LangGraph × Azure OpenAIで構築するBicepコード生成アプリの技術解説
LangGraph × Azure OpenAIで構築するBicepコード生成アプリの技術解説
導入
本記事は、Microsoft Global Hackathon 2025 にチームで出場した際に開発したアプリケーションの技術的な解説記事です。アプリケーションの概要やハッカソンに出た際の話は以下の記事をご覧ください。
LangGraphとAzure OpenAIでBicep自動生成チャットを作った
GitHub リポジトリはこちら
はじめに
インフラのコード化(IaC)は便利ですが、ゼロからBicepやTerraformを書き始めるのは手間がかかります。用途・スケール・可用性といった前提を聞き漏らしたり、リソース名や構成の“当たり”が出るまで時間を使ってしまうのはよくある話です。
「ここをLLMに任せられればいいのに」と思ったことがある人も多いのではないでしょうか。
ただし、実際にLLMに丸投げすると次のような課題が出てきます。
- 一度に大量の質問をされて答えが粗くなる
- lintに通らないコードが出てくる
- 再生成を人間が手動で制御する必要がある
- パラメータの指定がおかしい
自分もLLMを使ってBicepを生成して遊んでみたりしたのですが、思ったようなものが生成されず結局自分で書いた方が良かったなーってなりがちです。
この課題を解決するために、LangGraphを使って「会話からBicepを生成するパイプライン」を作ってみました。
TL;DR
- LangGraphを使った有限ステートマシン設計により、「対話→要件サマリ→コード生成→lint→自動再生成→完成」という流れを自動で進行。
- lint結果をLLMに渡す軽量フィードバック設計で、トークン消費を抑えつつ再現性を確保。
- フロントエンドUXの工夫(自動前進、進捗バッジ、即編集)により「待たされ感」を軽減。
- 最小構成は FastAPI + Next.js + LangGraph + Azure OpenAI。API化しているのでCI/CDや他システム連携にも応用可能。
本記事では、アプリの機能紹介からLangGraph設計の工夫、API化による拡張性までを解説します。
1. アプリの概要とゴール
今回作ったのは、会話を通じて要件を整理し、そのままBicepコードを自動生成してくれるチャットアプリケーションです。
ユーザーは「Webアプリを作りたい」「冗長構成にしたい」「XXのサービスの挙動を確認したい」など、自然言語で答えるだけで、裏側でLangGraphが会話を状態管理しながら以下の流れを自動で進めます。
-
要件ヒアリング
- 一問一答形式で、用途・スケール・可用性など必要な前提を少しずつ質問。
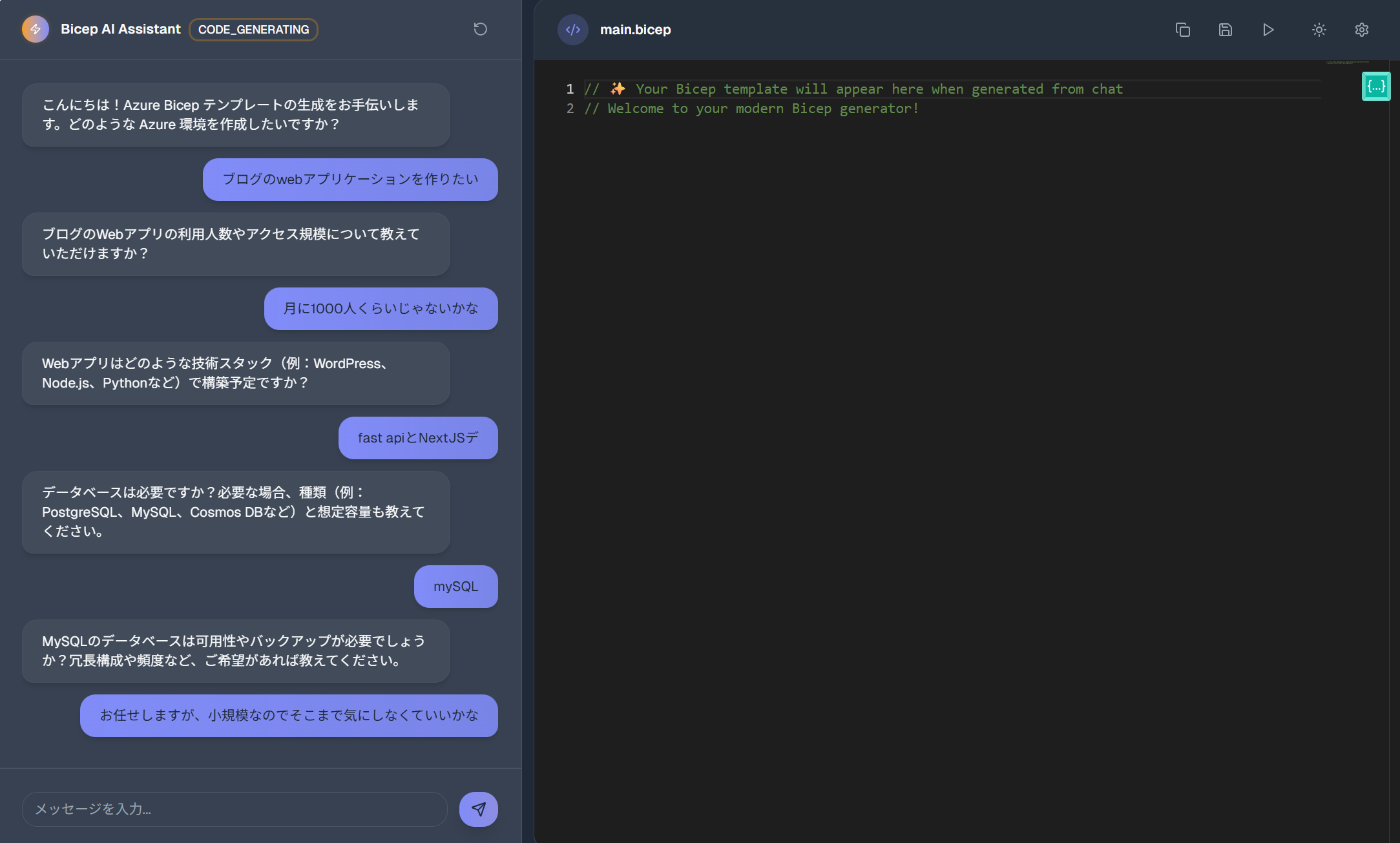
- 一問一答形式で、用途・スケール・可用性など必要な前提を少しずつ質問。
-
要件サマリ生成
- 全ての会話履歴をまとめて構造化し、次のフェーズで使えるように整理。
