Kuromojiでかんたん形態素解析
Kuromojiとは!?
Kuromojiは、文章を名詞や動詞、形容詞や副詞などに分解する事ができる、大人気形態素解析ライブラリです。
ライブラリのダウンロード
Kuromojiのソースコードは、GitHubに公開されております。
次のサイトにアクセスし、1, 2の順番にクリックしてライブラリ1式をダウンロードしましょう。
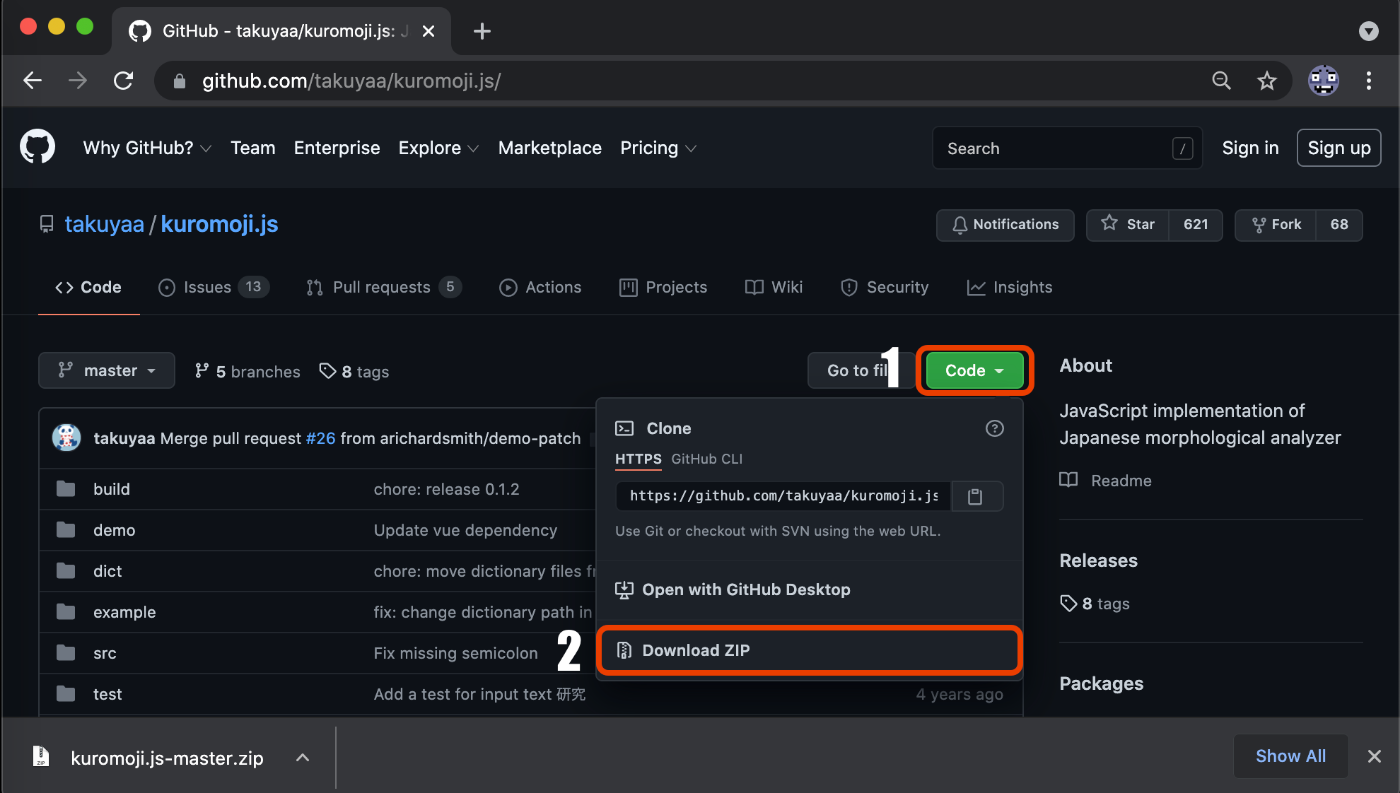
必要なファイル
圧縮ファイルをダウンロードしたら、解凍して必要なファイルを取り出しましょう。
1, Kuromojiライブラリ本体

2, ディクショナリーフォルダ1式(辞書データです)
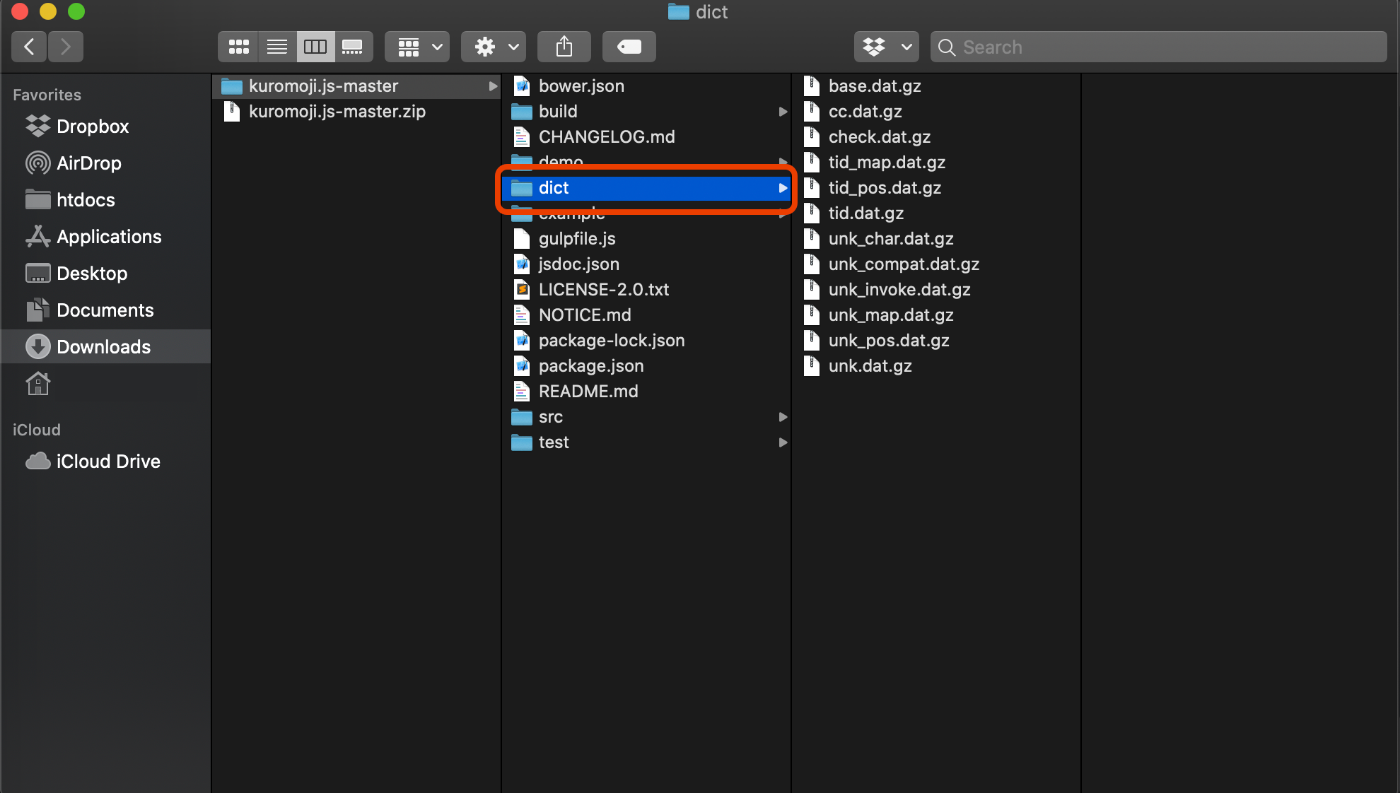
プロジェクトを作る
プロジェクトを作り、これらのファイルを配置します。
MyProject01/
├ dict/ (ディクショナリーフォルダ1式です)
├ index.html (プログラムを起動するファイルです)
├ kuromoji.js (Kuromojiライブラリ本体です)
├ main.js (メインのプログラムを記述するファイルです)
HTMLファイルを用意する
では、作っていきましょう。
HTMLファイルを用意して、下記コードを記述します。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8"/>
<title>Kuromoji</title>
</head>
<body>
<script src="./kuromoji.js"></script>
<script src="./main.js"></script>
</body>
</html>
JavaScriptファイルを用意する
次はメインのプログラムです。
Kuromojiライブラリを読み込む事で、"kuromoji"を扱える様になります。
"kuromoji.builder関数"で、辞書データへのパスを指定します。
後に続く"build関数"のコールバックに帰ってくる、"tokennizer"オブジェクトを使って解析を行います。
kuromoji.builder({dicPath: 辞書データへのパス}).build((err, tokenizer)=>{
// ここで解析を行います。
});
"tokenizer.tokenize関数"に、解析対象の文字列を渡して解析を開始します。
これの実行後に帰ってくるデータには、解析結果が格納されています。
const tokens = tokenizer.tokenize(story);// 解析データの取得
tokens.forEach((token)=>{// 解析結果を順番に取得する
console.log(token);
});
実装例は、次の様になります。
const DICT_PATH = "./dict";
const story = "昔々、あるところにお爺さんとお婆さんが住んでいたそうな。お爺さんは山へ芝刈りに、お婆さんは川へ洗濯に向かいましたとさ。すると、川上からどんぶらこどんぶらこと大きな桃が流れてきました。";
window.onload = (event)=>{
const ids = [];
const names = [];
// Kuromoji
kuromoji.builder({dicPath: DICT_PATH}).build((err, tokenizer)=>{
const tokens = tokenizer.tokenize(story);// 解析データの取得
tokens.forEach((token)=>{// 解析結果を順番に取得する
console.log(token);
});
});
}
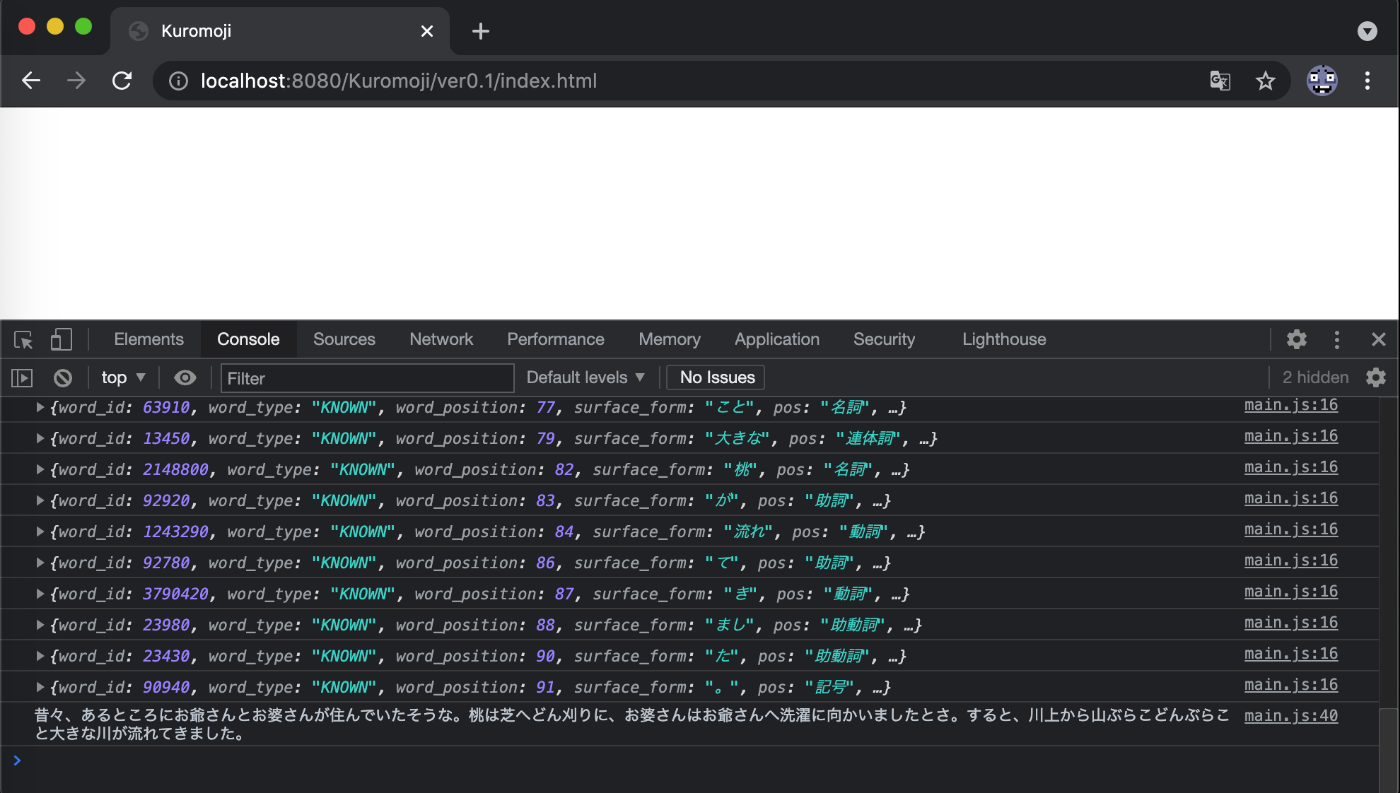
解析データを取得する事ができました。(やりました!!)
