レバウェルSREグループ設立からの1年とこれから
レバウェル開発部 アドベントカレンダー3日目です。
こんにちは!
レバウェル開発部レバウェルSREグループの中村です。
レバウェルSREグループ設立からざっくり1年が経過したので、
ここ1年でのグループとしての取り組みと今後についてまとめていきます。
なお、SRE化に向けた下地作りが中心となるフェーズなので、その前提でご覧いただければと思います。
弊社のSRE組織

引用元: SREから始める、関係者全員の幸福(レバレジーズテックブログ)
上図のように、
- Evangelist SRE
- SREとインフラ周りのノウハウの集約と展開を全社横断的に行うチーム
- Embedded SRE
- ノウハウを展開していただいて、ドメイン知識を踏まえて適用していくチーム
の二つに分かれており、レバウェルSREグループは後者に当たります。
SREグループ設立後の取り組み
監視の整備
弊開発部では、監視が行き届いていなかったり、オオカミアラート化している現状がありました。
そこでまずは、弊社ガイドライン(後述)で定義されているLv.2を目指して監視の整備を進めました。Lv.2の具体的な状態は下記です。
- 監視ルールが整備されていて、サービスの異常が定義されている状態
- サービスの異常がアプリチーム、SREチームに通知されている状態
- 各サービスのダッシュボードが用意され、定期的なメトリクスの見直しがされている
- ステークホルダーへの通知のエスカレーションルールが定義されている
メトリクスアラート
元々は一部のEC2とRDSとELB,ECSのみメトリクスアラートを設定されている状態でした。そのままの作りですと、原因調査の効率や不具合の検知速度に難があります。
e.g.) EC2から呼び出しているStepFunctionsがこけたことを検知するためには、ELBの5xxエラーアラートからEC2のLaravelログを確認し、その中のエラーメッセージからStepFunctionsの実行に失敗したことを検知する必要がある。
そこで、上記以外のリソースについても必要なメトリクスの実装を行いました。
必要と判断した基準は、アラートが通知された際に、他の作業を中断してすぐにアクションを起こす必要があるかどうかになります。
- OpenSearch
- ClusterStatus.red
- MasterReachableFromNode
- Nodes
- FreeStorageSpace
- SQS(DLQ含む)
- ApproximateAgeOfOldestMessage
- ApproximateNumberOfMessagesVisible
- Lambda
- Duration
- ConcurrentExecutions
- StepFunctions
- ExecutionsFailed
- ExecutionsAborted
- ExecutionsTimedOut
- カバーしていなかったEC2とRDSとELB,ECS
これまでこれらのアラートが実装されていなかった背景については、推測になりますが、通知先を一つのチャンネルに集約していたので、アラートで通知先がいっぱいになってしまうのを防ぐために実装をしていなかったのではと考えています。
この問題について、
- 開発チームごとのチャンネルと開発チームを跨いでいる共通リソース用のチャンネルをそれぞれ用意し、確認が必要な量を減らす
- EC2やECSにおいては、TargetGroupに紐づいていることでELBアラートで検知できるものについては実装しないようにし、必要以上にアラートを作らない
という方針で対応をしています。
また、通知対象のリソースが増加することにより、アラートを検知/対応する側にも必要な知識が増えるので、今後SREグループがノウハウの共有を進めていく必要があります。
外形監視
オオカミアラート化によって「アラートが出ているからといってサービスが危険な状態にあるとは限らない」状況になっており、サービスが利用不可になっている状況を検知するのに時間がかかることがある課題がありました。これまでは、定期的にメンバーが確認する暫定対応をしている状態でした。そこで、確認コストを削減するため、toCのサービスに外形監視を導入しました。
利用サービスはCloudWatch Syntheticsです。
考慮事項としては
- マーケティング部で計測しているPV数に影響しないようにする方法
- 対象とするページとその頻度
といったものがあり、いずれもマーケティング部の方に協力していただきながら検討を進めました。
1. マーケティング部で計測しているPV数に影響しないようにする方法
GTMでGA4のタグを発火するという方法で計測をしており、 選択肢として以下のものがありました。
- 外形監視ツールによるアクセスでは特定のUser Agentを設定
- CloudWatch Syntheticsで使用しているLambdaをNAT Gateway経由にすることでIPを固定
- CloudWatch Syntheticsで使用しているLambdaに直接EIPを紐づけることでIPを固定(参考:【裏技】Lambda の固定IP化にまだ NatGateway 使ってるの?)
