【論文読み】MMMU: A Massive Multi-discipline MultimodalUnderstanding
先日のCVPR2024で発表されていた新しいマルチモーダルベンチマークMMMU[1][2]の論文を調査しましたのでまとめます。
概要
- マルチモーダルモデルを評価する新しいベンチマーク
- 芸術から光学まで30科目と、11500個の大学レベルのマルチモーダルな質問が用意されてる
- ChatGPT-4V, Gemini Ultraですら56%, 59%となっている
なぜ新しいベンチマークを作る必要があったのか?
既にマルチモーダルのベンチマークは存在しています。
が、オープンソースのCogVLMは以下のベンチマークで90%前後を達成しています。
しかし、ほとんどの既存のマルチモーダルベンチマークは専門知識を伴う高度な推論ではなく、常識や日常知識レベルの問題となっています。
その中でも専門性のあるScienceQAですら多くの質問が初等教育から中学校レベルであり、これからのモデルを評価するには物足りないというのが現状です。
VQA-v2
Visual Question Answering。画像と説明が与えられ、質問に答えるというもの

ScienceQA
21万のマルチモーダルな複数選択質問と多様な科学トピックとそれに対応する講義や説明による回答の注釈からなる新しいベンチマーク

RefCOCO
COCOデータセットは画像から物体中心の(Object-centric)の画像認識タスク各種をおこなう目的で用いる大規模画像データセット[3]ですが、COCOデータセットの人気増加(使用頻度増)に伴い、個々の研究用に必要な外部アノテーションが後から追加されていきました。(有名なものだと上のVQAです)
そのうちの一つがRefCOCOです。
画像中の特定領域や特定物体についての記述文をクエリーとして入力して、その文が示す領域を特定してバウンディングボックス(bbox)を出力します。
つまりこのデータではCOCOの各物体インスタンスに対して、その物体領域の様子を指し示す記述(Referring Expression)が正解として追加されており、そのReferring Expression文を画像中の領域にGround(意味が同じところを対応付ける)ことを行います。

MMMUの特徴
上記の背景から、新しく作られたより専門性の高いベンチマークがMMMUです。
MMMUは大学の試験、クイズ、教科書から収集された問題を有しており、芸術とデザイン、ビジネス、科学、健康と医学、人文社会科学、技術と工学の6つの一般的な分野にまたがっています。
MMMUは、30科目の11,500のマルチモーダルな質問で構成されています。
包括性
- 芸術とデザイン、ビジネス、科学、健康と医学、人文社会科学、技術と工学の6つの一般的な分野
- 30科目にまたがる11,500の大学レベルの問題
画像タイプ
- 写真や絵画のような視覚シーンから、図表や表まで、多様な視覚的データを扱う
テキストと画像の交互入力
- モデルは画像とテキストを統合的に理解して推論して問題を解く必要がある
深い専門知識
- 「フーリエ変換」や「平衡理論」を適用して解決策を導き出すなど、専門家レベルの推論を必要とする


ChatGPT-4Vでの実験
GPT-4Vの予測からランダムに抽出された150件のエラーを分析しました。
-
知覚エラー(35%)
- GPT-4Vの大部分を占めている
- GPT-4Vはテキストに対するバイアスを示し、視覚入力よりもテキスト情報を優先する傾向がある
-
知識の欠如(29%)
- GPT-4Vモデルにおける知覚エラーの根本原因は、専門知識の不足
- 科目固有のコンテキストを正しく解釈できない場合に見られる
-
推論エラー(26%)
- 他の主要なエラー原因として挙げられる
- モデルがテキストと画像を正しく解釈し、関連する知識を想起しても、正確な推論を導き出すための論理的および数学的な推論能力を効果的に適用できない場合がある
-
その他のエラー
- テキスト理解エラー(6%)
- 回答拒否(3%)
- アノテーションエラー(2%)
- 回答抽出エラー(1%)

問題見てみた
HuggingFaceのDatasetから拝借。
Each of the following situations relates to a different company. <image 1> For company B, find the missing amounts.
Option
- $63,020
- $58,410
- $71,320
- $77,490
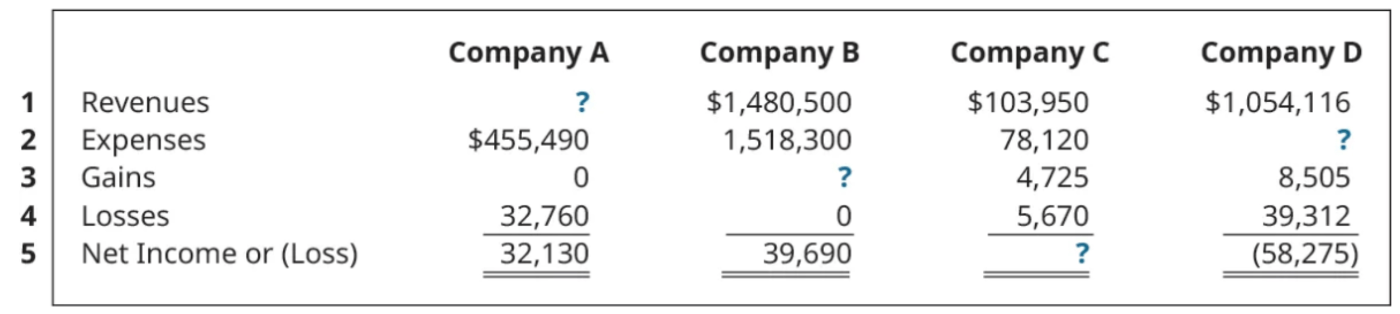
これでEasyらしいが、IQ低めの私にはお腹いっぱいです。。
Discussion