Grafana/Prometheus で Kubernetes のリソースモニタリングをしてみる
Kind を使って簡単なリソースモニタリング環境を構築します。
前提
- Docker がインストールされていること
- Kind がインストールされていること
- Helm 3 がインストールされていること
セットアップ手順
まずは、Kind でコントロールプレーンのみのシンプルなクラスタを作成します。
30000, 30001, 30002 に関してホストのポートと NodePort をマッピングさせることでホストの環境から Grafana にアクセスできるようにします。
NodePort を使うことで、Kind のコンテナ外部(ホストマシン)から直接サービスにアクセスできるようになります。
cat <<EOF | kind create cluster --config -
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: monitoring-cluster
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
protocol: TCP
- containerPort: 30001
hostPort: 30001
protocol: TCP
- containerPort: 30002
hostPort: 30002
protocol: TCP
EOF
次に HPA によるスケーリングを可能にするために metrics-server をデプロイします。
kubectl apply -f - <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-server
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: metrics-server
template:
metadata:
labels:
app: metrics-server
spec:
serviceAccountName: metrics-server
containers:
- name: metrics-server
image: registry.k8s.io/metrics-server/metrics-server:v0.7.0
args:
- --cert-dir=/tmp
- --secure-port=10250
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
ports:
- containerPort: 10250