今回は無料で実現できるため、「外形監視ツールによるアクセスでは特定のUser Agentを設定」を選択し、該当のUser Agentを計測から除外することにしました。
2. 対象とするページとその頻度
既存ページのCVRなどを元に、監視対象のページを決定いただきました。その後、対象ページにかけられる監視コストと検知までにかかる時間のバランスを考えながら頻度を決定いただきました。
ご協力のおかげで、toCの全サービスで外形監視の導入が完了しております。
コストの削減
STG/DEVサーバーの自動停止/開始
弊開発部では、EC2をメインのコンピューティングサービスとして利用しており、
STG/DEV環境でも、スペックは低いですが起動し続けてしまっている状態でした。
そこで、下記のように自動停止/開始の仕組みを構築し、実装前後で25~30%ほどのコストを削減できました。
1. 各サーバーを起動しておく時間のヒアリング
利用する側に不都合が発生しないよう、事前に稼働時間のヒアリングを行いました。マーケターやデザイナーの方が表示の確認などに使用することも踏まえた稼働時間を、開発チームのメンバーにヒアリングし、エンジニアに影響が出ない時間をデフォルトとして、各サーバーの停止/開始時刻を決定しました。
2. EventBridge + SSMによる簡易な実装
まずは早期に実装して金銭コストの削減を早めることが優先であると考え、EC2の特定のタグを参照して自動停止/開始する仕組みを構築しました。
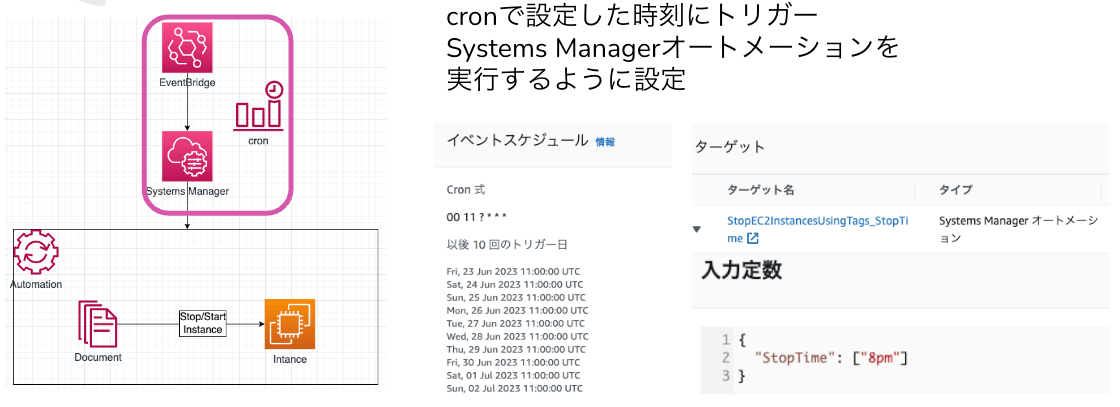
構成図と設定例
3. Googleカレンダー + StepFunctionsによる実装
上記の実装では、
- 停止/開始時刻を変更する際、EventBridgeルールになければ追加で作成する必要がある
- 停止/開始時刻を変更する際、EC2のタグを操作するためヒューマンエラーが発生する可能性がある
- STGを確認する可能性があるマーケターやデザイナーの方が時刻を操作できず、依頼されるエンジニアの工数が取られる
といった課題があるため、下記のような処理をStepFunctionsで実装しました。
これにより、サーバーに紐づいたGoogleカレンダー上の予定を操作することで、稼働時間を変更できます。
フローチャートと定義グラフ

フローチャート

StepFunctionsの定義グラフ
参考:
Googleカレンダー連携の記事
[AWS Step Functions]Mapステート内でエラーをキャッチしてステートマシンを失敗させる(AWS CDK)
Savings Plans
前年もSavings Plansを使用していましたが、今年度はEC2 -> ECS移行の計画もあったので
スケジュールも踏まえて比較検討しました。
1. 最初に使用するSavings Plansを検討
Computeリソースによるコストのうち、LambdaとECSの割合は15%ほどだったので、
まずはEC2 Instance Savings Plansを使用することにしました。
最初にと記載しているのは、ECS化が進んだ後にCompute Savings Plansを導入する可能性があるためです。
2. Savings Plansの料金計算
Savings Plansでの前払い金額による割引金額/割引率をEC2のサイジングとECS化のスケジュールを踏まえて計算しました。
ECS化のスケジュールについては、大まかに四半期ごとに区切って
- 1Q~2Q: 25%
- 2Q~3Q: 50%
- 3Q~4Q: 75%
という形でオンデマンド料金を計算しました。
3. 前払金の比較検討
3パターンほど比較検討を行いました。カバレッジと使用率、削減金額を元に検討を行い、
前年での平均カバレッジが75%, 使用率が98~100%であることを踏まえて
前払金が一番少ないパターンを選択しました。
- 予測カバレッジが77%になるので前年度と大きく乖離せず、使い切れる可能性が高い
- EC2のスケールイン/ダウン実施や、予定よりECS化が進行することがあっても余分な支払いになりづらい
- 割引率は最大にはならないが、35%ほどなので十分である
といったことが決定理由になりました。
RI
