Google の Gemma 3 を解説して試してみる
tl;dr
- Google の Gemma シリーズの最新版 Gemma 3 が発表されたよ
- 1B / 4B / 12B / 27B の事前学習済み / 指示学習モデルがあるよ
- マルチモーダル対応、ロングコンテキスト、多言語対応、数学やコーディングタスクで性能が向上したよ
- Shield Gemma 2 というテキストと画像の両方を入力できる有害コンテンツ検出モデルもあるよ
- transformers / Ollama で動かしてみたよ
Gemma 3 とは
上記の記事に沿ってまとめていきます。
初見の方でも Gemma 3 という名前から察することのできるように、Gemma / Gemma 2 からの系譜な訳ですが、Google のオープンウェイトモデルの最新版が今回発表された Gemma 3 です。Gemma 2 まではマルチモーダルモデルといえば PaliGemma という別のモデルが存在していましたが、今回の Gemma 3 ではマルチモーダルモデルとして、画像入力部分の統合がなされました。
また、ロングコンテクストウインドウ(128k)や多言語対応(140 以上の言語)、数学や Reasoning の性能も改善し、Structured Outputs / Function calling にも対応しています。
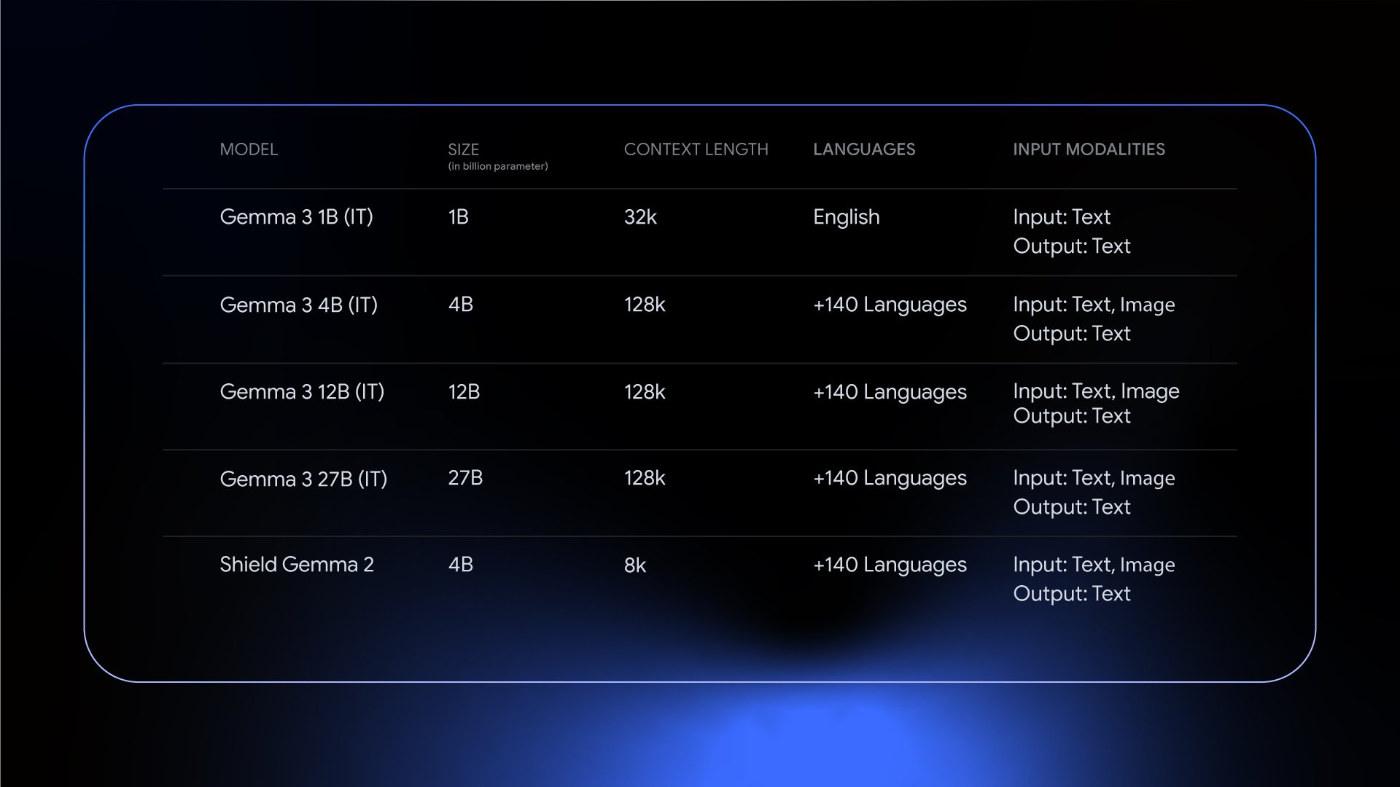
パラメータ数としては 1B / 4B / 12B / 27B の四つのモデルラインナップで、事前学習済みモデルと指示学習済みのモデルのそれぞれが公開されています。のちほどモデルコレクションの部分にて触れますが、モデル名の -pt / -it のサフィックスがそれに対応します。記事内の画像を引用しますと、1B のモデルだけはさすがにパラメータ数が小さすぎるのか、英語のみの対応、テキスト入力のみの対応となっています。
Gemma 3 のモデルの学習周りの話。事前学習、事後学習のどちらにおいても、蒸留、強化学習、モデルマージを組み合わせていることが明示的に書かれています。これらにより数学やコーディング、指示追従性能が向上されているようです。多言語対応を謳っているようにトークナイザーも新しくなっています。Google TPU x JAX フレームワークを用いて学習されています。
また、4 つのコンポーネントとして書かれているうち蒸留以外のものは強化学習となっており、かの有名な Reinforcement Learning from Human Feedback (RLHF)だけでなく、Reinforcement Learning from Machine Feedback (RLMF)や Reinforcement Learning from Execution Feedback (RLEF)を用いて、数学的推論タスクやコーディングタスクの性能向上を図っています。
こうした工夫により、LMArena というもともと LMSys が運営していたベンチマークにおいてスコア 1338 を達成、オープンコンパクトモデル(27B がコンパクトという基準になりつつある笑)のトップの成績を納めました。とありますが、個人的に 70B オーダーのモデルはもちろん、671B の DeepSeek V3 よりもスコアが高いのはかなり期待値が高いです。

Gemma 2 にはなかった画像の入力を受け付けているため、少しトークンの与え方が異なっています。
マルチターンのテキスト入力の例
<bos><start_of_turn>user
knock knock<end_of_turn>
<start_of_turn>model
who is there<end_of_turn>
