背景
我々のチームでは、TeamsとLLMを連携させたチャットボットの構築を進めています。
このチャットボットには多様な機能を持たせることを目指していますが、会話が単一のスレッドで継続していく特性上、履歴をプロンプトに含める際のコンテキストの扱いについて検討が必要だと感じました。
本記事では、過去のやり取りに関連する質問を行う際に、履歴をどのように活用できるかについて検証しています。
特に、直近の会話履歴に対してEmbeddingとコサイン類似度によるスコアリングを適用することで、会話の精度や応答内容にどのような影響を与えるかを評価しました。
対象読者
- LLMを使ったチャットボットを作ろうとしている方
- 会話履歴の扱い方についてこれから検討する方
環境
| 項目 | バージョン |
|---|---|
| OS | WSL( Ubuntu 22.04 ) |
| ランタイム | Python 3.12.7 |
| モデル | GPT 4.1-mini (Azure AI Foundry) |
| 主要ライブラリ | openai==1.97.1 |
| langfuse==3.2.1 |
検証の目的
チャットボットとの会話では、基本的に会話履歴が継続されており、「セッション」のような明確な区切りは存在しません。そのため、LLM(大規模言語モデル)と連携して履歴に基づいた応答を実装する際には、「どこまでの履歴を新しいプロンプトに含めるか」を慎重に検討する必要があります。
この履歴の切り取り方について、現時点で思いつく代表的なアプローチは以下の2つです:
-
時間的な距離による区切り
直近の発話を優先し、古い履歴は省略する方法です。会話の「最近性」を重視します。 -
意味的な距離による区切り
現在の話題と関連性の高い履歴のみを抽出する方法です。トピックの「関連性」を重視します。
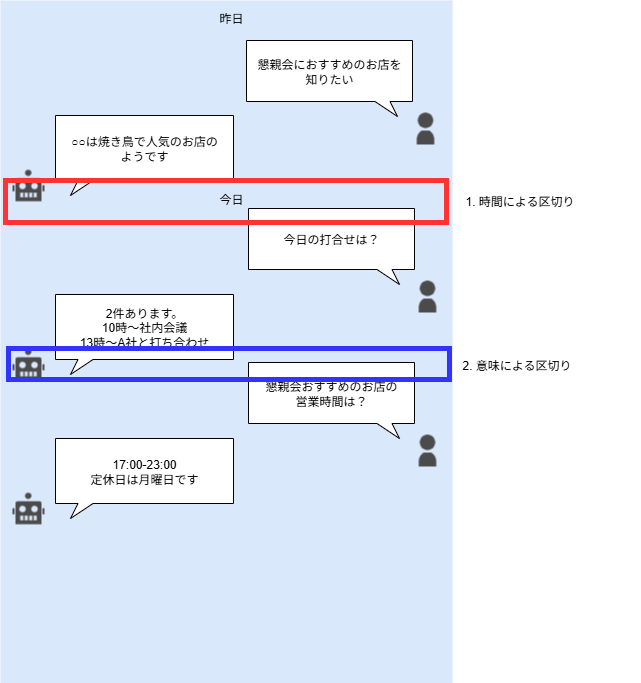
どの区切り方が最適かを判断するために、これらの手法を実際に試し、それぞれのケースでのトークン数や生成される応答の質を比較・検証することにしました。
時間軸による単純区切りは結果がある程度想定できるので、主に意味による区切り方を中心に、一部時間軸を考慮した検証を行っています。
検証の概要
区切り方の比較に向けた検証設計
履歴の区切り方による違いを比較するため、以下の前提条件のもとで4種類の検証を行いました。
前提条件
履歴データの固定化
チャットボットとの会話を模した履歴データをあらかじめ用意し、すべての検証で同じ履歴を使用しました。
履歴の内容
履歴には「ラーメン」「天気」「観光地」「映画」「プログラミング」など、複数の話題が混在しています。
検証の目的
この履歴の中から「ラーメン」に関する話題について要約を求められたケースを想定し、履歴の渡し方(区切り方)を変えてプロンプトを構成し、LLMの応答結果を比較しました。
実際のデータ
実際に使用したデータはこちらです。
[
{"role": "user", "content": "こんにちは、元気ですか?", "timestamp": "2025-07-29T09:00:00+09:00"},
{"role": "assistant", "content": "はい、元気です。ご用件をどうぞ。", "timestamp": "2025-07-29T09:00:30+09:00"},
{"role": "user", "content": "おすすめのラーメン屋を教えてください。", "timestamp": "2025-07-29T09:01:10+09:00"},
{"role": "assistant", "content": "近くの人気ラーメン店は「一蘭」です。", "timestamp": "2025-07-29T09:01:40+09:00"},
{"role": "user", "content": "一蘭の特徴は?", "timestamp": "2025-07-29T09:02:20+09:00"},
{"role": "assistant", "content": "一蘭はとんこつラーメン専門店で、味の濃さや辛さを選べます。", "timestamp": "2025-07-29T09:02:50+09:00"},
{"role": "user", "content": "おすすめメニューは?", "timestamp": "2025-07-29T09:03:30+09:00"},
{"role": "assistant", "content": "基本のとんこつラーメンが一番人気です。", "timestamp": "2025-07-29T09:04:00+09:00"},
{"role": "user", "content": "トッピングは何がある?", "timestamp": "2025-07-29T09:04:40+09:00"},
{"role": "assistant", "content": "ねぎ、きくらげ、チャーシュー、半熟卵などがあります。", "timestamp": "2025-07-29T09:05:10+09:00"},
{"role": "user", "content": "他に美味しいラーメン屋は?", "timestamp": "2025-07-29T09:05:50+09:00"},
{"role": "assistant", "content": "すみれの味噌ラーメンもおすすめです。", "timestamp": "2025-07-29T09:06:20+09:00"},
{"role": "user", "content": "すみれの特徴は?", "timestamp": "2025-07-29T09:07:00+09:00"},
{"role": "assistant", "content": "濃厚な味噌スープと中太麺が特徴です。", "timestamp": "2025-07-29T09:07:30+09:00"},
{"role": "user", "content": "すみれはどこにある?", "timestamp": "2025-07-29T09:08:10+09:00"},
{"role": "assistant", "content": "札幌に本店があり、東京や福岡にも支店があります。", "timestamp": "2025-07-29T09:08:40+09:00"},