例年購入しているRIの内容の見直しを行いました。
検討対象は、以下の通りです。
- RDS
- ElastiCache
- OpenSearch
弊開発部において、ElastiCacheはRDSやOpenSearchに比べて削減効果が小さいことから、
例年購入しているRDSに加えて、OpenSearchの購入までに留めることになりました。
なお、OpenSearchについては、インスタンスタイプが古くてRI適用できないノードがいくつかあったため未だ購入しておらず
実際にRIを適用しているのはRDSのみという状況でしたが、
対象を拡張したこともあって、オンデマンドの金額から40%ほどの削減ができました。
S3
各AWSアカウントのコスト内訳を確認している中で、特定のアカウントでS3の占める割合が大きかったため、コスト削減を行いました。
1. S3の何が原因でコストがかかっているのか確認する
Cost Explorerにて、フィルターでサービス: S3、グループ化の条件でディメンション: 使用タイプを選択すると、下記のような結果でした。
| 使用タイプ | 内容 |
|---|---|
| APN1-TimedStorage-SIA-ByteHrs | S3 Standard-IA ストレージに保存されたデータの GB-月の数 |
| APN1-TimedStorage-ByteHrs | S3 Standard ストレージに保存されたデータの GB-月の数 |
| APN1-DataTransfer-Out-Bytes | Amazon S3 からインターネット1 に転送されたデータ量 |
| APN1-Requests-Tier1 | S3 Standard、RRS、タグに対する PUT、COPY、または POST リクエストに加え、すべてのバケットとオブジェクトに対する LIST リクエストの数 |
| APN1-Requests-Tier2 | GET および他のすべての Tier1 以外のリクエストの数 |
| APN1-Requests-Tier4 | S3 Glacier Flexible Retrieval、S3 Intelligent-Tiering、S3 Standard-IA、または S3 One Zone-IA ストレージへのライフサイクル移行数 |
| APN1-Retrieval-SIA | S3 Standard – IA ストレージから取得したデータの量 |
2. コストの内訳から対応方針検討
具体的な値は控えますが、上記のうちAPN1-TimedStorage-SIA-ByteHrsのコストが70%ほどでしたので、こちらの削減を中心に検討を進めました。
元々は、Standard -> Standard-IAに90日後に移動する設定のみが存在していました。
Storage Lensで該当バケットのデータ量はどれくらいのペースで増加しているかを確認しつつ、下記の2案で検討しました。
- Standard-IAへの移行を30日後に早め、90日後にGlacier Instant Retrievalへ移行する
- Standard-IAを飛ばして30日経過の時点でGlacier Instant Retrievalへ移行する
3. 対応方針決定と実装
結局、下記の理由から後者の案に決定しました。
- 削減効果が後者は前者の2倍くらいある
- 取り出し料金が3倍になるが、現状Standard-IAからの取り出しでかかっているのは$0.5~1であり、クラス移行による削減額の方が大きいため許容できる
- バケットのデータを利用するチームにアクセス頻度を確認したところ、そこまで高くない
- Glacier Instant Retrievalでも取り出し速度は現状と変わらない
実装についてはライフサイクルの変更だけなので一瞬で終わり、前月比で50~60%ほどのコスト削減ができました。
ECS on Fargateへの移行(WIP)
現在運用しているサービスはほとんど「ECS on EC2」「EC2」を使用していますが、それぞれの課題や共通の課題があり、ECS on Fargateへの移行を進めています。
-
ECS on EC2
多い時は週に2回ほど不具合が発生するサービスがあり、その都度対象のEC2を立ち上げ直す必要がありました。不具合修正までの暫定対応として、このサービスをFargateに移行することで、自動で復旧が行われるようになり、運用コストの削減につながりました。 -
EC2
現状運用しているサービスはほぼEC2ですが、AutoScalingが適用されていない状態です。そのため、- 急なスパイクに対応できない
- サイジングに手間がかかる
- インスタンスが止まったら手動で復旧する必要がある
- 余裕を持ったスペックにする必要があり、コスト最適化ができない
といった課題があります。
-
共通の課題
もうすぐ訪れるAmazon Linux2のEOLに伴い- 対象インスタンスの作り直し
- ミドルウェアの変更
- Node.jsのバージョンアップ
といった対応が発生しています。
これらによる運用コスト軽減と、耐障害性の向上やパフォーマンス最適化のため、ECS on Fargateへの移行が絶賛進行中です。
PR自動作成
レバウェルSREグループは開発チームの業務効率化への協力もしているので、その取り組みも紹介させていただきます。
開発チーム側のブランチ運用として、GitFeatureFlowを採用しています。
実装後、mainとstg-env両方に向けてPRを作成する必要があります。
1回あたりが5分としても、これがチリツモで工数をとってきます。
週あたり20PRほどは作成されているので、100分/週余分な時間がかかっていることになります。
そこで、main向きにPRを作成したら同じ内容でstg-env向きにPRが自動作成される処理の追加と移行を実施しました。
元々2プロジェクトで導入されていた処理を、ここ数年で増えたリポジトリにも追加していきました。
また、既存の処理はGithubのWebhookを起点にしてCodeBuildを呼び出す作りになっていましたが、Github Actionsに移行を行いました。
Actionsの中身
on:
pull_request:
branches: [main]
types: [opened]
permissions:
contents: write
pull-requests: write
jobs:
create-stg-env-pr:
runs-on: ubuntu-latest
env:
GH_TOKEN: ${{ secrets.CREATE_PULL_REQUEST }}
RP_TITLE: ${{ github.event.pull_request.title }}
steps:
- name: main checkout
uses: actions/checkout@v4
- name: Add Label
run: |
gh pr edit ${{ github.event.number }} --add-label 'main'
- name: Set Default Repository
run: |
gh repo set-default git@github.com:xxx/yyy
- name: Create Release Pull Request
run: |
gh pr create \
-B stg-env \
-H ${{ github.actor }}:${{ github.head_ref }} \
-t "[stg-env] ${RP_TITLE}" \
-a ${{ github.actor }} \
-l stg-env \
-b "mainPR
#${{ github.event.number }}"
移行については、
- Github Enterpriseへの移行に伴って、CodeBuildのために認証周りの再設定が必要になり、類似の事象があるたびに工数がかかる
- 操作対象がGithubなので、Github内で完結させた方が良い
- 不具合発生時の調査範囲を狭められる
- 余計な通信が発生しないのでやや時短
- 変更をするとき、開発側のエンジニアで調整しやすい
といった背景があります。
IaC
Terraformの導入
元々はCloudFormation(以下CFn)を利用していましたが、Terraformを導入しました。
理由としては、
- 全社横断のSREチームの方でTerraformモジュールの構築を進めている