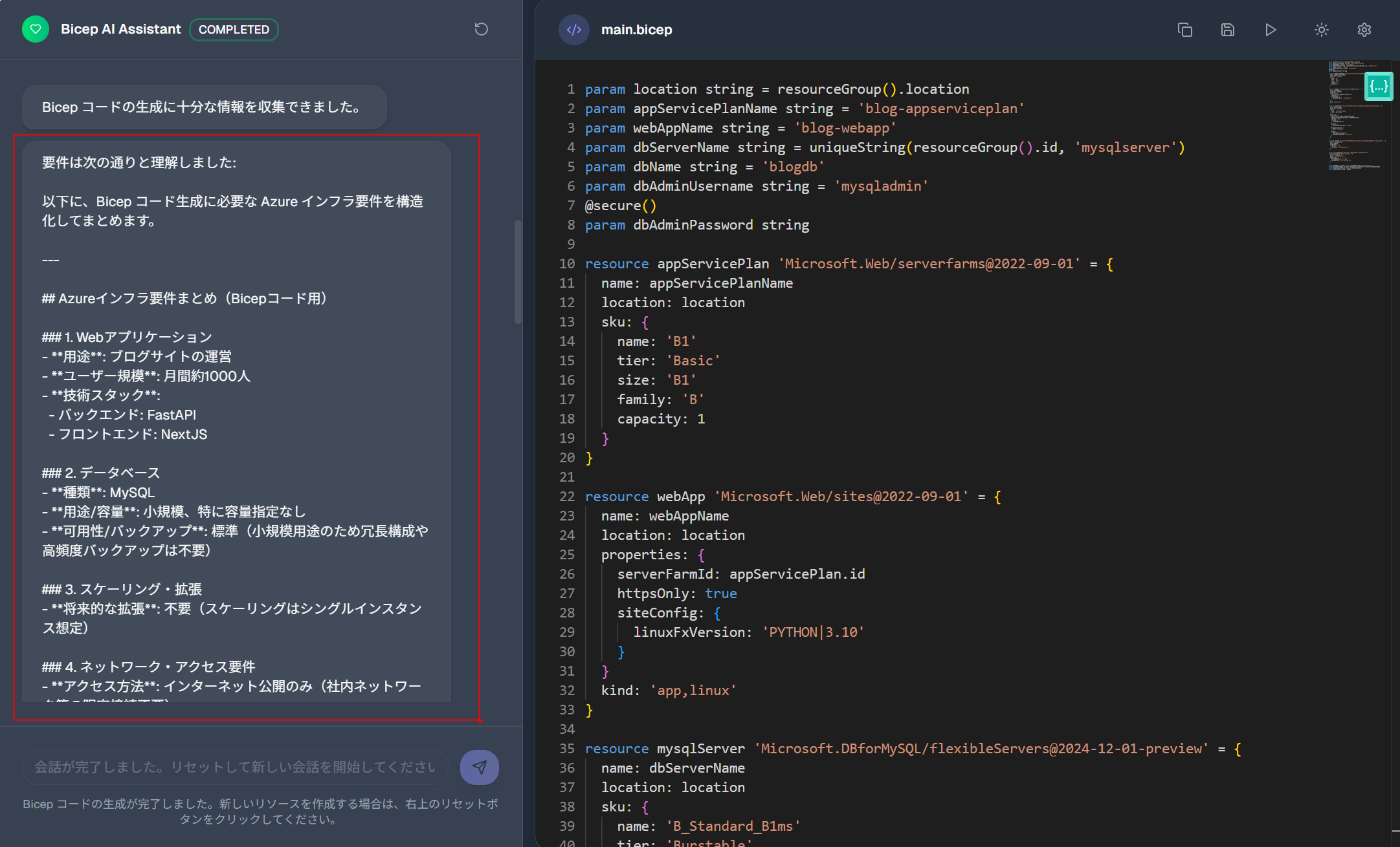
- 全ての会話履歴をまとめて構造化し、次のフェーズで使えるように整理。
-
Bicepコード生成
- Azure OpenAIを使ってコードを生成。
-
lint検証と自動再生成
- CLIの
bicep lintを実行し、エラーや警告があればその抜粋を再度LLMに渡し、自動で再生成。このとき、MicrosoftのDocsを参照してエラーを直す - 最大リトライ回数まで繰り返し。
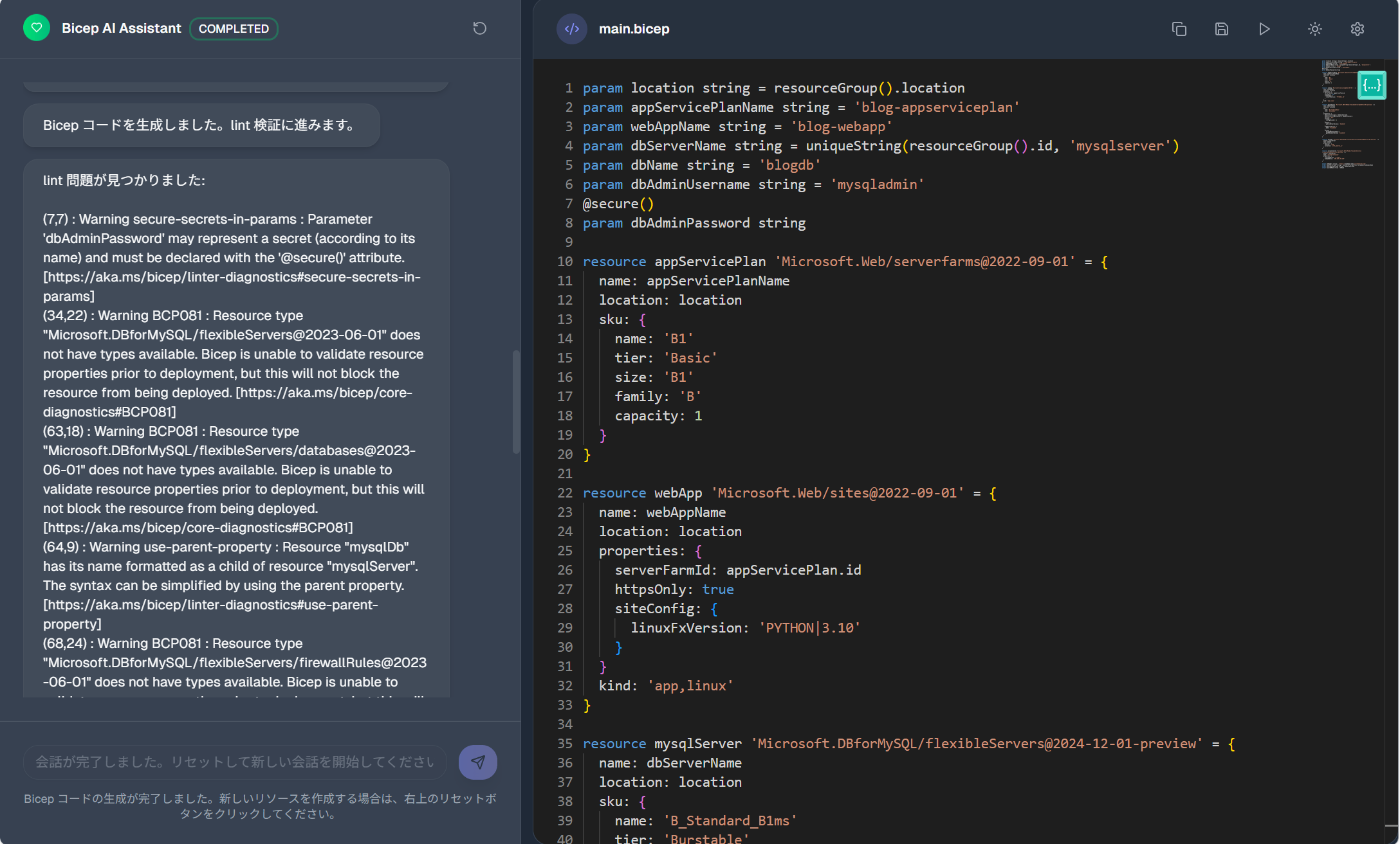
- CLIの
-
完成コード提示
- 問題がなければユーザーにBicepを返し、その場で編集・再利用可能。

- 問題がなければユーザーにBicepを返し、その場で編集・再利用可能。
ゴール
-
「会話しているだけで要件が整理されて、いちいち細かいことを考えないで検証環境とかPoC環境を作れる」体験を実現すること。
社員さんの話を聞いていても、 簡単な検証環境を作るのに結構時間をとられがちで、早く検証したいのに面倒だという声がちらほらあったので、IaCのたたき台としても使えるものが作れればと思い開発しました。
2. なぜ LangGraph を選んだか
本アプリケーションのように「会話 → 要件整理 → コード生成 → 検証 → 再生成」という複数フェーズを踏む処理では、単発プロンプトや簡単なチェーンでは限界があります。そのため、既存のライブラリを使うことを検討しました。
今回、以下の3つを候補として検討しました。
| 選択肢 | 強み | 課題 | 総評 |
|---|---|---|---|
| Semantic Kernel | スキルやプランニング機能で複雑なワークフローを自動生成できる | 最小構成にはオーバーエンジニアリング。 | 高度なシナリオには有効だが、シンプルなIaC生成には重い |
| 自作ステートマシン | 完全に自由度が高い。Python/TSでif/elseを書けば柔軟に制御可能 | フェーズ増加でコードが爆発。ログ管理・セッション復元・チェックポイントを全部自作する必要あり。 | 小規模なら可だが、拡張性・保守性に欠ける |
| LangGraph | LLMアプリ向けに設計されたステートマシン。ノードとエッジで状態遷移を宣言的に記述できる。 | 学習コストは少し必要。まだ事例が少なく若干情報が少ない | シンプルな実装が短期間で可能 |
今回の結論
「Semantic Kernelだと重すぎる」「自作FSMだと辛すぎる」——その中間にあるLangGraphが最適解でした。
3. システム全体アーキテクチャ
今回のシステムは、フロントエンドのチャットUIとコードエディタ、バックエンドのLangGraphパイプライン、そしてAzure OpenAIを組み合わせた最小構成です。
全体像
フロントエンド
- Next.js 14 (App Router) + shadcn/ui で構築。
- Monaco Editor を組み込み、生成されたBicepをその場で編集可能。
-
