LoRA の論文紹介
はじめに
- 本記事はとある勉強会で使用したものです。
- 10 分程度の発表を想定していますので、詳細については触れません。
- 対象の論文は以下となります。
LoRA とはなにか
LoRA とは Low-Rank Adaptation の略称です。その名のとおり Adapter の一種と考えることができますが、 Low-Rank が意味するところは次式で端的に表されます。
ここで
これを模式的に表したものが下図となります(計算にあたっては
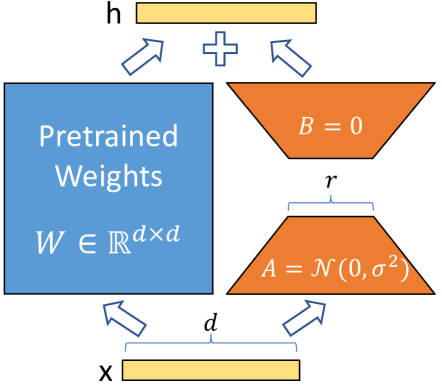
LoRA の模式図
LoRA にはどんな特徴があるか
本論文では LoRA の優れている点が 4 つ挙げられています。
- ベースモデルを固定し、 LoRA 層を可変とすることで、タスクの切り替えが容易にできる。
- 低次元である LoRA 層のみが最適化の対象となるため、より効率的に計算することができる。
- LoRA 層は線形写像であるから、ベースモデルにマージすることができる。
- Prefix-Turning のような既存の様々な手法と組み合わせて使用することができる。
たとえば 2 について、
LoRA の性能はどうか
他の手法との性能を比較したものが以下 3 つのテーブルとなります。特に Fine-Tuning (FT) と比べると、他の Adapter と同様、パラメータの数を大幅に抑えることができています。また、多くのタスクで LoRA がより高い性能を示しています。
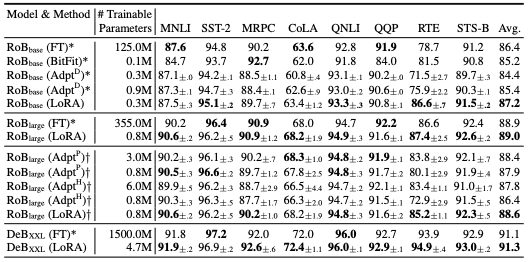
RoBERTa base/large と DeBERTa XXL における性能
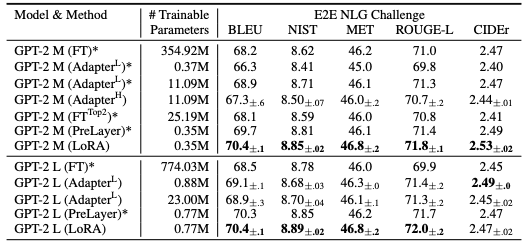
GPT-2 medium/large における性能
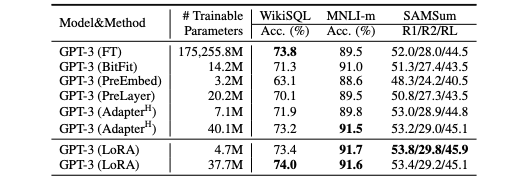
GPT-3 175B における性能
さらに GPT-3 175B における精度とパラメータ数との関係を見てみると、 LoRA が比較的安定した性能を発揮していることもわかります。
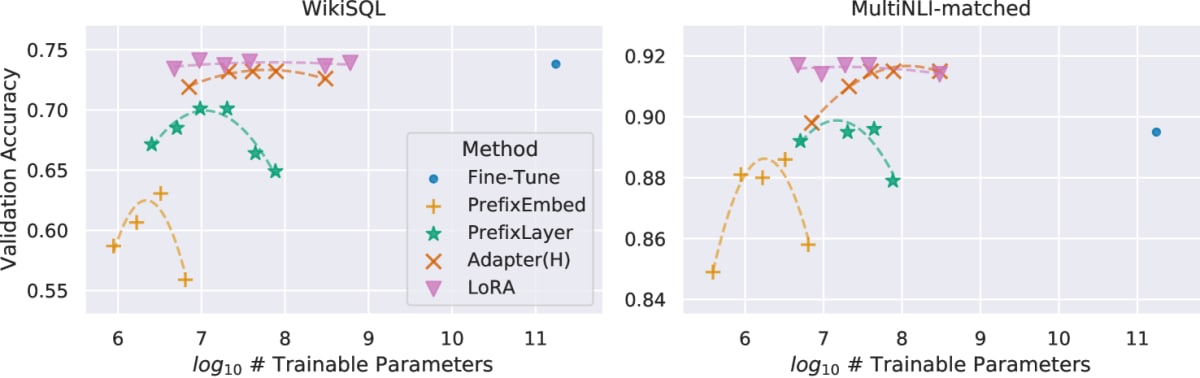
精度とパラメータ数
LoRA 層でなにが起きているのか
ここで、
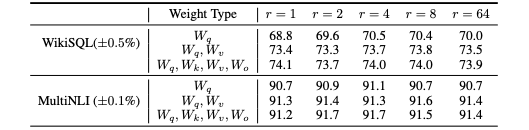
最適化する層やランクによる性能の違い

GPT-3 48 層目における Frobenius norm
おわりに
これまで見てきたとおり、 LoRA の原理自体は非常にシンプルです。線形変換をしているだけなのにも関わらず、場合によっては Fine-Tuning よりも高い性能が出るというのも非常に興味深い点かと思います。 LoRA 層(の線形性)が知識を強調する、という解釈が妥当かどうかはもう少し検証が必要なようにも感じましたが、これにより物事の抽象度が判別できるようになるのだとしたら、知識の習得過程についてもおもしろい議論ができるかもしれません。
今回は LLM の論文をちゃんと読むのは初めてだったということもあり、前提知識を整理するのにとても時間がかかってしまいました。 はじめに「詳細については触れません」と書きましたが、「詳細については説明できません」というのが正直なところなので、注意機構や Transformer についての理解もこれから深めてゆければと考えています。
Discussion