SIGNATE Cup 2024 夏 旅行パッケージ成約率予測 Bronze Solution
はじめに
こんにちは、データサイエンティストをしているせりです。
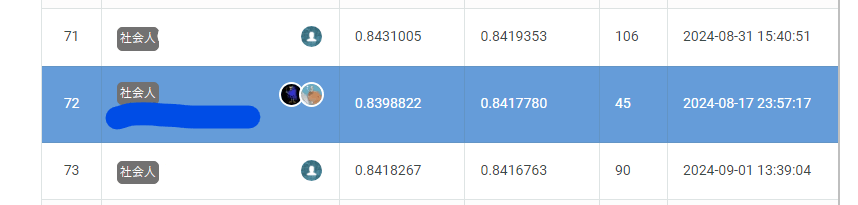
2024/8/1~2024/09/01の期間に行われた「SIGNATE Cup 2024 夏」の旅行パッケージ成約率予測コンペ において、まだ確定ではないですが72位となり、銅メダルを獲得することが出来ました。
また、これによりSIGNATE Expertへ昇格しました!
この記事では、そのBest solutionと戦略、他に検証した手法について紹介したいと思います。
コンペ概要
このコンペは、旅行会社が保有する顧客データを元に、旅行パッケージの成約率を予測することが目標です。
予測した成約率に対してAUCで評価を行い、そのスコアで順位を競うというものでした。

詳細はコンペサイトを見ていただければと思います。
手順と戦略
手順
今回のコンペでは、以下の手順で取り組みました。
コンペに参加したのが8/15からで締め切りまで半月しかなかったのですが、手順5からは友人とチームを組んで2馬力で進めたので、様々なことを試すことが出来ました。
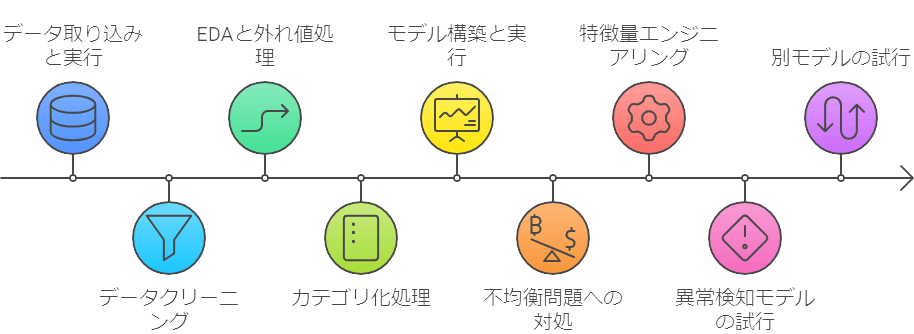
- データを取り込んでtutorialをそのまま実行し、スコアを確認する
- データクリーニングを行い、データを整える
- EDAを行い、外れ値などの対処を行う
- Catboost用にカテゴリ化処理を行う
- LightGBM、Catboostを用いてモデルを構築・実行し、ベースラインを作り、EDA結果と合わせて戦略を練る
- 不均衡問題に対する対処を実施する
- 特徴量エンジニアリングを行う
- 異常検知モデルを試す
- 別モデルとしてXGBoost、TabPFNを試す
- アンサンブル、スタッキングを試す
- LLM fine-tuningを試す
戦略
手順【5】でベースラインが出来たところで、以下3点の戦略を練りました。
- 3のEDAの結果から、不均衡データであることが分かっていたので、これの対処としてUnder sampling + Baggingを試すこと (手順6)
- 単純に特徴量エンジニアリングを試すこと (手順7)
- 並行して、LightGBMとCatboost以外の有効そうなモデルを検討すること
上記を実施後、再度戦略検討を行い、以下の案が出ました。
- 不均衡問題に対して、Under sampling + Baggingはそこまで効いていない。別の対処法として、異常検知モデルのLocal Outlier FactorとOne Class SVMのスコアを特徴量として追加することを試す (手順8)
- LightGBMとCatboost以外の有効そうなモデルとして、XGBoostとTabPFNを試す (手順9)
これらが終わった時点であと1日程度だったので、アンサンブル、Logistic RegressionとNeural Networkを使ったスタッキングをして終了しました (LLM fine-tuningについては後述)。
また、今回のコンペでは最終提出するファイルが2つまで選べるとのことで、以下の条件で2つのファイルを選択しました。
| 選択モデル | 狙い | CV | LB |
|---|---|---|---|
| 全モデルのスタッキングモデル | 汎化性が高く、shake downの可能性が低い&shake upが狙えるモデル | 0.86 | 0.8398 |
| Catboostのモデル | CV, LBとも精度が高いモデル | 0.8442 | 0.8417 |
結果として、CatboostのモデルのLBがベストスコアとなりました。
Best Solution
上記の通り、最終評価で最もスコアが高かったモデルは、Catboostモデルでした。
本ソリューションのコードは以下で公開しています。
