【論文読み】DriveGPT4: 自動運転のためのマルチモーダルモデル
ここ数年、生成AIやVision&Languageを活用して自動運転を実現するという流れが強くなってきています。
理由としては完全自動運転(レベル5[1])の領域になるとレアケースの対応が求められるため、走行時の状況把握をルールベースで行うのは難しく、状況理解ができるモデルが必要になるからです。また説明性という観点でも相性がいいのは事実です。
LLMの登場で、この流れが加速したと言っても良いのでは無いでしょうか?
Turingさんの講義動画は、現時点の立ち位置と目指す方向性が非常にわかりやすくまとまっていると思いました。
そんな中、中国の香港大学から自動運転をEnd2Endで行う興味深い論文[2]が出ていたので、こちらをみてみようと思います。
何がすごいか
はじめに
これまでにもEnd2Endシステムは提案されてきました
一方で、End2Endであるが故に、自動運転システムがブラックボックス化しており、法的懸念等の問題点があります。
2018年頃からBERT, GPTが登場し、車載センサーから事前言語を生成するということが行われてきましたが、小さな言語モデルでは定義済みの質問に対して堅苦しい応答しか生成できず、パフォーマンスが不十分でした。
ChatGPTやLLaMAのような大規模言語モデル(LLM)は広範囲な一般知識を有するため、低レベルの車両制御をより良く分析および生成する可能性を持っています。
上記を実現するために、LLMが画像やビデオなどのマルチモーダルデータを理解する必要があるため、LLMを利用した解釈可能なエンドツーエンド自動運転システム「DriveGPT4」を提案しています。
DriveGPT4では、主に
- データ観点
- モデル観点
に特徴がありますので、分けて記載します。
データ観点
まとめると
- BDD-X[5]をベースとして使用
- BDD-Xについているキャプションに対応する質問を作成(QAを作成する)
- 上記QAをChatGPTでデータ拡張
- またデータ拡張の際、YOLOv8[6]を使ってオブジェクトの位置情報をChatGPTに付与(車両、交通信号、曲がる方向、車線変更、周囲の物体、物体間の空間関係などをChatGPTが理解して拡張できる)
BDD-Xデータセット
BDD-X[5:1]は約20000のビデオデータとラベルデータが存在するデータセットです。(日本で撮影されたデータは含まれておりません)
Githubを見えるとどのようなデータか良くわかると思います。
- ビデオ
- 8枚の画像フレームからなります
- ラベルデータ
3種類のデータがあります- 車両の行動説明(Action Description)
- 行動の正当化(Action Justification)
- 各フレームに対する車両速度などの制御信号
BDD-X Githubから拝借したサンプルデータ

DriveGPT4論文から拝借したサンプルデータ

QAの作成
LLMをトレーニングするために、質問応答(QA)ペアが必要になります。
この論文では、BDD-Xのラベルが正解になるような質問を作成します。
たとえば、車両の行動説明に対しては、
- この車両の現在の行動は何ですか?
のような質問を作成すれば、行動説明が答えとなるQAが作成され、LLMがAを予測するタスクとしてトレーニングできます。
が入力質問としてLLMに送信されるべきです。その後、LLMは応答を生成し、その正解ラベルは車両の行動説明となります。BDD-Xデータセットには3種類のラベルがあるため、Qa、Qj、Qcの3つの質問セットを作成します。LLMが固定された質問パターンに過剰適合しないようにするために、Liu et al.(2023)に触発されて、各質問セットには1つの質問に対する複数の同義表現が含まれるべきです。
3つのラベルに対しての質問例は以下になります。
- Qaには、「この車両の現在の行動は何ですか?」と同義の質問
- Qjには、「この車両はなぜこのように振る舞っていますか?」と同義の質問
- Qcには、「次のフレームで車両の速度と曲がる角度を予測してください」と同義の質問
データ拡張
上記でQAができましたが、これだけでは多様性に欠けます。ユーザーが車両の状態を詳細に知りたい場合や日常的な質問をした場合、十分に対応できない可能性があります。
そのため、ChatGPTを使ってデータ拡張を行います。
QAの拡張に加えて、ChatGPTが画像の詳細を理解できることを利用して、物体検出モデルYOLOv8[6:1]を使用して、画像内に映る一般的な物体(人とか車とか)を検出し、この情報も付与します。
(LLaMAに入力するためにbboxの座標値は正規化されています)
こうして生成されたデータが以下です。