requires_user_input=falseを受けると 800ms 後に自動で API を再呼び出し、裏で勝手に進んでいる感を演出。 - i18next を利用して ja/en切り替えが可能。
バックエンド
-
FastAPI で
chat/resetの2つのエンドポイントを提供。 - LangGraph のノードを以下のフェーズで構成:
- hearing(要件ヒアリング)
- summarizing(要件サマリ生成)
- code_generation(Bicep生成/再生成)
- code_validation(lint実行)
- completed(最終出力)
- 状態は SQLiteSaver に保存(なければ MemorySaver)。スレッド単位で分離できるため、複数ユーザー/複数会話の同時進行も可能。
LLM(Azure OpenAI)
-
AzureChatOpenAIを利用。 - hearing フェーズでは一問一答を生成、summarizing フェーズでは直近ログを要約。
- code_generation フェーズでは要件サマリと lint 結果を統合し、再現性のあるBicepを生成。
まとめ
この構成のポイントは、LLMに丸投げせず、LangGraphが全体の制御になっている点です。
ユーザーは会話するだけで、裏側ではLangGraphがFSMとして遷移を制御し、最終的にBicepコードを仕上げてくれます。
4. フェーズ設計とステートマシン
本アプリは LangGraph を用いた有限ステートマシンとして設計しています。会話が止まっても自動で後続フェーズへ前進し、要件ヒアリング → サマリ化 → コード生成 → lint検証 →自動再生成 → 完了までを一気通貫で回します。
4.1 フェーズ一覧と遷移
| Phase | 主目的 | 入力 | 出力 | 自動遷移 | 備考 |
|---|---|---|---|---|---|
hearing |
一問一答で要件深掘り | 直近会話 | 次の質問 | 条件付き | 上限 MAX_HEARING_CALLS
|
summarizing |
会話全体を要件に集約 | 会話履歴 | requirement_summary |
Yes | |
code_generation |
Bicep 生成/再生成 | 要約、旧コード、lint抜粋、Microsoft Docs | Bicep | Yes | 差分パッチではなく全文再構成方針 |
code_validation |
bicep lint 実行と合否判定 |
Bicep | lint出力 / pass判定 | Yes | 判定はerror/warning
|
completed |
完了通知と成果物提示 | 最終 state | 完了メッセージ+Bicep | No | ここでUIに提示して編集可能 |
-
hearing以外は 自動前進 (auto-advance)。UI はレスポンスのrequires_user_input=falseを受けて 800ms 後に空メッセージで再呼び出し、連続フェーズをスムーズに実行します。
4.2 再生成ループ(lintフィードバック駆動+Microsoft Learn参照)
code_generation → code_validation を1サイクルとして、lintにエラー/警告が残る限り再生成を回します。再生成の上限は MAX_REGEN_CALLS で制御し、暴走を防止します。
- Microsoft Learn公式ドキュメント参照機能
lintエラーが発生すると、該当リソースタイプの公式ドキュメントを自動取得
https://learn.microsoft.com/en-us/azure/templates/{resource_type}/?pivots=deployment-language-bicep から最新情報を取得し、エラー箇所・ドキュメント・コードブロックをLLMに渡し、具体的な修正ガイダンスを生成します。
lintの合否判定をLLMに委ねず、CLI結果の最小限の抜粋のみをLLMに返すことで、トークン消費と変動を抑制します。Microsoft公式ドキュメントを参照することで、古い情報や非推奨パターンではなく、最新のベストプラクティスに基づいたコード生成を実現しています。差分パッチ方式は依存や命名の整合性が崩れやすいため、全文再構成を採用しています。
4.3 State
LangGraphの State は下記のような構成で運用します。
messages: List[AnyMessage]
n_callings: int
bicep_code: str
lint_output: str
validation_passed: bool
code_regen_count: int
phase: str
requirement_summary: str
language: str
-
requirement_summaryを中間アセットとして保持することで、以降のプロンプト長を安定化させ、コストとブレを低減します。 -
lint_outputは要点のみをプロンプトに戻し、再生成の素材に使います。
5. プロンプト設計の工夫
LangGraph の強みは「状態ごとにプロンプトを切り替えられる」ことです。
ここでは実際に使ったプロンプトの中から、特徴的なものを紹介します。
5.1 Hearing(要件ヒアリング)
一問一答で Azure 上の環境構築に必要な情報を引き出すためのプロンプト。
短く簡潔な質問に限定し、必要な場合は背景を掘り下げるようにしています。
{
"system_role": "## 役割\nあなたは優秀な要件ヒアリング担当者です。ユーザーの要件を深掘りして、必要な情報を引き出すための質問を生成するのがあなたの役割です。\n\n## 目的\nユーザーは、最終的に Azure 上に環境を構築しようとしています。ヒアリング項目はあくまでも、Azure 上に環境を構築するための bicep コード生成に必要な情報に限定してください。\n\n## 考え方\nまだ背景が明確になっていない場合には、まずは背景を明確にするための質問をしてください。",
"user_instruction": "ユーザーの要件を深掘りするための質問をしてください。ただし、質問は一つだけにしてください。分量は短く、簡潔にしてください。",
