【形態素解析ツール】Juman++ ver2 の使い方
Juman++は自然言語処理を行うにあたって必要不可欠な処理である形態素解析を行うツールです。MeCabと比べると処理速度は約1/10となりますが、より高精度の解析が可能で表記揺れや口語表現にも比較的堅牢な解析ができる印象があります。
インストール方法
ソースコードをダウンロードして手元の環境でビルドする必要があります。
対応する環境のインストール方法を参照してください。
Debian系Linux
# パッケージの更新&install
sudo apt update
sudo apt install -y cmake g++ wget xz-utils
# ソースをダウンロード
wget "https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc3/jumanpp-2.0.0-rc3.tar.xz"
tar xvJf jumanpp-2.0.0-rc3.tar.xz
# ビルド用ディレクトリを作成
cd jumanpp-2.0.0-rc3
mkdir bld && cd bld
# catch.hppを最新のものに
curl -LO https://github.com/catchorg/Catch2/releases/download/v2.13.8/catch.hpp
mv catch.hpp ../libs/
# ビルド&install
cmake .. -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX="インストール先"
sudo make -j $(nproc)
sudo make install
M1 Mac
ダウンロードするソースがApple M1に対応していないので後から編集する必要があります。
# パッケージの更新&install
brew updata
brew install zlib wget
# ソースをダウンロード
wget "https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc3/jumanpp-2.0.0-rc3.tar.xz"
tar xvJf jumanpp-2.0.0-rc3.tar.xz
cd jumanpp-2.0.0-rc3
# ビルド用ディレクトリを作成
mkdir bld && cd bld
cmake .. -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX="インストール先"
# catch.hppを最新のものに
curl -LO https://github.com/catchorg/Catch2/releases/download/v2.13.8/catch.hpp
mv catch.hpp ../libs/
このままmakeコマンドを実行しビルドを行うとエラーが発生するのでソースコードを書き換えます。
jumanpp-2.0.0-rc3/libs/backward.hppの2267,2268行目付近をコメントアウトし以下のように改変します。
// #elif defined(__aarch64__)
// error_addr = reinterpret_cast<void*>(uctx->uc_mcontext.pc);
#elif defined(__aarch64__)
#if defined(__APPLE__)
error_addr = reinterpret_cast<void *>(uctx->uc_mcontext->__ss.__pc);
#else
error_addr = reinterpret_cast<void *>(uctx->uc_mcontext.pc);
#endif
ソースコードを書き換えたら、あとはいつも通りです。
sudo make -j $(getconf _NPROCESSORS_ONLN)
sudo make install
使い方
通常のコマンドラインでの使い方とPythonラッパーを利用した使い方を紹介します。
コマンドラインでの使い方
携帯素解析したいテキストを標準入力するか、引数に解析対象のテキストファイルを指定することで解析できます。
吾輩は猫である。
名前はまだ無い。
# 標準入力
cat sample.txt | jumanpp
# 引数指定
jumanpp sample.txt
すると以下のような解析結果が出力される。
吾輩 わがはい 吾輩 名詞 6 普通名詞 1 * 0 * 0 "代表表記:我が輩/わがはい カテゴリ:人"
は は は 助詞 9 副助詞 2 * 0 * 0 NIL
猫 ねこ 猫 名詞 6 普通名詞 1 * 0 * 0 "代表表記:猫/ねこ カテゴリ:動物 漢字読み:訓"
である である だ 判定詞 4 * 0 判定詞 25 デアル列基本形 15 NIL
。 。 。 特殊 1 句点 1 * 0 * 0 NIL
名前 なまえ 名前 名詞 6 普通名詞 1 * 0 * 0 "代表表記:名前/なまえ カテゴリ:抽象物"
は は は 助詞 9 副助詞 2 * 0 * 0 NIL
まだ まだ まだ 副詞 8 * 0 * 0 * 0 "代表表記:まだ/まだ"
無い ない 無い 形容詞 3 * 0 イ形容詞アウオ段 18 基本形 2 "代表表記:無い/ない 反義:動詞:有る/ある"
。 。 。 特殊 1 句点 1 * 0 * 0 NIL
EOS
昨今は深層学習を使った自然言語処理が主流なので分かち書きさえできれば良い場合多い。そのような場合は--segmentオプションをつける。
# 標準入力
cat sample.txt | jumanpp --segment
# 引数指定
jumanpp sample.txt --segment
# 吾輩 は 猫 である 。 名前 は まだ 無い 。
Pythonからの使い方
pyknpというライブラリを使ってjuman++をpythonから呼び出します。
# pyknpをinstall
pip install pyknp
juman++を扱う場合はpyknp.Jumanクラスを使います。
from pyknp import Juman
jumanpp = Juman()
text = '吾輩は猫である。'
mlist = jumanpp.analysis(text)
print([mrph.midasi for mrph in mlist.mrph_list()])
# ['吾輩', 'は', '猫', 'である', '。']
このようにすれば分かち書きができる。
