Azure AI SearchにベクトルデータをAPI経由でアップロードする
前提
・データをベクトル化している(次元数2048以下)
・Azure Open AIにembeddingモデル(ada-2)をデプロイしている
全体の流れ
- Azureにデータのインポート
- データの検索
Azureの使い方
・Azure Portalというブラウザ上のサービスから操作する
アップロードの手段
- Portal(Blob)経由:
言語アナライザーが日本語にならないのが問題
言語アナライザーとは、キーワード検索のために文章をトークンという単位に分割する際に使用される
- API経由
言語アナライザーを日本語にできるので今回はこちら
アップロードの手順(ベクトル化済みデータ)
- Indexを作成
- データをAPI経由でPost
Indexの作成
Portal上からAI Search➡︎リソースを作成して移動

リソース(箱)の下にデータを置いています
Indexを作成
Indexとはベクトルデータを入れるための箱
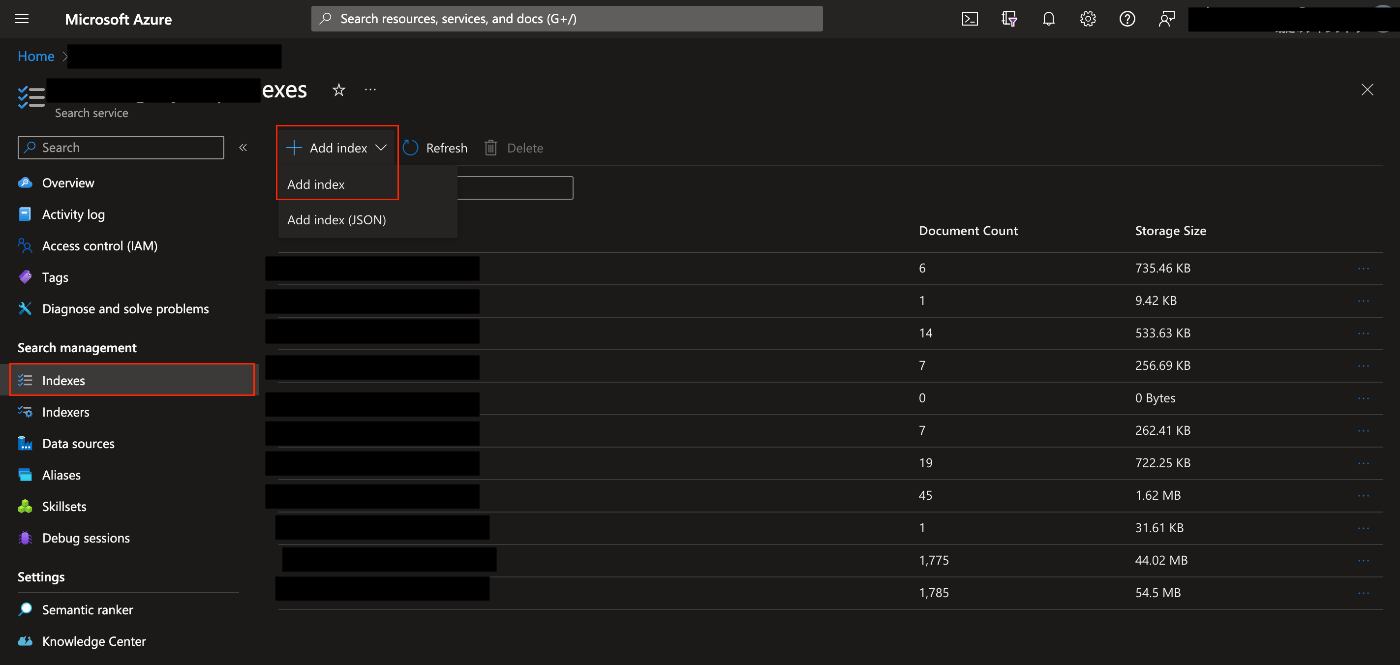