"fallback_question": "要件をもう少し教えてください。"
}
5.2 Should Hear Again(ヒアリング継続判定)
「もう十分要件が集まったか?」を LLM に yes/no でだけ答えさせるプロンプト。
会話を切り上げるタイミングをシンプルに制御できます。
{
"system_instruction": "あなたの役割は、これまでの会話に、Bicep を使って要求された Azure 環境を生成するために十分で具体的な要件が含まれているかどうかを判断することです。80% ルールを適用してください: 他のエンジニアが大体 80% の確率で同じ環境を構築する場合、要件は十分とマークしてください。要件が十分であれば、「yes」のみで返信してください。不十分であれば、「no」のみで返信してください。他のテキストは含めないでください。",
"user_instruction": "与えられた要件は、Bicep を使って要求された Azure 環境を生成するのに十分ですか? 'yes' または 'no' のみで答えてください。"
},
5.3 Code Generation(初回 / 再生成 + Microsoft Learn参照)
Bicep コード生成では「初回」と「再生成」でプロンプトを分けています。
- 初回は要件サマリを根拠にゼロから生成
- 再生成は既存コード+lint 結果+Microsoft公式ドキュメントを基に全文再構成
Microsoft Learn参照の仕組み:
# lintエラーから該当リソースタイプのドキュメントを自動取得
docs_url = f"https://learn.microsoft.com/en-us/azure/templates/{resource_type.lower()}/?pivots=deployment-language-bicep"
docs_content = fetch_url_content(docs_url, query_selector='div[data-pivot="deployment-language-bicep"]')
# エラー内容・コード・公式ドキュメントをLLMに渡してガイダンス生成
messages = [{
"role": "user",
"content": f"## Lint message\n{lint_message}\n## Bicep code\n{code_block}\n## Learn doc:\n{docs_content}\n"
}]
```json
{
"system_initial": "あなたは熟練した Azure インフラエンジニアです。ユーザーの要件に基づき、最小で妥当かつ再利用しやすい Bicep コードを 1 ファイルで提示してください。出力は説明を含めず、```bicep で始まるコードブロックのみです。要件サマリ内の情報だけで不足があれば合理的なデフォルトを仮定してください。",