解析結果に格納されているデータ
解析結果には、下記の様に様々なデータが格納されています。(Kuromojiより)
[ {
word_id: 509800, // 辞書内での単語ID
word_type: 'KNOWN', // 単語タイプ(辞書に登録されている単語ならKNOWN, 未知語ならUNKNOWN)
word_position: 1, // 単語の開始位置
surface_form: '黒文字', // 表層形
pos: '名詞', // 品詞
pos_detail_1: '一般', // 品詞細分類1
pos_detail_2: '*', // 品詞細分類2
pos_detail_3: '*', // 品詞細分類3
conjugated_type: '*', // 活用型
conjugated_form: '*', // 活用形
basic_form: '黒文字', // 基本形
reading: 'クロモジ', // 読み
pronunciation: 'クロモジ' // 発音
} ]
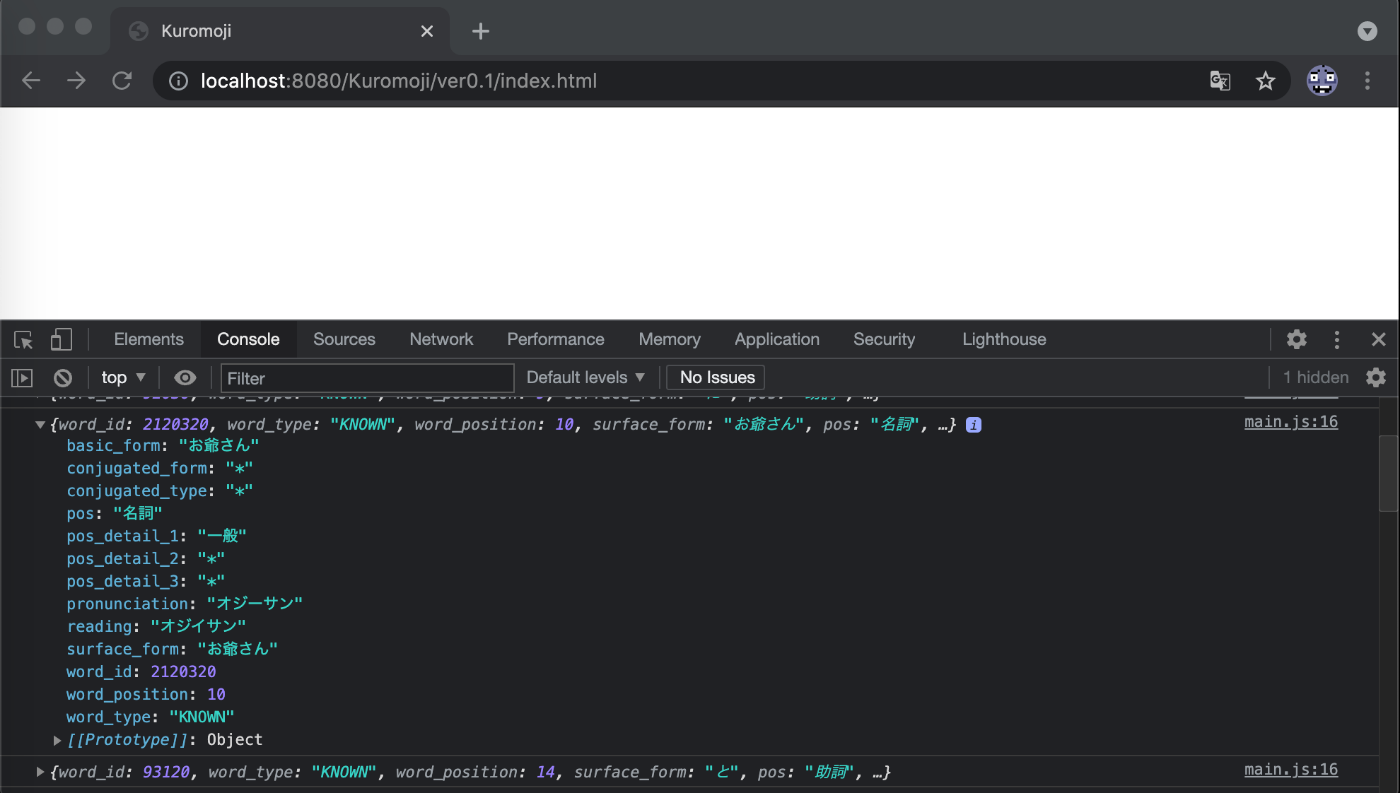
名詞だけシャッフルする
簡単な解説があっさり終わってしまいましたので、(お疲れ様でした!!)
使用例として、昔話にある"名詞"を抽出し、それらをシャッフルするプログラムを作ってみました。(思いつきです!!)
以下が完成コードです。
const DICT_PATH = "./dict";
const story = "昔々、あるところにお爺さんとお婆さんが住んでいたそうな。お爺さんは山へ芝刈りに、お婆さんは川へ洗濯に向かいましたとさ。すると、川上からどんぶらこどんぶらこと大きな桃が流れてきました。";
// Main
window.onload = (event)=>{
const ids = []; // tokenで取得できる言葉のIDを格納する配列
const names = [];// tokenで取得した名詞を格納する配列
// Kuromoji
kuromoji.builder({dicPath: DICT_PATH}).build((err, tokenizer)=>{
const tokens = tokenizer.tokenize(story);
tokens.forEach((token)=>{
console.log(token);
if(token.pos == "名詞" && token.pos_detail_1 == "一般"){
ids.push(token.word_id);// IDを追加する
