Azure AI ServiceにベクトルDBを構築する
主なフロー
- Azure Storage accountsを作成
- データをBlob serviceにアップロード
- AI SearviceでBlob serviceからデータをインポート
前提条件
・Azure OpenAIのアカウントを作成済み
・text-embedding-ada-002 のデプロイ済み
text-embedding-ada-002のデプロイ方法:
Azure Storage accountsを作成
Azure PortalでStorage accountを検索して開く
格納用の新規アカウントを作成

詳細:
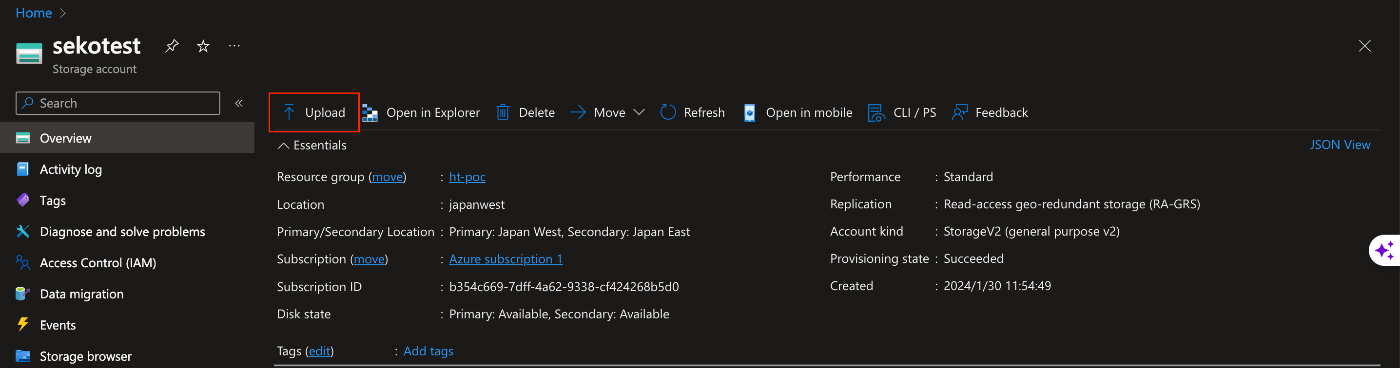
Azure Storage accountsにデータをアップロード
OverviewのUploadをクリック
_
右側にウィンドウが出るので、下画像のcreateボタンを押し新規コンテナを作成する。
その後格納したいデータ(csvなど)をアップロード

ベクトル化する際にCSVであっても、フィールド属性(カラム)関係なく取り込まれます。
例えば、id, nameというカラムがあったとしてもid+nameで検索対象になるイメージです。
カラムごとにわけて取り込むやり方があれば追記します。
AI Serviceにデータをインポートしベクトル化(Indexの作成)
-
Portal上でAzure AI Searviceに移動
左側のメニューからAI Searchを選択後、中央の画面でCreateボタンを押しSearch serviceを作成

-
データをインポート
Search serviceを作成後に中央の画面から「Import and vectoraize data」をクリック
先ほど作成したBlob storage account, Blob storage containerを選択して作成

