こんにちは😊 kesojiです。
Social Databank Tech Blog Advent Calendar 2023の17日目です。
2度目の登場です。今日の担当はshiouraでしたが、急遽代打となりました。
予定外の担当者変更、こんなサプライズもテクノロジーの世界では日常茶飯事ですね。
予定にはありませんでしたが、思わぬチャレンジは新たな発見につながることも。
(※ここまでAIによる代筆)
ソーシャルデータバンク(以下、SDB)ではAWS Enterprise Supportを契約しています。契約をしていることで、AWSを利用している上で起こったことの質問対応だけでなく、より密にいろいろな相談ができます。
その中でデータ分析に課題を持っており相談したところ、今回AWSさんが「データ分析/活用ワークショップ」を企画してくれました。
今回はそのレポートをお届けします。
開催のきっかけ
AWS Enterprise Supportでは月次の定例を開催しており、その中で現在のプロダクトやインフラの課題について共有することがあります。
現在の課題として、以下のようなものがありました(あります)。
- インフラ目線: レジリエンスの向上、コスト削減のために、最適なAuto Scalingを設定したい
- そのために、何のメトリクスをAuto Scalingの指標とすべきか
- そのメトリクスをどうやって取得するか
- そのために、何のメトリクスをAuto Scalingの指標とすべきか
- プロダクト目線: 利用率、解約率、MRRといった一般的な指標が正しく取れていない/運用できていない
- そもそも「データを使う」という意識や意義が発展途上
この課題にアプローチすべく、AWSさんからワークショップの提案を頂きました。
SDBのメンバーとしては、AWSの運用担当のインフラチームと、 PM/PjMを行う企画チームから数名が参加しました。
前半 SageMaker Canvasハンズオン
まずは、製品紹介がてらAmazon SageMaker Canvasのハンズオンを実施しました。
SageMakerは、個人的には「名前は知っているが使ったことはない」状態でした。
ハンズオンの内容は、デモデータとして以下のような通信キャリアの顧客データを用い、AIで解約予測をするものです。(データの列はかなり間引いています)
| State | Phone | Intl_Plan | Vmail_Plan | Vmail_Message | Day_Mins | Day_Calls | Day_Charge | CustServ_Calls | Churn |
|---|---|---|---|---|---|---|---|---|---|
| VA | 893-6679 | no | yes | 200 | 7.809921212312691 | 5 | 4.8389797082800134 | 6 | True. |
| AL | 968-7223 | no | no | 0 | 2.5592099519628446 | 4 | 4.107720624140598 | 6 | False. |
Amazon SageMaker Canvas自体の利用方法や活用例は調べればすぐ出てくるので、初めて触った身としての使い方以外の所感をいくつか挙げます。
(無料サービスと比べるな / そもそもGoogle SpreadsheetはBIツールじゃない / Tableauならそんなん当たり前にできるぞ / SageMakerはそこがメインじゃない、という批判は甘んじて受けつつ...)
