🍘
データ分析でのEDAチートシート(python/基本編)※随時更新
EDAでよく使うものをまとめていきます。
必要ライブラリのインポート
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
データファイル(csv)をdataframeとして読み込む
df = pd.read_csv("path_file.csv")
データセットのカラム確認
df.columns
"""
Index(['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'], dtype='object')
"""
手軽に欠損値の数を確認
data.isna().sum()
"""
sepal_length 0
sepal_width 0
petal_length 0
petal_width 0
species 0
dtype: int64
"""
カラムの統計的な要約を確認
総数、平均、標準偏差、最小値、四分位数、最大値を表示してくれる
df.describe()
"""
sepal_length sepal_width petal_length petal_width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.057333 3.758000 1.199333
std 0.828066 0.435866 1.765298 0.762238
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
"""
※当然だがデフォルトでは数値データしか表示されない。
数値データ以外も含めたい場合はinclude="all"を指定する。
df.describe(include="all")
"""
sepal_length sepal_width petal_length petal_width species
count 150.000000 150.000000 150.000000 150.000000 150
unique NaN NaN NaN NaN 3
top NaN NaN NaN NaN setosa
freq NaN NaN NaN NaN 50
mean 5.843333 3.057333 3.758000 1.199333 NaN
std 0.828066 0.435866 1.765298 0.762238 NaN
min 4.300000 2.000000 1.000000 0.100000 NaN
25% 5.100000 2.800000 1.600000 0.300000 NaN
50% 5.800000 3.000000 4.350000 1.300000 NaN
75% 6.400000 3.300000 5.100000 1.800000 NaN
max 7.900000 4.400000 6.900000 2.500000 NaN
"""
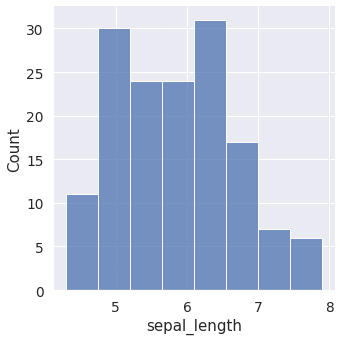
ヒストグラムで分布を確認
bins(階級数)はデータが過不足なく表示されるような値を設定する。
※ スタージェスの公式[1]で大体の階級数を求めても良い。
sns.displot(df["column1"], bins=8)
plt.show()
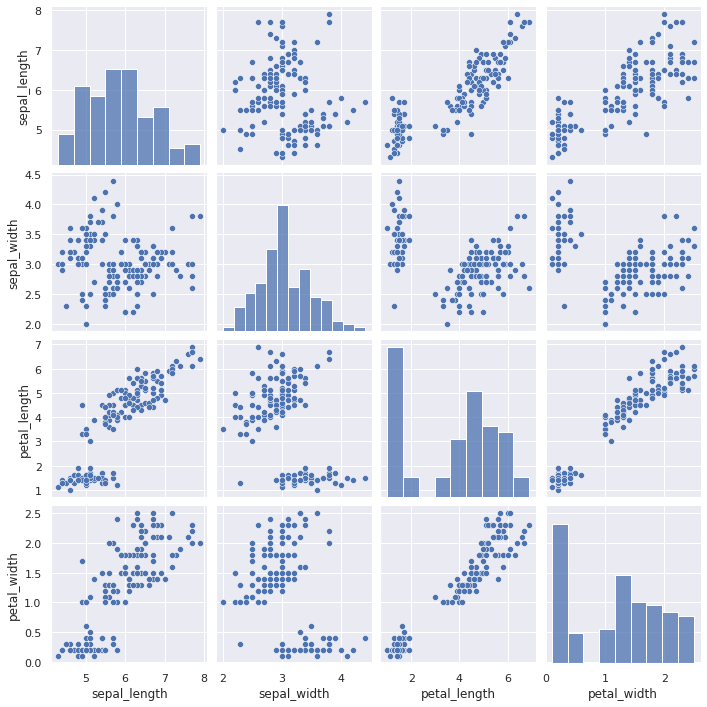
散布図で複数要素のペア間の関係を確認
sns.pairplot(df)
plt.show()
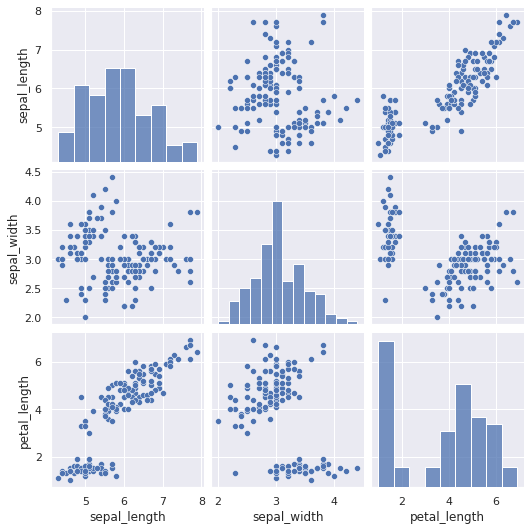
要素を指定することも可能
cols = ["sepal_length", "sepal_width", "petal_length"]
sns.pairplot(df[cols])
plt.show();
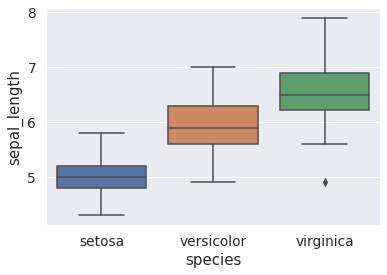
箱ひげ図でデータのばらつきを確認
sns.boxplot(x="species", y="sepal_length", data=df)
plt.show()
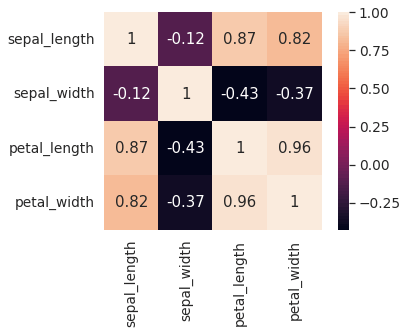
ヒートマップでデータ間の相関を確認する
corrmat = df.corr()
sns.heatmap(corrmat, square=True);
plt.show()
Discussion