- 左側のツールバーから「Indexes」を選択
- AddIndexを選択
Fieldの設定
Index上にフィールド(カラム)を作成
- 左側のAdd fieldを選択
- 右側にFieldの設定が出てくるので入力
ここで主に下記のフィールドを作成
(入れるデータに合わせて作成してください)
・chunk: String
・title: String
・summary: String
・vector:Collection(Edm.Single)
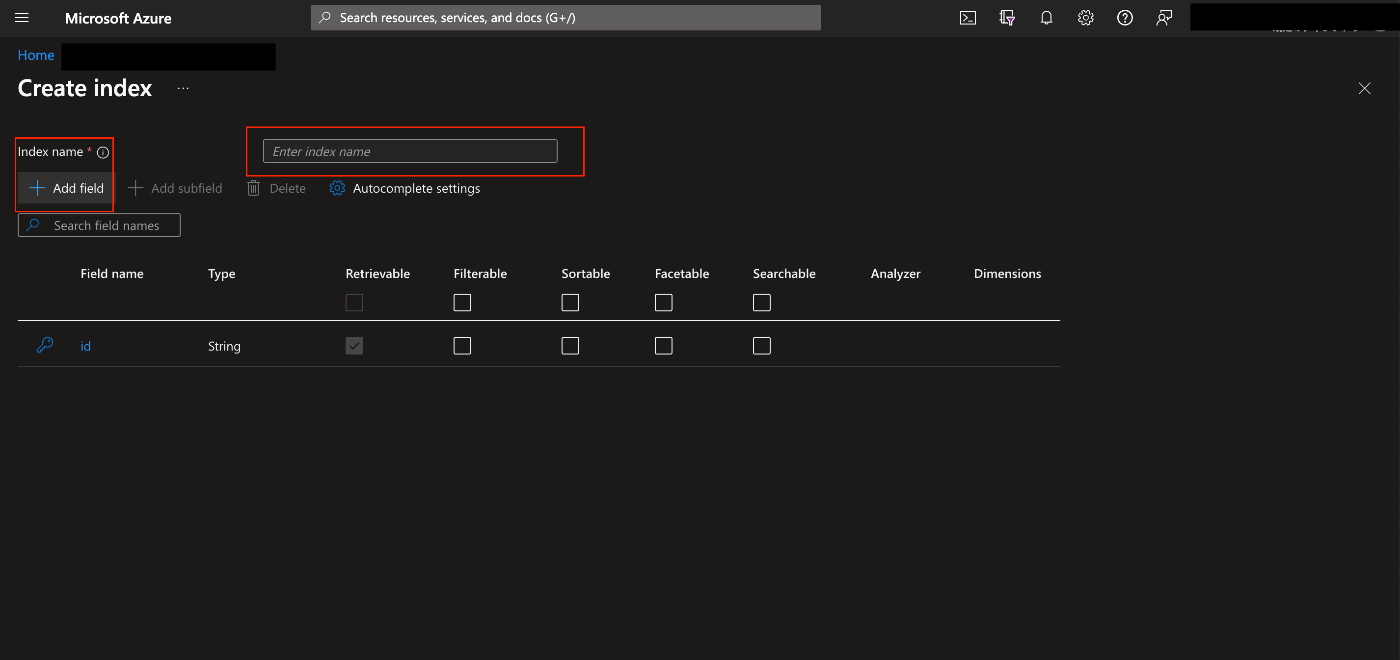
・Configure attributesについて
-
Retrievable:クエリを叩いた際に取得可能か
➡︎今回は全てチェック -
Filterable:クエリを叩く際に検索結果をフィルター可能にするか
➡︎今回は全てチェックしない -
Sortable:ソート可能にするか
➡︎今回は全てチェックしない -
Facetable:フィルターの一種
➡︎今回は全てチェックしない
詳細:
https://shinodogg.com/2021/03/18/facets-and-faceted-search-making-every-attribute-count/
https://learn.microsoft.com/en-us/dotnet/api/microsoft.azure.search.models.field.isfacetable?view=azure-dotnet-legacy -
Searchable:全文検索(キーワード検索)を可能にするか
クエリを叩く時に 「"search": 」という項目があり、ここに設定した文字列で検索が行われる
➡︎今回は全てチェック
言語アナライザーの設定
Searchableをチェックすると言語アナライザーの選択画面が出てくるので
日本語に設定
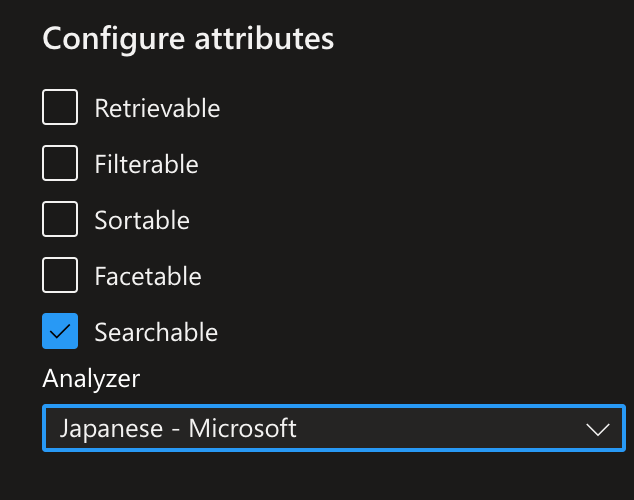
vectorデータの設定
・Configure attributes
➡︎Retrievableに設定
・Dimensions
➡︎
ベクトル化したデータの次元数と必ず同じ数を入力
・Vector algorithm