SageMakerは最終目的としては機械学習モデルを作成することですが、その過程としてのBI的な操作がとても簡単でした。 (ここはQuickSightと同じなんですかね。分かっていません)
例えば、以下のように各列に対して、統計情報や欠損値の割合等を簡易的にグラフに表示してくれます。便利。
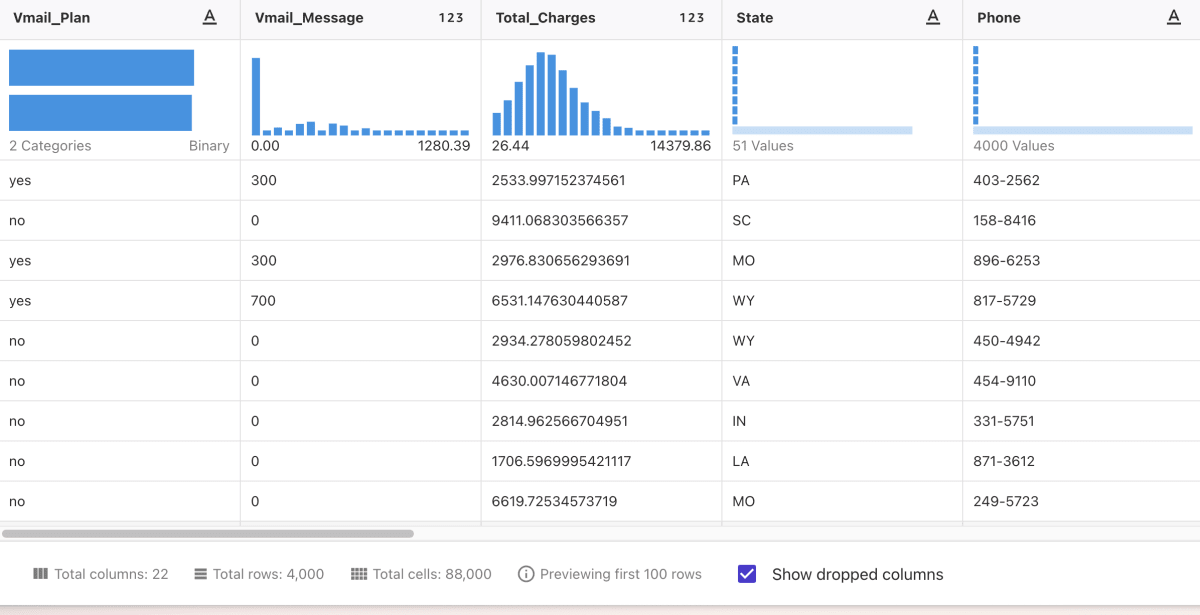
Data Visualizerを使ったよくあるUIも、シンプルながら必要なものが揃っているイメージです。便利。
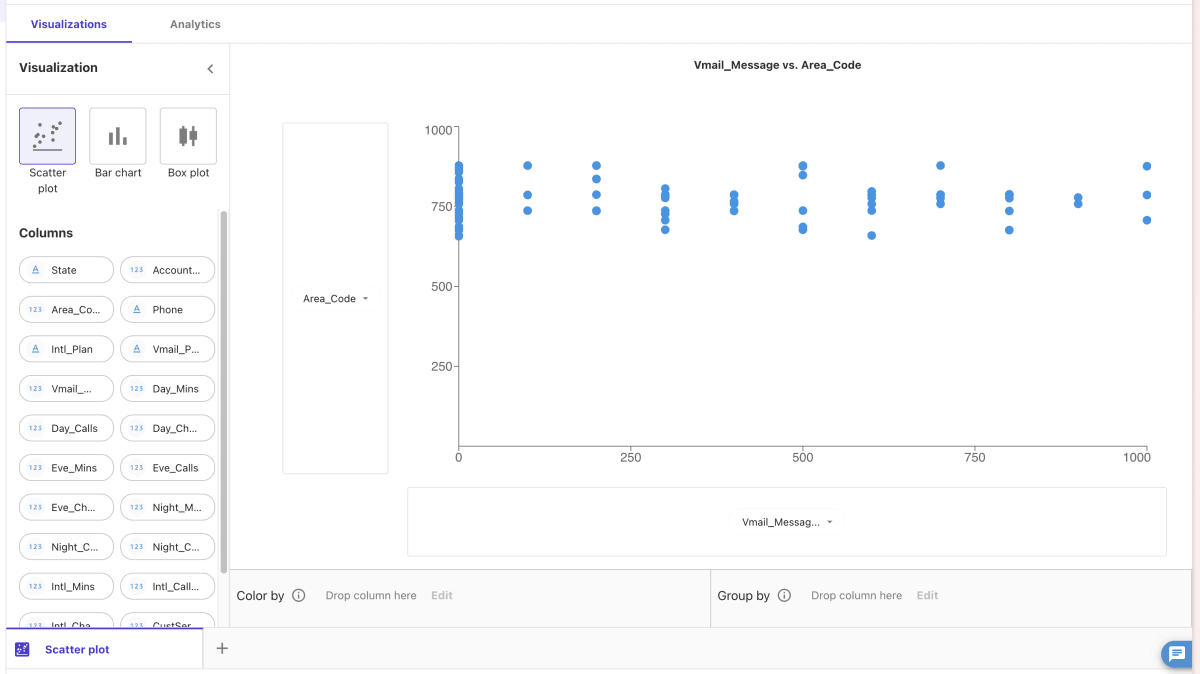
BIツールなら当たり前ではありますが、 ローカルPCのスペックとかに左右されないので、そこそこ巨大なデータもストレスなく扱えるのが良いですね。便利。
AWSの各種データストアと連携できるのも魅力的です。
(SageMakerのメイン用途である)モデルの作成に関しても、ポチポチクリックすれば作成できます。
あまりにも簡単で「これでいいのか?」という気持ちもありましたが、 こういうものと納得することにしました。
意味があるかはさておき「とりあえずデータ投げ込んで予測モデル作ってみるか」みたいなことはとても簡単そうで、心理的ハードルはとても下がりました。
Amazon SageMaker Canvasはセッション時間でお金がかかるため、使い終わったらログアウトは必須です。私は既に1回忘れてアラートが飛んできました。
後半 プロダクトのデータ活用のためのディスカッション