names.push(token.surface_form);// 名詞を追加する
}
});
makeAnotherStory(tokens, ids, names);// 話を作る関数を実行
});
}
// 話を作る関数
function makeAnotherStory(tokens, ids, names){
shuffle(names);// 名詞配列をシャッフルする関数を実行
const story = [];// 結果を格納する配列
tokens.forEach((token)=>{// tokensから1語づつ抜き出す
const id = token.word_id;// IDを取り出す
const find = ids.findIndex((elem)=>elem==id);// ID配列に存在するかどうか
if(find < 0){// ID配列に存在しない場合(名詞でない)
story.push(token.surface_form);// そのままstoryに追加
}else{// ID配列に存在する場合(名詞である)
story.push(names.pop());// 名詞配列から1つ取り出してstoryに追加
}
});
console.log(story.join(""));// 配列を1つの文章にして出力する
}
// 名詞配列をシャッフルする関数
function shuffle(arr){
for(let i=arr.length-1; 0<i; i--){
const r = Math.floor(Math.random() * i);
const tmp = arr[r];
arr[r] = arr[i];
arr[i] = tmp;
}
}
名詞として抽出する条件として、"名詞"かつ"一般"という条件をつけてみました。
token.pos == "名詞" && token.pos_detail_1 == "一般"
実行すると、"お爺さん"、"お婆さん"、"山"や"川"等の名詞がシャッフルされ、
違和感しか感じない桃太郎が出来上がります。(やりました!!)
昔々、あるところに川とお婆さんが住んでいたそうな。桃はお爺さんへどん刈りに、どんはお婆さんへ洗濯に向かいましたとさ。すると、川上から芝ぶらこお爺さんぶらこと大きな山が流れてきました。
最後に
Kuromojiライブラリを使って簡単なサンプルを作ってみました。
いかがだったでしょうか?
とても簡単に解析ができる事が伝われば幸いです。
ここまで読んでいただき有難うございました。
Discussion