詳細:
クイックスタート: 垂直統合 (プレビュー)
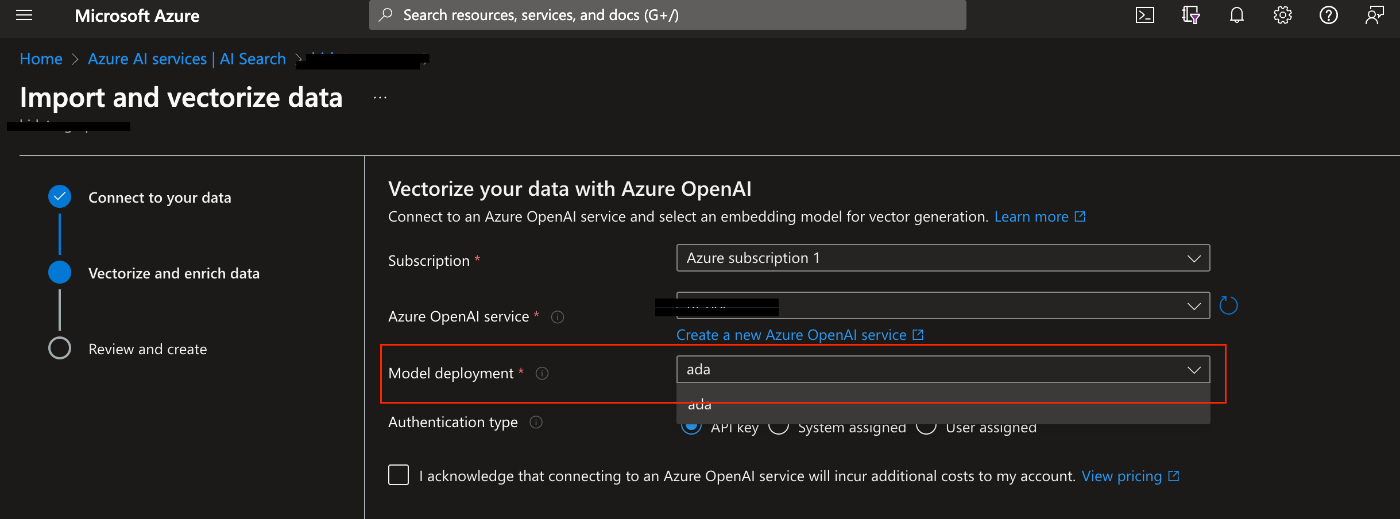
- ベクトル化するためのモデルを選択
・モデル選択欄
Azure OpenAIでデプロイしたemdeddingする用のモデルを選択
(今回はtext-embedding-ada-002)
・Advanced ranking and relevancy
今回はsemantic rankerを使うのでオンにする
・最後まで進みCreate
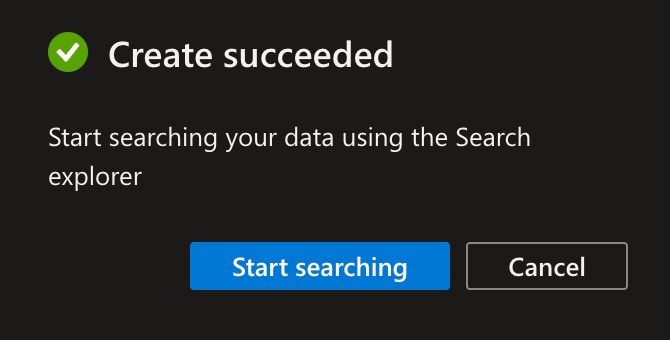
成功すると下記の画面が出てくるのでそのままstart Searching
Demo appをつくってみる
遷移先の画面でCreate Demo appをクリック
最終的にhtmlがダウンロードされて、ファイルを開くとサンプルアプリが使えるので
実際に文章をRetrieveできているのかを確認できます。

