案:
// "Domain層ではフレームワーク依存は禁止です。
// infrastructure層に移動し、ポートを使用してください"
4. 機能追加の一貫性
# Cursorでの新機能追加フロー
User: "通知機能を追加"
Cursor:
1. packages/features/notification/ を作成
2. domain/notification.entity.ts を生成 (純粋ロジック)
3. application/sendNotification.usecase.ts を生成 (オーケストレーション)
4. infrastructure/email.adapter.ts を生成 (外部連携)
5. 既存のapps/web から usecase を呼び出すコード生成
→ 一貫した構造で生成していける
5. 型安全なコード生成
// Cursorが自動で型を推論・生成
// 1. domain でポート定義
export interface INotificationRepository {
send(notification: Notification): Promise<void>;
}
// 2. Cursorが infrastructure で実装を自動生成
export class EmailNotificationRepository implements INotificationRepository {
async send(notification: Notification): Promise<void> {
// 実装をCursorが自動生成
}
}
// 3. application での依存注入も自動
export class SendNotificationUseCase {
constructor(
private readonly notificationRepo: INotificationRepository // ← 自動注入
) {}
}
6. エラーパターンの予測と修正
// Cursorが検知する典型的エラーパターン
// ❌ パターン1: 逆方向依存
// packages/features/user/domain/user.entity.ts
import { CreateUserUseCase } from '../application/createUser.usecase';
// Cursorの即座の警告とFix:
// "Domain → Application の依存は禁止です。依存を逆転させてください"
// ✅ Cursorの自動修正
// application/createUser.usecase.ts で domain を import
7. リファクタリング支援の高精度化
# ユーザーリクエスト
User: "User機能をProfile機能に分割したい"
# Cursorの自動提案と実行
Cursor:
1. packages/features/user/ を分析
2. Profile関連のコードを特定
3. packages/features/profile/ を新規作成
4. 関連コードを適切に移動
5. 依存関係を自動修正
6. import文を一括更新
8. 既存コードの再利用促進
// Cursorが既存機能を発見・再利用
User: "商品の通知機能を追加"
Cursor:
// 既存の packages/features/notification/ を発見
// "既存の通知機能を再利用しますか?"
// → SendNotificationUseCase を products機能から呼び出すコード生成
FHDがいかにAIフレンドリーなのかClaude4さんに訊いてみる
より包括的なAIパフォーマンス比較を作成します。検索結果から得られた情報も含めて、6つの主要アーキテクチャパターンを比較分析します。
📊 拡張版AIパフォーマンス比較表
| アーキテクチャ | コード生成速度 | エラー検知精度 | リファクタリング提案 | 新機能追加支援 | 学習コスト | コンテキスト理解 | 総合AIフレンドリー度 |
|---|---|---|---|---|---|---|---|
| FHD Architecture | ⚡⚡⚡⚡⚡ | 🎯🎯🎯🎯🎯 | 🔧🔧🔧🔧🔧 | 🚀🚀🚀🚀🚀 | 📚📚 | 🧠🧠🧠🧠🧠 | ★★★★★ |
| Vertical Slice | ⚡⚡⚡⚡ | 🎯🎯🎯🎯 | 🔧🔧🔧🔧 | 🚀🚀🚀🚀🚀 | 📚📚 | 🧠🧠🧠🧠 | ★★★★☆ |
| Hexagonal | ⚡⚡⚡ | 🎯🎯🎯🎯 | 🔧🔧🔧 | 🚀🚀🚀 | 📚📚📚 | 🧠🧠🧠 | ★★★☆☆ |
| Feature Modular | ⚡⚡⚡⚡ | 🎯🎯🎯 | 🔧🔧🔧🔧 | 🚀🚀🚀🚀 | 📚📚📚 | 🧠🧠🧠🧠 | ★★★★☆ |
| Clean Architecture | ⚡⚡⚡ | 🎯🎯🎯 | 🔧🔧🔧 | 🚀🚀🚀 | 📚📚📚📚 | 🧠🧠 | ★★★☆☆ |
| Onion Architecture | ⚡⚡⚡ | 🎯🎯 | 🔧🔧🔧 | 🚀🚀 | 📚📚📚 | 🧠🧠 | ★★☆☆☆ |
🔍 各アーキテクチャの詳細分析
1. FHD Architecture ⭐ 最高AIフレンドリー
packages/features/user-management/
├── domain/user.entity.ts # 🎯 AIが迷わない配置
├── application/createUser.usecase.ts # 🎯 明確な命名規則
└── infrastructure/user.repository.ts # 🎯 依存方向が明確
AIフレンドリー要因:
- ✅ ヘキサゴナル + フィーチャー + VSAの最良の組み合わせ
- ✅ 構造的制約がAIの「迷い」を排除