<start_of_turn>user
Gemma<end_of_turn>
<start_of_turn>model
Gemma who?<end_of_turn>
画像入力を挟んだ例
<bos><start_of_turn>user
Image A: <start_of_image>
Image B: <start_of_image>
Label A: water lily
Label B:<end_of_turn>
<start_of_turn>model
Desert rote<end_of_turn>
Gemma 3 のマルチモーダル対応について、Vision Encoder として SigLIP を採用、画像と動画の入力を受け付けられるようになっています。ユースケース例としては、画像に関する質問に答えるといったよくある例はもちろん、画像の比較や分析、オブジェクトの識別、画像内のテキストに関する応答などが挙げられています。もともとは 896px x 896px の画像を想定していたようですが、Pan & Scan (P&S) という入力した画像を特定の縦横の画像に分割し、896px x 896px にリサイズしてエンコーダーに渡す Adaptive Window Algorithm を用いることで、高解像度や非正方形の画像にも対応できるようになっています。
最後に ShieldGemma 2 について書かれています。Gemma 3 をベースとした 4B の画像入力を受け付ける安全性分類モデルで、入力と出力の両方において有害コンテンツを検出します。
とりあえず記事についてはこのくらいにして、モデルカードを見ていきます。
Gemma 3 とその関連モデルについては上記の Hugging Face Hub のモデルコレクションにて公開されています。それぞれのパラメータ数を含むモデル名の最後のサフィックスが -it / -pt になっていますが、それぞれ Instruction Tuned / Pre-trained を意味しているかと思われます。つまり、少し試してみるのであれば -it の方が良いかと思います。
いちばん大きな 27B の -it を見てみます。これまでと重複していない箇所について見ていきます。
データセットに関して、27B のモデルは 14 兆トークン、12B のモデルは 12 兆トークン、4B のモデルは 4 兆トークン、1B のモデルは 2 兆トークンのデータセットで学習されています。内訳としては、140 言語以上のウェブから取得したドキュメント、コード、数学、画像の 4 つ。データセットの前処理としては、有害・違法コンテンツを防ぐための CSAM フィルタリング(Child Sexual Abuse Material)、個人情報や機密情報のフィルタリング、その他ポリシーに沿った安全性フィルタリングが施されています。
ハードウェアに関して、TPU と先ほど書きましたが、具体的には TPUv4p、TPUv5p、TPUv5e を用いて学習が行なわれ、VLM の学習に TPU が役に立ったと記載があります。ソフトウェアは JAX と ML Pathways を用いて学習が行われています。このふたつはあんまりわからないので気になる方は調べてみてください。
ベンチマークについて、Gemma 3 同士でいろいろと評価されていますが細かい話なので興味のある方は見てみてください。
安全性に関しては、内部レッドチーミングを実施し、子どもに関する安全性やコンテンツそのものの安全性、有害な表現がないかなどについて検証され、改善されました。ただし、評価は英語のプロンプトについてのみ行なわれた点が限界とあり、個人的にはマルチリンガルでの安全性を担保するのは難しいなと感じました。
あとは細かい話なので良いでしょう!