Indexの各種設定
ベクトル化されたデータを格納しているIndexの設定をしていきます。
インデックスに下記項目があるのでみていきます。
Fieldsについて
・chunkはインポートしたデータ(CSVで入れた場合は、セルの値)
・titleはインポートしたファイル名
scoring profileについて
特定のフィールド(カラム)に重みづけするすることができる。
例えば、「タイトル」フィールドで見つかった一致を、「本文」で見つかった同じ一致よりも高くすることができる。
今回は特に指定しません。
Semantic rankerの説明
Semantic configrationsの説明の前にSemantic rankerの要素について説明します。
Semantic Rankerとは:
ハイブリッド検索の際に、クエリの意味や意図に基づいて結果をリランキングする仕組み
Semantic RankerでリランキングすることでRAGの精度が向上するようです。
詳細:
Semantic rankerの要素
・semantic caption:
textとhighlightとして返ってくる。
chunkの中から、クエリに直接関連のある部分を抽出して、さらに重要部分をハイライトしてくれます。
・semantic answer:
Retrieveしてきたデータを元に、クエリに対する簡単な回答を返してくれる。
機械読解モデルを使用して最適な答えを認識し、該当箇所を選択してくれる。
queryの際にパラメータを付与することでanswerを取得できます。
答えが不定の場合は"@search.answers"に空の配列で帰ってきます。
複数の回答を取得することができます。
詳細:
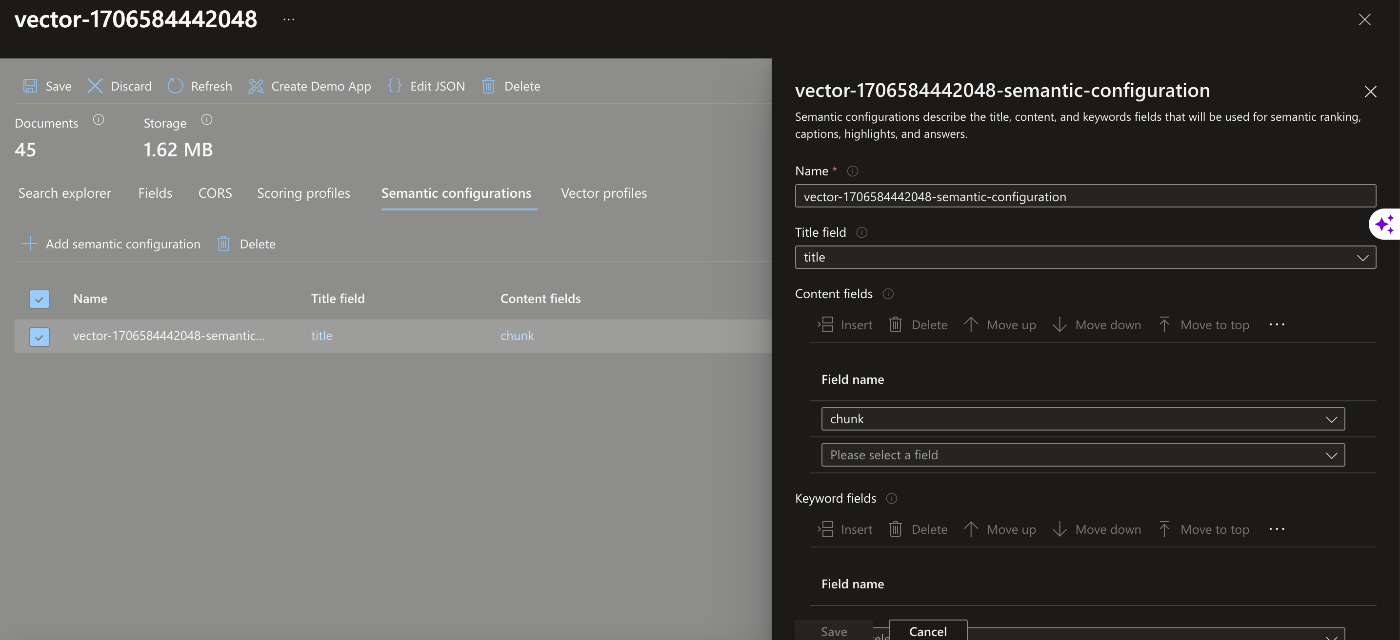
Semantic configrationsについて
Semantic Configがない場合はまず作成します。
・設定する部分
Name
Title: titleフィールドに設定(ファイル名になります)
ContentField: chunk
KeywordField: 今回は設定しません
注意
AzureのBlobからデータを読み込むと言語アナライザーがデフォルトの英語になっているので
日本語に変更する必要があるみたいです
参考: