並行処理の基礎知識をハードウェアとOSレベルから理解したい
並行処理について、大雑把なイメージではなくハードウェア、OSレベルでどのように具体的に実現されているのかを知りたくて調べてみました。
この記事はプログラムのコードを用いて解説する部分はありませんので、並行処理そのものについて知りたい方ならどなたでもご覧いただけます。
間違いのある箇所がありましたらご指摘いただけると嬉しいです。
話すこと
- 並行処理とは?
- 並行処理はなぜ必要?
- 並行処理を実現する仕組み
- 並行処理の注意事項
話さないこと
- 並行処理プログラミング
- 特定の言語の並行処理の内部実装
並行処理に関する知識はハードウェアやOSに関する話も多く登場しますし苦手な方も多いかとは思いますが、正しい理解のために抽象的な例えを用いて話すことはせずにあえて具体的に話していきます。
なお、記事のボリュームが大きいので、ここでは具体的な並行プログラミングのテクニックについては扱いません。
並行処理とは?
並行処理というと皆さんはどのようなものを思い浮かべますか?
自分は最初、ブラウザやOSのように「同時に色々な処理をすることかな」なんて思っていました。
残念ながら私は「並行」と「並列」を混同してしまっていました。
Concurrency is not Parallesism by Rob Pike
※ 動画内のスライド
並行処理を勉強しはじめたころに見たのがこの動画です。
Rob Pike氏はGoの言語開発者の1人であり、動画内では「並行」と「並列」の違いについて述べられています(動画前半はGo固有の話ではなく一般的な並行・並列性の知識について語られています)。
彼は動画内で次のように述べています。
Concurrency is about dealing with lots of things at once.
並行性とは、一度にたくさんのことを扱うことだ。
Parallelism is about doing lots of things at once.
並列性とは、一度にたくさんのことをすることだ。
Not the same, but related.
(2つは)同じものではないが、関連している。
Concurrency is about structure, parallelism is about execution.
並行性は構造に関するもので、並列性は実行に関するものだ。
Concurrency provides a way to structure a solution to solve a problem that may (but not necessarily) be parallelizable.
並行性は、並列化可能かもしれない(必ずしもそうではない)問題を解決するための解決策を構造化する方法を提供する。
ここで特に重要なのは並行性は構造に関するもので、並列性は実行に関するものだの部分です。
これはどのような意味でしょうか?
いくつかの並行処理に関する本も読みましたが、総括すると次のようなことだと理解しました。
並行性というのは、システムが複数のスレッド(あるいはプロセス)を実行状態※に保てるプログラムの構造を備えていること
=> プログラムの構造的な性質
並列性というのは、全くの同タイミングで複数の動作を同時実行できること
=> プログラムの実行時の性質
※ あるスレッドが実行中であるとOSが認識しており、メモリ上のどこかに当該スレッドの情報が格納されている状態。そのスレッドが実際にCPUで処理されているかは問わない
並行性は、複数のスレッドが実行状態となるようにプログラムが構成されていればよく、並列性と違って全く同時に実行されている必要性はありません。
また、Rob Pike氏は並行性について、このように述べています。
(Concurrency is )Programming as the composition of independently executing processes.
並行性は独立して実行されるプロセスの構成としてプログラミングされる
(Processes in the general sense, not Linux processes. Famously hard to define.)
(Linuxのプロセスではなく、一般的な意味でのプロセス。定義が難しいことで有名)
このことからも、並行性というのはプログラムの構造にフォーカスしたものであると理解しました。(ただ、Rob Pike氏の発言はどちらかというと並行性というより並行プログラミングのことかな?そこまで読み取れませんでした。。)
実際、並行処理を用いて組まれたプログラムはタスクを複数スレッドに分解して実行状態とし、どのような順序で処理するかはOSや言語のランタイムに任せるのでマシンのコアがシングルなのかマルチなのかは気にしません。
一方、並列性は全く同時に複数動作が行われてなければならないため、実現するにはマルチコアであることが前提になります。CPUコアが一つでは全く同タイミングに複数の処理は実行できません。
冒頭に戻ると、私は並行処理を「同時に色々な処理をすること」だと思っていたわけですが、これは実行時の性質を話をしているので並列性のことであったというわけです。
ちなみに、並行性と並列性はどちらかしか取りえないものではなくそれぞれ独立しています。
例えば、並行性を有するプログラムがマルチコアで同タイミングに動作していれば、それは並行性と並列性を両立していることになります。
並行処理はなぜ必要?
