SQLアンチパターン
ジェウォークについて
多対多の中間テーブルを作成しないでリスト構造で1カラム内に複数データを入れてしまうケース
アンチパターン:カンマ区切りのリストを格納する
-- ex. account_ids を文字列のカンマ区切りで表現している
INSERT INTO foo_table (id, name, account_ids) VALUES (1, "jon", "10,20,30");
上手くいっていると思える点
多対多の関係性が必要になってもリスト構造のカラムを追加することで表現できる
アンチな点
- 検索のパフォーマンスに影響がでる
- 検索クエリの条件をパターンマッチにしないと特定の項目を抽出できない
- 条件式によっては意図しない結果が取れてしまう(WHERE区で正規表現を正しく書く必要がある)
- インデックスの効果も得られない
- 結合条件を作るのも一苦労
- リスト構造にすることはカラムの型としてはVERCHARになる。そのためRDBのバリデーションを受けれないに等しい
- 文字列に制限があると(VERCHAR(100)とか)制限以上の文字列に達した時データが正しく反映させない
アンチパターンを使ってもよいケース
データをバラバラに格納するとかえってデータ構造がわかりにくなる場合は非正規化してデータを格納するケースもある
→ 非正規化するにしてもJSON型などである程度構造化した方がいいのではと思う
解決策
多対多の関係性があるなら中間テーブルを作成するのがベータ
ナイーブツリーについて
例えば、GitHubのPRタイムラインのようにコメントがあり、そのコメントに対してスレッド化してリプライできるサービスがあるとする(よくあるコメント機能)
このデータ構造を表現するのに多く書籍では親IDを持たせて親子関係をつくることが推奨させているが、この手法は思慮が浅い素朴(ナイーブ)な解決策であるとも言える。
アンチパターン:常に親ののみに依存する
親IDを持つDDLはこんな感じ
CREATE TABLE comments (
comment_id SERIAL PRIMARY KEY,
parent_id BIGINT,
author VARCHAR,
comment TEXT
)
登録されるデータはこんな感じだとする
| comment_id | parent_id | author | comment |
|---|---|---|---|
| 1 | Fran | このバグの原因はなにかな? | |
| 2 | 1 | Ollie | ヌルポインターのせいじゃない? |
| 3 | 2 | Fran | そうじゃない。それは確認済みだから |
| 4 | 1 | Kukla | 無効な入力は調べてみた? |
| 5 | 4 | Ollie | そうか、バグの原因はそれだ |
| 6 | 4 | Fran | よし、じゃあチェック機能を追加してもらっていい? |
| 7 | 6 | Kukla | 了解。修正したよ |
parent_idに上位コメントのcomment_idを持っている
このような設計を隣接リストと呼ばれる
このデータ構造で直近の子のデータを取得するには以下で可能になる
SELECT
*
FROM
"comments" c
LEFT OUTER JOIN "comments" c2 ON
c2.parent_id = c.comment_id
| comment_id | parent_id | author | comment | comment_id | parent_id | author | comment |
|---|---|---|---|---|---|---|---|
| 1 | Fran | このバグの原因はなにかな? | 2 | 1 | Ollie | ヌルポインターのせいじゃない? | |
| 2 | 1 | Ollie | ヌルポインターのせいじゃない? | 3 | 2 | Fran | そうじゃない。それは確認済みだから |
| 4 | 1 | Kukla | 無効な入力は調べてみた? | 5 | 4 | Ollie | そうか、バグの原因はそれだ |
| 4 | 1 | Kukla | 無効な入力は調べてみた? | 6 | 4 | Fran | よし、じゃあチェック機能を追加してもらっていい? |
| 6 | 4 | Fran | よし、じゃあチェック機能を追加してもらっていい? | 7 | 6 | Kukla | 了解。修正したよ |
| 1 | Fran | このバグの原因はなにかな? | 4 | 1 | Kukla | 無効な入力は調べてみた? | |
| 5 | 4 | Ollie | そうか、バグの原因はそれだ | ||||
| 3 | 2 | Fran | そうじゃない。それは確認済みだから | ||||
| 7 | 6 | Kukla | 了解。修正したよ |
結果を取得するのは簡単だが、隣接リストと呼ばれる通り1レコードに表現できるのは直近のデータのみである。
各階層のデータを取得したければ階層ごとにJOINを増やす必要がでてくる。
この構造の利点として、INSERTやUPDATEは単純にできるがDELETEが一工夫必要
→ 親子関係の途中のコメントが削除された場合、削除された子供のparent_idを一つ上の親にUPDATEする必要がでてくる
ナイーブツリー - 経路列挙について
ナイーブツリーについての続き
隣接リストの解決策
代替え手法として以下の3つが挙げられる
- 経路列挙モデル ← ここの話
- 入れこ集合モデル
- 閉包テーブルモデル
経路列挙モデルについて
親IDを持たないでスレッドの順路をパスとして持つ考え方
DDLはこんな感じ
CREATE TABLE comments_path (
comment_id SERIAL PRIMARY KEY,
PATH VARCHAR,
author VARCHAR,
COMMENT TEXT
)
登録されるデータはこんな感じ
| comment_id | path | author | comment |
|---|---|---|---|
| 1 | 1/ | Fran | このバグの原因はなにかな? |
| 2 | 1/2/ | Ollie | ヌルポインターのせいじゃない? |
| 3 | 1/2/3/ | Fran | そうじゃない。それは確認済みだから |
| 4 | 1/4 | Kukla | 無効な入力は調べてみた? |
| 5 | 1/4/5/ | Ollie | そうか、バグの原因はそれだ |
| 6 | 1/4/6/ | Fran | よし、じゃあチェック機能を追加してもらっていい? |
| 7 | 1/4/6/7/ | Kukla | 了解。修正したよ |
パスに対してパターンマッチを行うことですべての祖先を取得することができる
comment_id = 7の祖先を取得した場合は下記クエリで取得でき
SELECT
*
FROM
comments_path cp
WHERE
'1/4/6/7' LIKE cp."path" || '%';
| comment_id | path | author | comment |
|---|---|---|---|
| 1 | 1/ | Fran | このバグの原因はなにかな? |
| 4 | 1/4 | Kukla | 無効な入力は調べてみた? |
| 6 | 1/4/6/ | Fran | よし、じゃあチェック機能を追加してもらっていい? |
逆に、comment_id = 4の子孫をすべて取得したい場合は
SELECT
*
FROM
comments_path cp
WHERE
cp."path" LIKE '1/4/' || '%';
| comment_id | path | author | comment |
|---|---|---|---|
| 5 | 1/4/5/ | Ollie | そうか、バグの原因はそれだ |
| 6 | 1/4/6/ | Fran | よし、じゃあチェック機能を追加してもらっていい? |
| 7 | 1/4/6/7/ | Kukla | 了解。修正したよ |
で可能になる
欠点
- ジェイウォークでも上げた通り、VARCHAR型で区切り文字を入れて階層を表現しているためRDB上からpathの確らしさは検証できない
参考
LIKEでのパターンマッチは固定文字から部分一致する文字列を検索できる
ナイーブツリー - 入れこ集合について
ナイーブツリーについての続き
隣接リストの解決策
代替え手法として以下の3つが挙げられる
- 経路列挙モデル
- 入れこ集合モデル ← ここの話
- 閉包テーブルモデル
入れこ集合モデル
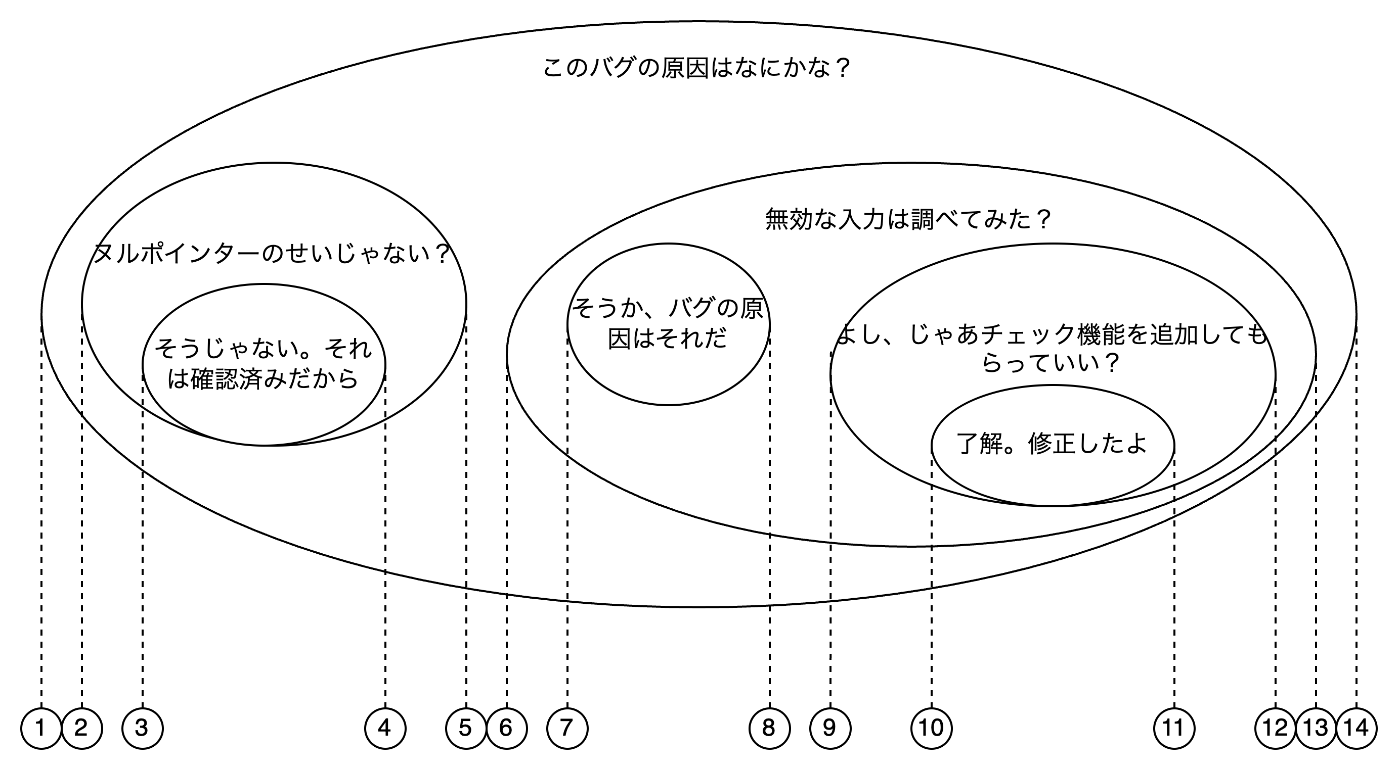
円の包含関係のようにツリー構造を保持する考え
レコードの包含情報はそれぞれnsleft、nsrightのカラムに保持される
- nsleft:包含対象の最小値
- nsrigth:包含対象の最大値
包含関係はこうなる
DDLはこんな感じ
CREATE TABLE comments_nested (
comment_id SERIAL PRIMARY KEY,
nsleft INTEGER,
nsrigth INTEGER,
author VARCHAR,
COMMENT TEXT