"user_initial": "Bicep コードを生成してください。説明・コメントは不要で、コードブロックのみで返してください。\n\n## 要件\n{requirement_summary}",
"system_regeneration": "あなたは熟練した Azure インフラエンジニアです。ユーザーの要件と提示された情報に基づき、致命的/重要な問題を解消しつつ、不要なリソース追加や過剰最適化を避けて Bicep コードを改良してください。\n以下の原則を必ず守ってください: \n1. 既存コードで既に妥当な部分は極力変更しない(diff を最小化)。\n2. lint / 要件サマリに基づく不足のみを補う。推測が必要な場合は最小構成で仮定。\n3. 出力はコードブロックのみ(説明・コメントは問題箇所への最小限のコメント以外不要)。\n4. 変更加筆が必須でない限りリソース名やパラメータ名を再命名しない。",
"user_regeneration": "最小修正で、改良後の Bicep コードを生成してください。説明・コメントは不要で、コードブロックのみで返してください。\n\n## 要件\n{requirement_summary}"
}
この仕組みにより、単なるlintエラーの修正ではなく、Microsoft公式ドキュメントに基づいた正確で最新のBicepコードを生成できます。
5.4 Summarize Requirements(要件サマリ化)
会話ログを整理して、Bicep 生成に必要な項目だけを構造化するプロンプト。
中間アセットとして保持し、後段のプロンプトを安定化させます。
{
"system_instruction": "あなたの役割は、ユーザーの要件を簡潔で構造化されたフォーマットにまとめることです。これまでの会話を踏まえ、Bicep コード生成に必要な Azure インフラ要件を抽出し、要約してください。",
"user_instruction": "ユーザーの要件を抽出しまとめてください。\n\n## 会話履歴\n{dialog_history}"
},
まとめ
- Hearing: 一問一答で必要な情報だけを抽出
- Should Hear Again: yes/no でフェーズを切り上げるシンプル判定
- Code Generation: 初回と再生成を明確に分け、安定した IaC を出力
- Summarize Requirements: 後続処理のための中間アセットを構築
これらのプロンプトを LangGraph のステートごとに適用することで、会話からコード生成までを安定して制御できるようになりました。
6. UX へのこだわり
今回はハッカソンに提出するということで見た目や使いやすさにもこだわりました。
6.1 自動前進(auto-advance)
- hearing フェーズ以外の応答には
requires_user_input=falseを付与。 - フロントはこれを検知すると、一定時間ごとに次フェーズへ進めます。
→ ユーザーは特に操作しなくても、フェーズがどんどん進んでいきます。Github Copilotをイメージして作りました。どんどんいちいちYes/Noとかを返す必要はないです。