name: https
volumeMounts:
- name: tmp-dir
mountPath: /tmp
volumes:
- name: tmp-dir
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: metrics-server
namespace: kube-system
spec:
ports:
- port: 443
targetPort: https
selector:
app: metrics-server
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.metrics.k8s.io
spec:
service:
name: metrics-server
namespace: kube-system
group: metrics.k8s.io
version: v1beta1
groupPriorityMinimum: 100
versionPriority: 100
insecureSkipTLSVerify: true
EOF
起動するまで待つ
kubectl wait --for=condition=ready pod -l app=metrics-server -n kube-system --timeout=60s
次に Prometheus Stack をインストールします。
各サービスは先ほど設定した NodePort に対応付けます。
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install prometheus-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--create-namespace \
--set prometheus.service.type=NodePort \
--set prometheus.service.nodePort=30000 \
--set grafana.service.type=NodePort \
--set grafana.service.nodePort=30001 \
--set alertmanager.service.type=NodePort \
--set alertmanager.service.nodePort=30002 \
--set grafana.adminPassword=admin
インストール確認をしてください
kubectl get pods -n monitoring
# すべての Pod が Running になるまで待機
kubectl wait --namespace monitoring \
--for=condition=ready pod \
--selector=app.kubernetes.io/name=grafana \
--timeout=300s
Pod が立ち上がると各サービスには以下の URL からアクセスできるようになります。
| サービス | URL | ユーザー名 | パスワード |
|---|---|---|---|
| Grafana | http://localhost:30001 | admin | admin |
| Prometheus | http://localhost:30000 | - | - |
| AlertManager | http://localhost:30002 | - | - |
kube-prometheus-stack には以下のダッシュボードがプリインストールされています。
- Kubernetes / Compute Resources / Cluster - クラスタ全体のリソース使用状況
- Kubernetes / Compute Resources / Namespace (Pods) - Namespace ごとの Pod のリソース使用状況
- Kubernetes / Compute Resources / Pod - 個別 Pod の詳細メトリクス
- Node Exporter / Nodes - ノードレベルのメトリクス
監視対象のサンプルアプリをデプロイします
# サンプル Deployment の作成
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: nginx
image: nginx:alpine
resources:
requests:
memory: "64Mi"
cpu: "50m"
limits:
memory: "128Mi"
cpu: "100m"
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: sample-app
namespace: default
spec:
selector:
app: sample-app
ports:
- port: 80
targetPort: 80
EOF
# HPA (Horizontal Pod Autoscaler) の設定
kubectl autoscale deployment sample-app --cpu-percent=50 --min=1 --max=10
ダッシュボード構築
Prometheus クエリについて