)
登録されるデータはこんな感じ
| comment_id | nsleft | nsrigth | author | comment |
|---|---|---|---|---|
| 1 | 1 | 14 | Fran | このバグの原因はなにかな? |
| 2 | 2 | 5 | Ollie | ヌルポインターのせいじゃない? |
| 3 | 3 | 4 | Fran | そうじゃない。それは確認済みだから |
| 4 | 6 | 13 | Kukla | 無効な入力は調べてみた? |
| 5 | 7 | 8 | Ollie | そうか、バグの原因はそれだ |
| 6 | 9 | 12 | Fran | よし、じゃあチェック機能を追加してもらっていい? |
| 7 | 10 | 11 | Kukla | 了解。修正したよ |
この状態でcomment_id = 4の子孫を取得しようとしたとき、コメント4のnsleftとnsrightとの間にnsleftが含まれるノードを検索することで取得できる
SELECT
*
FROM
comments_nested cn
INNER JOIN comments_nested cn2 ON
cn2.nsleft BETWEEN cn.nsleft AND cn.nsrigth
WHERE
cn.comment_id = 4
| comment_id | nsleft | nsrigth | author | comment | comment_id | nsleft | nsrigth | author | comment |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 6 | 13 | Kukla | 無効な入力は調べてみた? | 4 | 6 | 13 | Kukla | 無効な入力は調べてみた? |
| 4 | 6 | 13 | Kukla | 無効な入力は調べてみた? | 5 | 7 | 8 | Ollie | そうか、バグの原因はそれだ |
| 4 | 6 | 13 | Kukla | 無効な入力は調べてみた? | 6 | 9 | 12 | Fran | よし、じゃあチェック機能を追加してもらっていい? |
| 4 | 6 | 13 | Kukla | 無効な入力は調べてみた? | 7 | 10 | 11 | Kukla | 了解。修正したよ |
メリット
クエリで複雑な表現が可能そう
デメリット
データ登録等で座標をずらす必要が出た場合、多くのレコードに影響がでそう
直感的に分かりずらい
単純に座標を計算するのが面倒そう
ナイーブツリー - 閉包テーブルについて
ナイーブツリーについての続き
隣接リストの解決策
代替え手法として以下の3つが挙げられる
- 経路列挙モデル
- 入れこ集合モデル
- 閉包テーブルモデル ← ここの話
閉包テーブルモデルについて
コメントテーブルには依存関係は保持しないで別テーブルに持たせる
DDLはこんな感じ
CREATE TABLE comments_closure (
comment_id SERIAL PRIMARY KEY,
author VARCHAR,
COMMENT TEXT
)
;
CREATE TABLE tree_path (
ancestor BIGINT,
descendant BIGINT
);
登録されるデータはこんな感じ
| comment_id | author | comment |
|---|---|---|
| 1 | Fran | このバグの原因はなにかな? |
| 2 | Ollie | ヌルポインターのせいじゃない? |
| 3 | Fran | そうじゃない。それは確認済みだから |
| 4 | Kukla | 無効な入力は調べてみた? |
| 5 | Ollie | そうか、バグの原因はそれだ |
| 6 | Fran | よし、じゃあチェック機能を追加してもらっていい? |
| 7 | Kukla | 了解。修正したよ |
| ancestor | descendant |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 1 | 4 |
| 1 | 5 |
| 1 | 6 |
| 1 | 7 |
| 2 | 2 |
| 2 | 3 |
| 3 | 3 |
| 4 | 4 |
| 4 | 5 |
| 4 | 6 |
| 4 | 7 |
| 5 | 5 |
| 6 | 6 |
| 6 | 7 |
| 7 | 7 |
見ての通りツリー情報が外だしになっているのでSELECTするときは2つのテーブルを結合する必要あり