SIGNATE RAG-1グランプリ Solution備忘録

はじめに
こんにちは、データサイエンティストをしているせりです。
2024/09/12~2024/10/10の期間にSIGNATEで開催された「RAG-1グランプリ」コンペに参加しました。結果は惜しくも138位とメダル圏外だったものの、多くの手法を試して得るものが多かったため、Solutionをまとめておきます。
コンペ概要
このコンペは、与えられたデータセットと問いのリストに基づき、最適なRAGシステムを構築し、その性能や精度を競うというものでした。データセットは複数の小説テキストから構成されていました。
詳細はコンペサイトを見ていただければと思います。
行った取り組み
今回のコンペでは、以下の手順で取り組みました。
最終的には、以下の試行の一部を組み合わせた結果がBest Solutionとなりました。
- データセットの前処理を実施
- シンプルなRAGシステムを構築し、スコアを確認
- 検索手法としてHybrid Searchを試行
- Indexingに対し、Chunk Optimizationの一つであるSemantic Chunkingを試行
- Indexingに対し、Multi-representation indexingの一つであるSummary Embeddingを試行
- Retrivalに対し、Query Translationの一つであるMulti-queryを試行
- Retrivalに対し、Query Translationの一つであるHyDEを試行
Best Solution
本Solutionのスクリプトは以下で公開しています。
Best Solutionは20241004_multi_query.ipynbスクリプトになります。
1. Data Cleaning
与えられたRAG用のデータセットは、ルビが振られていたり小説の内容とは関係ない情報が付与されていたため、小説本文だけを抜き出すスクリプトを作成し、小説本文だけのデータセットを構築しました。
2. Indexingに対し、Semantic Chunking
RAGは、主にIndexing, Retrieval, Generationの3ステップに分けることが出来ます。
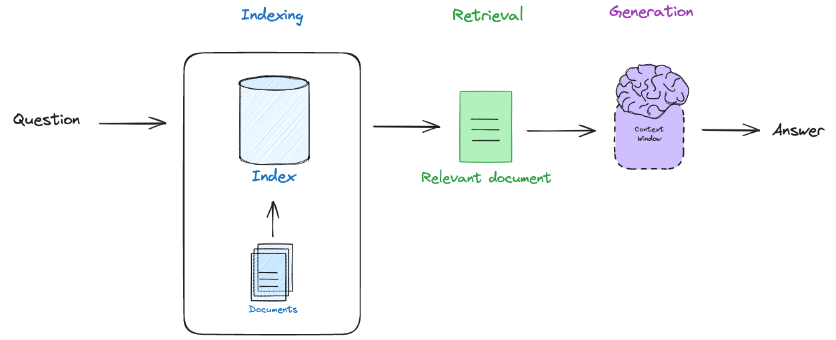
画像出典:RAG from scratch: Overview
この中で、まずIndexingに対し、Chunk Optimizationの一つであるSemantic Chunkingを行いました。
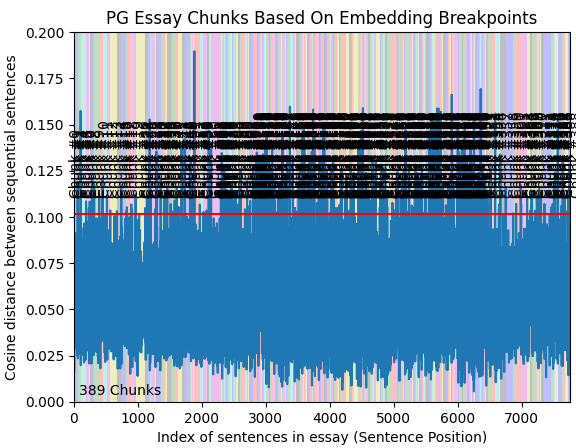
Semantic Chunkingは与えられた文章に対し、まずEmbeddingを行います。その後、各文と次の文との類似度を比較し、大きく異なる箇所でChunk分割を行います。
実際に行った結果、以下のように389Chunkに分割されました。X軸が文のID(文書の順番)、Y軸がCos類似度になり、色ごとで文章が分割されています。
3. Retrievalに対し、Multi-query
次に、Retrievalに対し、Multi-queryという手法を追加しました。
これは、与えられた問い (クエリ) に対し、LLMでクエリを言い換えて複数作成し、それぞれのクエリで文書検索を行った後に、結合してLLMに回答させるというものです。