http://localhost:30000 にアクセスすることで Prometheus ダッシュボードにアクセスできます。
検索窓に入力することでどんなメトリクスがあるかどうか補完でみることができます。
メトリクスの探し方のコツとしてはよく使うメトリクスの接頭辞を覚えることです。
| 接頭辞 | 説明 |
|---|---|
container_ |
コンテナレベルのメトリクス |
kube_ |
Kubernetes オブジェクトの状態 |
node_ |
ノードレベルのメトリクス |
まずは、特定の Deployment の Pod 単位の CPU 使用量及び メモリの使用量、Deployment のレプリカ数に関してどんなクエリで取得できるかを考えていきます。
Pod 単位の CPU 使用量
container_cpu_usage_seconds_total というメトリクスを利用して算出します。
container_cpu_usage_seconds_total は 累積値(Counter型) で、以下のような意味を持つメトリクスです。
時刻 10:00:00 → 値: 100秒
時刻 10:05:00 → 値: 115秒
→ 5分間で 15秒分 CPU を使用した
CPU 使用率を計算するには単位時間あたりにどれくらいの CPU 使用量が増えるかどうか分かり、それの計算に使えるのが rate() 関数です。
例えば、rate(container_cpu_usage_seconds_total[N]) というクエリは直近 N 秒間の CPU 使用量の平均を表します。
# rate(container_cpu_usage_seconds_total[5m]): 5分間の平均
rate = (115秒 - 100秒) / (5分 × 60秒/分) = 15秒 / 300秒 = 0.05
以上を元に rate(container_cpu_usage_seconds_total[1m]) を Prometheus UI 上で実行すると大量のメトリクスが出力されるのでさらに絞り込む必要があります。
Promethues においてはメトリクスの後に {} でフィールドを指定することでメトリクスを絞り込むことができます。
sample-app という Deployment の Pod のコンテナのみをフィルターしたいので例えば以下のように絞り込むことができます。
rate(container_cpu_usage_seconds_total{namespace="default", pod=~"sample-app-.*", container!=""}[1m])