// Chat UI の概念コード
if (!response.requires_user_input) {
setTimeout(async () => {
const resp = await sendMessageToAPI(""); // 空メッセージで次フェーズへ
processChatResponse(resp);
}, 800);
}
6.2 フェーズの可視化
- 画面上部に 進行中のフェーズバッジ(hearing / summarizing / code_generation / code_validation / completed)を配置。
→ 「今どこまで進んでいるのか」が一目で分かります。
6.3 コードとの即時インタラクション
- 生成された Bicep は Monaco Editor 上に表示され、そのまま編集可能。
- lint パス後はコピー/保存操作にすぐ繋げられます。
→ 簡単な修正や改善だったらブラウザ上ですべて完結します。
6.4 多言語対応
- i18next を利用し、日本語 / 英語の切り替えが可能。
- システムプロンプトからすべてを日本語と英語で切り替えられるようにしてみました。
7. API化と拡張性
この仕組みは「チャットアプリ」で完結させるのではなく、API として利用可能な形にしました。
これにより CI/CD への組み込みや社内ツールからの呼び出しが容易になり、ユースケースが一気に広がります。
7.1 API設計の概要
-
エンドポイント
-
/chat: ユーザー入力を渡すと LangGraph の状態を 1 ステップ進める -
/reset: セッションをリセット
-
-
レスポンス構造
-
phase: 現在のフェーズ(hearing / summarizing / code_generation / code_validation / completed) -
requires_user_input: ユーザーの次回答を待つかどうか -
messages: 出力された質問やコード
-
7.2 実際のレスポンス例
{
"phase": "code_generation",
"requires_user_input": false,
"messages": [
{
"role": "assistant",
"content": "```bicep\nresource stg 'Microsoft.Storage/storageAccounts@2022-09-01' = {\n name: 'mystorage123'\n location: resourceGroup().location\n sku: {\n name: 'Standard_LRS'\n }\n kind: 'StorageV2'\n}\n```"
}
]
}
7.3 API化による拡張可能性
以下のような拡張が 実現可能になりました:
-
CI/CD パイプラインとの統合
- GitHub Actions や Azure DevOps から API を呼び出し
-