このモデルで実施したことは以下の通りです。
- 受領データに対し、データクリーニングを実施する
- クリーニングデータに対し、数値データのカテゴリ化と外れ値補正を行う
- OptunaでCatboostのパラメータ最適化を行う
- 最適パラメータを用いて学習を行う
- K-foldの平均値を提出
今回のSolutionで特徴的な、1~3の処理内容を紹介します。
1.データクリーニング
まずデータを確認したところ、明らかに内容がおかしいカラムが複数ありましたので、それらのカラムの内容を揃える処理を行いました。
例)性別:male, Male, Ma1e → Maleに揃える
これらの処理のスクリプトは基本的にChatGPTに書いてもらい。微修正することでパパっと終わらせました。
2.カテゴリ化と外れ値補正
自分もコンペのディスカッションで知ったのですが、Catboostは名前の通りカテゴリカルデータに強いモデルとのことなので、年齢や年収など一部の数値データをカテゴリ化する処理を行いました。
特に月収カラムなどは振れ幅が大きく、区分分けの方法に悩んだのですが、各カラムで区分分けを変えて学習した時の精度差と、これまでデータ分析を行ってきた経験で決定しました。
また、クリーニングしたデータを確認した際、NumberOfFollowupsカラムは基本的には1~6の数値が入っていたのですが、一部100, 300といった数値が混ざっていました。
実際に店員が1組の顧客に対するフォローを何百回も行うことは現実的ではないので、顧客データベースへの入力ミスと仮定して100で割る処理を行ったところ、精度改善することが確認できました。
例)300 → 3
3.パラメータ最適化
Github Code: Catboost Parameter Tuning
本学習を行う前に、OptunaでCatboostのパラメータ最適化を行いました。
ただ、iter=20より iter=100 の方がcvは良くなるものの、LBは低下するということもあり、あまり意味はなかったかもしれないです。
他に試したことで面白かったこと (LLMの話)
本コンペが終わる直前の8/29~31に、atmaCupが開催されていました。
こちらのコンペで話題となっていたのが、上位陣のソリューションの多くがLLMをコンペデータでfine-tuningしてスコアを予測させていたということです。
こんな方法があるのかと思い、コンペ最終日を使って真似してみることにしました。
コードはatmaCupでも使われていた、Kaggleで公開されている以下を用いて実装しました。
LLMのfine-tuningを行うのが初めてということもあり、トライアンドエラーを繰り返しているうちにタイムアップとなってしまい、提出があと30分間に合いませんでした。。
ただ、手元のデータでcvを確認したところ、0.7515 というようなスコアとなりました。
自分の他のモデルやベストソリューションのスコアが0.84台なのを考えると低いですが、これはatmaCupなどと違い、コンペデータに自然言語があまり入っていないことが原因の1つかなと考えています。
ただ、特別な前処理をせずにこの精度が出たことを考えると、改善の余地は多分にありそうだなとも考えています。
感想
今回のコンペは、正直運の要素も大きいコンペでした。
ただ、参加してから締め切りまで半月しかないなかで多くの試行が出来ました。
特に、異常検知モデルやTabPFN、LLM fine-tuning辺りは初めて触ったので、実装経験を積むことが出来て良かったです。
加えて、コンペの全体像を把握した後や戦略を練る際の構造化と分析設計について、普段の業務経験を踏まえながら自分が出来ることとまだ出来ないことを把握することができ、非常に良い経験となりました。
コンペお疲れ様でした!
謝辞
今回、コンペでチームを組んで一緒に取り組んでくれたご学友のデータサイエンティスト、baibai氏に深く感謝申し上げます。
Discussion