㊙️
【kanjiconv】固有名詞にも対応した「漢字」→「かな/ローマ字」Python変換ライブラリ
はじめに
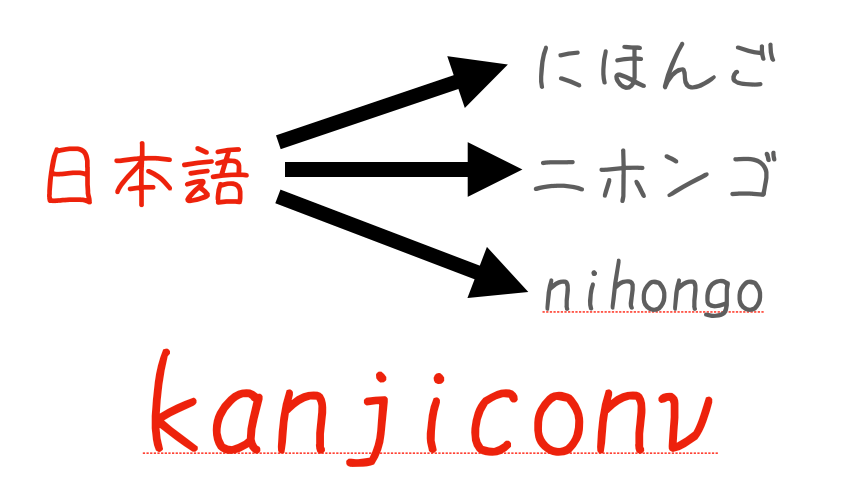
日本語の文章を処理する際、漢字をひらがなやカタカナ、ローマ字に変換したい場面は多々あります。例えば、日本語学習者向けの教材作成や、音声合成の前処理などです。そこで今回は、簡単に漢字の読みや発音を取得できるPythonライブラリ『kanjiconv』を作成しました。
『kanjiconv』は、形態素解析エンジンであるSudachiPyとその辞書であるSudachiDictをベースに開発されています。これにより、固有名詞など高精度な読み仮名の取得が可能です。
実は以前mecab-unidic-neologdをベースとした同じようなライブラリを作成したことがあるのですが、neologdの更新が止まってしまったということで、今回こちらのkanjiconvを作成しました。
※kanjiconvのLicenseはApache License 2.0です。
GitHubページ
インストール
kanjiconvのインストール
まず、pipを使用して『kanjiconv』をインストールします。
pip install kanjiconv
使用方法
インポートとインスタンスの生成
まず、ライブラリをインポートし、KanjiConvのインスタンスを生成します。オプションで区切り文字を指定できます(デフォルトは/)。
# インポート
from kanjiconv import KanjiConv
# インスタンス生成&区切り文字を指定(例:'/')
kanji_conv = KanjiConv(separator="/")
漢字をひらがなに変換
text = "幽☆遊☆白書は、最高の漫画デス。"
print(kanji_conv.to_hiragana(text))
# 出力: ゆうゆうはくしょ/は/、/さいこう/の/まんが/です/。
漢字をカタカナに変換
print(kanji_conv.to_katakana(text))
# 出力: ユウユウハクショ/ハ/、/サイコウ/ノ/マンガ/デス/。
漢字をローマ字に変換
print(kanji_conv.to_roman(text))
# 出力: yuuyuuhakusho/ha/, /saikou/no/manga/desu/.
区切り文字を変更
# 区切り文字を'_'に設定
kanji_conv = KanjiConv(separator="_")
print(kanji_conv.to_hiragana(text))
# 出力: ゆうゆうはくしょ_は_、_さいこう_の_まんが_です_。
# 区切り文字をなしに設定
kanji_conv = KanjiConv(separator="")
print(kanji_conv.to_hiragana(text))
# 出力: ゆうゆうはくしょは、さいこうのまんがです。
まとめ
『kanjiconv』を使うことで、漢字を簡単にひらがな、カタカナ、ローマ字に変換できます。日本語テキストの前処理や言語学習の支援など、さまざまな用途で活用できる便利なツールです。ぜひ試してみてください。
ライセンス
- kanjiconv: Apache License 2.0
- SudachiPy: Apache License 2.0
- SudachiDict: Apache License 2.0
追記
漢字によってはSudachiでは対応されていないものもあったため、unidicやカスタム辞書にも対応するようアップデートしました。
詳細についてはこちら
【kanjiconv】【アップデート】Unidic & カスタム辞書対応(「漢字」→「かな/ローマ字」変換)GitHubで開く
Discussion