➡︎下記のように設定
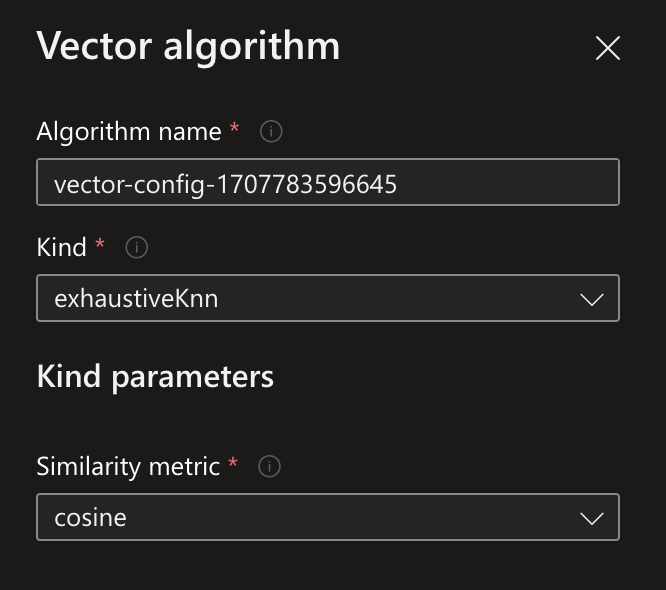
アルゴリズムの詳細:
exhaustive knnは少量のデータの探索に有効。精度高いが計算量が多くなるので時間かかる
ざっくりhnswはその逆
数万件くらいのデータならexhaustive knnの方が精度が高く良さそう
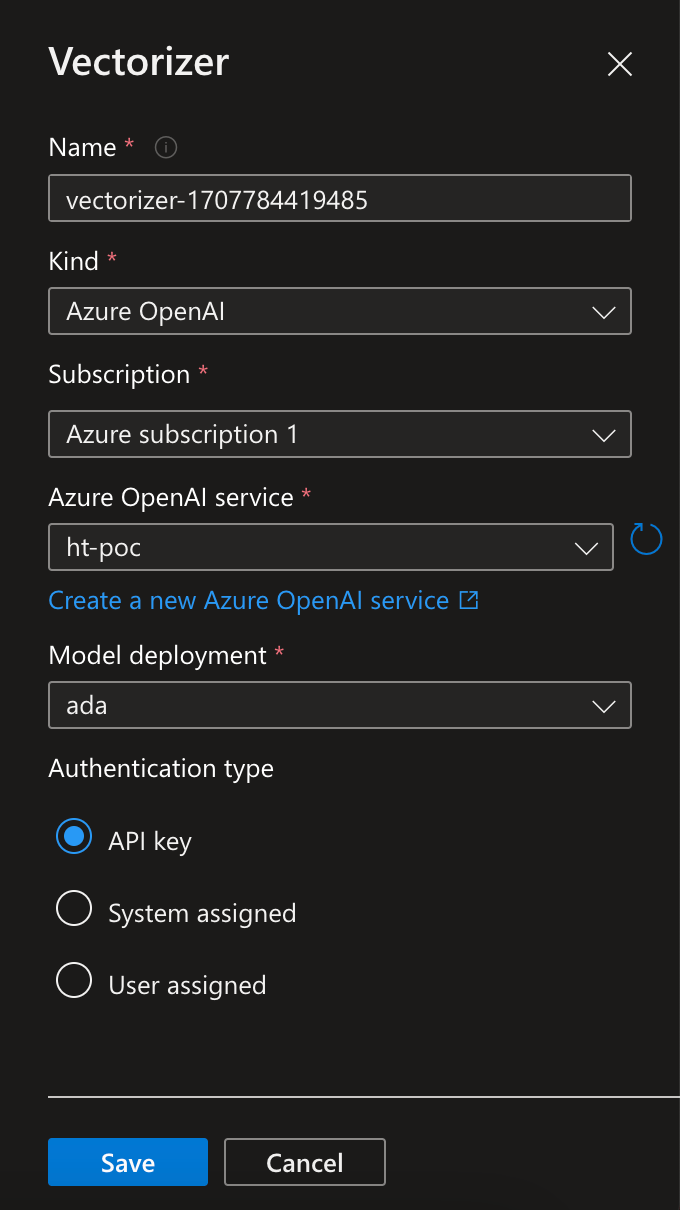
・vectorizerの設定
➡︎
queryをベクトル化するときの設定です
下記のように設定
新しいモデルが出たら、Azure OpenAI serviceに別途モデルをデプロイする必要があります。
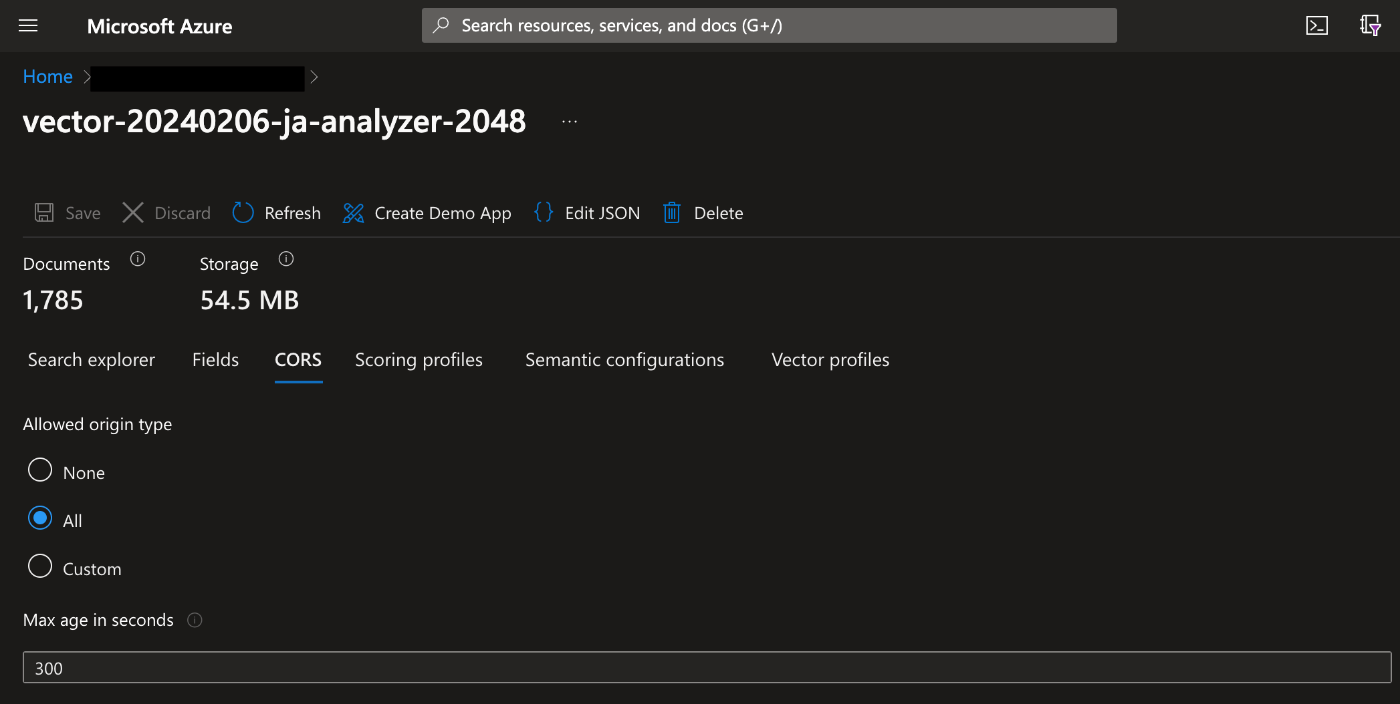
CORSの設定
特にURLなど公開しないので、Allowed origin typeをALLに設定
Scoring profilesの設定
今回は設定しない
特定のフィールドに重みづけできたりします
Semantic Configrationの設定
セマンティックランカーを使用する際の設定
-