{"role": "user", "content": "ラーメンの季節限定メニューは?", "timestamp": "2025-07-29T09:09:20+09:00"},
{"role": "assistant", "content": "夏は冷やしラーメン、冬は辛味噌ラーメンなどがあります。", "timestamp": "2025-07-29T09:09:50+09:00"},
{"role": "user", "content": "ラーメンの健康面はどう?", "timestamp": "2025-07-29T09:10:30+09:00"},
{"role": "assistant", "content": "塩分が多いので、スープは控えめにすると良いです。", "timestamp": "2025-07-29T09:11:00+09:00"},
{"role": "user", "content": "おすすめのトッピングは?", "timestamp": "2025-07-29T09:11:40+09:00"},
{"role": "assistant", "content": "半熟卵やチャーシューが人気です。", "timestamp": "2025-07-29T09:12:10+09:00"},
{"role": "user", "content": "明日の天気は?", "timestamp": "2025-07-29T09:20:00+09:00"},
{"role": "assistant", "content": "明日は晴れの予報です。", "timestamp": "2025-07-29T09:20:30+09:00"},
{"role": "user", "content": "気温はどれくらい?", "timestamp": "2025-07-29T09:21:10+09:00"},
{"role": "assistant", "content": "最高気温は30度、最低気温は22度です。", "timestamp": "2025-07-29T09:21:40+09:00"},
{"role": "user", "content": "週末に家族で行ける観光地は?", "timestamp": "2025-07-29T09:30:00+09:00"},
{"role": "assistant", "content": "箱根や鎌倉が人気です。", "timestamp": "2025-07-29T09:30:30+09:00"},
{"role": "user", "content": "箱根のおすすめスポットは?", "timestamp": "2025-07-29T09:31:10+09:00"},
{"role": "assistant", "content": "大涌谷や芦ノ湖がおすすめです。", "timestamp": "2025-07-29T09:31:40+09:00"},
{"role": "user", "content": "AI技術の最新動向について教えて。", "timestamp": "2025-07-29T09:40:00+09:00"},
{"role": "assistant", "content": "生成AIや大規模言語モデルが注目されています。", "timestamp": "2025-07-29T09:40:30+09:00"},
{"role": "user", "content": "大規模言語モデルの活用事例は?", "timestamp": "2025-07-29T09:41:10+09:00"},
{"role": "assistant", "content": "チャットボットや自動要約、翻訳などに使われています。", "timestamp": "2025-07-29T09:41:40+09:00"},
{"role": "user", "content": "おすすめの映画は?", "timestamp": "2025-07-29T09:50:00+09:00"},
{"role": "assistant", "content": "『君の名は。』はいかがでしょうか。", "timestamp": "2025-07-29T09:50:30+09:00"},
{"role": "user", "content": "他に感動する映画は?", "timestamp": "2025-07-29T09:51:10+09:00"},
{"role": "assistant", "content": "『天気の子』もおすすめです。", "timestamp": "2025-07-29T09:51:40+09:00"},
{"role": "user", "content": "映画のジャンルでおすすめは?", "timestamp": "2025-07-29T09:52:20+09:00"},
{"role": "assistant", "content": "アニメ映画やヒューマンドラマが人気です。", "timestamp": "2025-07-29T09:52:50+09:00"},
{"role": "user", "content": "最近公開された映画は?", "timestamp": "2025-07-29T09:53:30+09:00"},
{"role": "assistant", "content": "『シン・仮面ライダー』などが話題です。", "timestamp": "2025-07-29T09:54:00+09:00"},
{"role": "user", "content": "映画館のおすすめは?", "timestamp": "2025-07-29T09:54:40+09:00"},
{"role": "assistant", "content": "TOHOシネマズや109シネマズが設備も良いです。", "timestamp": "2025-07-29T09:55:10+09:00"},
{"role": "user", "content": "映画の割引サービスは?", "timestamp": "2025-07-29T09:55:50+09:00"},
{"role": "assistant", "content": "レディースデーやシニア割引があります。", "timestamp": "2025-07-29T09:56:20+09:00"},