最後にテクニカルレポートと Vertex AI のモデルガーデンと Google AI Studio のリンクをおいて解説は終わりにします。
Google AI Studio にて Gemma 3 27B が使えるようになっています。
Transformers で Gemma 3 を試す
とりあえず Gemma 3 27B it を動かしてみます。ご自身の環境に合わせて実行コマンドを変えてください。私は Mac Studio M2 Ultra にて動かしています。
お好きなモデルをまずはモデルコレクションから選んでダウンロードしましょう。
huggingface-cli download google/gemma-3-27b-it
huggingface-cli download google/gemma-3-12b-it
huggingface-cli download google/gemma-3-4b-it
huggingface-cli download google/gemma-3-1b-it
CLI で動作確認したいだけなのでワンライナーで実行します。
uv run --with "git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3",torch,pillow,accelerate python -c "from transformers import pipeline; import torch; pipe = pipeline('image-text-to-text', model='google/gemma-3-27b-it', device_map='auto', torch_dtype=torch.bfloat16); messages = [{'role': 'system', 'content': [{'type': 'text', 'text': 'あなたは役に立つアシスタントです。'}]}, {'role': 'user', 'content': [{'type': 'image', 'url': 'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG'}, {'type': 'text', 'text': 'キャンディに描かれている動物は何ですか?'}]}]; output = pipe(text=messages, max_new_tokens=200); print(output[0]['generated_text'][-1]['content'])"
モデルカードのサンプルにある画像は M&M's のチョコっぽい。原文がキャンディになっているのでそのまま翻訳して投げました。

Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:26<00:00, 2.22s/it]
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.48, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Device set to use mps
写真に写っているキャンディには、次の動物が描かれています。
* オレンジ色のキャンディには、**ハチドリ**が描かれています。
* 青緑色のキャンディには、**カタツムリ**が描かれています。
* 緑色のキャンディには、**カメ**が描かれています。
ちょっとうまくいっていないですね。これが日本語の問題なのか切り分けたいので英語でも試してみます。
uv run --with "git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3",torch,pillow,accelerate python -c "from transformers import pipeline; import torch; pipe = pipeline('image-text-to-text', model='google/gemma-3-27b-it', device_map='auto', torch_dtype=torch.bfloat16); messages = [{'role': 'system', 'content': [{'type': 'text', 'text': 'You are a helpful assistant.'}]}, {'role': 'user', 'content': [{'type': 'image', 'url': 'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG'}, {'type': 'text', 'text': 'What animal is on the candy?'}]}]; output = pipe(text=messages, max_new_tokens=200); print(output[0]['generated_text'][-1]['content'])"
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:26<00:00, 2.21s/it]
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.48, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Device set to use mps
Based on the image, the animal on the candy appears to be a **turtle**. You can see the shape of the shell and the head/legs of a turtle printed on the orange and green candies.
英語だとうまくいきました。日本語性能が高くなくとも英語であればうまくいくひとつの事例になりました。多言語対応って難しいですね!
Ollama で Gemma 3 を試す
Gemma 3 は既に Ollama Library 経由でダウンロードできるようになっています。Q4_K_M ですので、4 つすべて合わせて 30GB 程度必要です。
ollama pull gemma3:27b
ollama pull gemma3:12b
ollama pull gemma3:4b
ollama pull gemma3:1b
たとえば 27B のモデルを推論する場合は以下のように実行します。--verbose オプションをつけておくと推論速度などが表示されるのでおすすめです。
ollama run gemma3:27b --verbose "こんにちは!あなたの名前はなんですか?"
こんにちは!私の名前はGemmaです。Google DeepMindによってトレーニングされた大規模言語モデルです。
total duration: 6.275726166s
load duration: 4.489050125s
prompt eval count: 17 token(s)
prompt eval duration: 1.008s
prompt eval rate: 16.87 tokens/s
eval count: 21 token(s)
eval duration: 776ms
eval rate: 27.06 tokens/s
MLX で Gemma 3 を試す
モデルはあるもののまだ動かすことができませんでした。
以上となります。お読みいただきありがとうございます。よかったらフォローしていただけると励みになります!
Discussion