チャットツールとの連携
- Teams ボットから API を呼び出し
- 自然言語での IaC リクエストに対応
- 社内開発ポータルへの組み込み
-
他 IaC への展開
- LangGraph のステートマシン設計により、出力部分のみの変更で Terraform などにも対応可能
現在の実装状況:
- REST API として
/chatと/resetエンドポイントを提供 - セッション管理(
thread_idによる並列利用) - JSON でのリクエスト/レスポンス
- 上記拡張案は API 基盤があることで実装が容易
まとめ
API としてラップことで、PoC にとどまらず実運用やチーム利用に耐えられる可能性になりました。ただし、バックエンド自体はローカルで動かしてるのでまだまだ改善が必要ですね。
8. まとめ
本記事では、会話から Bicep を生成する LangGraph をもちいたアプリケーションを紹介しました。
本記事のポイント
-
LangGraph による有限ステートマシン設計
→ ユーザー入力が途切れても「ヒアリング → サマリ → コード生成 → lint → 再生成 → 完了」まで自動で進行。 -
lint 結果を利用したフィードバックループ
→ LLM に丸投げせず、CLI の出力を最小限返すことで トークン節約と安定性 を両立。 -
UX へのこだわり
→ 自動前進、フェーズ可視化、Monaco Editor による編集機能で、快適な体験を実現。 -
API化と拡張性
→ FastAPI でエンドポイントを公開し、CI/CD や Teams 連携にも応用可能。Terraform や Pulumi など他 IaC にも横展開可能。
今後に向けて
実は、時間がなかったので実装をあきらめた機能がたくさんあります。記事執筆時点で、インターンの残り期間が3日しかないので難しいとは思いますが、以下の機能を実装したいと思っていました。
- Bicep からアーキテクチャ図の自動生成: Diagram as Code と呼ばれる分野ですね。Azure のアーキテクチャ図をコードから自動的に生成するツールをざっと調べた限り、完璧な機能としてリリースされているものはなく、需要もありそうでした。
- Azure リソースのデプロイ: 生成した Bicep コードをそのまま Azure にデプロイできると便利ですよね。アプリケーション内でデプロイまで完結できるようにしたいです。lint 検証を通ったコードでも、デプロイしてみないと分からないエラー(例:グローバルにユニークな名前が求められるリソースの名前衝突)があるので、デプロイエラーも含めてコードを再生成するようなワークフローにできれば、より高品質なコードが生成できるようになると思います。
- Web アプリ化: 今回のアプリケーションはローカルで動するアプリとして作成しましたが、Web アプリとして公開できればより多くの人に使ってもらえると思います。
ここまで読んでくださりありがとうございました。
改めて共同開発してくださった、チームの皆さんありがとうございます!
Discussion