後半は、 実際にプロダクトのデータベースのテーブルやカラム、 取得しているログデータなどを参考にしつつ、 以下の問いかけにチームで考え「何を検証していきたいか」というワークを行っていきました。
- データの理解、分類
- プロダクトにおける主な指標(Major)、 主な分析軸(Dimension) は何か
- プロダクトにおける主な指標(Major)、 主な分析軸(Dimension) を4W1Hで分類できるか
- どのようなものを対比したいか
- どのような傾向を見たいか
- どのような異常に気づきたいか
- ビジネスの検討
- 顧客の重要な指標は何か、なぜ重要か
- 顧客の誰が、どんな時に分析するか。その結果の服ションは
- 主な指標は顧客の何の課題を発見するか
- 主な指標は顧客の何の原因を理解するか
- 主な指標はどんな可視化をすると良いか
- 利用者とは誰か、いつどんな時に何をみるか


このワークの結果、 以下のような検証アイディアがでてきました。
- とりあえず出して眺めてみたい
- ユーザ毎のメッセージ送信数、友だち数のオーダーで分類(ディメンションを作ってみる)
- ユーザ毎の送信メッセージタイプの量で分類(個別の返信 or ターゲティング配信) (ディメンションを作ってみる)
- 業種、用途で比較してみる(既にあるディメンションで分類してみる)
- 異常値を調べてみたい
- 大量にXXを設定している
- 頻繁にXXを更新している
- チャーン予測
- 機能の利用量を算出してみたい
- 開いた数と開いている時間から算出できる?