container!="" は pause コンテナなどの補助的なコンテナを除外し、実際のアプリケーションコンテナのみを対象にするための条件です。
最終的にこれを 100 倍することで Pod が使用している CPU のコア数をメトリクスとして取得することができます。
Pod 単位の RAM 使用量
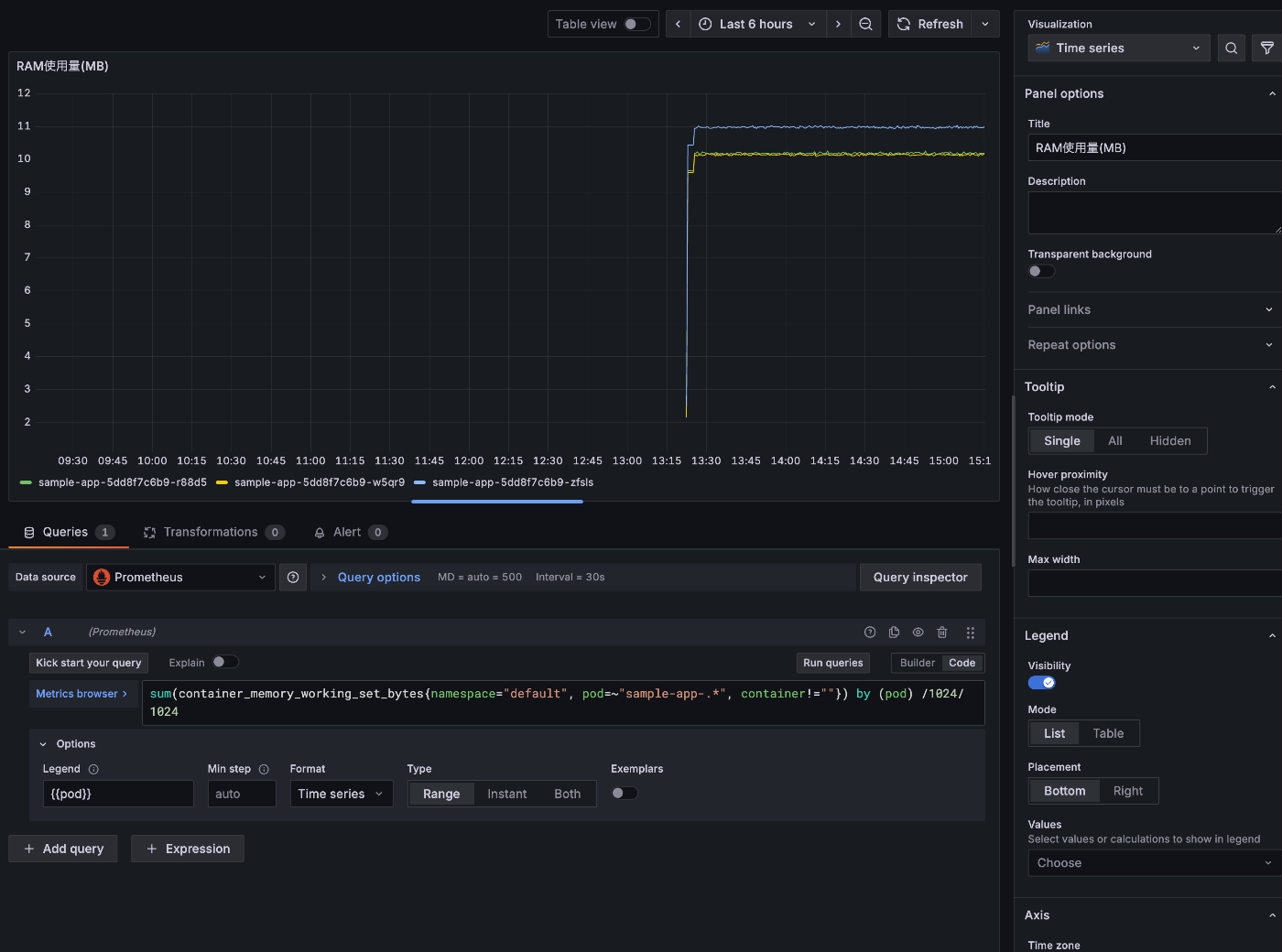
コンテナのメモリ使用量は container_memory_working_set_bytes で取得できます。
Pod 単位でのメモリ使用量を取得するには以下のクエリを実行すれば良いです。
sum(container_memory_working_set_bytes{namespace="default", pod=~"sample-app-.*", container!=""}) by (pod) /1024/1024
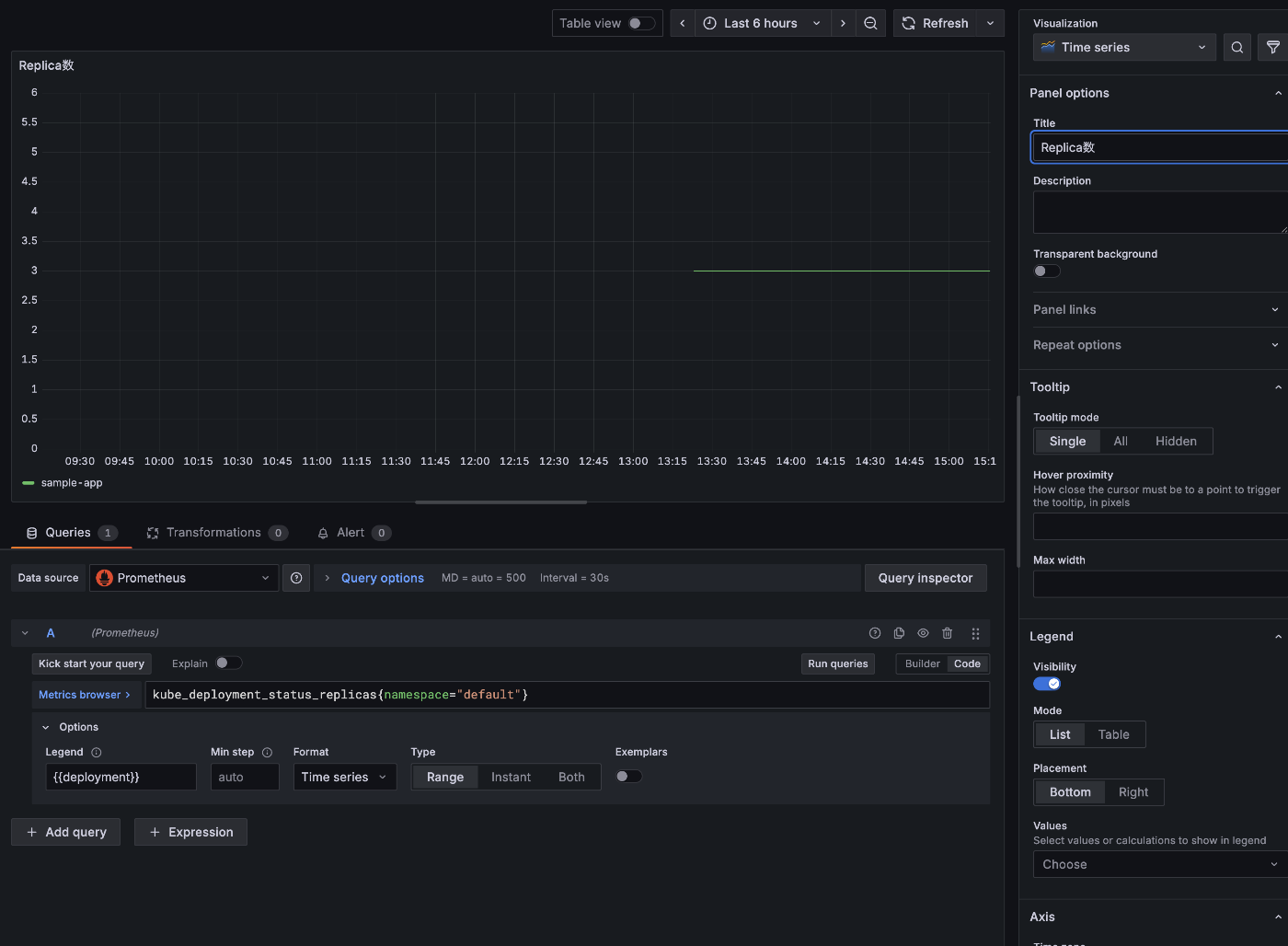
Deployment のレプリカ数
Deployment のレプリカ数 status.replicas は以下のクエリで確認できます。
kube_deployment_status_replicas{namespace="default"}
Grafana ダッシュボード作成
取得方法を確認した3つのメトリクスをダッシュボード化します
まずは Grafana を開いて左のタブから「Dashboard」を選択します。
「New」->「New Dashboard」->「Save Dashboard」と進んでまずは空のダッシュボードを保存しましょう。

続いて「Add Visualization」を選択し、データソースの指定が出るので Prometheus を選択してグラフを追加していきます。
まずは CPU の使用コア数からいきます。
以下のように入力して終わったら「Save」してください。
- Title: CPU 使用量
- Query:
rate(container_cpu_usage_seconds_total{namespace="default", pod=~"sample-app-.*", container!=""}[1m]) - Legend: {{pod}}

「My First Dashboard」に戻って次にメモリ使用量も同様に入力してください。
デプロイメントの数に関しても同様です。
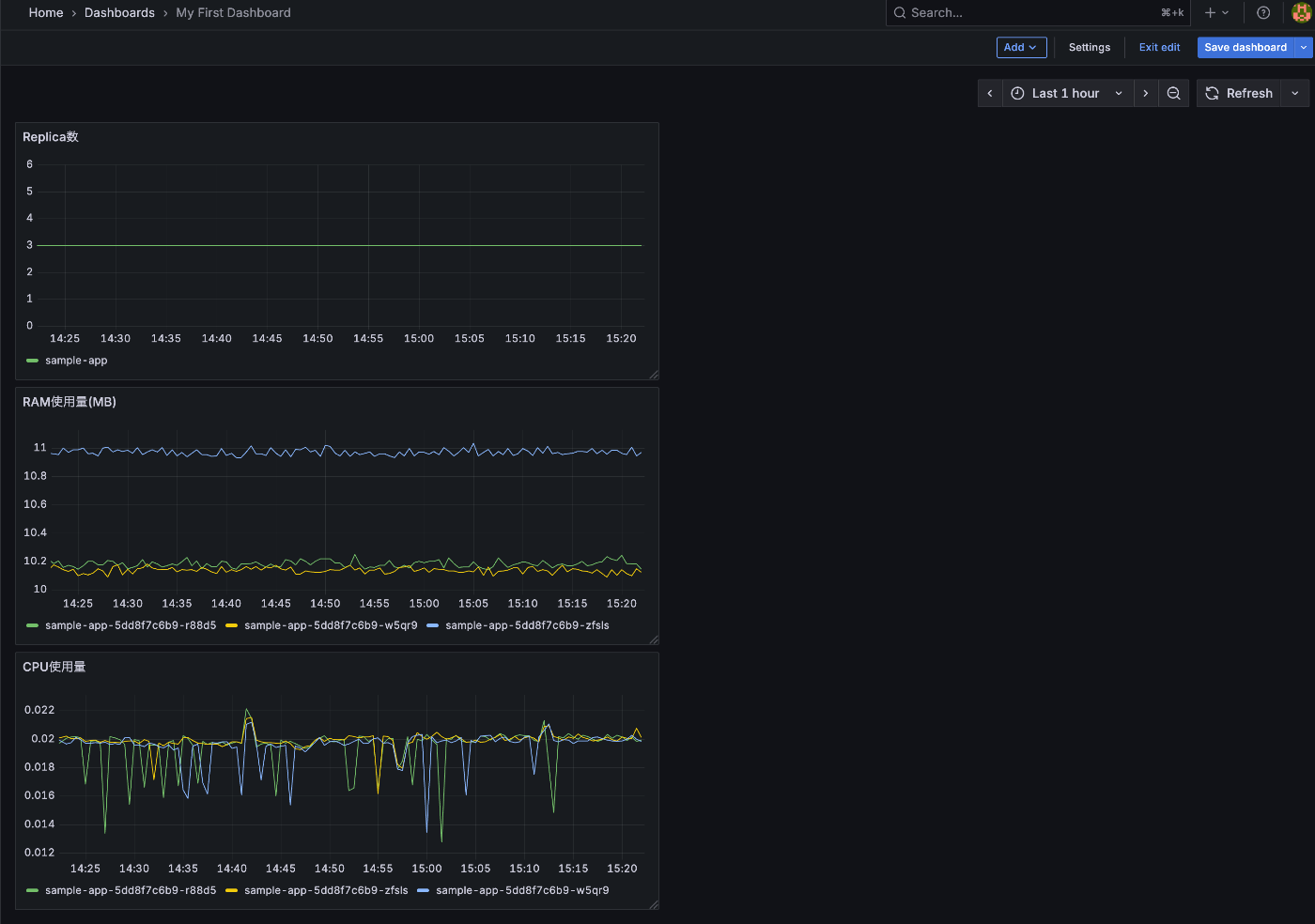
ダッシュボードのページに戻ると以下のようなダッシュボードが表示されています
Pod に負荷をかけてスケールの様子を観測してみる