{"role": "user", "content": "映画の話に戻るけど、アニメ映画のおすすめは?", "timestamp": "2025-07-29T09:57:00+09:00"},
{"role": "assistant", "content": "『千と千尋の神隠し』や『もののけ姫』が有名です。", "timestamp": "2025-07-29T09:57:30+09:00"},
{"role": "user", "content": "PythonでWebスクレイピングする方法は?", "timestamp": "2025-07-29T10:10:00+09:00"},
{"role": "assistant", "content": "BeautifulSoupやrequestsライブラリが便利です。", "timestamp": "2025-07-29T10:10:30+09:00"},
{"role": "user", "content": "サンプルコードを教えて。", "timestamp": "2025-07-29T10:11:10+09:00"},
{"role": "assistant", "content": "以下のように記述できます。\nimport requests\nfrom bs4 import BeautifulSoup\n...", "timestamp": "2025-07-29T10:11:40+09:00"},
{"role": "user", "content": "Webスクレイピングの注意点は?", "timestamp": "2025-07-29T10:12:20+09:00"},
{"role": "assistant", "content": "利用規約やrobots.txtを確認しましょう。", "timestamp": "2025-07-29T10:12:50+09:00"},
{"role": "user", "content": "データ保存の方法は?", "timestamp": "2025-07-29T10:13:30+09:00"},
{"role": "assistant", "content": "CSVやJSON形式で保存できます。", "timestamp": "2025-07-29T10:14:00+09:00"},
{"role": "user", "content": "おすすめのプログラミング言語は?", "timestamp": "2025-07-29T10:20:00+09:00"},
{"role": "assistant", "content": "Pythonは初心者にも扱いやすいです。", "timestamp": "2025-07-29T10:20:30+09:00"},
{"role": "user", "content": "AI開発に向いている言語は?", "timestamp": "2025-07-29T10:21:10+09:00"},
{"role": "assistant", "content": "PythonやRがよく使われます。", "timestamp": "2025-07-29T10:21:40+09:00"},
{"role": "user", "content": "プログラミング学習のコツは?", "timestamp": "2025-07-29T10:22:20+09:00"},
{"role": "assistant", "content": "小さなプログラムから始めて、継続することが大切です。", "timestamp": "2025-07-29T10:22:50+09:00"},
{"role": "user", "content": "おすすめの学習サイトは?", "timestamp": "2025-07-29T10:23:30+09:00"},
{"role": "assistant", "content": "Progateやドットインストールが人気です。", "timestamp": "2025-07-29T10:24:00+09:00"},
{"role": "user", "content": "久しぶりにラーメンの話に戻るけど、最近の限定メニューは?", "timestamp": "2025-07-29T10:40:00+09:00"},
{"role": "assistant", "content": "最近は柚子塩ラーメンやベジタブルラーメンが人気です。", "timestamp": "2025-07-29T10:40:30+09:00"},
{"role": "user", "content": "ラーメンのテイクアウトはできる?", "timestamp": "2025-07-29T10:41:00+09:00"},
{"role": "assistant", "content": "一部店舗でテイクアウト対応しています。", "timestamp": "2025-07-29T10:41:30+09:00"}
]
検証準備
検証に先立ち、必要なライブラリをインストールし、仮想環境を整備しました。使用したパッケージは以下の通りです:
pip install sentence-transformers openai python-dotenv langfuse janome python-dateutil
これらは、履歴の意味的な分析やLLMとの連携、トークン数の計測、自然言語処理などに使用します。
検証した手法
手法1 履歴をすべてプロンプトに含める
概要
すべての会話履歴をそのままプロンプトに含め、「この会話履歴からラーメンの話題について要約してください」と指示を与えました。
結果
-
トークン数(IN / OUT)
1040 / 281 -
評価:
履歴全体を含めているため、ラーメンに関する情報は網羅的に抽出されました。検証した中では最もトークン数が多くなりました。 -
プロンプト
user: こんにちは、元気ですか? assistant: はい、元気です。ご用件をどうぞ。 user: おすすめのラーメン屋を教えてください。 assistant: 近くの人気ラーメン店は「一蘭」です。 user: 一蘭の特徴は? assistant: 一蘭はとんこつラーメン専門店で、味の濃さや辛さを選べます。 user: おすすめメニューは? assistant: 基本のとんこつラーメンが一番人気です。 user: トッピングは何がある? assistant: ねぎ、きくらげ、チャーシュー、 (履歴すべてなので中略) user: ラーメンのテイクアウトはできる? assistant: 一部店舗でテイクアウト対応しています。 この会話履歴からラーメンの話題について要約してください。 -
回答
この会話では、ユーザーがラーメンについてさまざまな質問をしました。以下がラーメンの話題の要約です。 おすすめのラーメン店として「一蘭」と「すみれ」が紹介された。 一蘭の特徴はとんこつラーメン専門で、味や辛さを選べること。おすすめメニューは基本のとんこつラーメン。トッピングはねぎ、きくらげ、チャーシュー、半熟卵など。 すみれの特徴は濃厚な味噌スープと中太麺で、札幌に本店があり東京や福岡にも支店がある。 季節限定メニューとして、夏は冷やしラーメン、冬は辛味噌ラーメンがある。 健康面では塩分が多いためスープは控えめにすることが推奨された。 おすすめトッピングは半熟卵やチャーシュー。 最近の限定メニューとして柚子塩ラーメンやベジタブルラーメンが人気。 一部店舗でテイクアウトも可能。
ソース
手法1のソース
import json
import os
# .envから環境変数を読み込む
from dotenv import load_dotenv
# Langfuse経由でAzure OpenAI APIを利用
from langfuse.openai import AzureOpenAI
load_dotenv()
# Azure OpenAIクライアント初期化
client = AzureOpenAI(
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_version="2024-02-15-preview",
api_key=os.getenv("AZURE_OPENAI_API_KEY")
)
def load_conversation(path):
"""
サンプル会話データ(JSON)を読み込む
"""
with open(path, 'r', encoding='utf-8') as f:
return json.load(f)
def build_prompt(conversation):
"""
会話履歴をそのままプロンプト文字列に変換
"""
prompt = ""
for turn in conversation:
prompt += f"{turn['role']}: {turn['content']}\n"
prompt += "\nこの会話履歴からラーメンの話題について要約してください。"
return prompt
def call_gpt41_mini(prompt):
"""
Azure OpenAI GPT-4.1-mini APIを呼び出し、要約を取得
"""
deployment = os.getenv("AZURE_OPENAI_DEPLOYMENT")
response = client.chat.completions.create(
model=deployment,
messages=[{"role": "user", "content": prompt}],
name = "History Summary Wave-1",
metadata={"langfuse_tags": ["Wave-1"]}
)
return response.choices[0].message.content
if __name__ == "__main__":
# サンプル会話データを読み込み
conversation = load_conversation("sample_conversation.json")
# 全履歴をプロンプト化
prompt = build_prompt(conversation)
# LLMで要約を取得
answer = call_gpt41_mini(prompt)
print("---ラーメンの話題サマリ---")
print(answer)
手法2 各発話をEmbeddingし、キーワードとの類似度でピックアップ
概要
各発話をベクトル化(embedding)し、最終クエリ「この履歴からラーメンの話題について要約してください。」から抽出したキーワード(Janomeによる名詞抽出)との類似度を計算。類似度の高い発話のみを選別してプロンプトに含め、LLMに要約を依頼しました。
結果
-
トークン数(IN / OUT)
168 / 88 -
評価:
トークン数は最も少なく、効率的な履歴抽出を目指した手法でしたが、結果としては意図したラーメン関連の発話が十分に抽出されず、LLMの応答も限定的な内容となりました。
特に、プロンプトから抽出された名詞の先頭に「履歴」が含まれていたため、履歴全体ではなく「履歴」という単語に類似した発話が抽出されてしまいました。 -
プロンプト
assistant: はい、元気です。ご用件をどうぞ。 assistant: 利用規約やrobots.txtを確認しましょう。 user: 映画の割引サービスは? user: すみれの特徴は? assistant: 小さなプログラムから始めて、継続することが大切です。 assistant: 以下のように記述できます。 user: すみれはどこにある? assistant: CSVやJSON形式で保存できます。 assistant: 基本のとんこつラーメンが一番人気です。 user: データ保存の方法は? この履歴からラーメンの話題について要約してください。 -
回答
履歴の中で「すみれ」に関する話題が出ており、「すみれ」はラーメン店で、「基本のとんこつラーメン」が一番人気であることが言及されています。その他、ラーメン以外の話題も混在していますが、「すみれ」はラーメン店として位置づけられています。
ソース
手法2のソース
import json
import os
# .envから環境変数を読み込む
from dotenv import load_dotenv
# 日本語埋め込みモデル
from sentence_transformers import SentenceTransformer, util
# Langfuse経由でAzure OpenAI APIを利用
from langfuse.openai import AzureOpenAI
# キーワード抽出用形態素解析
from janome.tokenizer import Tokenizer
load_dotenv()
# Azure OpenAIクライアント初期化
client = AzureOpenAI(
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_version="2024-02-15-preview",
api_key=os.getenv("AZURE_OPENAI_KEY")
)
def load_conversation(path):
"""
サンプル会話データ(JSON)を読み込む
"""
with open(path, 'r', encoding='utf-8') as f:
return json.load(f)
def select_similar(conversation, query, model, top_k=3):
"""
各発話の埋め込みとクエリ埋め込みの類似度を計算し、上位のみ抽出
"""
sentences = [turn['content'] for turn in conversation]
embeddings = model.encode(sentences)
query_emb = model.encode([query])[0]
scores = util.cos_sim(query_emb, embeddings)[0]
top_indices = scores.argsort(descending=True)[:top_k]
selected = [conversation[i] for i in top_indices]
print(selected)
return selected
def extract_main_keyword(text):
"""
クエリ文から名詞を抽出し、最初の名詞をキーワードとして返す
"""
t = Tokenizer()
nouns = [token.surface for token in t.tokenize(text) if token.part_of_speech.startswith('名詞')]
# 最初の名詞をqueryに使う(必要に応じて工夫)
print("keyword:")
print(nouns)
return nouns[0] if len(nouns) > 1 else nouns[0]
if __name__ == "__main__":
# 日本語埋め込みモデルをロード
model = SentenceTransformer('sonoisa/sentence-bert-base-ja-mean-tokens')
# サンプル会話データを読み込み
conversation = load_conversation("sample_conversation.json")
# 最終問いをqueryとしてembedding検索
final_query = "この履歴からラーメンの話題について要約してください。"
# クエリからキーワード抽出
main_keyword = extract_main_keyword(final_query)
print(main_keyword)
# 類似度上位の発話を抽出
selected = select_similar(conversation, main_keyword, model, top_k=10)
# プロンプトを組み立て
prompt = ""
for turn in selected:
prompt += f"{turn['role']}: {turn['content']}\n"
prompt += f"\n{final_query}"
# GPT 4.1-mini API呼び出し
deployment = os.getenv("AZURE_OPENAI_DEPLOYMENT")
response = client.chat.completions.create(
model=deployment,
messages=[{"role": "user", "content": prompt}],
name="History Summary Wave-2",
metadata={"langfuse_tags": ["Wave-2"]}
)
answer = response.choices[0].message.content
print("---ラーメンの話題サマリ---")
print(answer)
手法3 各発話をEmbeddingし、キーワードとの類似度でピックアップ(キーワードはLLMで選定)
概要
前回の手法(2)では、形態素解析によって名詞を抽出しましたが、抽出された名詞の出現順や文脈に左右されやすく、意図しない履歴の選別につながりました。そこで今回は、最終的な問い「この履歴からラーメンの話題について要約してください」をLLMに渡し、履歴抽出に使うキーワードを1語だけ選定してもらう方式を採用しました。
そのキーワードをもとに、各発話のEmbeddingとの類似度を計算し、関連性の高い履歴のみをプロンプトに含めて要約を依頼しました。
結果
- トークン数(IN / OUT)
- キーワード抽出 71 / 5
- 回答生成 204 / 149
- 合計 275 / 154
- 評価:
LLMによるキーワード選定により、ラーメンに関連する履歴は比較的うまく抽出されました。ただし、「トッピング」などラーメンという語を含まないが関連性の高い情報は抽出されず、要約に含まれない結果となりました。
キーワード抽出
- プロンプト
次の問いから、履歴検索に最も重要なキーワードを日本語で1語だけ抽出してください。不要な語や説明は一切付けず、キーワードのみを出力してください。 問い: この履歴からラーメンの話題について要約してください。 - 回答
ラーメン
回答生成
-
プロンプト
user: ラーメンの健康面はどう? user: ラーメンのテイクアウトはできる? user: ラーメンの季節限定メニューは? assistant: すみれの味噌ラーメンもおすすめです。 assistant: 近くの人気ラーメン店は「一蘭」です。 user: おすすめメニューは? assistant: 夏は冷やしラーメン、冬は辛味噌ラーメンなどがあります。 assistant: 最近は柚子塩ラーメンやベジタブルラーメンが人気です。 assistant: 一蘭はとんこつラーメン専門店で、味の濃さや辛さを選べます。 user: 他に美味しいラーメン屋は? この履歴からラーメンの話題について要約してください。 -
回答
ラーメンの健康面やテイクアウトの可否、季節限定メニューについての質問がありました。おすすめとして、すみれの味噌ラーメン、一蘭のとんこつラーメンが紹介されています。季節限定メニューは夏の冷やしラーメンや冬の辛味噌ラーメンがあり、最近は柚子塩ラーメンやベジタブルラーメンも人気です。さらに、一蘭では味の濃さや辛さを選べることや、他の美味しいラーメン店についても関心が示されています。
ソース
手法3のソース
import json
import os
# .envから環境変数を読み込む
from dotenv import load_dotenv
# 日本語埋め込みモデル
from sentence_transformers import SentenceTransformer, util
# Langfuse経由でAzure OpenAI APIを利用
from langfuse.openai import AzureOpenAI
load_dotenv()
# Azure OpenAIクライアント初期化
client = AzureOpenAI(
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_version="2024-02-15-preview",
api_key=os.getenv("AZURE_OPENAI_KEY")
)
def load_conversation(path):
"""
サンプル会話データ(JSON)を読み込む
"""
with open(path, 'r', encoding='utf-8') as f:
return json.load(f)
def select_similar(conversation, query, model, top_k=3):
"""
各発話の埋め込みとクエリ埋め込みの類似度を計算し、上位のみ抽出
"""
sentences = [turn['content'] for turn in conversation]
embeddings = model.encode(sentences)
query_emb = model.encode([query])[0]
scores = util.cos_sim(query_emb, embeddings)[0]
print(util.cos_sim(query_emb, embeddings))
top_indices = scores.argsort(descending=True)[:top_k]
print(top_indices)
selected = [conversation[i] for i in top_indices]
return selected
def extract_main_keyword_with_llm(final_query):
"""
LLM(GPT-4.1-mini)でクエリから主要キーワードを抽出
"""
deployment = os.getenv("AZURE_OPENAI_DEPLOYMENT")
prompt = (
f"次の問いから、履歴検索に最も重要なキーワードを日本語で1語だけ抽出してください。"
f"不要な語や説明は一切付けず、キーワードのみを出力してください。\n\n"
f"問い: {final_query}"
)
response = client.chat.completions.create(
model=deployment,
messages=[{"role": "user", "content": prompt}],
name="History Summary Wave-3 Pre",
metadata={"langfuse_tags": ["Wave-3-Pre"]}
)
keyword = response.choices[0].message.content.strip()
return keyword
if __name__ == "__main__":
# 日本語埋め込みモデルをロード
model = SentenceTransformer('sonoisa/sentence-bert-base-ja-mean-tokens')
# サンプル会話データを読み込み
conversation = load_conversation("sample_conversation.json")
final_query = "この履歴からラーメンの話題について要約してください。"
# LLMで主要キーワードを抽出
main_keyword = extract_main_keyword_with_llm(final_query)
print(f"抽出キーワード: {main_keyword}")
# 類似度スコアを計算
sentences = [turn['content'] for turn in conversation]
embeddings = model.encode(sentences)
query_emb = model.encode([main_keyword])[0]
scores = util.cos_sim(query_emb, embeddings)[0]
# 履歴とスコアを並べて表示
print("\n--- 履歴ごとの類似度スコア ---")
for turn, score in zip(conversation, scores):
print(f"{turn['role']}: {turn['content']} [score: {score:.4f}]")
# 上位のみ抽出
top_k = 10
top_indices = scores.argsort(descending=True)[:top_k]
selected = [conversation[i] for i in top_indices]
# プロンプトを組み立て
prompt = ""
for turn in selected:
prompt += f"{turn['role']}: {turn['content']}\n"
prompt += f"\n{final_query}"
# GPT 4.1-mini API呼び出し
deployment = os.getenv("AZURE_OPENAI_DEPLOYMENT")
response = client.chat.completions.create(
model=deployment,
messages=[{"role": "user", "content": prompt}],
name="History Summary Wave-3",
metadata={"langfuse_tags": ["Wave-3"]}