この方法を用いることで、単純に1つのクエリだけで文書検索を行うより精度向上を図ることが出来ました。
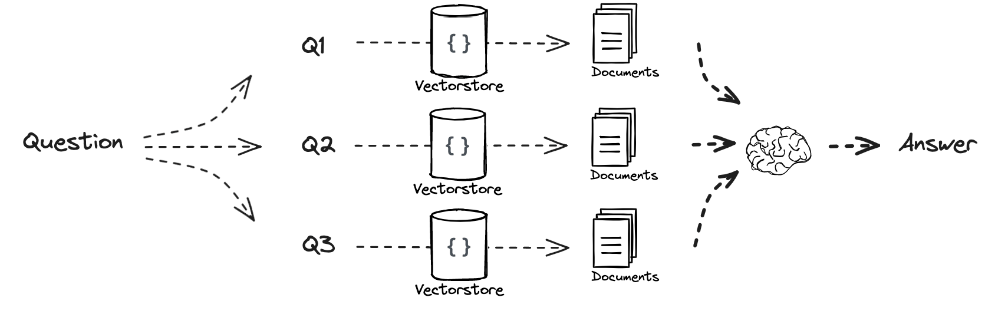
画像出典:RAG from scratch: Query Translation (Multi-Query)
4. プロンプトの工夫
今回は与えられたテキストからの情報のみで50トークン以内で回答するという制約があるため、プロンプトも非常に重要となっていました。そこで、試行錯誤の上で以下のようなプロンプトを与えて回答させました。
prompt_template = """あなたは正確性の高いQAシステムです。
事前知識ではなく、常に提供されたコンテキスト情報を使用して質問に回答してください。
以下のルールに従って回答してください。:
1. 事前知識は使わず、コンテキストから得られる情報のみを使用して回答してください。
2. 回答内で指定されたコンテキストを直接参照しないでください。
3. 「コンテキストに基づいて、...」や「コンテキスト情報は...」、またはそれに類するような記述は避けてください。
4. 回答は50トークン以内で簡潔に回答してください。
5. コンテキストから具体的な回答ができない場合は「分かりません」と回答してください。
コンテキスト: {context}
質問: {question}
回答:"""
5. 出力結果を再度LLMで加工
4のプロンプトで実行しても、50トークンに収まらないことがありました。そこで、コンペのディスカッションで提案していた方のスクリプトを参考に、50トークンを超えた場合のみ以下のプロンプトで再度回答生成する仕組みを追加することで、出力としました。
template="""以下のQuestionに対するAnswerの文章をEvidenceを元に50文字以内に収まるように簡潔に答え直してください。
50文字以内に収まらない場合、要約して一言で答えてください。
回答だけを答えてください。
f"Question: {problem}\n\n"
f"Answer: {full_answer}\n"
f"Evidence: {evidence}\n"
回答:"""
反省
今回のコンペでは、上記の手法でもメダル圏内に入ることが出来ませんでした。
反省として、まずData Cleaningが良くなかったかと考えています。今回は各小説が与えられている中で、本文だけ抽出してしまう形では何の小説の話なのかなど分からなくなっています。なので、タイトルや著者などのメタデータも与えられる形にした方が良かったかもしれないです。
もう一つとして、Semantic Chunkingがそもそも良くなかったかもしれないです。別の方のSolutionなどを見ると、検索に引っかかった文を含んでいる小説を丸ごとLLMに与えていました。今回のような小説について回答させる場合、小説を丸ごと与える方が前後情報を獲得しやすくて良かったかもしれないです。
感想
メダル圏内に入ることはできなかったですが、RAGの多くの手法を実装して試すことができ、非常に勉強になりました。今後RAGは多くの場で必要な技術となると思うので、定期的にキャッチアップしていきたいです。
コンペお疲れさまでした!
Discussion