- 長い目で見ると実装コストが削減できる
- 全社で定めたセキュリティ基準や基本構成を簡単に展開できる
- 後にマルチクラウド化しても対応できる
- 相対的に、若干プログラミング寄りの書き方ができる
といったことが主となります。
IaCの統合(WIP)
上述の通り、Terraformを導入したので既存のリソースをCFn管理からTerraform管理へと少しづつ移行しています。
具体的には、Terraformにimportして、CFn側ではDeletionPolicy: Retainを付与してからスタックを削除することで管理を移行しています。
対象となるリソース量が多いため、基本的には変更が発生したリソースに対して実施しています。
また、以下のIaCツールもあるので移行を予定しています。
- AWS CDK
- 部分的にCDKで作られているものがあるが、TSで実装するメリットに対してIaCツールが分かれることのデメリットの方が大きいため
- Serverless Framework
- V4に移行しようとすると、企業規模的に有料になってしまうため
CI/CD
CI/CDの移行(WIP)
既存の構成では、CircleCI + Deployer(PHPのライブラリ)を使用しており
- GithubのPRがマージ or リリースタグが切られる
- CircleCIによって
EC2RunCommandを起動 - デプロイ用のEC2にて、Deployerを利用した処理が実行される
といった流れになっていますが、
- 使用するデプロイサーバーが共通のため、複数プロジェクトのパイプラインが稼働するとリソースが逼迫する
- デプロイに失敗した際、デプロイサーバー内とアプリケーションサーバー内でバージョンにずれが生じ、再デプロイに手間がかかる
- CircleCIの課金体系がアクティブユーザー数に応じた課金のため、コスト管理に手間がかかる
- CircleCIの利用プランの都合上、サポートからの返信に1ヶ月かかる
といった課題があります。
そこで、下記の理由からAWSのCodeシリーズへの移行を進めております。
- パイプラインごとに別の環境のため、他のプロジェクトの影響を受けない
- バージョンずれが発生せず、再デプロイもスムーズにできる
- 従量課金のため、コスト管理/予測がしやすい
- サポートからの回答を1~2日で得られる
- 現状ホスティングしているのがAWSのリソースのため、親和性が高い
CI/CDの短縮
CI/CDの実行時間短縮のために、まずビルド処理の時間配分を調査しました。
すると、yarnとwebpackの実行時間が全体に占める割合の多くを占めていました。
そこで、yarnとwebpackについて追加で調査を行い
- localだけでなくCodeBuild内でも
yarnのキャッシュを有効化 -
webpackはCodeBuild, localともにキャッシュが効いていなかったので有効化&調整
といった変更を加えた結果、
yarn: 65s => 0.67s
webpack: 220s => 20s
まで短縮をすることができました。
CodeBuildは実行時間に応じた課金なので、コスト削減にもなりましたね。
その他
マス広告対策
レバウェルとして2024年2月から広告を出したため、その際に生じうる負荷の対策を実施しました。結果、無事サービス停止もなく乗り切ることができました。
- 想定されるアクセス量を踏まえてキャパシティプランニングとサイジングの実施
各アプリケーションサーバーのCPUUtilization, mem_used_percent, RequestCountPerTarget(これだけALBのメトリクス)を過去3ヶ月分ほどエクスポートし、
Max/Min, Averageと第一四分位数 ~ 第三四分位数を算出しました。
その後、アクセス量が増加した場合の数値の変化を確認し、適宜サイジングを実施しました。 - 認知度向上による攻撃発生のリスクを踏まえたWAFの導入
広告による認知度向上に伴い、攻撃が発生するリスクも高まるためマネージドルールも使用しつつWAFの導入を行いました。
手順としては、以下の流れで行いました。- STGでCountモードを使用して、検知されるリクエストを確認する
