Web上のドキュメントから良い感じに質問へ回答する v0.1


TLDR
Web上の技術ドキュメントを参照し、良い感じに質問へ回答するWebサービスを作ってる途中経過のアウトプットです。
インデクサとリトリーバを工夫をすることで、インデクサはほぼGPT-3.5のみで低価格に、リトリーバは具体的なコードを参照して高精度に回答できます。
RAG技術
RAG(Retrieval-Augmented Generation)はLLM(Large Language Model)のインプットにコンテキスト(付加的な情報)を与えることで、回答を高精度にする技術の総称です。
一概にRAGといっても範囲は(以下の図からも分かるように)広いですが、コンテキストのインデクサとリトリーバを備えていることが多いです。
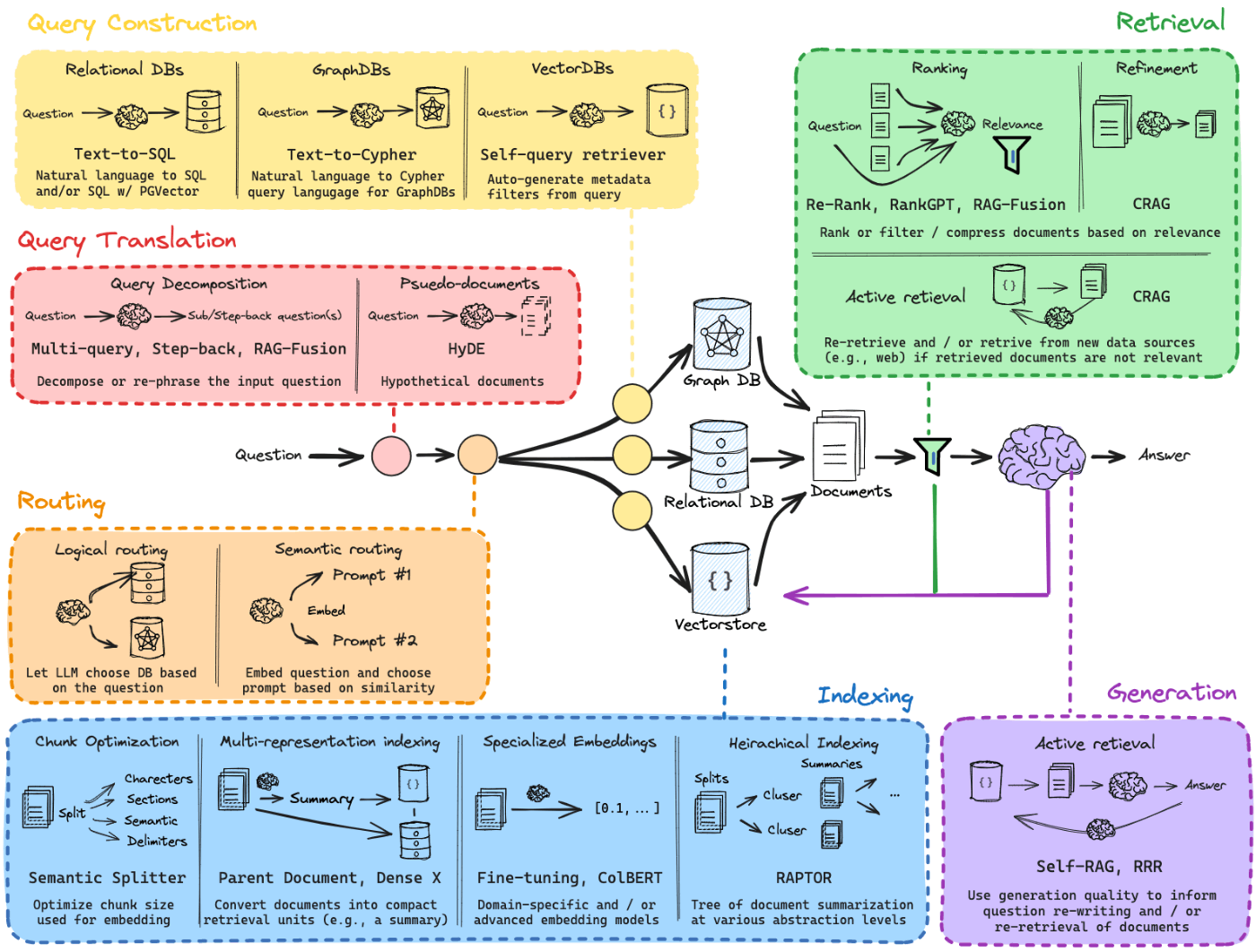
https://github.com/langchain-ai/rag-from-scratch より引用(ちなみに、この「RAG from scratch」シリーズは動画があり、RAGの基礎から回答精度向上のテクニックまで紹介されていておすすめです)
背景
技術文書、読むの面倒じゃないですか?