現在の HPA の様子を確認すると対象の Pod の平均CPU使用率が 50% を切っているので最低稼働数である 1 にスケールインしていることが分かります。
❯ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
sample-app Deployment/sample-app cpu: 0%/50% 1 10 1 145m
ダッシュボードを見ても現在のPod数が 1、メモリ使用量は 10MB 程度、CPU 使用量はほぼ 0 であることが分かります。

クラスタ内に別の Pod をデプロイしてApache Bench (ab)を使って負荷をかけてみます。
この動作により、CPU 使用率が最大の 100m まで急激に上昇し HPA のスケールが発動して Pod の数が増えると予想されます。
cat <<'EOF' | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: ab-extreme-load
spec:
containers:
- name: ab-load
image: httpd:alpine
resources:
requests:
cpu: "500m"
memory: "512Mi"
command: ["/bin/sh"]
args:
- -c
- |
START_TIME=$(date +%s)
END_TIME=$((START_TIME + 600))
echo "Starting EXTREME 10 minute load test with 10 parallel processes..."
echo "Start time: $START_TIME"
echo "End time: $END_TIME"
# 10個の並列abプロセスを起動
for i in $(seq 1 10); do
(
echo "Starting worker $i"
while [ $(date +%s) -lt $END_TIME ]; do
CURRENT_TIME=$(date +%s)
ELAPSED=$((CURRENT_TIME - START_TIME))
echo "[Worker $i] Elapsed: ${ELAPSED}s - Sending 5000 requests with 500 concurrent connections"
ab -n 5000 -c 500 -s 30 -r http://sample-app.default.svc.cluster.local/ 2>&1 | grep -E "Requests per second|Time per request|Failed"
done
echo "Worker $i completed"
) &
done
# 全プロセスの終了を待つ
wait
echo "All workers completed after 10 minutes"
sleep 3600
EOF
検証の途中で最大 Pod 数を 30 台まで増やしました
kubectl patch hpa sample-app --patch '{"spec":{"maxReplicas":30}}'
負荷をかけ終わって数分経ったのちに確認したダッシュボードの様子です。
最大 18 台まで Pod の台数がスケールしていることが分かります。
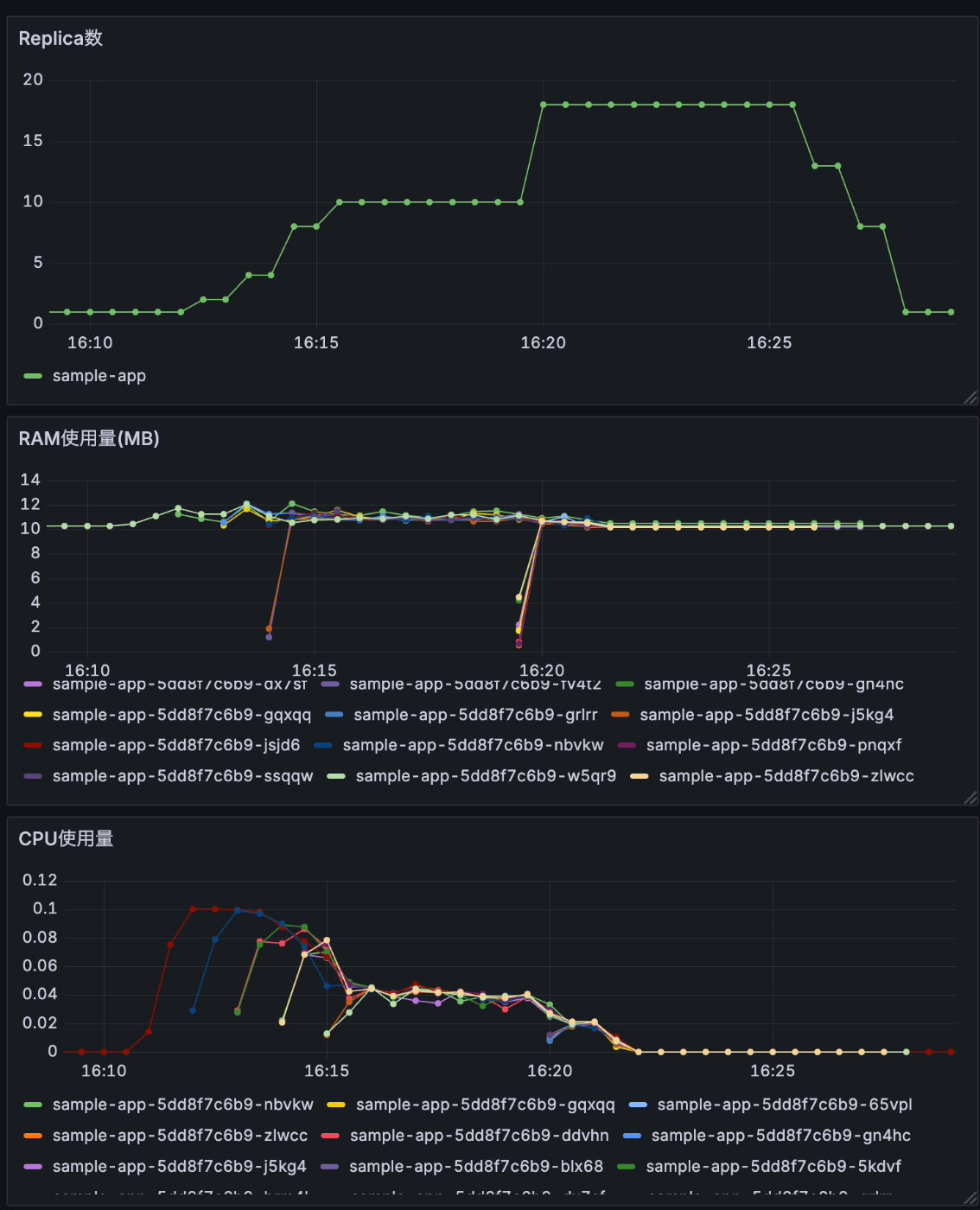
HPA は CPU の使用率に対して設定されており、resources.requests.cpu の値を基準に割合を出すので絶対で言うと 0.025 (25m) になるようにワーカーの台数が K8s の機能で調整されます。
おわりに
本記事では Kind を使用して Prometheus と Grafana によるモニタリング環境を構築し、実際に負荷をかけて HPA によるオートスケーリングの様子を可視化しました。
体験できたこと
オブザーバビリティの実践
- リアルタイムな可視化: CPU やメモリの使用状況、Pod 数の変化をリアルタイムで確認できることで、システムの挙動を直感的に理解できました
- トラブルシューティング: メトリクスを見ることで、なぜ Pod がスケールしたのか、どの程度のリソースを消費しているのかが明確になりました
- パフォーマンス分析: 負荷テスト時の応答性能や、リソース使用効率を数値で把握できました
Prometheus/Grafana の基礎
-
PromQL の実践:
rate()やsum()などの関数を使った実用的なクエリの書き方を学びました - ダッシュボード作成: 必要なメトリクスを組み合わせて意味のある可視化を作る方法を習得しました
-
メトリクスの理解:
container_、kube_、node_などの接頭辞から適切なメトリクスを探す方法を理解しました
クリーンアップ
検証が終わったら、以下のコマンドで環境を削除しましょう
kind delete cluster --name monitoring-cluster
モニタリングはシステム運用において不可欠な要素です。今回のハンズオンを通じて、実際にメトリクスが変化する様子を目で見て、オブザーバビリティの重要性を実感していただけたなら幸いです!
Discussion