- ✅ ルールベース開発でAIが高精度コード生成可能
2. Vertical Slice Architecture ⭐ 高AIフレンドリー
Vertical Slice Architectureは技術的層ではなく機能を中心にシステムを組織化し、機能追加時に複数の層を触る必要性を解決します。
src/features/
├── CreateUser/
│ ├── CreateUser.cs # すべてがここに
│ ├── CreateUserValidator.cs
│ └── CreateUserHandler.cs
AIパフォーマンス:
- ✅ 機能単位のコンテキスト集約でAIの注意力が集中
- ✅ レイヤー跨ぎが少なく、AIが一気通貫で実装可能
- ⚠️ 共通コードの重複をAIが見落としやすい
3. Hexagonal Architecture ⭐ 中程度AIフレンドリー
src/
├── domain/
├── ports/ # インターフェース定義
├── adapters/ # 実装
└── application/
AIパフォーマンス:
- ✅ ポート・アダプターパターンでAIが型安全コード生成
- ⚠️ ポートとアダプターの対応関係をAIが混同しやすい
- ⚠️ 単一の大きなヘキサゴンで機能境界が曖昧
4. Feature Modular Architecture ⭐ 高AIフレンドリー
modules/
├── user-management/
├── billing/
└── notifications/
AIパフォーマンス:
- ✅ モジュール境界が明確でAIが機能追加しやすい
- ✅ モジュラー設計により、AIモデルとビジネスロジックを分離
- ⚠️ モジュール間の依存関係管理が複雑
5. Clean Architecture ⭐ 低-中程度AIフレンドリー
src/
├── entities/ # ビジネスルール
├── use-cases/ # アプリケーションルール
├── interface-adapters/
└── frameworks-drivers/
AIパフォーマンス:
- ⚠️ 抽象的な層分けでAIが具体的配置に迷う
- ⚠️ Use Cases ↔ Entities間の循環依存リスクをAIが見落とし
- ✅ 依存性の方向は明確
6. Onion Architecture ⭐ 低AIフレンドリー
src/
├── Core/
│ ├── Domain/
│ └── Application/
├── Infrastructure/
└── Presentation/
AIパフォーマンス:
- ⚠️ 同心円的レイヤーでAIが適切な層選択に迷う
- ⚠️ Application Services vs Domain Servicesの判断が困難
- ⚠️ 内部から外部への依存管理が複雑
🎯 AI開発における実践的比較
新機能追加シナリオ:「通知機能の追加」
FHD Architecture with AI:
AI: "新しい notification フィーチャーを作成します"
→ packages/features/notification/ を自動作成
→ domain/notification.entity.ts (純粋ロジック)
→ application/sendNotification.usecase.ts (オーケストレーション)
→ infrastructure/email.adapter.ts (外部連携)
AI実行時間: ~30秒、エラー率: 5%
Vertical Slice with AI:
AI: "CreateNotification スライスを作成します"
→ features/CreateNotification/ に全てを配置
→ 高い結合度で実装完了
AI実行時間: ~45秒、エラー率: 10%
Clean Architecture with AI:
AI: "どの層に配置すべきか判断中..."
→ Entity? Use Case? Interface Adapter?
→ 複数回の修正が必要
AI実行時間: ~90秒、エラー率: 25%
🏆 結論:AIフレンドリー度ランキング
-
🥇 FHD Architecture (★★★★★)
- AI開発に特化設計
- 構造的制約によるエラー予防
- 最高の開発速度とコード品質
-
🥈 Vertical Slice (★★★★☆)
- 機能の結合に焦点を当て、技術的結合を重視しない
- 機能単位での高い生産性
-
🥈 Feature Modular (★★★★☆)
- モジュラー設計の利点
- モジュール間依存の複雑さ
-
🥉 Hexagonal (★★★☆☆)
- ポート・アダプター理解に時間要
- 単一ヘキサゴンの限界
-
Clean Architecture (★★★☆☆)
- 概念理解の困難さ
- 抽象度の高さが障壁
-
Onion Architecture (★★☆☆☆)
- 同心円構造の複雑さ
- レイヤー判断の困難さ
FHDアーキテクチャは、AIとの共同開発において他を圧倒する性能を発揮する「AI-Native Architecture」として評価できます。
最後に
FHDアーキテクチャは長期的に応じてどのような副作用が生じるのかはまだわかりません。
しかしAIのおかげでFHDアーキテクチャに限らず個人開発レベルで意図的にアーキテクチャを選定して実装するという大げさなことをMVPレベルの開発で気軽に行えるようになったこと自体がとても大きいと今回は感じました。
最近はLLMの進歩が目覚ましくコードを読む量も減ってきたためコード以外を読まずにいかに品質を担保できるかというポイントにニーズが移りつつあります。おそらく今後は一般的にも設計の大切さは増していくのではないでしょうか。
Discussion