私は面倒です。読みたくないです。
技術文書は大抵の場合、何かが知りたくて読むものだと思うので、それならRAGを使いたいと思うのは自然かと思います。
そこで、Web上の技術ドキュメントを参照し、良い感じに質問へ回答するWebサービス(DoQLM)を作成しようと思いました。
DoQLMの俯瞰図
DoQLMは以下のような感じです(色々省略してます、謎に雑英語なのはご勘弁ください)。
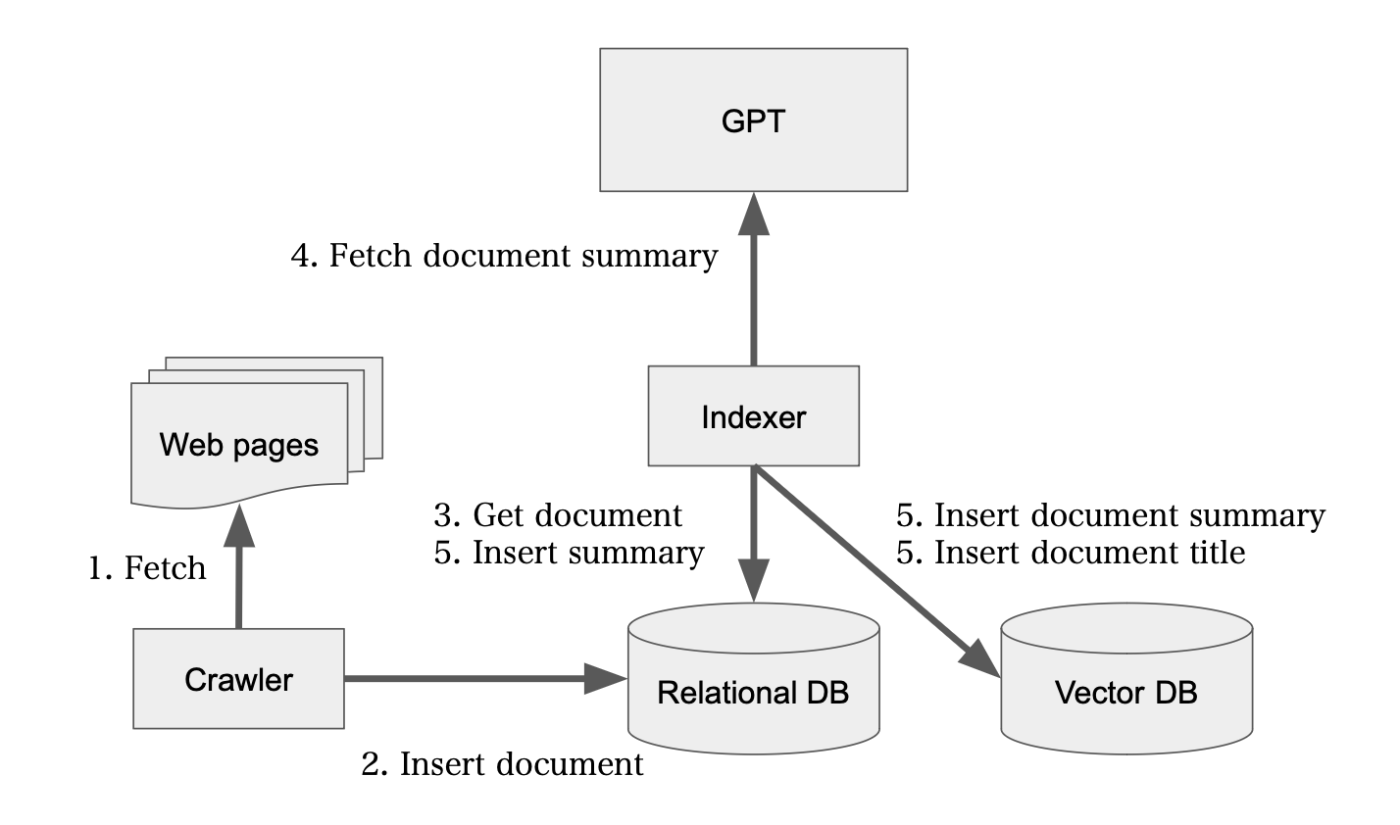
インデクサ
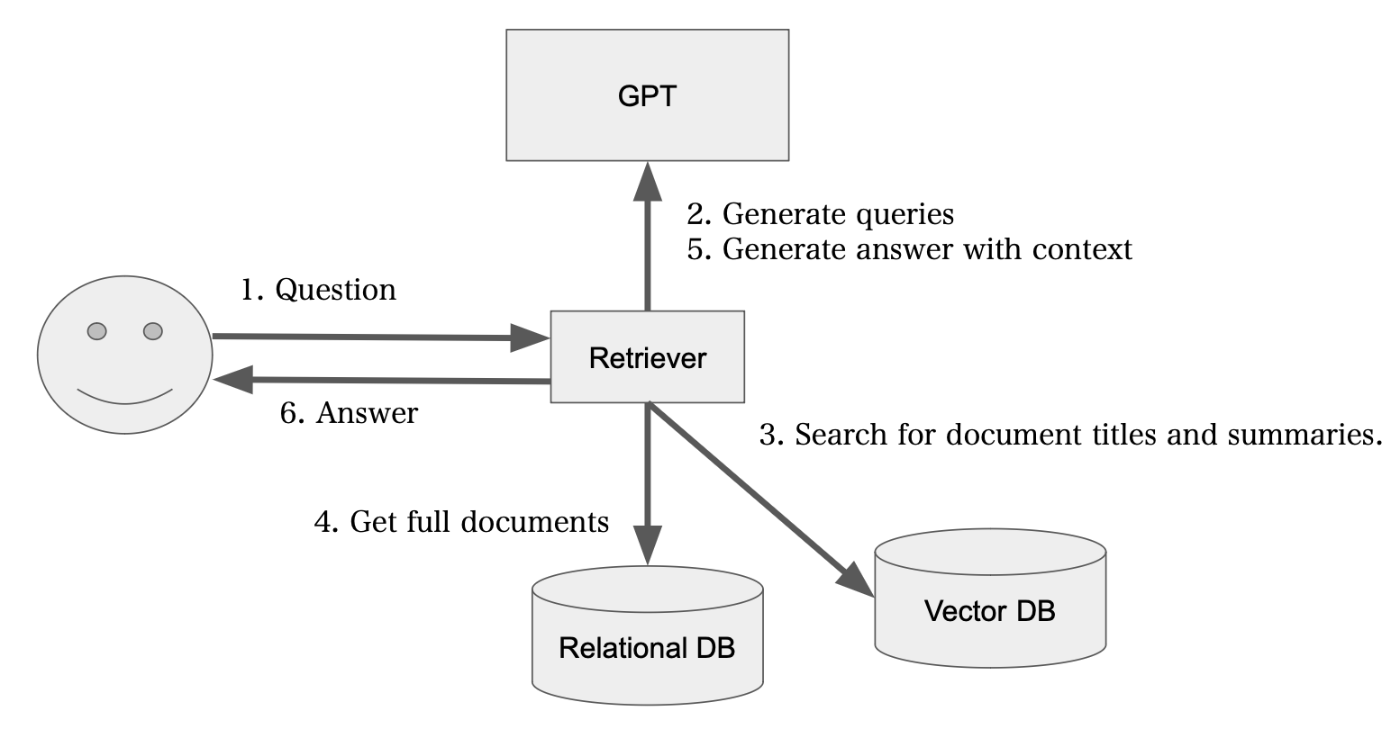
リトリーバ
インデクサ
処理工程
- クローラ
- 与えられたリンクからクロール処理開始
- サイト内のリンクを辿り、全てのページをHTMLからMD(マークダウン)に変換し、RDBに挿入
- 要約作成
- RDBからMDを取得し、コードブロックのリストを取得
- それぞれのコードブロックを要約し、MDを更新
- コードブロック要約済みのMDをRDBに保存
- GPTで要約を作成
- 要約したドキュメントとページのタイトルをベクトルDBに挿入
工夫
MD変換、コードブロックの要約
MD変換はHTMLのタグを除去するためにやっています。
またコードを自然言語に変換することで、コードの持つ意味だけを抽出しています。
これらはコンテキスト長を減らすためにやっています。