- 一定期間経過後Count対象に問題がないかマーケティング部にも確認を行い、なければBlockに変更
- 上記の手順をPRDでも実施
Gmailの受信ポリシー変更対応
Gmailの受信ポリシー変更に伴い、これまでは届いていたメールが届かなくなるという事象が懸念されていました。
そこで、下記の対応を実施しました。
-
各サービスでSPF/DKIM/DMARCレコードの設定
設定の有無がサービスごとにまちまちだったので、各サービスでレコードの設定を実施しました。 -
Postmaster toolsの設定
受信ポリシー変更後の、Gmail側の受信状況を把握するためPostmaster toolsの設定を行いました。メリットとしては、以下のものがあります。- シンプルなUIで、エンジニアでない方にも使っていただきやすい。
- TXTレコードを登録するだけで利用可能になり、導入コストが小さい
- Googleアカウントを使用して権限制御できる
デメリットは、管理者権限をつけようとすると対象者のアカウントから発行したTXTレコードを追加で登録する手間があるところですね。
-
迷惑メール率のアラート構築
日次でGoogleAPIを叩いて、Postmaster toolから迷惑メールとして判定されたメールの割合を取得して、閾値を超えていたらSlack通知する仕組みを構築しました。これにより、こまめにPostmaster toolsを確認する必要がなくなりました。
AWSレクチャー企画
インフラ周りの調査について、各チームからSREに依頼が発生してSREのリソースが足りなくなり、対応までに時間がかかってしまうことがよくありました。
そこで、各チームのエンジニアが自力で調査や対応をできるようにすることで、SREのリソース確保とリードタイムの短縮に繋げるため、業務上AWSでよく行う操作をレクチャーする企画を実施しました。レクチャーの際には、業務の際に思い出せるよう、「nginx/access.logのステータスコードを抜き出してフィールドに表示, 200以外のレコードを出すクエリをログインサイトで実行する」というように、業務上起こりうる内容を意識しました。
メンバーの方と自分で講師を担当し、以下のテーマについて解説しました。
- EC2
- 基本操作
- 起動/開始/停止/終了
- 接続(セッションマネージャーによる/SSH)
- 考慮すべきセキュリティ
- 現状の構成
- 基本操作
- RDS
- 基本概念
- 接続方法(EC2, GUIツール, クエリエディタ)
- 不具合発生時によく見るメトリクス
- パフォーマンスインサイトの利用方法
- ポイントインタイムリカバリによる復元
- CloudWatch
- ダッシュボード
- ログ
- ロググループのフィルタリング
- ライブテールによるリアルタイムのログ調査
- インサイトでのクエリ実行
- メトリクス
- アラーム
脆弱性診断の準備と対応
弊社には、サービスの品質や脆弱性診断を実施してくれる、TQCチームという組織があります。
今年度は、そちらのチームにレバウェル開発部の全サービスの脆弱性診断を依頼しています。
それに伴い、
- 脆弱性診断によって負荷がかかるため、既存とは別の環境を構築
- 診断で発見された脆弱性について
- インフラ周りでの変更が必要なものを対応する
- リアーキや機能追加が必要なものの一部設計
といった対応をしました。
これから
ここからは、今後レバウェルSREグループとして取り組んでいくことについて紹介いたします。
SREガイドライン
弊社では、SREの成熟度を測定するためのガイドラインが作成されています。
これはレバレジーズ全体での取り組みで、まだ改善途中のものなので今後変わっていく可能性はあります。基本的にこれらに則り、開発チームのSRE成熟度を高めていく予定です。
サービスレベル目標
Lv.3
- SLOが適切に設定され、定期的に見直す機会を設けて改善を行っている
- SLOがステークホルダー間で合意が取れた状態で運用されている(100%の稼働がありえないことが認識されている)
- エラーバジェットが設定され、超えそうになった場合にステークホルダーと合意してその状態の改善を優先的に行えている
Lv.2
- SLOが適切に設定されていて、定期的に見直す機会を設けている