- ユーザーサポートのデータと連携してみたい
- サポートの利用数で分類(ディメンションを作ってみる)
- LINE友だち(エンドユーザ)の増加パターンを出してみたい
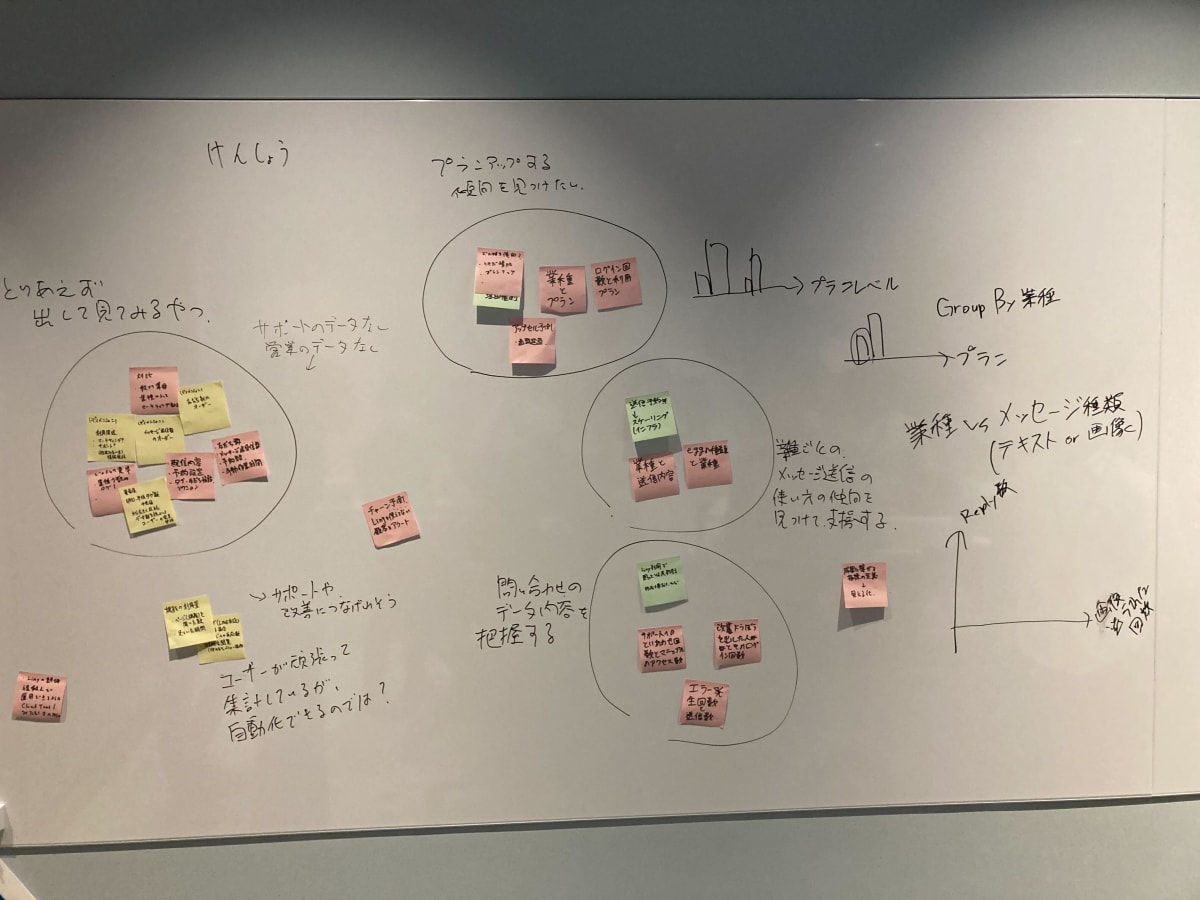
このワークの際、 AWSのSA(Solution Architect)さんも一緒になって考えてくれたり、私たちが考えやすいように深掘り質問をしてくれたりとサポートしてくれました。
現在の担当のSAさんは、「前職では泣きながらBIツールとにらめっこしていた」経歴があるそうです。今回のサポートも頼りになりましたが、実際にデータ分析や予測のフェーズで力をお借りするのが楽しみです。
「こんなデータが欲しいな〜」とあれやこれや考えることはありますが、体系立てたりちゃんと理由付けをして、人と話しながらやるのは新鮮でした。
ネクストアクション
このワークショップにはまだ続きがあります。
弊社側で後半に出てきたアイディアをいくつか実践してみて、 その結果の共有をAWSさん交えて行います。
そして、実践の過程で出てきた課題や、今後のステップなどをディスカッションしていきます。
...実践しなきゃ。実践編のレポートをお楽しみに...!

Discussion