)
answer = response.choices[0].message.content
print("\n---ラーメンの話題サマリ---")
print(answer)
手法4 時間経過により会話をグループ化してEmbeddingし、キーワードとグループの類似度でピックアップ
概要
キーワードの選定は手法3と同様にLLMに依頼し、「ラーメン」という語を抽出しました。一方、履歴の扱いについては、発話単位ではなく時間間隔に着目し、ある程度のまとまり(連続した会話)をグループ化してEmbeddingを行いました。
その後、グループ単位でキーワードとの類似度を計算し、関連性の高いグループのみをプロンプトに含めて要約を依頼しました。
結果
- トークン数(IN / OUT)
- キーワード抽出 71 / 5
- 回答生成 452 / 292
- 合計 523 / 297
- 評価:
発話単位ではなく、時間的にまとまった会話をグループ化してEmbeddingすることで、意味的な連続性が保たれた履歴抽出が可能となりました。結果として、網羅性は「履歴全体を渡した場合」とほぼ同等でありながら、トークン数は約半分に抑えることができました。
この手法は、意味的な関連性だけでなく、会話の流れや文脈を保持したまま履歴を抽出できる点で有効性は高いと考えられます。
キーワード生成((3)の例と同じです)
- プロンプト
次の問いから、履歴検索に最も重要なキーワードを日本語で1語だけ抽出してください。不要な語や説明は一切付けず、キーワードのみを出力してください。 問い: この履歴からラーメンの話題について要約してください。 - 回答
ラーメン
回答生成
- プロンプト
user: こんにちは、元気ですか? assistant: はい、元気です。ご用件をどうぞ。 user: おすすめのラーメン屋を教えてください。 assistant: 近くの人気ラーメン店は「一蘭」です。 user: 一蘭の特徴は? assistant: 一蘭はとんこつラーメン専門店で、味の濃さや辛さを選べます。 user: おすすめメニューは? assistant: 基本のとんこつラーメンが一番人気です。 user: トッピングは何がある? assistant: ねぎ、きくらげ、チャーシュー、半熟卵などがあります。 user: 他に美味しいラーメン屋は? assistant: すみれの味噌ラーメンもおすすめです。 user: すみれの特徴は? assistant: 濃厚な味噌スープと中太麺が特徴です。 user: すみれはどこにある? assistant: 札幌に本店があり、東京や福岡にも支店があります。 user: ラーメンの季節限定メニューは? assistant: 夏は冷やしラーメン、冬は辛味噌ラーメンなどがあります。 user: ラーメンの健康面はどう? assistant: 塩分が多いので、スープは控えめにすると良いです。 user: おすすめのトッピングは? assistant: 半熟卵やチャーシューが人気です。 user: 久しぶりにラーメンの話に戻るけど、最近の限定メニューは? assistant: 最近は柚子塩ラーメンやベジタブルラーメンが人気です。 user: ラーメンのテイクアウトはできる? assistant: 一部店舗でテイクアウト対応しています。 この履歴からラーメンの話題について要約してください。 - 回答
ユーザーはラーメンについて会話を続け、主に以下の内容が話されました: - 「一蘭」はとんこつラーメン専門店で、味の濃さや辛さを調整可能。おすすめは基本のとんこつラーメンで、トッピングにはねぎ、きくらげ、チャーシュー、半熟卵などがある。 - 「すみれ」は濃厚な味噌スープと中太麺が特徴で、札幌に本店があり東京や福岡にも支店がある。 - 季節限定メニューとして、夏は冷やしラーメン、冬は辛味噌ラーメンが提供されることがある。 - 健康面では塩分が多いのでスープは控えめがおすすめ。 - 最近の限定メニューには柚子塩ラーメンやベジタブルラーメンが人気。 - 一部店舗でラーメンのテイクアウトも可能である。 要するに、ユーザーは人気店やメニューの特徴、トッピング、限定商品、健康面、そしてテイクアウト対応について情報を求め、ラーメンに関して幅広く話が展開されました。
ソース
手法4のソース
import json
import os
# .envから環境変数を読み込む
from dotenv import load_dotenv
# 日本語埋め込みモデル
from sentence_transformers import SentenceTransformer, util
# Langfuse経由でAzure OpenAI APIを利用
from langfuse.openai import AzureOpenAI
load_dotenv()
# Azure OpenAIクライアント初期化
client = AzureOpenAI(
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_version="2024-02-15-preview",
api_key=os.getenv("AZURE_OPENAI_KEY")
)
def load_conversation(path):
"""
サンプル会話データ(JSON)を読み込む
"""
with open(path, 'r', encoding='utf-8') as f:
return json.load(f)
def extract_main_keyword_with_llm(final_query):
"""
LLM(GPT-4.1-mini)でクエリから主要キーワードを抽出
"""
deployment = os.getenv("AZURE_OPENAI_DEPLOYMENT")
prompt = (
f"次の問いから、履歴検索に最も重要なキーワードを日本語で1語だけ抽出してください。"
f"不要な語や説明は一切付けず、キーワードのみを出力してください。\n\n"
f"問い: {final_query}"
)
response = client.chat.completions.create(
model=deployment,
messages=[{"role": "user", "content": prompt}],
name="History Summary Wave-4 Pre",
metadata={"langfuse_tags": ["Wave-4-Pre"]}
)
keyword = response.choices[0].message.content.strip()
return keyword
if __name__ == "__main__":
# 日本語埋め込みモデルをロード
model = SentenceTransformer('sonoisa/sentence-bert-base-ja-mean-tokens')
# サンプル会話データを読み込み
conversation = load_conversation("sample_conversation.json")
final_query = "この履歴からラーメンの話題について要約してください。"
# LLMで主要キーワードを抽出
main_keyword = extract_main_keyword_with_llm(final_query)
print(f"抽出キーワード: {main_keyword}")
# 一定時間(例:5分=300秒)以上空いたら新しいブロックを開始
from datetime import datetime
import dateutil.parser
time_threshold_sec = 300 # 5分
blocks = []
current_block = []
block_indices = []
current_indices = []
prev_time = None
for idx, utter in enumerate(conversation):
t = dateutil.parser.parse(utter["timestamp"])
if prev_time is not None:
diff = (t - prev_time).total_seconds()
if diff > time_threshold_sec and current_block:
# 一定時間空いたら新しいブロックを開始
blocks.append("\n".join(current_block))
block_indices.append(current_indices)
current_block = []
current_indices = []
current_block.append(f"{utter['role']}: {utter['content']}")
current_indices.append(idx)
prev_time = t
if current_block:
blocks.append("\n".join(current_block))
block_indices.append(current_indices)
# 各ブロックの埋め込みとクエリ埋め込みの類似度を計算
block_embeddings = model.encode(blocks)
query_emb = model.encode([main_keyword])[0]
scores = util.cos_sim(query_emb, block_embeddings)[0]
print("\n--- ブロックごとの類似度スコア ---")
for idx, (block, score) in enumerate(zip(blocks, scores)):
print(f"Block {idx}: [score: {score:.4f}]\n{block}\n")
# スコアが0.3(30%)を超えるブロックのみ抽出
threshold = 0.3
selected = [(i, float(score)) for i, score in enumerate(scores) if float(score) > threshold]
# インデックス昇順(時系列順)で並べる
selected.sort(key=lambda x: x[0])
selected_blocks = [blocks[i] for i, _ in selected]
# プロンプトを組み立て
prompt = "\n".join(selected_blocks) + f"\n{final_query}"
# GPT 4.1-mini API呼び出し
deployment = os.getenv("AZURE_OPENAI_DEPLOYMENT")
response = client.chat.completions.create(
model=deployment,
messages=[{"role": "user", "content": prompt}],
name="History Summary Wave-4",
metadata={"langfuse_tags": ["Wave-4"]}
)
answer = response.choices[0].message.content
print("\n---ラーメンの話題サマリ---")
print(answer)
考察
今回の検証では、時間的なまとまりと意味的な関連性を組み合わせた履歴抽出(手法4)が最も効果的であることが確認できました。特に、網羅性とトークン効率のバランスが良かったです。
ただし、以下のような点も考慮が必要だと感じました。
- 実際の会話では話題の切り替えや空白時間が不規則であるため、時間ベースのグルーピングが常に有効とは限らない。
- Embeddingの都度実行は応答速度に影響し、リアルタイム性が求められる場面では課題となる。
- 時間間隔によるグループ化からの類似度の閾値による抽出では、会話の流れによって意味的に重要な履歴を含むグループのスコアが低くなってしまい、抽出されない可能性があるため、上位N件の抽出など、より柔軟な選定方法の検討が必要。
今後
-
履歴に基づいた応答機能の実装
検証結果を活かし、チャットボットが過去の会話を踏まえて自然な応答を返す機能を構築。
最初はフレームワークのメモリ機能をそのまま組込み、その後の状況に応じて検証から得た知見を適用したいと思います。 -
短期履歴から長期記憶への昇華
直近の履歴をもとに、ユーザーの嗜好や傾向を長期的に保持・活用する仕組みの検討。 -
LangChainのメモリ機能の再評価
今回のように履歴を細かく条件で抽出するケースでは、LangChainの標準的なメモリ機能ではフレームワークのメリットを見いだせず、使用せずに検証を行いました。
フレームワークの拡張や独自実装の可能性も含めて、より深く検証してみたいです。

Discussion