mrphのその他の属性に関しては下記を参考にしてください。上の例ではmidasi属性を列挙して参照しました。
mrph_id (int): 形態素ID
mrph_index (int): mrph_idに同じ
doukei (list):
midasi (str): 見出し
yomi (str): 読み
genkei (str): 原形
hinsi (str): 品詞
hinsi_id (int): 品詞ID
bunrui (str): 品詞細分類
bunrui_id (int): 品詞細分類ID
katuyou1 (str): 活用型
katuyou1_id (int): 活用型ID
katuyou2 (str): 活用形
katuyou2_id (int): 活用形ID
imis (str): 意味情報
fstring (str): 素性情報
repname (str): 代表表記
ranks (set[int]): ラティスでのランク
span (tuple): 形態素の位置 (開始位置, 終了位置), JUMAN出力形式がラティス形式の場合のみ
形態素解析の応用例
nlp100本ノック: 第四章
全ての問題は解かずに一部に回答してみます。
import urllib
from collections import defaultdict as ddict
import matplotlib.pyplot as plt
import japanize_matplotlib
from pyknp import Juman
def download_file(url, dst_path):
try:
with urllib.request.urlopen(url) as web_file:
data = web_file.read()
with open(dst_path, mode='wb') as local_file:
local_file.write(data)
except urllib.error.URLError as e:
print(e)
class Analyzer:
def __init__(self, file):
self._jumanpp = Juman()
self.lines = [line for line in open(file)]
self.mlists = [self._jumanpp.analysis(line.rstrip()) for line in self.lines]
self.freq = self._count_frequency()
def get_verbs(self):
verbs_surface = set()
verbs = set()
for mlist in self.mlists:
for mrph in mlist:
if mrph.hinsi == '動詞':
verbs_surface.add(mrph.midasi)
verbs.add(mrph.genkei)
return verbs_surface, verbs
def get_A_no_B(self):
ans = set()
for mlist in self.mlists:
for i, mrph in enumerate(mlist):
if mrph.midasi == 'の':
if i == 0 or i == len(mlist) - 1:
continue
if mlist[i-1].hinsi == '名詞' and mlist[i+1].hinsi == '名詞':
ans.add((mlist[i-1].midasi, mrph.midasi, mlist[i+1].midasi))
return ans
def _count_frequency(self):
freq = ddict(int)
for mlist in self.mlists:
for mrph in mlist:
freq[mrph.genkei] += 1
freq = sorted(freq.items(), key=lambda x: x[1], reverse=True)
return freq
def plot(self):
data = [(i+1,f) for i, f in enumerate(self.freq)]
fig, ax = plt.subplots(dpi=100, figsize=(6,4))
X = [d[0] for d in data]
Y = [d[1][1] for d in data]
ax.plot(X,Y)
ax.set_xscale('log'); ax.set_yscale('log');
ax.set_xlabel('Rank'); ax.set_ylabel('Frequency')
ax.set_title('単語の出現頻度と出現順位の関係')
ax.grid()
return fig, ax
39番の問題に回答してみます。
download_file('https://nlp100.github.io/data/neko.txt', dst_path='neko.txt')
analyzer = Analyzer('neko.txt')
fig, ax = analyzer.plot()
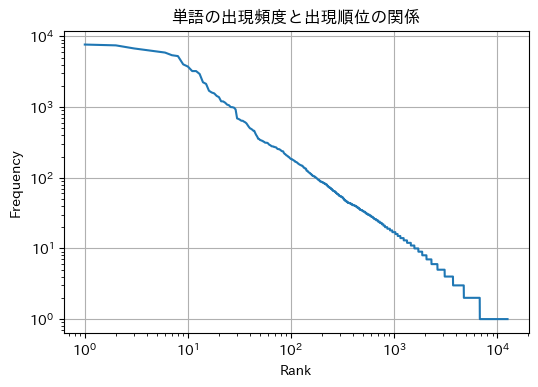
せっかくなので他のデータでもZipfの法則が成り立つか検証してみます。
import os
download_file('https://raw.githubusercontent.com/ecator/izunoko/master/books/%E4%BC%8A%E8%B1%86%E3%81%AE%E8%B8%8A%E5%AD%90%EF%BC%88%E8%A7%92%E5%B7%9D%E6%96%87%E5%BA%AB%EF%BC%89.txt', dst_path='odoriko.tmp')
with open('odoriko.tmp') as fin, open('odoriko.txt', 'w') as fout:
for line in fin:
line = line.rstrip()
if line != '':
fout.write(f'{line}\n')
os.remove('odoriko.tmp')
analyzer = Analyzer('odoriko.txt')
fig, ax = analyzer.plot()
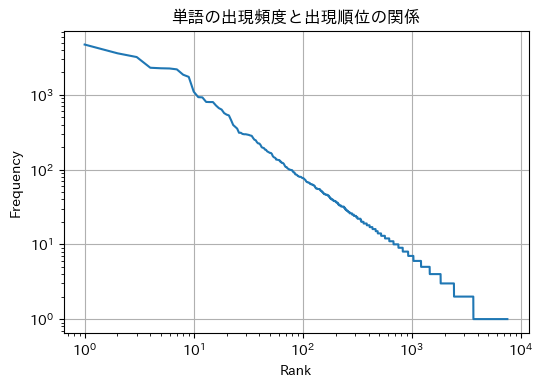
伊豆踊り子で試した場合もZipfの法則が成り立つことが確認できます。
Discussion