モデル観点
まとめると
- ビデオトークナイザーとしてValleyを使用
- 後段にLLaMA2を使って動画とテキストを処理

ビデオトークナイザー
入力ビデオフレームを
とします。各ビデオフレーム
簡潔な表現のために、

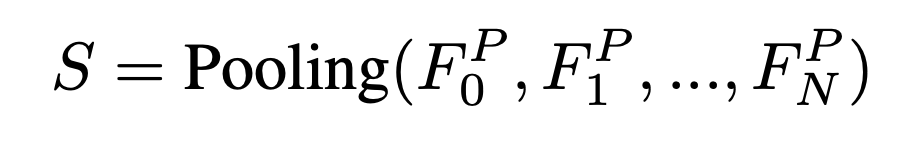
Poolingは、メモリ効率のために
最終的に、時系列特徴
LLaMA2
DriveGPT4では、マルチモーダル入力データに基づいて、次のステップで制御信号を予測する必要があります。
入力となるものは
- ビデオのフレームの時間長
- 現在の車両速度
テキスト入力に含まれます。予測されたトークンを取得した後、LLaMAトークナイザーを使用してトークンをテキストにデコードします。
予測された制御信号は、固定フォーマットで出力テキストに埋め込まれ、簡単に抽出できるようにします。
学習
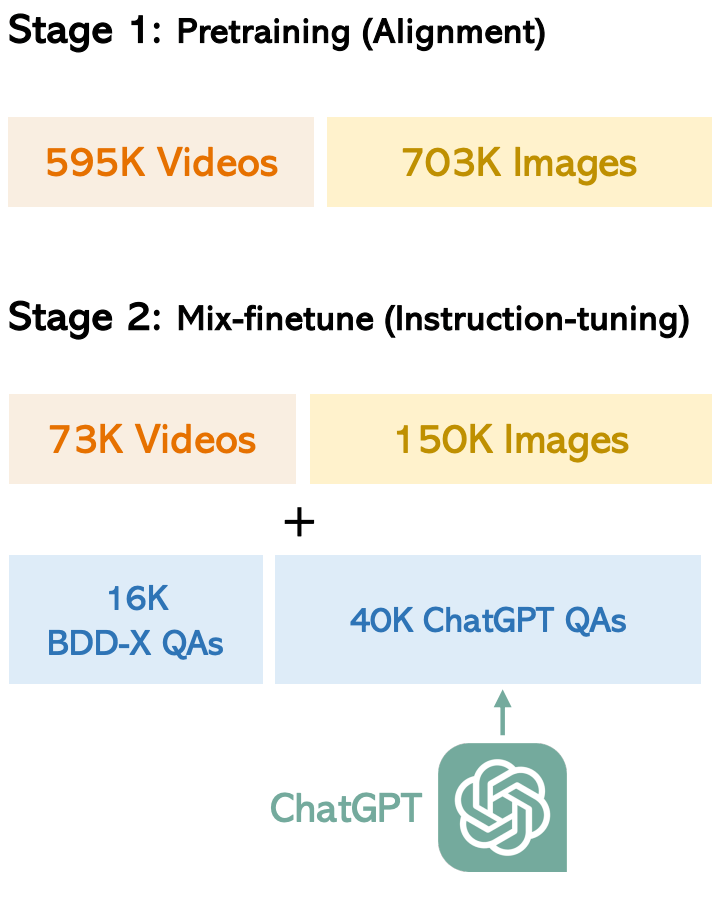
学習は2つのStepからなります。
事前トレーニング
ビデオとテキストを両方理解できるようにするために学習を行います。
ここでは自動運転用に特化しているわけではないので、CLIPエンコーダとLLMの重みは固定されて、プロジェクターのみを学習します。
使用したデータは
- 593Kの画像とテキストのペアであるCC3M[^cc3m]
- 703KのビデオとテキストのペアであるWebVid-2M[^WebVid-2M]
ファインチューニング
拡張して自作したデータセット使って、E2E自動運転に関する質問に回答するため学習を行います。
ここではLLMとプロジェクターを学習します。
さらにLLaMAとValleyで生成したデータも学習データに加えます。
実験結果
テストデータは状況により理解の難易度が変わるので、運転シーンと車両の状態に基づいて簡単、普通、難しいという3クラスに分割します。
精度指標はNLPの世界でよく用いられるCIDEr、BLEU4等を使用します。
結果をみると、この時点でのSOTAモデルであるADAPTを上回っていることがわかります。

最後に
DriveGPT4のページを見ると、コードはまだ公開されていないですね。
公開された動かしてみたいと思います。
Reference
-
https://www.ecva.net/papers/eccv_2018/papers_ECCV/papers/Jinkyu_Kim_Textual_Explanations_for_ECCV_2018_paper.pdf ↩︎ ↩︎
-
https://arxiv.org/pdf/2305.09972
[^clip]https://arxiv.org/abs/2103.00020
[^cc3m]https://huggingface.co/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K
[^WebVid-2M]https://huggingface.co/datasets/luoruipu1/Valley-webvid2M-Pretrain-703K ↩︎ ↩︎
Discussion