- エラーバジェットが設定されていて、超えそうになった場合に優先度を調整するなどSLO違反のポリシーを策定している
Lv.1
- SLOが全く設定されていない状態
- サービスの信頼性を測る重要なメトリクスが認知されていない状態
監視
Lv.3
- サービスの異常が定義され、異常な状態であるかが迅速に把握できる状態である
- オオカミアラートがなく、アラートの閾値をその都度調整している
- 9割以上のアラートがSLOバーンレートに基づいている
- ステークホルダーへの通知のエスカレーションルールが定義されていて、適切に運用されている
- ユーザー視点での監視が行われ、監視項目の見直しや改善が行われている
- 自動復旧ができるものに設定がされ、されていないものは復旧作業がドキュメント化されている
Lv.2
- 監視ルールが整備されていて、サービスの異常が定義されている状態
- サービスの異常がアプリチーム、SREチームに通知されている状態
- 各サービスのダッシュボードが用意され、定期的なメトリクスの見直しがされている
- ステークホルダーへの通知のエスカレーションルールが定義されている
Lv.1
監視ルールが整備されておらず、場当たり的なアラート設定を行っている
インシデント対応
補足: インシデントとは「緊急時のサービス対応チームおよび Google では、
何かが起こったときのことを「インシデント」と呼んでいます。」 GoogleSREより
アプリチーム:サービスの実装、機能改善、運用に責任を持っている各チーム、Embedded SREも含まれる
SREチーム:レバレジーズ全体のサービス信頼性に責任を持っているチーム
Lv.3
- 定義された対応フローがアプリチーム、SREチーム全体に浸透している
- 定期的にインシデント対応の訓練が実施されている
- 対応フローの定期的な見直し、改善がされている
- インシデント対応チケットがいつでも誰でも確認できるように管理されている
- セキュリティインシデントの対応フローが確立されている
- 個人情報に関するインシデントや攻撃などへの対応がまとめられている
- リリースのインパクトをコントロールできている
- カナリアリリースが可能でリリースのインパクトを最小限に抑えられる
- アラートの重要度レベルが定義されていて、レベル順に対応できている
Lv.2
- 対応フローが定義され、アプリチーム全体で反復可能な状態になっている
- アプリチーム内で定期的に対応フローの読み直しをしている
- 対応フローのなかに以下の項目が定義されている
- インシデント対応中の役割分担
- インシデント発生時の連絡フロー
- ポストモーテムの実施
- 迅速な切り戻しが可能な状態を構築している
- デプロイが自動化されている
- 新規環境と既存環境の移行が容易な状態になっている
- インシデントが複数発生したときにその都度優先度をつけて対応できている
Lv.1
対応フローが定義されておらず、対応が属人化されている
ポストモーテム
Lv.3
- 非難を伴わないポストモーテムを記録するカルチャーがある
- システムやプロセスの改善による解決を目指している
- 恒久対応と機能開発に優先度をつけて適切なリソースの振り分けができている
- 一つのチームで発生したインシデントが他チームで発生しないように知見の共有と対応が行われている
- 他チームのポストモーテムを活かしてタスク化している
Lv.2
- 自チーム内でインシデントを振り返り、対応プロセスやプロダクトの改善につながっている
- インシデントの暫定対応後にポストモーテムを書いている
- 恒久対応を行い、プロダクト運用を改善している
- 恒久対応の履行管理ができている
- 自チーム内の対応を他アプリチーム、SREチーム、ステークホルダーに発信している
Lv.1
障害報告は書いているが、障害から学習できる状態になっていない
トイルの撲滅
Lv.3
- 各トイルの自動化、半自動化の見通しが立っている
- SREチームで持っている各サービスの全体のタスクのうちトイルは30%未満である
Lv.2
- トイルの見直しや改善が計画性をもって行われている
- 定期的に普段の運用作業にかかっているコストを見直している
- 各運用作業のリストが管理されている