ここからは並行処理が私たちにもたらす恩恵について見ていきます。
並行処理は、マルチコアプロセッサが当たり前の現代において下記の2点を実現するためであると理解しています。
- パフォーマンス向上
- 同時実行
1つずつ見ていきます。
パフォーマンス向上
私たちが普段書いているコードは(コンパイラもしくはインタプリタによって機械語に変換されてから)上から順に逐次的にCPUによって実行されます。
そして、処理の中にはI/O処理やスリープなどCPUに「待ち」時間を生じさせるものがあります。
この「待ち」の時間、CPUを眠らせておくのは勿体無いと思いませんか?
並行処理によって、このCPUの「待ち」の間に他の処理を実行することができるため、処理の総量が増えてスループットも上がります。
また、CPUのコア数が複数あるのであれば、並行処理によってタスク(実行されるプログラム)をそれぞれ異なるコアに処理させることができるため、これまたスループットが上がります。
同時実行
あなたは今ブラウザを開いてZennを見ているわけですが、おそらく他にも何か、LINEやYoutubeなどのアプリケーションを立ち上げているのではないでしょうか?
スマートフォンやPCが常に一つのアプリケーションしか実行できないというのでは困ります。
複数のアプリケーションを同時に実行できている(ように見せることができている)のは、OSが並行処理によって各アプリケーションにCPUの利用時間を分散しているからに他なりません。
並行処理を用いて書かれたプログラムは「待ち」のタイミングに限らずとも、OSや言語のランタイムによってCPUへの割り当てが切り替えられます。
それにより、「アプリAの操作が完了するまでアプリBを動かせない」ということにはならず、「アプリAとアプリBが同時に動いている」(ように見せる)ことができます。
また、現実世界のすべての事象は独立して発生し、同時進行しています。
例えば、スマートフォンを例に考えてみます。あなたは同時に音楽を聴きながら、SNSの通知を受け取り、通話もしているかもしれません。これらはすべて、現実世界で独立して同時に起こっているイベントです。もしこれらを直列に、つまり一つずつ順番に処理するプログラムで実現しようとすれば、どれか一つの処理が終わるまで他の処理が待たされ、ユーザーは不便さを感じるでしょう。
これをプログラムで再現するには、各事象を独立したタスクとして並行処理しなければなりません。つまり、現実世界がもともと並行に動作しているため、その動きを忠実に模倣するためには、プログラム上でも並行処理が必要なのです。
このように、並行処理によってもたらされる恩恵はとても大きなものです。
しかし、無闇に使うべきではありません。
並行処理がどのような仕組みで動作しており、どのようなトレードオフによって上述のメリットを生み出しているのかをきちんと理解することが重要です。
並行処理を実現する仕組み
並行処理の理解のためにCPU、OS、プロセス、スレッドについて解説していきます。
CPUの話
普段私たちが書いている高水準なプログラムは機械語に変換され、CPUで処理されています。
具体的に、プログラムがどのようにCPUで処理されているのかを少し見てみます。
現代のコンピューターの基本的な構成はノイマン型と呼ばれ、下記の特徴があります。
- CPUを中心とし、入力デバイスから受け取ったデータをCPUで演算してから出力デバイスへデータを送信する
- 実行するプログラムもデータも区別せずに記憶装置(メインメモリ)に格納する
図にするとこんな感じです。(mermaidなので若干図の配置がおかしいのは許してください。。)
私たちが書いたプログラム(の命令)自体もデータと同じようにメインメモリに格納されているという点は意識しておいてください。
このうち、CPUの部分に着目すると、ALU・レジスタ・制御装置と呼ばれるものが含まれています。
まず、ALUは"arithmetic logic unit"という名前の通り、加算器をはじめとする様々な論理回路によって構成される算術論理演算装置です。
高速でビット演算を行うことで実際の演算処理を担っています。
つまり、最終的に機械語の命令を実行する部分です。
次に、レジスタという、一時データを格納するための記憶装置もCPUには備わっています。
レジスタはいくつか種類があり、プログラムが処理に利用するデータのメモリアドレスを記憶するアドレスレジスタや、次に実行する命令を格納するPCレジスタなどがあります。
レジスタに格納された値はALUでの演算に使用されることとなります。
最後に、CPUには制御装置と呼ばれるものも備わっています。
これは、高水準言語から生成された機械語の命令をメモリからフェッチし、CPUの各装置(レジスタ、メモリ、ALUなど)で扱えるようにデコードし、命令を実行します。
そして、この動作を繰り返すことでプログラムは実行されていきます。
といった感じで、制御装置がALUやレジスタなどを操作して私たちが書いたコードは実行されていくのが基本的な流れです。
ここではひとまず、私たちのプログラムがCPUで処理される際には必要な情報をレジスタから(あるいは経由して)参照してALUで演算しているのだと覚えておいてください。
OSの話
OS(operating system)とは、ハードウェアとアプリケーションとの架け橋となるための様々な基本機能を備えたソフトウェアです。
皆さんが普段使っているコンピュータやスマートフォンにも必ず搭載されています。
OSはCPU、メモリ、IOデバイス(キーボード・マウス・スクリーンなど)、ディスクなどのハードウェアをアプリケーションから利用できるように抽象化してくれます(プログラミングしていてCPUやMMUを直接操作することはないですよね)。
主に、OSは下記のことをしてくれています。
ハードウェアの持つ物理的制約の緩和
例えば物理メモリは容量や配置に制限がありますが、OSは仮想メモリ管理機能により、各プロセスに対して独立した大容量の仮想アドレス空間を提供し、メモリ不足や断片化の問題を緩和してくれます。
ハードウェアの詳細の隠蔽
例えばキーボードから文字を入力した場合のOSの働きを考えてみます。
キーの押下によってスキャンコード(キーボードからCPUに送信される符号)がキーボードから送信され、BluetoothやUSBがそれをコンピュータへ転送します。
この時点ではプログラマが普段目にするASCIIなどの文字コードではありません。
その到着がOSに知らされる(割り込みされる)と、OSはコードをASCIIやUnicodeに変換し、OSはアプリケーションにイベントとして通知し、アプリケーションはそれを使用します。
OSがなければ、アプリケーションはキーボードからの入力検知、コード変換、アプリケーションへの通知などの様々な処理を実装しなければならなくなります(もちろん、そもそもの話OSがないとアプリケーション自体も低レイヤの部分から作り込みが必要です)。
アプリケーション間でのハードウェアの共有
CPUは基本的に1命令ずつ実行されます。
となると、普通に考えると一度に実行できるプログラムは1つだけになる気がしますが、OSによって複数のプログラムにCPUの利用時間が行き渡るようにスケジューリングされています。
つまり、OSによって各プログラムは並行に処理されています。
このように、OSは様々な機能を提供してくれているわけですが、そこにはOSがOSたりうるのに中核的な役割を果たすカーネルと呼ばれるプログラムの存在があります。
カーネルはOSのコア機能であり、CPU・メモリ・IOデバイスなどのHWとのやりとりを抽象化します。カーネルはプロセスではないですが、メモリ上に常駐してシステムコールやIPCの提供、プロセスの管理などをしてくれます。
カーネルは前述の通りメモリ上に常駐しているため、外部からの干渉(ユーザプログラムのバグなど)による影響を受けて止まってしまうことがあっては困ります。
そのため、カーネルにはカーネル空間と呼ばれる仮想メモリ空間とカーネルモード(特権モード)と呼ばれるCPUのあらゆる命令を特権的に実行できる機能を持っています。
カーネル空間にはカーネルの機能が存在しており、それらを利用するにはカーネルモードである必要があります。
カーネルモードとは反対に普段私たちが動作させるプロセスが存在するメモリ空間をユーザ空間と呼び、カーネルモード以外の非特権的な命令実行するモードをユーザモード(非特権モード)と呼びます。
色々書きましたが、並行処理という観点で特に重要なのは、OSによってプログラムが並行に処理されているという点です。
これは、私たちが並行プログラミングをする際にも関わってきます。
そこに言及する前に、OSが並行に処理する実体であるプロセスとスレッドをそれぞれ見ていきます。
プロセスの話
プロセスとは実行状態にあるプログラムです。
ここでいうプログラムとは.binファイルやWindowsなら.exeなどのコンパイルによって生成される、機械語の命令が書かれたファイルのことです。
カーネルはこのプログラムからプロセスを生成します。
プロセスはいくつかのメモリ領域を持っています。
プログラムコードが格納されるコード領域、プログラムの実行に必要なデータが格納されているデータ領域(ヒープもここ)、関数の呼び戻しアドレスやローカル変数を格納するスタック領域です。
プロセス生成時にはカーネルによって最初にコード領域にプログラムが読み込まれ、次にデータ領域やスタック領域が初期化されます。
プロセスのメモリ領域は独立していますので、IPCでデータをやり取りするなどしないとプロセスは他のプロセスの状態を知ることはできません。
プロセスもスレッドも並行動作します。
プロセスを並行動作させるためにOSは実行中のプロセスが持つ様々な情報を極めて短い間隔で高速に切り替えます。
これをコンテキストスイッチと言います。
物理的にいうと、CPUの話で出てきたレジスタに格納されているアドレスの値を他のプロセスの値に切り替えることで実現します。
しかし、プロセスが持つ情報とは、プロセスID、環境変数、CPUの状態(レジスタ)、ファイルディスクリプタ(開いているファイルの情報)、作業ディレクトリ、ページテーブル(仮想アドレスと物理アドレスの対応表)などなど様々なものがありますので切り替えのオーバーヘッドが大きいです。
歴史的にはもともとOSはプロセスのみでプログラムを実行していましたが、プロセスより軽量なスレッドがやがて登場します。
スレッドの話
スレッドとは、OSがスケジューリングする最小の実行単位であり、CPU上で実行される一連の命令の流れです。
プロセスは必ず少なくとも1つ以上のスレッドを含んでいます。
スレッドには大きく分けて2つの種類があります。
カーネルスレッド(OSスレッド)とユーザスレッドです。
カーネルスレッドはカーネル空間で実装され、動作するスレッドです。
Linuxを例にすると、kthread_create() を使ってカーネル空間内でカーネルスレッドを作成できます。
カーネルスレッドはプロセスとは異なりますが、OSによってはスケジューリングやリソース管理の単位として、プロセスと同等の扱いを受けることもあります(Linuxなど)。
コンテキストスイッチはカーネルによって行われます。
それぞれ独立したアドレス空間を持つプロセスとは異なり、あるプロセス上で動作するカーネルスレッド同士は当該プロセスのアドレス空間や開いているファイルディスクリプタなどのリソースを共有します。
そのため、カーネルスレッドのコンテキストスイッチは、同じプロセス内で動作している場合、アドレス空間の切り替えが不要なため、通常のプロセスのコンテキストスイッチより軽量です。
それゆえ、OS(例: Solarisなど)によってはLWP(軽量プロセス)と呼ばれることもあります(LWPという用語の使われ方はOSによって微妙に異なるっぽい)。
次に、ユーザスレッドとはユーザ空間で実装されたスレッドのことです。
ユーザ空間ってなんだ?となる方もいるかと思いますが、これは普段私たちが作成したプログラムのプロセスが動作しているアドレス空間のことです。
ユーザスレッドもカーネルスレッド同様、親プロセスとアドレス空間やファイルディスクリプタなどは共有します。
ユーザスレッドはカーネルスレッドとひもづいており、それによってカーネルにCPU時間を割り当ててもらえます(カーネルはユーザスレッドのことを知りません)。
ユーザスレッドとカーネルスレッドは必ずしも1:1で紐づかなければならないわけではありません。
ユーザスレッドがカーネルスレッドと1:1で紐づいていない場合、ユーザスレッドのコンテキストスイッチはカーネルスレッドよりも軽量です。
カーネルスレッドの場合はカーネルモード(カーネルとしての機能を実行できる権限を有する状態)への遷移やページテーブルの更新が必要ですがユーザスレッドはそれらが不要な場合が多いです。
ユーザスレッドがカーネルスレッドと1:1で紐づいている場合はユーザスレッドは実質カーネルスレッドのようなものなのでコンテキストスイッチのオーバーヘッドは変わりません。
最初この辺りを勉強すると紛らわしいですが、カーネルモードでの特権的機能の利用はカーネルスレッドからでないと行えないわけではないです。
ユーザモードからカーネルモードの機能を利用するのにはシステムコール(ファイルオープンやプロセス生成など)を利用できます。
システムコールを用いると、呼び出し元スレッドからカーネル内にあらかじめ用意された関数を呼び出し(スーパバイザ呼び出し)、この時に自動的にモードがカーネルモードに切り替わります。
そして処理が終わるとまたユーザモードに戻ります。
並行処理の仕組み
冒頭、並行性というのは「システムが複数のスレッド(あるいはプロセス)を実行状態に保てるプログラムの構造を備えていること」だと述べました。
この構造の根本は、OSのスケジューラがCPUに割り当てるプロセスやスレッドを短期間にコンテキストスイッチするとともに、場合によってはユーザスレッドライブラリもさらに細かく動作させるスレッドをコンテキストスイッチすることによって実現されています。
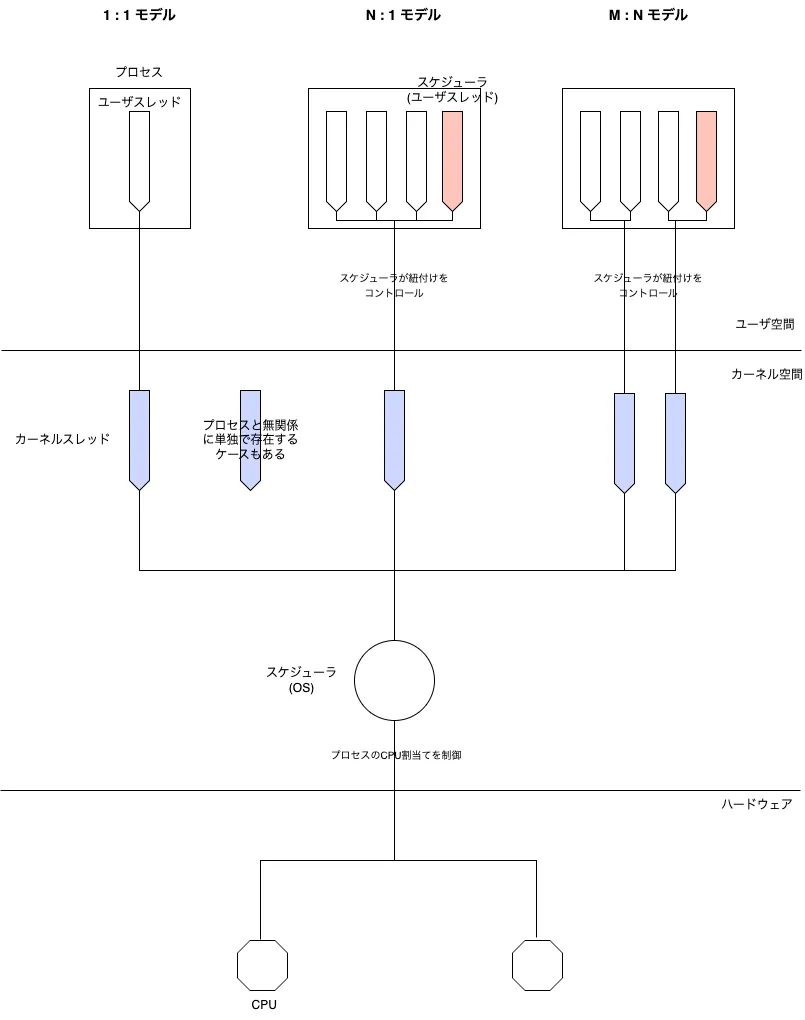
上図はプロセスとスレッドがどのようにCPUによって処理されるのかというこれまでの解説内容を表しています。
図に記載の通り、ユーザスレッドとカーネルスレッドとの間の紐付けのモデルは3種類あります。
1:1モデル
各ユーザスレッドが 1つのカーネルスレッド(OSスレッド)に直接マッピングされます。
このモデルのコンテキストスイッチはカーネルによって行われます。
POSIX Threads、Windowsスレッドなどはこれです。
メリット
- 各スレッドがカーネルスレッドとしてOSに認識されるため、マルチコア環境で複数スレッドが同時に実行されます(並列性が得られる)
- ブロッキング操作がスレッド単なので、nあるスレッドがI/O待ちなどでブロックしても、他のスレッドには影響しません
- ユーザ空間でユーザスレッドを管理しなくてもカーネルがスレッドを管理してくれます
デメリット
- 大量のスレッドを作ると、カーネルスレッドも同数作成されるため、コンテキストスイッチやメモリ使用量が増えます
- スレッド切り替えにはカーネルモードへの遷移が必要なため、コンテキストスイッチはカーネルに依存します
N:1モデル
複数のユーザスレッドが、単一のカーネルスレッド上で動作します。
このモデルのコンテキストスイッチはユーザライブラリによって行われます。
古いJava(Green Threads)などで使われていたようですが、現在ではあまり採用されないみたいです。
メリット
- スレッド切り替えがユーザ空間だけで完結するため、カーネルモードへの切り替えが不要で高速
- カーネルスレッドは1つだけなので、OSのリソース消費が少なくて済む
デメリット
- OSから見ると単一のカーネルスレッドしか存在しないため、マルチコアを活かせず並列実行が起きません
- 1つのスレッドがI/O待ちになると、他のユーザスレッドも同時にブロックされてしまいます
- スレッド管理やスケジューリングをユーザ空間で完全に行うため、ブロッキングを回避するにはノンブロッキングI/Oやイベント駆動を実装する必要があります
M:Nモデル
M個のユーザスレッドを、N個のカーネルスレッドに動的にマッピングするモデルです。
ユーザ空間のスレッドライブラリはユーザスレッドのスケジューリングと、複数あるカーネルスレッドへの紐付けを行います。
このモデルのコンテキストスイッチはカーネルとユーザライブラリの両方によって行われます。
Goのgoroutineや、Erlangのプロセスなどで使用されています。
メリット
- 複数のカーネルスレッドを利用してマルチコア上で並列実行できるうえ、ユーザ空間で大量のスレッド(goroutineなど)を軽量に管理できます
- カーネルスレッド数は抑えつつ、多数のユーザスレッドを効率的に運用できます
デメリット
- ユーザ空間とカーネル空間のスケジューリングを二重に管理する必要があり、ライブラリやランタイムの実装が非常に複雑になります
このように、普段意識していないだけで、使っている言語あるいは実装によってどのモデルで並行処理が実現されているのかが変わってきます。
一口に並行処理と言っても、そこにはOSレベルの話とユーザレベルの話があるのです。
皆さんがよく使う環境ではどうなっているのか、興味があればぜひ調べてみてください。
並行処理の注意事項
最後に、とても有益な並行処理を使用する上での注意事項についてまとめていこうと思います。
並行処理によってマルチコアCPUを活用することができるならどんどん並行処理を使っていけばいいんじゃないかと思うかもしれませんが、そこにはいくつかの落とし穴があります。
race condition(競合状態)
race conditionとは、複数のプロセスやスレッドが共有する資源(変数、メモリ領域、ファイルなど)に同時にアクセスし、その実行順序やタイミングの違いにより、予期しない結果や不整合な状態が生じる現象です。
たとえば、二つのスレッドが同じ変数の値を更新する場合、一方のスレッドが読み込み、計算し、書き戻す一連の操作中にもう一方のスレッドも同じ操作を行うと、最終的な変数の値がどちらの計算結果になるか、あるいは中途半端な状態になるかは実行タイミング次第で決まります。
これがrace conditionであり、並行処理プログラムのバグの主要原因の一つとなります。
この問題を回避するためには、共有資源への同時アクセスを制御し、各処理が確実に排他的に実行されるようにする必要があります。
代表的な手法としては、ミューテックス、セマフォ、リーダー・ライターロックなどの同期機構を用いて、クリティカルセクション(共有資源を操作するコード領域)の排他制御を行います。
これにより、一度に1つのスレッドのみが該当部分にアクセスし、データの整合性が保たれます。
また、アトミック操作やメモリバリアを活用して、ハードウェアレベルでの競合状態を防ぐことも可能です。
しかし、同期機構を用いる場合はデッドロックやライブロックなどの同期問題も発生しますし、デバッグが大変です(分かりやすくエラーが出るのではなく処理が先に進まなくなります)。
総じて、並行処理を導入することは逐次処理のみの場合と比べて実装難易度を高めます。
速くなるとは限らない
並行処理をすると実装は難しくなるとしてもマルチコアを効率的に利用できて速くなるならいいではないかと思うかもしれません。
しかし、並行化したいコードによってあまり速くならないか、下手をするとパフォーマンスが悪化してしまうかもしれません。
まず、これまで説明して来た通り、並行処理の実現にあたってはコンテキストスイッチが発生します。
カーネルスレッドでもユーザスレッドでも、コストの大小はあれどオーバーヘッドは生じます。
そのため、処理を細かく分割してスレッド数を増やしすぎるとコンテキストスイッチのオーバーヘッドがマルチコアの利点を打ち消してしまう可能性があります。
そうならないようにするに、適切な処理の分割粒度(データ単位で分割するか、処理で分割するか、またその大きさはどうするか)を定義し、パフォーマンスを計測しながら調整する必要があります。
それだけではありません。
1967年に提唱されたアムダールの法則というものがあります。

これはあるプログラムをできるだけ並列化しても、並列化できなかった部分の割合によって性能向上の上限が決まるというものです。
上の図において、プログラムの95%を並列化できたとしても、残りの5%は並列処理ができないため、プロセッサ数が2048を超えてからはどれだけ数を増やしたとしても、図で示したように20倍以上には高速化しないことを示しています。
並列化の割合が50%の段階に至ってはプロセッサ数をどれだけ増やしても2倍までしか高速化しません。
このように、アムダールの法則はCPUコアを増やせば増やすだけ性能が向上するわけではなく、CPUのコア数に加え、プログラムをどれだけ並列化できるかで性能が決まるということを言っています。
ただし、この法則は「並列化しても処理する問題の大きさが変化しない」という前提と、「プログラムには並列化できない部分がある」という前提の上で成り立っているという点に留意が必要です。
おわりに
いかがでしたでしょうか。
並行処理はパフォーマンスを向上させてくれるかもしれませんが、適切に設計して使用しないと却って予期せぬバグやパフォーマンスの劣化を招く可能性があります。
並行処理は重厚な分野なのでさまざまな本があります。
快適な並行処理ライフのために、皆さんも是非ご自身の得意な言語で並行処理を学んでみてください。
ではまた!
Discussion