Create
-
Title field
➡︎Title -
Content fields
➡︎
summary, chunkを追加 -
Keyword fields
➡︎
今回は特定のキーワードを格納したテーブルはないので今回はスルー
設定する場合はkeywordのリストを格納したカラムを設定 -
Save
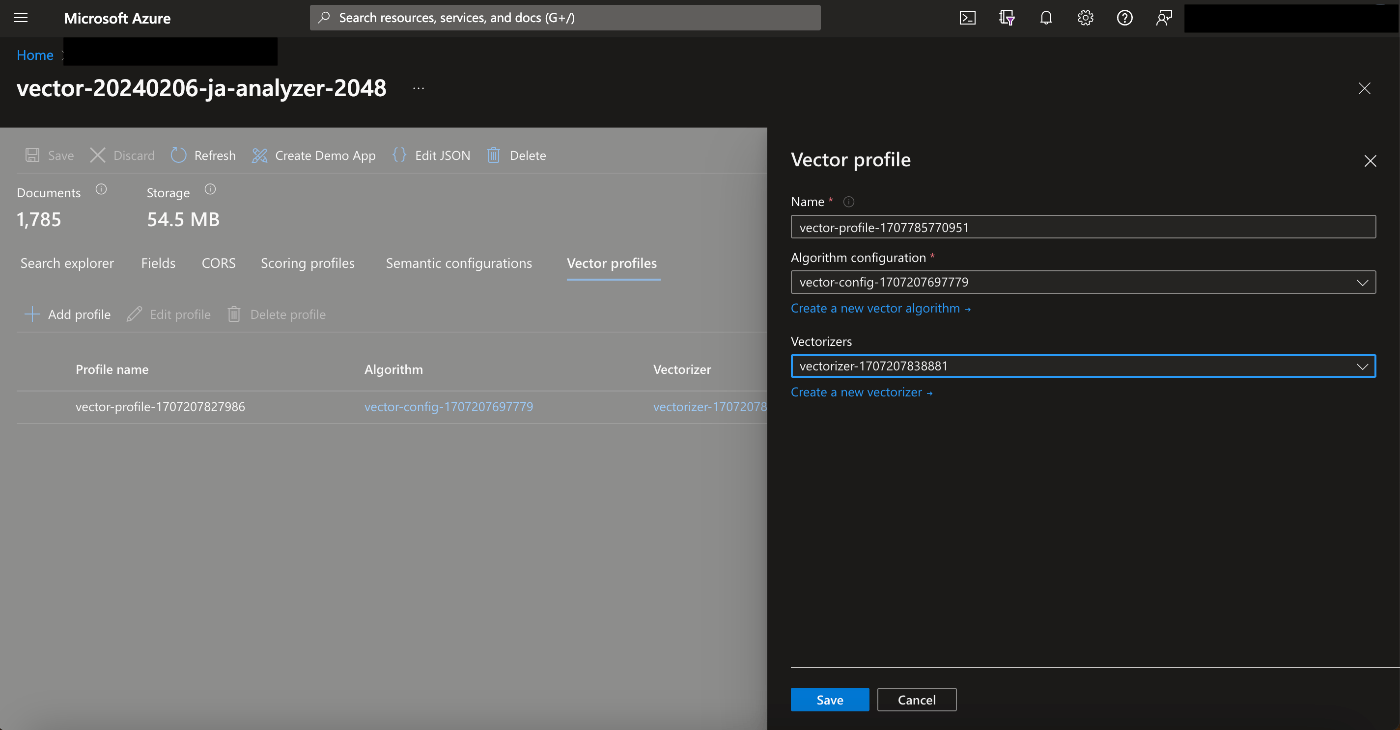
VectorProfile
queryをベクトル化する設定
- 左側からAddprofile
- 右側の編集タブで先ほど作成したvectorizerを選択
データをAPI経由で格納
前提
・事前にデータをベクトル化してCSV形式にしてカラムを追加しておく
今回の例だと
id, title, summary, chunk, embeddings(ベクトル値)のカラムを用意しておき、
embeddingsなどのカラムにベクトル化したデータの数値を格納しておく
詳細は別途アップロード予定
データアップロード手順
別途アップロード予定
検索結果の取得
別途アップロード予定
Discussion