- 各運用作業のドキュメントがあり、SREチームがアクセスできるようになっている
Lv.1
運用作業のプロセス改善が場当たり的に行われている
SREsの構築
弊開発部でSRE化を進めるにあたって、現状以下のような課題があります。
- 引き続き下地づくりを続ける必要がある
- 下地作りと運用業務に工数が取られ、SRE化に関わる業務が進めづらい
- 既存のSREチームのみでは各サービスの深いドメイン知識まで有していないことが多いため改善業務が難しいことがある
- 運用・障害対応を開発チーム内で完結できる状態を目指したい
これらの課題を解決するために、冒頭で説明した構成に加えてもう1種類SREチームを構築することになりました。

私が所属しているレバウェルSREグループは、上図でのProduct SREに変更となります。
開発チームから参画いただいたEmbedded SREには、
Evangelist SREのご協力の上で、学習を進めていただいております。
学習計画
- キックオフ(1.5h)
ゴールの共有
やることの共有
アイスブレイク兼現状分析 - SREの概念理解(1.5h)
- AWSについての知識を概念とハンズオン(10h)
EC2, ALB(3h)
ECS周り(3h)
SQS(2h)
Lambda(2h) - IaCについての知識(16h)
実践terraformのハンズオン実施(4h)
既存リソースのimport(8h)
モブプロの実施(4h)
CI/CD - 運用・監視(10h)
システム運用アンチパターン(6h)
障害対応訓練(4h) 突発的に実施予定 - 定期的なメトリクス・ログ確認会の実施(週次で確認)
学習を進めていただいている間に、Product SREがSRE化の基盤を用意しておき
Embedded SREが順次チームに適用を進めていく流れを想定しております。
SLI/SLO
今年度で監視の実装は終わり、
輪読会(書籍はSLO サービスレベル目標 ―SLI、SLO、エラーバジェット導入の実践ガイド)による知識の共有化も完了するため
来年度あたりから、SLI/SLOの導入を本格的に進めていく予定です。
ビジネス側とも相談しつつ進めていくので、今年度のうちに各所との相談に向けてデータ収集や説得プランをまとめていきます。
アラート運用体制の整備
来年は実装したメトリクスアラートを運用に乗せるための取り組みを進めていきます。
現状の課題として、開発チームによるアラート運用が定着していないというものがあり
その原因として
- 全てのアラートが一つのSlackチャンネルに集約されている
- 頻発しているアラートがありオオカミ化している
- アラートを検知した後の対応が不明確
といったものがあります。
これらの対応として、
- 開発チームごとにアラートの通知先チャンネルを用意して、そのチャンネルに通知が来たら即対応する運用に切り替える
- アラートの閾値調整を行う
- アラートごとの対応フローを周知する
- アラート対応のペアプロを実施する
といった流れを想定しています。
今年度で2までは実施できそうなので、来年度から開発チームがアラート運用できるよう
対応フローの整備やペアプロの実施といった活動を進めていきたいと考えています。
終わりに
いかがでしたでしょうか。
こうして振り返ると、結構色々取り組んだ1年でしたね。
金銭コスト削減だけでも以下のものがありました。
| 内容 | 削減コスト |
|---|---|
| STG/DEVサーバーの自動停止/開始 | STG/DEVのEC2コストを25~30% |
| Savings Plans | EC2のコストを35% |
| RDSのRI | RDSのコストを40% |
| S3のライフサイクル設定 | S3のコストを50~60% |
リソースにも限界があるので、最終的な目標までを細分化して焦らず進めることの重要性を、この1年で、実感を持って学んだ気がします。
なかなか思うように進められない歯痒さを感じることもありましたが、関係者の方々のおかげで今回の記事で紹介したような取り組みを進めてこられました。ありがたや。
ここまで読んでいただき、ありがとうございました!
明日は、弊開発部の命綱である通話サービスを極めしエンジニアの記事です!
Discussion