この処理によって、一つのページを複数に分けなくても(チャンキングせずとも)、ほぼ全てのページでGPT-3.5を使って要約を生成できます。
要約をベクトルDBに挿入
多くのドキュメントが保存されているベクトルDBで短いクエリから長いドキュメントを検索するのは精度がとても落ちます(経験則)。
そこでパッと思いつく精度を向上する方法として、
- ドキュメントを短くする
- クエリを長くする
- ドキュメントの検索対象を狭める
があると思います。
今回はQ&Aシステムという性質上、クエリを長くするのは向かないかなと思い1を使いました。3はリトリーバで実装できます(ベクトルDBの検索時にフィルタリングするため)。
もちろん、1,2,3全部使うのもありだと思います。
リトリーバ
リトリーバは現状イマイチで改善中ですが、一旦v0.1での報告です。
処理工程
- ユーザの質問からいくつかのクエリを生成
- クエリから、ページタイトルと要約済みドキュメントのベクトルDBを検索
- 検索でヒットしたドキュメントをRDBから取得
工夫
いくつかの異なるクエリを生成する
ユーザからの質問から検索のクエリをいくつか作成しています。
これはユーザの質問を答えるのに必要な情報を、より多く取得するために実装したプロセスです。
タイトルと要約からドキュメントを取得
タイトルと要約文という2つの検索対象を作り、その2つに対してクエリを実行しています。
上記では検索方法をいくつか作りましたが、この場合は検索対象を複数作っています。
取得したドキュメントのランク付け
今のところ、取ってきたドキュメントのランク付けは適当にしてます。
改善予定のポイントです。
コードブロック要約の復元
コードブロックを要約したドキュメントをGPTに投げて、ユーザの回答に必要なコードブロックを抽出します。
これはインデックス作成でコンテキスト長を節約するために必要となった処理です。
現状の実行結果
LangchainのPythonドキュメントをクローリングしました。
1400程度のページがありましたが、インデックス作成にかかったお金は4.5ドル程度です。
いくつかの質問をしてみます。
What is langchain
これくらいの質問ならGPT-4くんで一発ですが、一応やってみます。
GPT4

DoQLM

What kind of Text Splitters are there in LangChain
GPT4

DoQLM

はい、正確っぽいです。
むすびに代えて
現在まだ開発中ですが一旦アウトプットということで、今回の記事にしておきます。
皆さまに使っていただけるようになった際には、もう一度アナウンスするつもりです。
当たり前ですが、全ての工夫を自分で考えついてはないです。ネット上の情報を参照しつつこのサービスに合わせて実装してます。
私は現在、LLMの知見などを深めている最中です。
コラボ等ご用の方御座いましたら、X(Twitter)までお知らせください。
Discussion